") Meta是如何構(gòu)建新人工智能CICERO的?
Meta是如何構(gòu)建新人工智能CICERO的?

前段時(shí)間,Meta 正式發(fā)布人工智能 CICEROO——這是第一個(gè)在時(shí)下流行的戰(zhàn)略游戲 Diplomacy 中表現(xiàn)達(dá)到人類水平的人工智能。在 CICEROO 的背后,有哪些技術(shù)實(shí)踐?
本文最初發(fā)布于 Meta AI 官方博客。
長期以來,游戲一直是人工智能最新進(jìn)展的試驗(yàn)場——從深藍(lán)戰(zhàn)勝國際象棋大師 Garry Kasparov,到 AlphaGo 熟練掌握圍棋,再到 Pluribus 在撲克游戲中戰(zhàn)勝了人類高手。但真正有用的多功能代理不能局限于在棋盤上移動(dòng)棋子。我們能否建立更有效、更靈活的代理,使用語言進(jìn)行談判、說服,并與人合作,像人那樣實(shí)現(xiàn)戰(zhàn)略目標(biāo)?
日前,我們宣布了一項(xiàng)突破性進(jìn)展,向著構(gòu)建掌握這些技能的人工智能邁進(jìn)了重要的一步。我們已經(jīng)構(gòu)建了一個(gè)代理 CICERO——這是第一個(gè)在時(shí)下流行的戰(zhàn)略游戲 Diplomacy 中表現(xiàn)達(dá)到人類水平的人工智能。CICERO 在 webDiplomacy.net(該游戲的在線版本)上證明了這一點(diǎn),它的成績是人類玩家平均分的兩倍多,并且在玩過多個(gè)游戲的玩家中排名前 10%。
幾十年來,Diplomacy 一直被視為人工智能領(lǐng)域近乎不可能的重大挑戰(zhàn),因?yàn)樗笸婕艺莆樟私馑藙?dòng)機(jī)和觀點(diǎn)的藝術(shù);制定復(fù)雜的計(jì)劃并調(diào)整策略;然后用自然語言與他人達(dá)成協(xié)議,說服他們建立伙伴關(guān)系和聯(lián)盟,等等。CICERO 在使用自然語言與人進(jìn)行外交談判方面表現(xiàn)非得常出色,以至于玩家常常傾向于與 CICERO 而不是其他人類玩家合作。
