 ECS實例——Arm芯片的 Python-AI算力優化
ECS實例——Arm芯片的 Python-AI算力優化
深度學習技術在圖像識別、搜索推薦等領域得到了廣泛應用。近年來各大 CPU 廠商也逐漸把 AI 算力納入了重點發展方向,通過《Arm 芯片 Python-AI 算力優化》我們將看到龍蜥社區 Arm 架構 SIG(Special Interest Group) 利用最新的 Arm 指令集優化 Python-AI 推理 workload 的性能。
倚天 ECS 實例的 AI 推理軟件優化
阿里云推出的倚天 Arm ECS 實例,擁有針對 AI 場景的推理加速能力,我們將了解加速的原理以及以及相關的軟件生態適配。
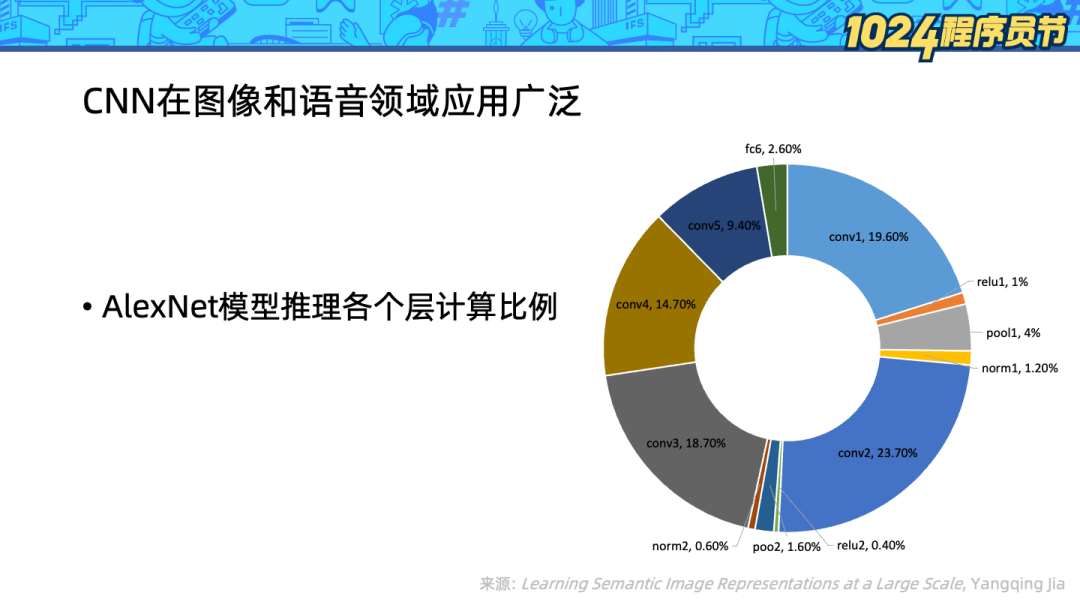
卷積神經網絡(CNN)在圖像和語音領域使用廣泛,神經網絡算法相比傳統的算法消耗了更多算力。為了探索對計算的優化,我們進一步看到 AlexNet 模型(一種 CNN)的推理過程的各個層的計算資源消耗占比。
可以看到名為 conv[1-5] 的 5 個卷積層消耗了 90% 的計算資源,因此優化 CNN 推理的關鍵就是優化卷積層的計算。
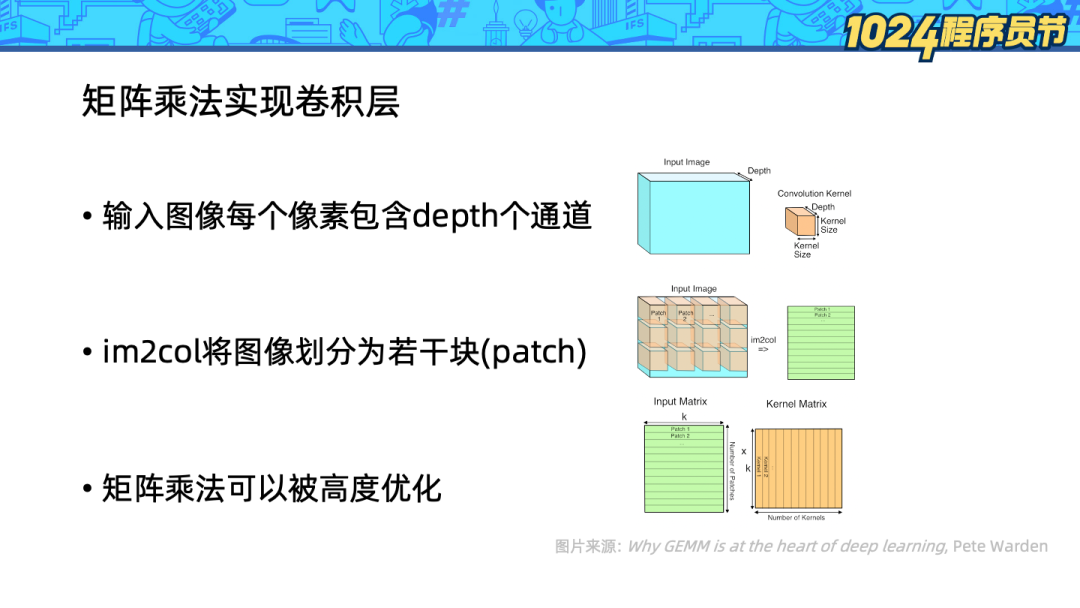
3、對由圖像塊組成的矩陣和由多個卷積核展開組成的矩陣應用矩陣乘法。

上面一頁的計算應用了矩陣乘法操作,為什么我們不采用更加直接的迭代計算方式,而是采用需要額外內存的矩陣乘法呢?這里有兩個關鍵因素:
-
深度學習的卷積計算量很大,典型計算需要涉及 5000 萬次乘法和加法操作,因此對計算的優化十分重要。
-
計算機科學家們已經深入探索了矩陣乘法操作,矩陣乘法操作可以被優化得非常快。
在 fortran 世界中,GEMM(general matrix multiplication)已經成為一個通用操作: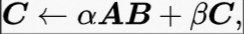 該操作通過對數據重新排列,精心設計計算過程,利用多線程和向量指令,可以比自己實現的樸素版本快十倍以上。因此使用矩陣運算帶來的收益相比額外的開銷是值得的。
