") Segment Anything又能分辨類別了:Meta/UTAustin提出全新開放類分割模型
Segment Anything又能分辨類別了:Meta/UTAustin提出全新開放類分割模型
前幾日,Meta 推出了「分割一切」AI模型Segment Anything,令網(wǎng)友直呼 CV 不存在了?!而在另一篇被CVPR 2023 收錄的論文中,Meta、UTAustin 聯(lián)合提出了新的開放語言風(fēng)格模型(open-vocabulary segmentation, OVSeg),它能讓 Segment Anything 模型知道所要分隔的類別。
從效果上來看,OVSeg 可以與 Segment Anything 結(jié)合,完成細(xì)粒度的開放語言分割。比如下圖 1 中識別花朵的種類:sunflowers (向日葵)、white roses (白玫瑰)、 chrysanthemums (菊花)、carnations (康乃馨)、green dianthus (綠石竹)。

即刻體驗(yàn):https://huggingface.co/spaces/facebook/ov-seg
項(xiàng)目地址:https://jeff-liangf.github.io/projects/ovseg/
研究背景
開放式詞匯語義分割旨在根據(jù)文本描述將圖像分割成語義區(qū)域,這些區(qū)域在訓(xùn)練期間可能沒有被看到。最近的兩階段方法首先生成類別不可知的掩膜提案,然后利用預(yù)訓(xùn)練的視覺-語言模型(例如 CLIP)對被掩膜的區(qū)域進(jìn)行分類。研究者確定這種方法的性能瓶頸是預(yù)訓(xùn)練的 CLIP 模型,因?yàn)樗谘谀D像上表現(xiàn)不佳。