與國際象棋和圍棋等游戲不同,Diplomacy 是一個(gè)關(guān)于人而不是棋子的游戲。如果代理無法辨別出某人可能在虛張聲勢,或者另一個(gè)玩家會(huì)認(rèn)為某一舉動(dòng)具有攻擊性,那么它很快就會(huì)輸?shù)粲螒颉M瑯樱绻荒芟裾嫒四菢诱f話——表現(xiàn)出同情心,建立關(guān)系,并對游戲有一定的了解——它就無法找到其他愿意與它合作的玩家。

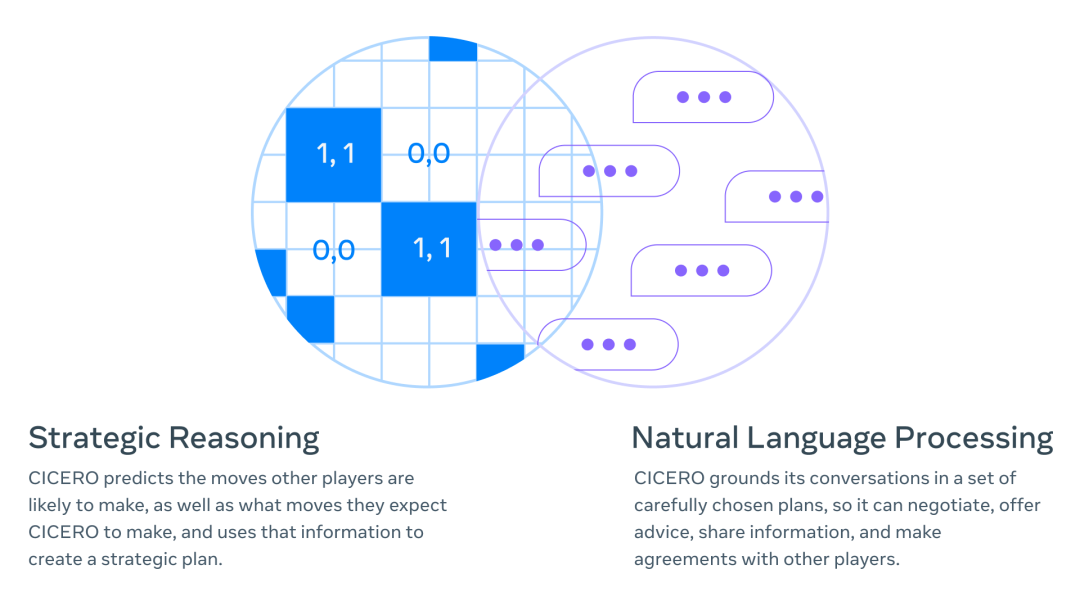
我們的主要成就是打通了兩個(gè)完全不同的人工智能研究領(lǐng)域并開發(fā)了新技術(shù):戰(zhàn)略推理(如 AlphaGo 和 Pluribus 等代理中使用的技術(shù))和自然語言處理(如 GPT-3、BlenderBot 3、LaMDA 和 OPT-175B 等模型中使用的技術(shù))。舉個(gè)例子,CICERO 可以推斷出,在游戲后期,它會(huì)需要特定玩家的支持,然后精心設(shè)計(jì)一個(gè)策略來贏得這個(gè)人的青睞——甚至可以識別出這個(gè)玩家從自己特定的視角所看到的風(fēng)險(xiǎn)和機(jī)會(huì)。
我們已經(jīng)將代碼開源,并發(fā)表了一篇論文,希望可以為更廣泛的人工智能社區(qū)帶來幫助,讓他們使用 CICERO 來推動(dòng)人類與人工智能的合作進(jìn)一步進(jìn)展。如果你想了解更多關(guān)于這個(gè)項(xiàng)目的信息,或者試用這個(gè)代碼,請移步 CICERO 的官網(wǎng)。感興趣的研究人員可以向 CICERO RFP 提交建議,獲取數(shù)據(jù)使用權(quán)。
我們是如何構(gòu)建 CICERO 的?
