") 大模型AI興起:新一輪芯片、服務(wù)器、智算等浪潮來襲
大模型AI興起:新一輪芯片、服務(wù)器、智算等浪潮來襲
AI需要多元異構(gòu)算力提供支持,拉動AI芯片需求。人工智能算法需要從海量的圖像、語音、視頻等非結(jié)構(gòu)化數(shù)據(jù)中挖掘信息。從大模型的訓(xùn)練、場景化的微調(diào)以及推理應(yīng)用場景,都需要算力支撐。而以CPU為主的通用計算能力已經(jīng)無法滿足多場景的AI需求。以CPU+AI芯片(GPU、FPGA、ASIC)提供的異構(gòu)算力,并行計算能力優(yōu)越、具有高互聯(lián)帶寬,可以支持AI計算效力實現(xiàn)最大化,成為智能計算的主流解決方案。
服務(wù)器中的CPU和AI卡的數(shù)量并不固定,會根據(jù)客戶應(yīng)用需求調(diào)整,對于AI服務(wù)器來講,較為常見的是配備2個CPU,以及八個AI卡。而相比于AI服務(wù)器,傳統(tǒng)的通用服務(wù)器則以CPU為主。因此,AI的發(fā)展將極大拉動GPGPU、TPU、NPU等AI芯片的需求。
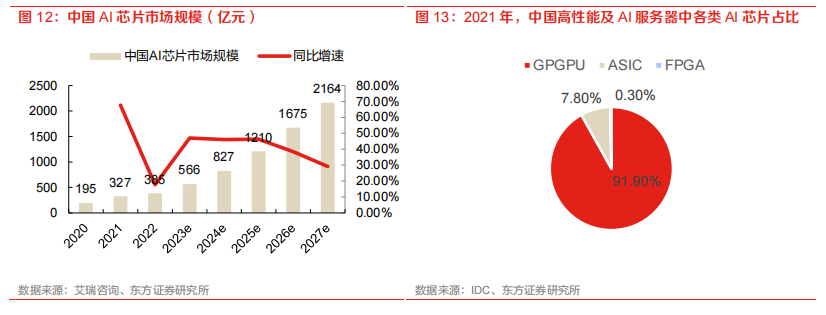
AI 計算需要多元異構(gòu)算力提供支持,將極大拉動GPGPU、AISC 等 AI 芯片的需求。中國 AI 芯片市場規(guī)模有望快速增長,據(jù)艾瑞咨詢發(fā)布的《2022 年中國人工智能產(chǎn)業(yè)研究報告(Ⅴ)》,預(yù)計 2027 年達到 2164 億元。
中國AI芯片市場將保持高速增長,AI推理芯片份額有望持續(xù)提升,國產(chǎn)化AI芯片占比有望提升。2022年,中國的AI芯片市場規(guī)模約385億元。隨著AI發(fā)展以及智算中心建設(shè)浪潮,該市場預(yù)計將保持高增長趨勢。據(jù)艾瑞咨詢測算,到2027年,中國的AI芯片市場規(guī)模預(yù)計將達到2164億元。另外,在我國高性能及AI服務(wù)器中,GPGPU憑借其優(yōu)秀的性能和通用能力占比92%,剩下份額由AISC和FPGA分享。隨著AI模型的優(yōu)化落地,AI推理芯片的占比將日益提升。據(jù)艾瑞咨詢,2022年,中國AI訓(xùn)練芯片以及AI推理芯片的占比分別為47.2%和52.8%。
AI芯片領(lǐng)域的三類玩家。大模型的訓(xùn)練需要大規(guī)模的訓(xùn)練數(shù)據(jù)以及強大的計算資源,需要多卡多機協(xié)同完成。這對AI芯片本身的性能,以及多卡多機的互聯(lián)提出了很高的要求。目前,在AI芯片領(lǐng)域,有三類玩家。一種是以Nvidia、AMD為代表的實力強勁的老牌芯片巨頭,這些企業(yè)積累了豐富的經(jīng)驗,產(chǎn)品性能突出。
另一種是以Google、百度、華為為代表的云計算巨頭,這些企業(yè)紛紛布局通用大模型,并自己開發(fā)了AI芯片、深度學(xué)習(xí)平臺等支持大模型發(fā)展。如google的TensorFlow以及TPU,華為的鯤鵬昇騰、CANN及Mindspore。