為了解決這個問題,研究者建議在一組被掩膜的圖像區(qū)域和它們對應(yīng)的文本描述的收集的數(shù)據(jù)上對 CLIP 進(jìn)行微調(diào)。研究者使用 CLIP 將掩膜圖像區(qū)域與圖像字幕中的名詞進(jìn)行匹配,從而收集訓(xùn)練數(shù)據(jù)。與具有固定類別的更精確和手動注釋的分割標(biāo)簽(例如 COCO-Stuff)相比,研究者發(fā)現(xiàn)嘈雜但多樣的數(shù)據(jù)集可以更好地保留 CLIP 的泛化能力。
除了對整個模型進(jìn)行微調(diào)之外,研究者還使用了被掩膜圖像中的「空白」區(qū)域,使用了他們稱之為掩膜提示微調(diào)的方法。
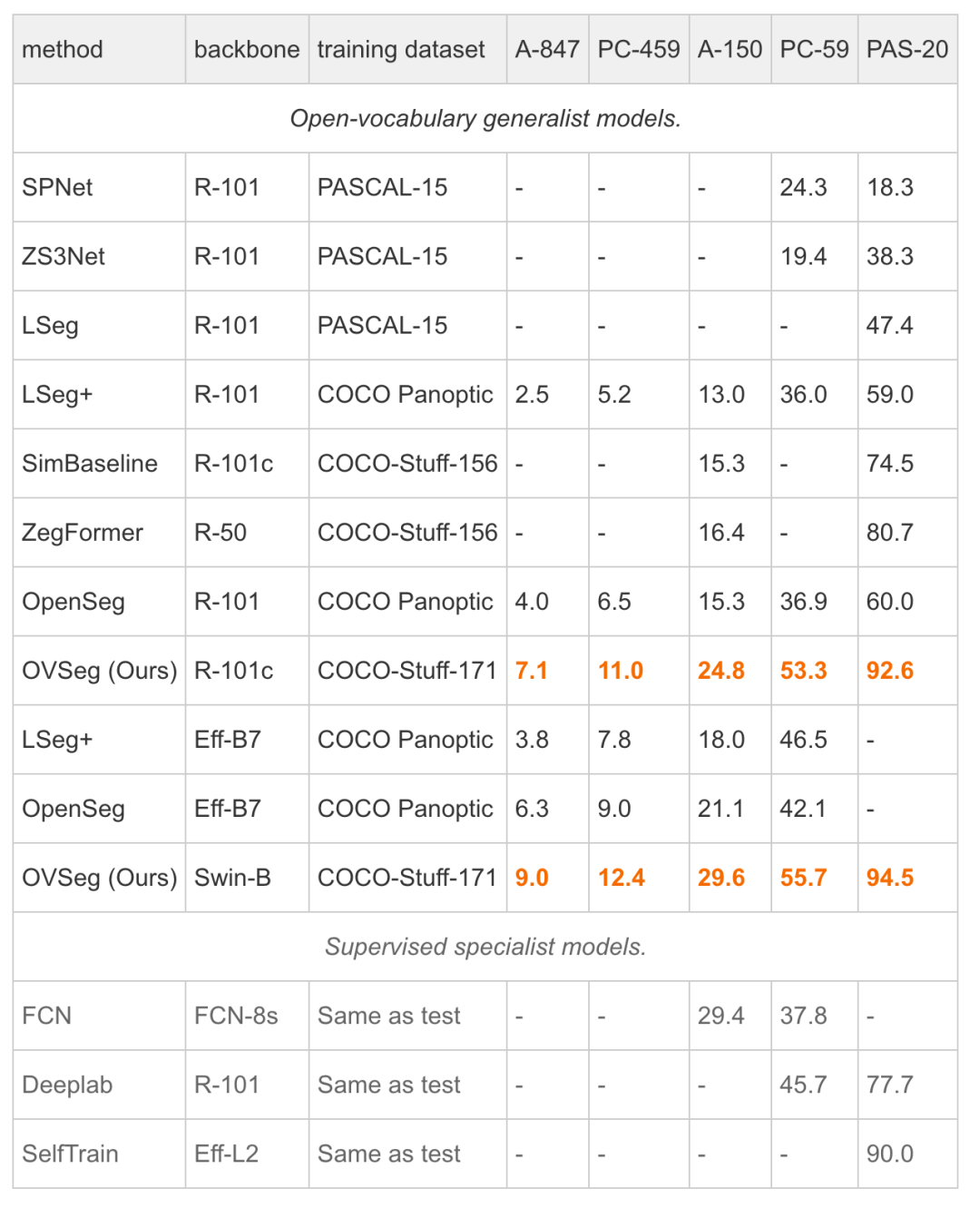
實(shí)驗(yàn)表明,掩膜提示微調(diào)可以在不修改任何 CLIP 權(quán)重的情況下帶來顯著的改進(jìn),并且它可以進(jìn)一步改善完全微調(diào)的模型。特別是當(dāng)在 COCO 上進(jìn)行訓(xùn)練并在 ADE20K-150 上進(jìn)行評估時,研究者的最佳模型實(shí)現(xiàn)了 29.6%的 mIoU,比先前的最先進(jìn)技術(shù)高出 8.5%。開放式詞匯通用模型首次與 2017 年的受監(jiān)督專家模型的性能匹配,而不需要特定于數(shù)據(jù)集的適應(yīng)。