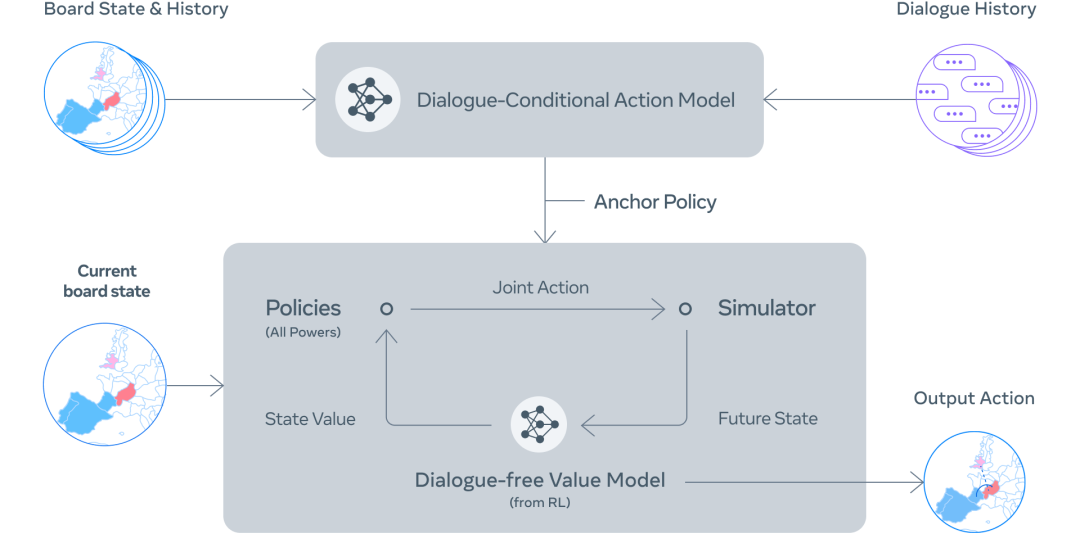
CICERO 的核心是一個(gè)可控的 Diplomacy 對話模型,外加一個(gè)策略推理引擎。在游戲中的每個(gè)時(shí)刻,CICERO 都會(huì)查看棋盤及其對話歷史,并對其他玩家可能采取的行動(dòng)建模。然后,它會(huì)用這個(gè)方案來控制一個(gè)可以生成自由對話的語言模型,告知其他玩家它的計(jì)劃,為其他玩家提出合理的行動(dòng)建議,與他們做好協(xié)調(diào)。
可控的對話
為了構(gòu)建一個(gè)可控的對話模型,我們從一個(gè)有 27 億參數(shù)的類似 BART 的語言模型開始,使用從互聯(lián)網(wǎng)上收集的文本對它進(jìn)行了預(yù)訓(xùn)練,然后使用 webDiplomacy.net 上超過 4 萬個(gè)人類游戲?qū)λM(jìn)行了優(yōu)化。我們開發(fā)了一些技術(shù),將訓(xùn)練數(shù)據(jù)中的信息與游戲中相應(yīng)的計(jì)劃動(dòng)作進(jìn)行自動(dòng)標(biāo)注,這樣,在推理時(shí)我們就可以控制對話的生成,討論代理和其對話伙伴所期望的具體行動(dòng)。
例如,如果我們的代理在扮演法國,在涉及英格蘭支持法國進(jìn)入勃艮第的計(jì)劃時(shí),對話模型可能會(huì)生成這樣一條信息發(fā)送給英格蘭,“嗨,英格蘭!你愿意支持我進(jìn)入勃艮第嗎?”以這種方式控制對話生成,可以使 CICERO 將對話建立在一套計(jì)劃之上,并隨著時(shí)間的推移完善和改進(jìn),以更好地進(jìn)行談判。這有助于代理更有效地協(xié)調(diào)和說服其他玩家。
第 1 步:使用棋盤狀態(tài)和當(dāng)前對話,CICERO 對每個(gè)人下一步會(huì)做什么做了一個(gè)初步預(yù)測。