該操作通過對數據重新排列,精心設計計算過程,利用多線程和向量指令,可以比自己實現的樸素版本快十倍以上。因此使用矩陣運算帶來的收益相比額外的開銷是值得的。
因為 AI 推理大量使用了矩陣乘法,如今也有許多硬件對矩陣運算進行了加速:
- NVIDIA Volta 架構引入了 tensor core,可以高效地以混合精度處理矩陣乘。
-
Intel AMX(Advanced Matrix Extensions) 通過脈動陣列在硬件層面支持矩陣乘。
-
Arm SME(Scalable Matrix Extension) 支持向量外積運算,加速矩陣乘。
雖然在 AI 算力上 GPU 要遠高于 CPU,但是 CPU 因為其部署方便,且無需在主機-設備間拷貝內存,在 AI 推理場景占有一席之地。目前市面上尚沒有可以大規模使用的支持 AMX 或者 SME 的硬件,在這個階段我們應該如何優化 CPU 上的 AI 推理算力?我們首先要了解 BF16 數據類型。

BF16(Brain Float 16)是由 Google Brain 開發設計的 16 位浮點數格式。相比傳統的 IEEE16 位浮點數,BF16 擁有和 IEEE 單精度浮點數(FP32)一樣的取值范圍,但是精度較差。研究人員發現,在 AI 訓練和推理中,使用 BF16 可以節約一半的內存,獲得和單精度浮點數接近的準確率。
根據右圖,BF16 指數的位數和 FP32 是一致的,因此 BF16 和 FP32 的相互轉換只要截斷尾數即可,左下角圖上便是 tensorflow 源碼中的轉換實現。
引入 BF16 的一大價值是如今的很多硬件計算的瓶頸在寄存器寬度或者訪問內存的速度上,更緊湊的內存表示往往可以獲得更高的計算吞吐,在理想情況下,BF16 相比 FP32 可以提高一倍的吞吐(FLOPS)。