論文地址:https://arxiv.org/pdf/2210.04150.pdf
論文解讀
動機(jī)
研究者的分析表明,預(yù)訓(xùn)練的 CLIP 在掩膜建議上表現(xiàn)不佳,成為兩階段方法的性能瓶頸。
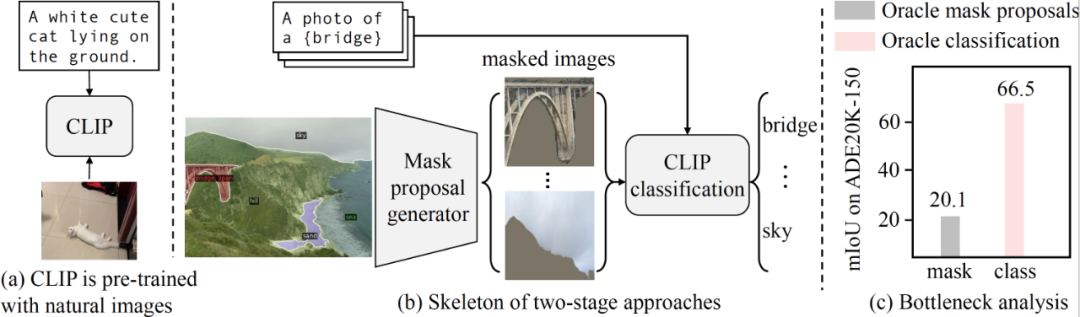
CLIP 是使用很少的數(shù)據(jù)增強(qiáng)在自然圖像上進(jìn)行預(yù)訓(xùn)練的。
兩階段的開放詞匯語義分割方法首先生成類別不可知的掩膜建議,然后利用預(yù)訓(xùn)練的 CLIP 進(jìn)行開放詞匯分類。CLIP 模型的輸入是裁剪的掩膜圖像,與自然圖像存在巨大的領(lǐng)域差距。
我們的分析表明,預(yù)訓(xùn)練的 CLIP 在掩膜圖像上表現(xiàn)不佳。
方法
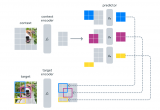
研究者的模型包括一個分割模型(例如 MaskFormer)和一個 CLIP 模型。
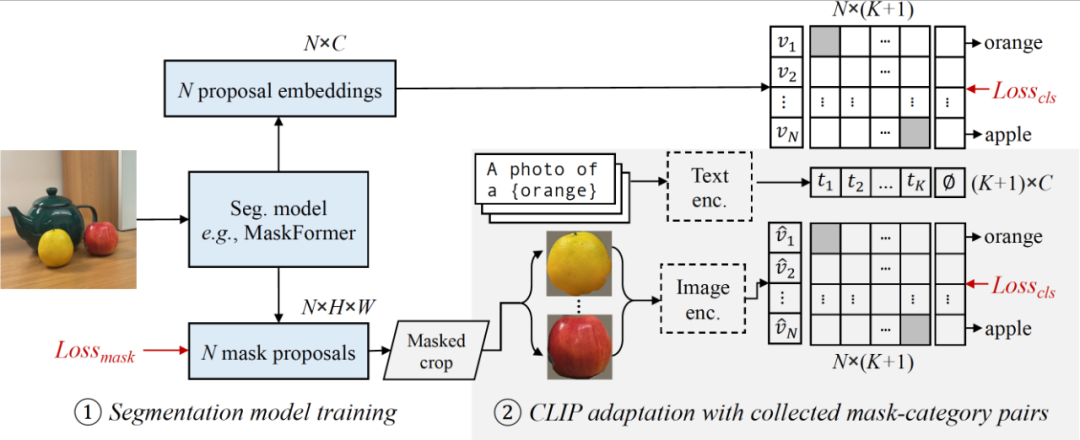
他們首先訓(xùn)練修改后的 MaskFormer 作為開放詞匯分割的基線(第 3.1 節(jié)),然后從圖像標(biāo)題中收集多樣的掩膜-類別對(第 3.2 節(jié)),并適應(yīng) CLIP 用于掩膜圖像(第 3.3 節(jié))。
結(jié)果
研究者首次展示開放詞匯的通用模型可以在沒有數(shù)據(jù)集特定調(diào)整的情況下與受監(jiān)督的專業(yè)模型的性能相匹配。
更多分類示例如下所示。


審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
41038 -
AI
+關(guān)注
關(guān)注
87文章
34294瀏覽量
275485 -
模型
+關(guān)注
關(guān)注
1文章
3488瀏覽量
50021
原文標(biāo)題:分割一切后,Segment Anything又能分辨類別了:Meta/UTAustin提出全新開放類分割模型
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何在SAM時代下打造高效的高性能計(jì)算大模型訓(xùn)練平臺
基于像素聚類進(jìn)行圖像分割的算法
通用AI大模型Segment Anything在醫(yī)學(xué)影像分割的性能究竟如何?
AI+制造業(yè):機(jī)器視覺開啟掘金新大陸
SAM分割模型是什么?
近期分割大模型發(fā)展情況

Segment Anything量化加速有多強(qiáng)!

分割一切?Segment Anything量化加速實(shí)戰(zhàn)
YOLOv8最新版本支持SAM分割一切

Meta開源I-JEPA,“類人”AI模型
基于 Transformer 的分割與檢測方法

ICCV 2023 | 超越SAM!EntitySeg:更少的數(shù)據(jù),更高的分割質(zhì)量






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論