最后是一些小而美的AI芯片獨角獸,如寒武紀、壁仞等。
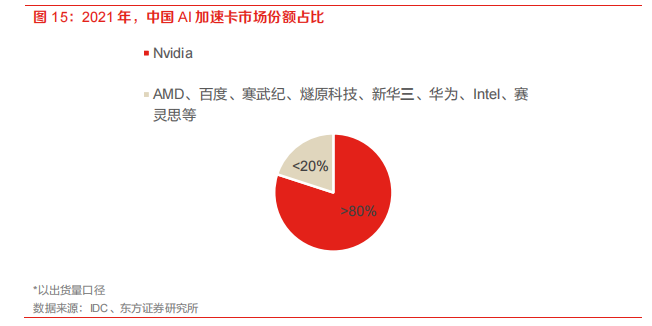
英偉達占據(jù)80%以上中國加速卡市場份額,國產(chǎn)AI芯片亟待發(fā)展。根據(jù)IDC的數(shù)據(jù)顯示,2021年中國加速卡的出貨數(shù)量已經(jīng)超過80萬片,其中Nvidia占據(jù)了超過80%的市場份額。剩下的份額有AMD、百度、寒武紀、燧原科技、新華三、華為、Intel和賽靈思等品牌。
1、英偉達:全球GPU龍頭
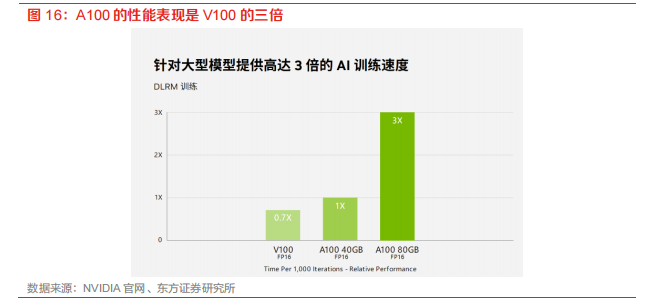
英偉達占據(jù)芯片市場絕對優(yōu)勢。長期以來,英偉達在高端GPU市場占據(jù)絕對主導(dǎo)地位,現(xiàn)如今已量產(chǎn)的主流A100芯片相比前代產(chǎn)品V100,性能得到顯著提高,代表當今高端芯片水平。最新一代H100芯片也已經(jīng)亮相,即將量產(chǎn)。天數(shù)智芯數(shù)據(jù)顯示,2021年英偉達在中國云端AI訓(xùn)練芯片市場的份額達到90%。據(jù)IDC,在2021年中國出貨的80多萬張加速卡中,英偉達占據(jù)超過80%份額。芯片的研發(fā)周期較長,英偉達具有絕對先行優(yōu)勢,雖然目前國內(nèi)企業(yè)突破英偉達壟斷仍然任重道遠,但寒武紀、華為AI芯片快速發(fā)展,有望逐步進行國產(chǎn)替代。
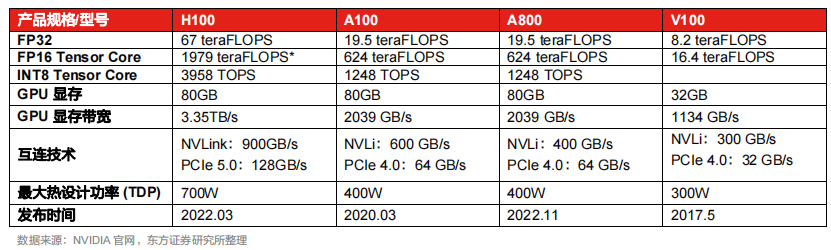
受制裁影響,英偉達對部分產(chǎn)品性能進行 “閹割”,推出“中國版芯片”A800、H800。2022年10月,美國發(fā)布了針對中國的先進計算與半導(dǎo)體產(chǎn)品的出口管制,限制美國企業(yè)向中國出口先進高端芯片設(shè)備。在新管制的限制下,英偉達的A100、H100被禁止售賣給中國,而采用12nm工藝、性能較低的V100 GPU芯片不在管控之列。針對此次制裁,英偉達對A100的部分性能進行“閹割”,推出A800。
相比于A100,A800在單卡計算性能上沒有差別,但是互聯(lián)帶寬從600GB/s下降到了400GB/s,在一定程度上影響了如大模型訓(xùn)練等多卡互聯(lián)場景的性能。目前,A800已實現(xiàn)量產(chǎn),并在中國規(guī)模化落地應(yīng)用。英偉達還推出了旗艦芯片H100的替代版H800,目前還未量產(chǎn)。
2、海光信息:國產(chǎn)高性能CPU和GPGPU領(lǐng)軍企業(yè)
海光信息專注于研發(fā)、設(shè)計和銷售高端處理器(CPU以及GPGPU),持續(xù)技術(shù)創(chuàng)新、產(chǎn)品迭代。海光信息的主要產(chǎn)品為應(yīng)用于服務(wù)器和工作站等設(shè)備中的通用處理器(CPU)和協(xié)處理器(DCU,即GPGPU)。海光處理器性能出眾,同時軟硬件生態(tài)豐富、工具鏈完整、應(yīng)用遷移成本低。另外,海光CPU與DCU雖脫胎于AMD,但經(jīng)過多年獨立自主研發(fā)迭代,已經(jīng)實現(xiàn)自主可控、安全可靠,是***之光。目前,蘇州昆山、成都等多地超算中心已經(jīng)搭載海光CPU與DCU,為社會提供優(yōu)質(zhì)算力。