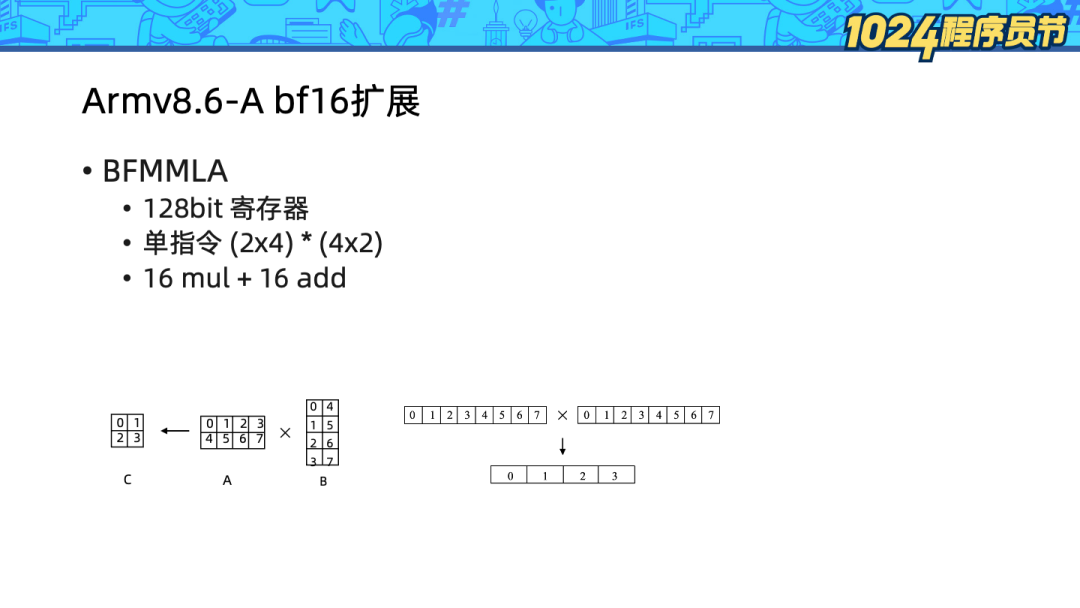
如今我們雖然無法大規模使用到支持 AMX/SME 的硬件,但是 Armv8.6-A 提供了 bf16 擴展,該擴展利用了有限的 128bit 向量寄存器,通過 BFMMLA 指令執行矩陣乘法運算:
-
輸入 A:大小為 2*4 的 BF16 矩陣,按行存儲。
-
輸入 B:大小為 4*2 的 BF16 矩陣,按列存儲。
-
輸出C:大小為 2*2 的 FP32 矩陣。
該指令單次執行進行了 16 次浮點數乘法和 16 次浮點數加法運算,計算吞吐非常高。
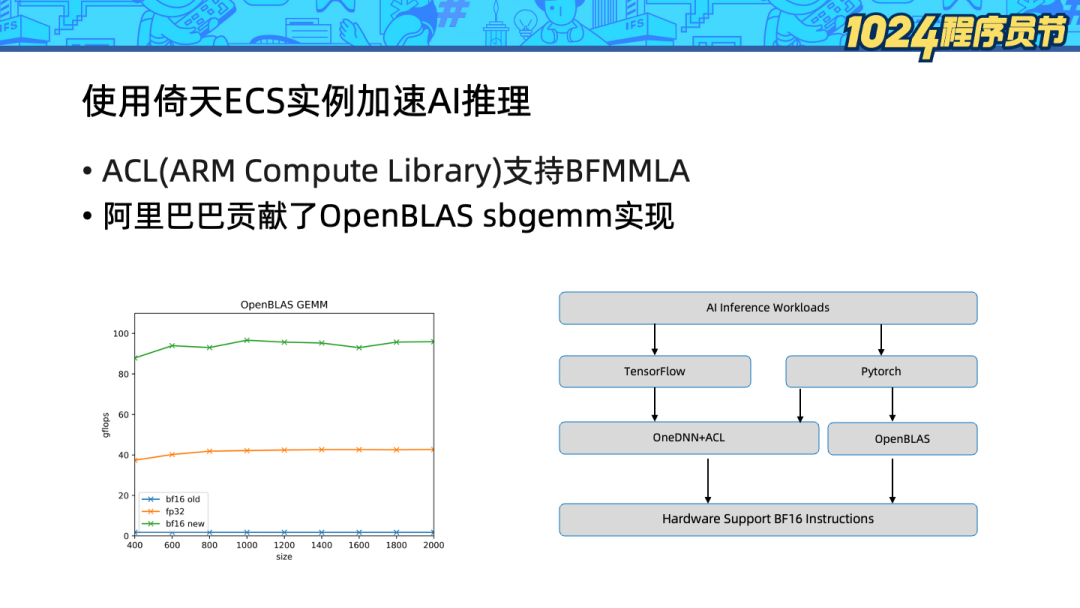
阿里巴巴向 OpenBLAS 項目貢獻了 sbgemm(s 表示返回單精度,b 表示輸入 bf16)的硬件加速實現,從 GEMM 吞吐上看,BF16 相比 FP32 GEMM 吞吐提升超過100%。
倚天 ECS 實例是市面上少數可以支持 bf16 指令擴展的 Arm服務器。目前已經支持了 Tensorflow 和 Pytorch 兩種框架的 AI 推理:
-
Tensorflow下可以通過OneDNN + ACL(Arm Compute Library)來使用BFMMLA 加速。
-
Pytorch 已經支持了 OneDNN + ACL,但是目前還在試驗狀態,無法很好地發揮性能。但是 Pytorch 同時支持 OpenBLAS 作為其計算后端,因此可以通過 OpenBLAS 來享受 ARM bf16 擴展帶來的性能收益。

可以看到相比默認的 eigen 實現,開啟 OneDNN + ACL 后,perf 獲得的計算熱點已經從 fmla(向量乘加)轉換到了 bfmmla,算力顯著提升。
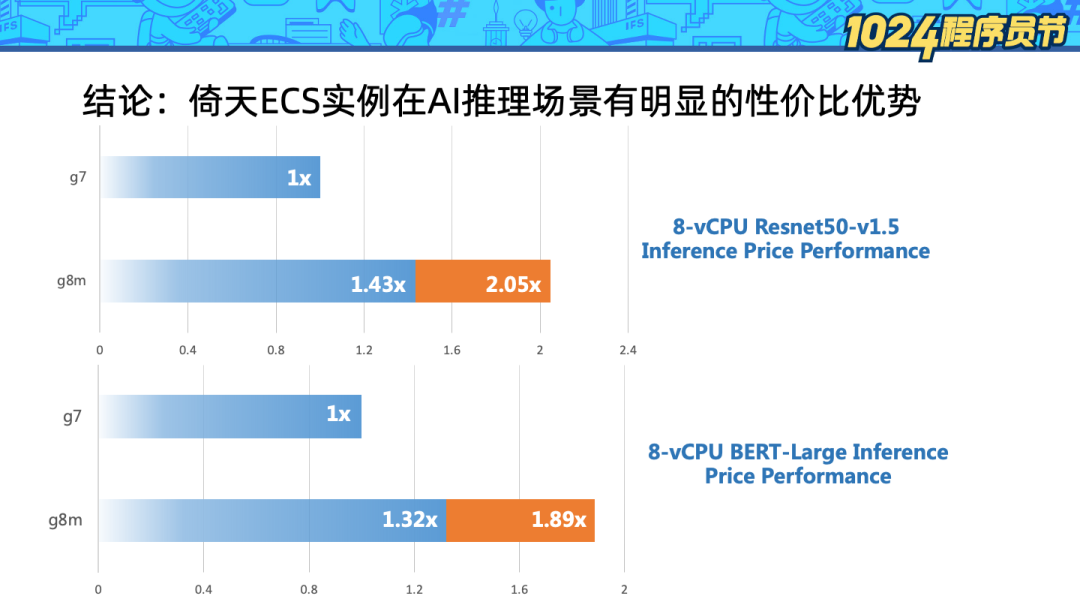
從 workload 角度評測,上圖對比了兩種機型:
-
g7:Intel IceLake 實例。