第 2 步:CICERO 利用規(guī)劃反復(fù)完善該預(yù)測,然后利用這些預(yù)測為自己和合作伙伴形成一個(gè)意圖。
第 3 步:根據(jù)棋盤狀態(tài)、對話和意圖,生成幾條候選信息。
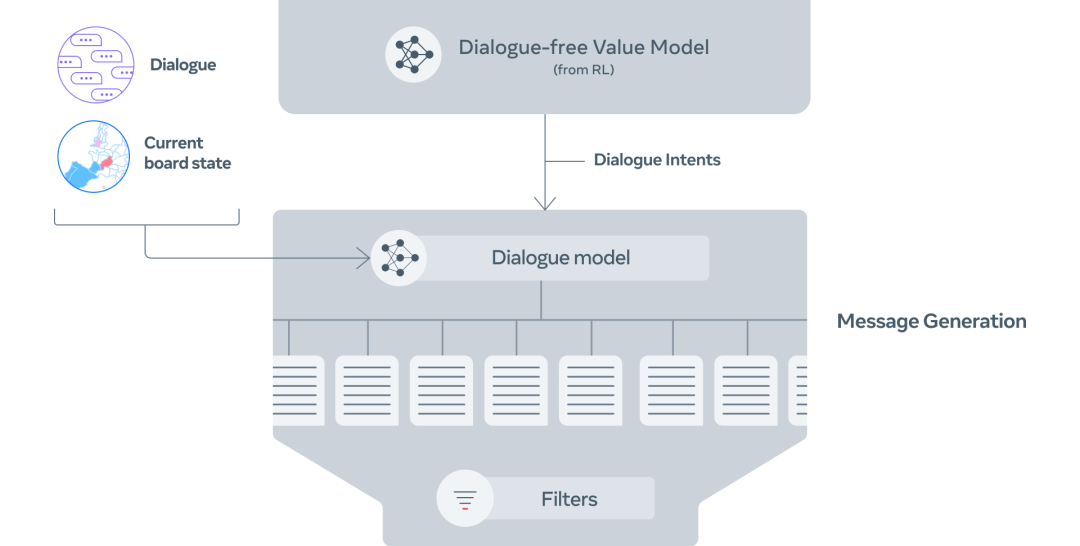
第 4 步:對候選信息進(jìn)行過濾,減少廢話,使價(jià)值最大化,并確保其符合意圖。
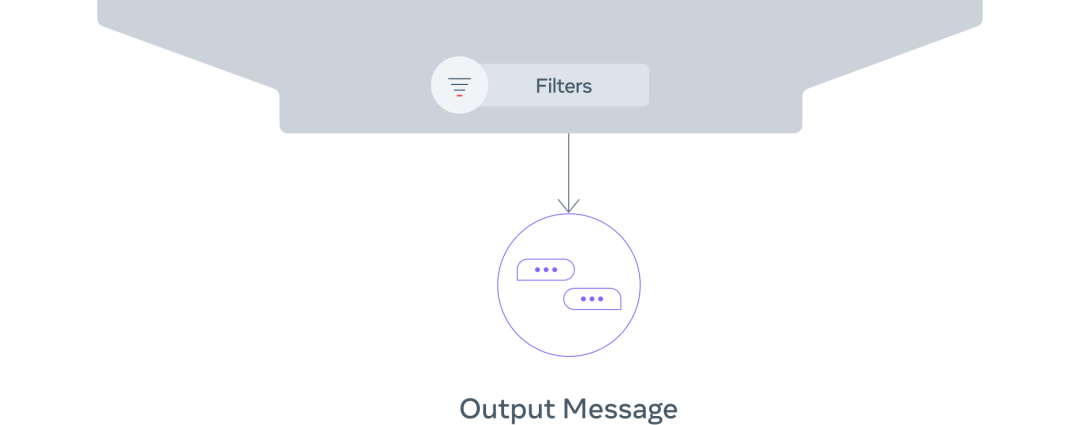
我們利用一些過濾機(jī)制——例如經(jīng)過訓(xùn)練的分類器來區(qū)分人類和模型生成的文本——來進(jìn)一步提高對話質(zhì)量,確保生成的對話是切合實(shí)際的,與當(dāng)前游戲狀態(tài)和之前的信息相一致,并且戰(zhàn)略上也合理。
對話感知策略 & 規(guī)劃
以前,在象棋、圍棋和撲克等對抗性游戲中的超人代理是通過自我強(qiáng)化學(xué)習(xí)(RL)創(chuàng)建的——讓代理與自身的其他副本進(jìn)行數(shù)百萬次對局來學(xué)習(xí)最佳策略。然而,涉及合作的游戲需要對人類在現(xiàn)實(shí)生活中的實(shí)際行為進(jìn)行建模,而不是對完美的機(jī)器人副本應(yīng)該做什么進(jìn)行建模。特別是,我們希望 CICERO 制定的計(jì)劃與它和其他玩家的對話一致。
人類建模的經(jīng)典方法是監(jiān)督學(xué)習(xí),即用帶標(biāo)簽的數(shù)據(jù)(如過去游戲中人類玩家的行動(dòng)數(shù)據(jù)庫)來訓(xùn)練代理。然而,純粹依靠監(jiān)督學(xué)習(xí)根據(jù)過去的對話結(jié)果來選擇行動(dòng),會(huì)導(dǎo)致代理的能力相對較弱,而且很容易被利用。例如,一個(gè)玩家可以告訴代理,“很高興我們能達(dá)成一致,你將把你的部隊(duì)從巴黎撤出!”由于類似的信息只有在達(dá)成協(xié)議時(shí)才會(huì)出現(xiàn)在訓(xùn)練數(shù)據(jù)中,所以代理可能真的會(huì)將其部隊(duì)調(diào)離巴黎,即使這樣做是一個(gè)明顯的戰(zhàn)略失誤。