海光CPU一、二代均已商業(yè)化, 三代初亮相,四代有序研發(fā)中。海光DCU一代已商業(yè)化應(yīng)用,二代研發(fā)中。公司持續(xù)技術(shù)創(chuàng)新和演進,堅持走“銷售一代, 驗證一代, 研發(fā)一代”的產(chǎn)品開發(fā)策略。公司建立了完善的高端處理器的研發(fā)環(huán)境和流程,持續(xù)開發(fā)多代產(chǎn)品,產(chǎn)品性能不斷提高,同時功能不斷完善豐富。海光CPU的四代產(chǎn)品中,海光一號和海光二號均實現(xiàn)了商業(yè)化應(yīng)用,海光三號已亮相發(fā)布會,海光四號處于研發(fā)階段。海光DCU于2018年啟動DCU第一代產(chǎn)品深算一號的產(chǎn)品研發(fā),于2020年1月啟動了深算二號的研發(fā),截至2022年6月,深算一號已實現(xiàn)商業(yè)化應(yīng)用。
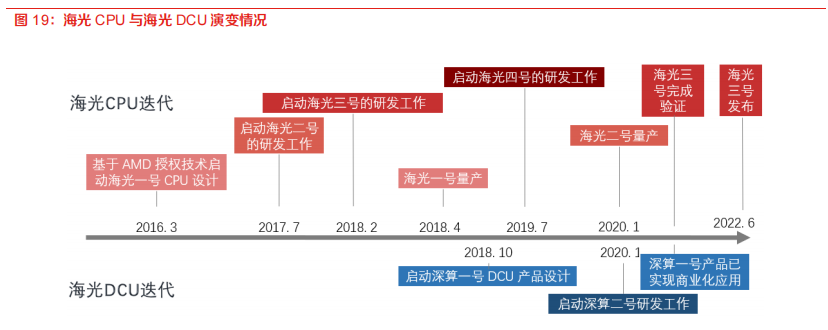
海光DCU某些硬件性能與英偉達的A100、AMD的MI100相近。海光DCU雙精度計算能力突出。據(jù)北京大學(xué)高性能計算系統(tǒng)中標公告(HCZB-2021-ZB0364),海光信息的DCU Z100的通用計算核心達到8192個。其關(guān)鍵性能指標實現(xiàn):FP64 10.8TFlops,顯存32GB HBM2,對比全球芯片巨頭的高端AI芯片不遑多讓。英偉達A100的相關(guān)指標為:FP64 9.7 TFlops、顯存40/80GB HBM2。AMD MI100的相關(guān)指標為:FP64 11.5 TFlops、顯存32GB HBM2。

海光DCU生態(tài)豐富,工具鏈完整。海光的DCU脫胎于AMD,兼容主流生態(tài)——開源ROCmGPU計算生態(tài),支持TensorFlow、Pytorch和PaddlePaddle等主流深度學(xué)習(xí)框架、適配主流應(yīng)軟件。ROCm又被稱為類CUDA,現(xiàn)有CUDA上運行的應(yīng)用可以低成本遷移到基于ROCm的海光平臺上運行。
2022年,海光發(fā)布國內(nèi)首個全精度(FP64)異構(gòu)計算平臺,該平臺搭載CPU海光三號和DCU海光深算,涵蓋數(shù)值模擬、AI訓(xùn)練、AI推理所需的多樣算力,實現(xiàn)了智能計算與數(shù)值運算的深度融合。同時,此平臺可全面支持TensorFlow、PyTorch、Caffe2等主流AI深度學(xué)習(xí)框架,目前已超過1000種應(yīng)用軟件部署在該平臺上。
3、寒武紀:國產(chǎn)AI芯片先行者