-
g8m:倚天 Arm 服務器。
左邊柱狀圖中藍色柱子表示算力對比,橙色柱子表示考慮性價比后使用倚天處理器獲得的收益。可以看到在 Resnet50和 BERT-Large 模型的推理場景下,軟件優化后的倚天處理器皆可獲得一倍左右的性價比收益。

在上文中,我們看到使用倚天處理器若想獲得較高收益,軟件版本的選擇十分重要。隨意選擇 tensorflow 或者 Pytorch 包可能遭遇:
- 未適配 Arm 架構,安裝失敗。
- 軟件未適配 bf16 擴展或者環境參數有誤,無法發揮硬件的全部算力,性能打折。
-
需要精心選擇計算后端,例如目前 Pytorch 下 OpenBLAS 較快。
因此我們提供了 Docker 鏡像,幫助云上的用戶充分使用倚天 710 處理器的 AI 推理性能:
-
accc-registry.cn-hangzhou.cr.aliyuncs.com/tensorflow/tensorflow
- accc-registry.cn-hangzhou.cr.aliyuncs.com/pytorch/pytorch
通過 Serverless 能力充分釋放算力
除了使能更多的硬件指令,另一種充分釋放硬件算力的方式就是通過 Serverless 架構提高 CPU 利用率。Python 作為動態語言,其模塊是動態導入的,因此啟動速度不是 Python 的強項,這也制約了 Python workload 在 Serverless 場景的普及。

3、執行代碼對象。
其中的第二步在首次加載模塊時,要對 .py 文件進行編譯,獲得 code_object, 為了降低將來加載的開銷,Python 解釋器會序列化并緩存 code_object 到 .pyc 文件。
即便模塊導入過程已經通過緩存機制優化過了,但是讀取 .pyc 文件并反序列化依舊比較耗時。
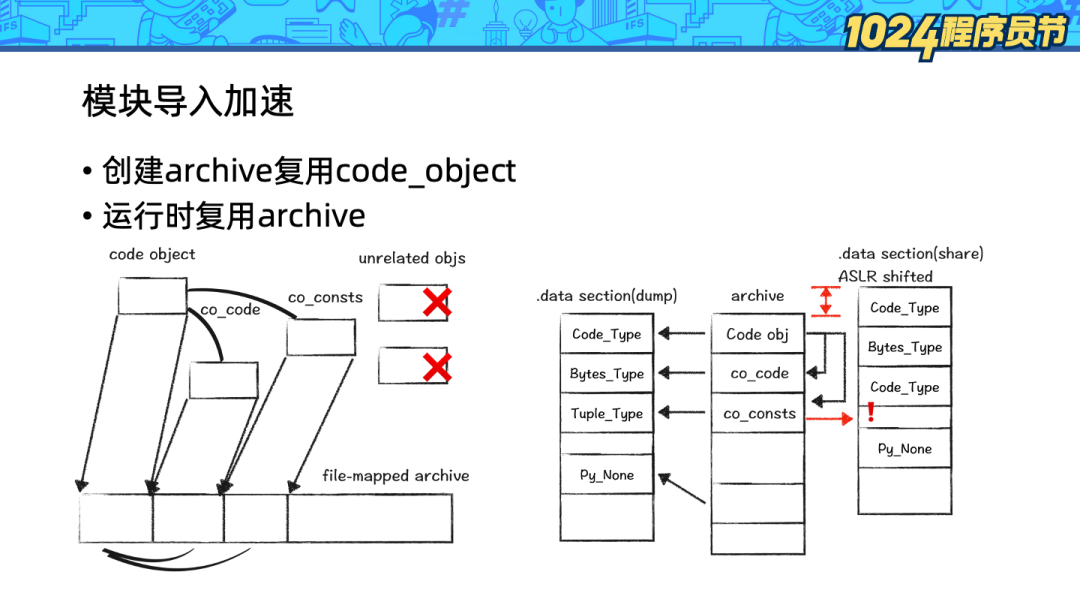
在這里我們借助了 OpenJDK 的 AppCDS 的思路:將 heap 上的 code_object 復制到內存映射文件中(mmap)。在下次加載模塊時,直接使用 mmap 中的 code_object。
這種框架下有兩個難點:
1、Python 的 code_object 是散落在 heap 的各處且不連續的,因此 mmap 復制整個 heap 是行不通的。我們采用的方式是以 code_object 為根,遍歷對象圖,對感興趣的內容復制并緊湊排布。
2、Python 的 code_object 會引用 .data 段的變量,在 Linux 的隨機地址安全機制下,.data 段的數據的地址在每次運行時都會隨機變化,這樣 mmap 中的指針就失效了。我們的解決方式是遍歷所有對象,針對 .data 段的指針進行偏移量修復。
因為該項目共享了 Python 的 code_object,因此名字是 code-data-share-for-python,簡稱 pycds。
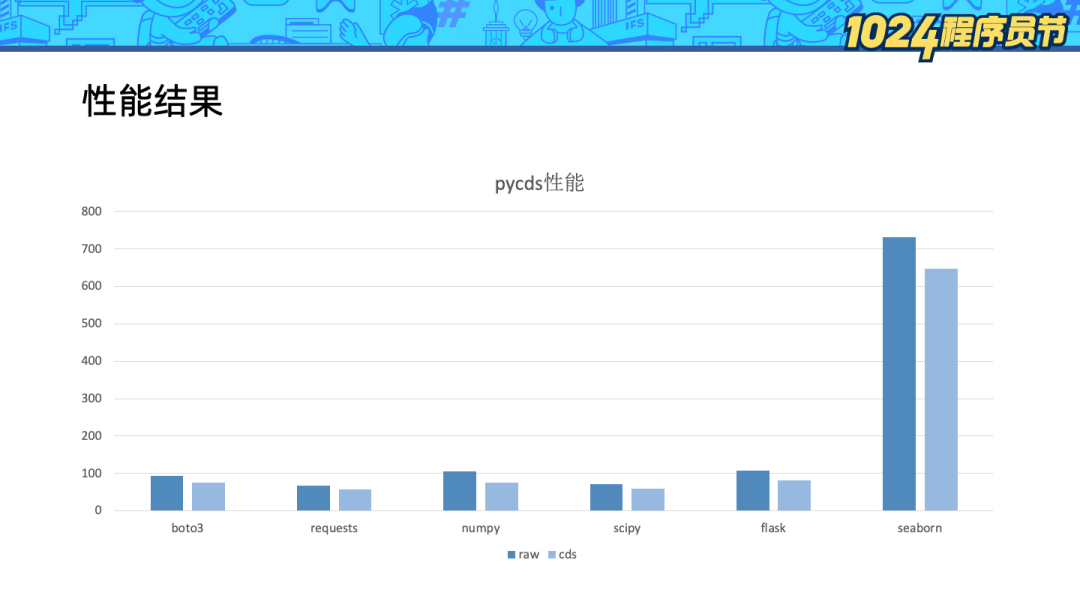
我們測試了 bota3、numpy、flask 等常用的 Python 庫,平均可以節省 20% 的模塊導入耗時。
對于現有的 Python 應用可以輕易地使用 pycds,且無需修改任何代碼:
# 安裝pycds
pip install code-data-share # 安裝pycds
# 生成模塊列表
PYCDSMODE=TRACE PYCDSLIST=mod.lst python -c 'import numpy’
# 生成 archive
python -c 'import cds.dump; cds.dump.run_dump("mod.lst", "mod.img")’
# 使用archive
time PYCDSMODE=SHARE PYCDSARCHIVE=mod.img python -c 'import numpy'
real 0m0.090s