寒武紀始終深耕芯片研發(fā),不斷推陳出新、實現(xiàn)技術(shù)進步。寒武紀成立于2016年,專注人工智能芯片產(chǎn)品的研發(fā)與創(chuàng)新。公司成立之初便開始了對AI芯片領(lǐng)域的探索創(chuàng)新。并在2016年年底成功研發(fā)出全球首款A(yù)I手機芯片——寒武紀1A。2017年,這款芯片被搭載于華為的高端系統(tǒng)級芯片麒麟970,應(yīng)用于Mate10手機,并獲得了廣泛好評。芯片可以在功耗極低的前提下,涵蓋人臉識別、語音識別、圖像增強等多種功能。此后,寒武紀又陸續(xù)推出了多款A(yù)I芯片產(chǎn)品,包括云端訓(xùn)練芯片MLU100、邊緣推理芯片MLU270、車載推理芯片MLU290等 。這些產(chǎn)品都具有高性能、低功耗、高集成度等特點,在圖像識別、語音識別、自然語言處理等領(lǐng)域都有著優(yōu)異的表現(xiàn)。
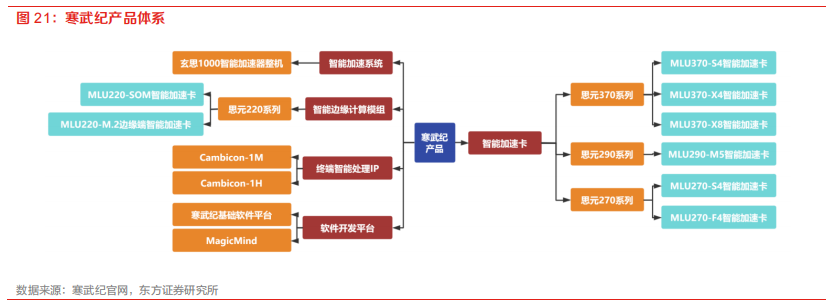
思元370是寒武紀的首款訓(xùn)練推理一體芯片,也是其云端產(chǎn)品的第三代。思元370采用了7nm制程工藝,并成為首款采用Chiplet技術(shù)的人工智能芯片。該芯片最大算力可達256TOPS(INT8),是上一代云端推理產(chǎn)品思元270算力的兩倍,同時該芯片還支持LPDDR5內(nèi)存,內(nèi)存帶寬是270的三倍,因此可以在板卡有限的功耗范圍內(nèi)為人工智能芯片分配更多的能源,從而輸出更高的算力。思元370智能芯片還采用了先進的Chiplet技術(shù),支持靈活的芯粒組合,僅用單次流片便可以實現(xiàn)多款智能加速卡產(chǎn)品的商用。目前,該公司已推出三款加速卡:MLU370-S4、MLU370-X4和MLU370-X8,包含應(yīng)用于計算密度高的數(shù)據(jù)中心、針對專注人工智能推理相關(guān)業(yè)務(wù)的互聯(lián)網(wǎng)廠商需求和應(yīng)用于對算力帶寬要求高的訓(xùn)練任務(wù),滿足用戶的多樣化需求。
新一代訓(xùn)練芯片寒武紀590還未量產(chǎn),據(jù)悉訓(xùn)練能力突出。寒武紀最新一代云端智能訓(xùn)練芯片思元590還未正式發(fā)布,據(jù)寒武紀董事長在2022 WAIC上介紹,思元590采用全新的MLUarch05架構(gòu),實測訓(xùn)練性能較在售產(chǎn)品有了顯著提升。思元590可提供更大的內(nèi)存容量和更高的內(nèi)存帶寬,其PCIe接口也較上代實現(xiàn)了升級。
審核編輯 :李倩
-
芯片
+關(guān)注
關(guān)注
459文章
52129瀏覽量
435691 -
AI
+關(guān)注
關(guān)注
87文章
34114瀏覽量
275218 -
人工智能
+關(guān)注
關(guān)注
1804文章
48660瀏覽量
246190
原文標題:大模型AI興起:新一輪芯片、服務(wù)器、智算等浪潮來襲
文章出處:【微信號:架構(gòu)師技術(shù)聯(lián)盟,微信公眾號:架構(gòu)師技術(shù)聯(lián)盟】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論