user 0m0.180s
sys 0m0.339s
# 對比基線
time python -c 'import numpy'
real 0m0.105s
user 0m0.216s
sys 0m0.476s
我們僅僅通過安裝 PyPI,修改環境變量運行和使用 cdsAPI 做 dump 即可對現有的應用啟動進行加速了。
code-data-share-for-python 是一個新項目,需要大家的參與和反饋,歡迎通過以下鏈接了解和使用:
https://github.com/alibaba/code-data-share-for-python
https://pypi.org/project/code-data-share-for-python
ARM 架構 SIG鏈接地址:
https://openanolis.cn/sig/ARM_ARCH_SIG
審核編輯 :李倩
-
ARM
+關注
關注
134文章
9311瀏覽量
375130 -
神經網絡
+關注
關注
42文章
4809瀏覽量
102825 -
算力
+關注
關注
2文章
1148瀏覽量
15459
原文標題:技術解讀倚天 ECS 實例——Arm 芯片的 Python-AI 算力優化 | 龍蜥技術
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
存算一體大算力AI芯片將逐漸走向落地應用
大算力芯片的生態突圍與算力革命
DeepSeek推動AI算力需求:800G光模塊的關鍵作用
ECS控制臺實例搜索的優化與改進
解讀最佳實踐:倚天 710 ARM 芯片的 Python+AI 算力優化
IBM全新AI芯片設計登上Nature,解決GPU的算力瓶頸
昆侖芯AI芯片以AI算力服務實體經濟 筑底算力經濟新基建
云端算力芯片為什么是科技石油?
ai芯片和算力芯片的區別
阿里云倚天實例已為數千家企業提供算力,性價比提升超30%







 工商網監
工商網監
評論