為了解決這個(gè)問題,CICERO 會(huì)運(yùn)行一個(gè)迭代規(guī)劃算法,平衡對話的一致性和合理性。首先,代理會(huì)根據(jù)它與其他玩家的對話預(yù)測每個(gè)人在當(dāng)前回合的策略,同時(shí)也預(yù)測其他玩家會(huì)如何預(yù)測代理的策略。然后,它會(huì)運(yùn)行我們開發(fā)的名為 piKL 的規(guī)劃算法,根據(jù)其他玩家預(yù)測的策略選擇具有更高期望值的新策略來迭代改進(jìn)自己的預(yù)測,同時(shí)還會(huì)設(shè)法使新的預(yù)測接近于初始的策略預(yù)測。我們發(fā)現(xiàn),與單純的監(jiān)督學(xué)習(xí)相比,piKL 能更好地模擬人類游戲,幫代理選出更好的策略。

生成自然、有目的的對話
在 Diplomacy 中,玩家與他人的交談方式,甚至比他們移動(dòng)棋子的方式更重要。在與其他玩家一起制定策略時(shí),CICERO 能夠說出清晰而有說服力的話。例如,在一個(gè)演示游戲中,CICERO 要求一個(gè)玩家立即在棋盤的某個(gè)部分提供支持,同時(shí)向另一個(gè)玩家施加壓力,使其在后續(xù)的游戲中考慮結(jié)盟。
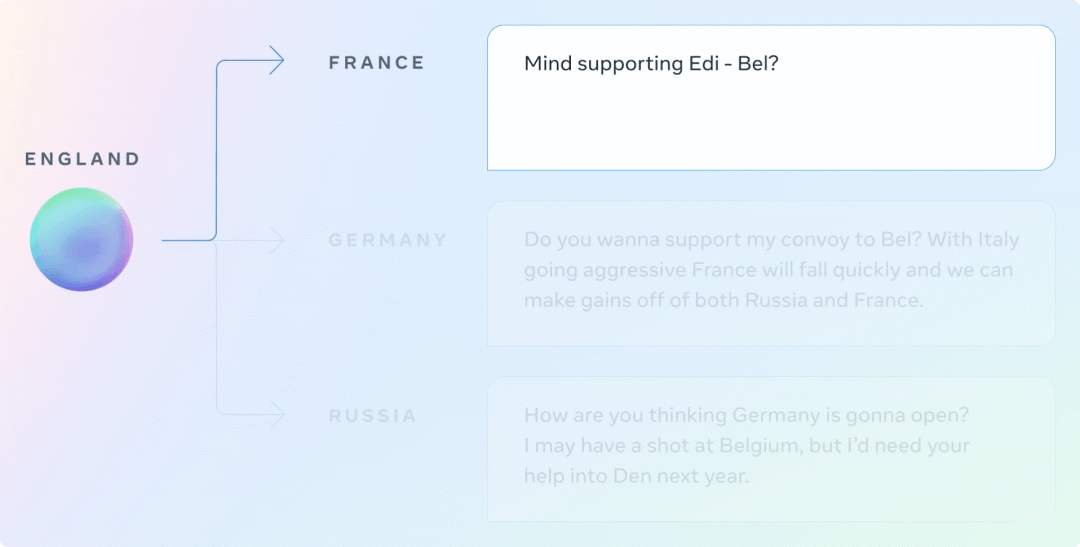
在這些交流中,CICERO 試圖通過向三個(gè)不同的玩家提供行動(dòng)建議來執(zhí)行其策略。在第二次對話中,代理能夠告訴其他玩家為什么他們應(yīng)該合作,以及合作如何對雙方有利。在第三次對話中,CICERO 既是在征集信息,也是在為未來的行動(dòng)打基礎(chǔ)。
哪里還有改進(jìn)空間?
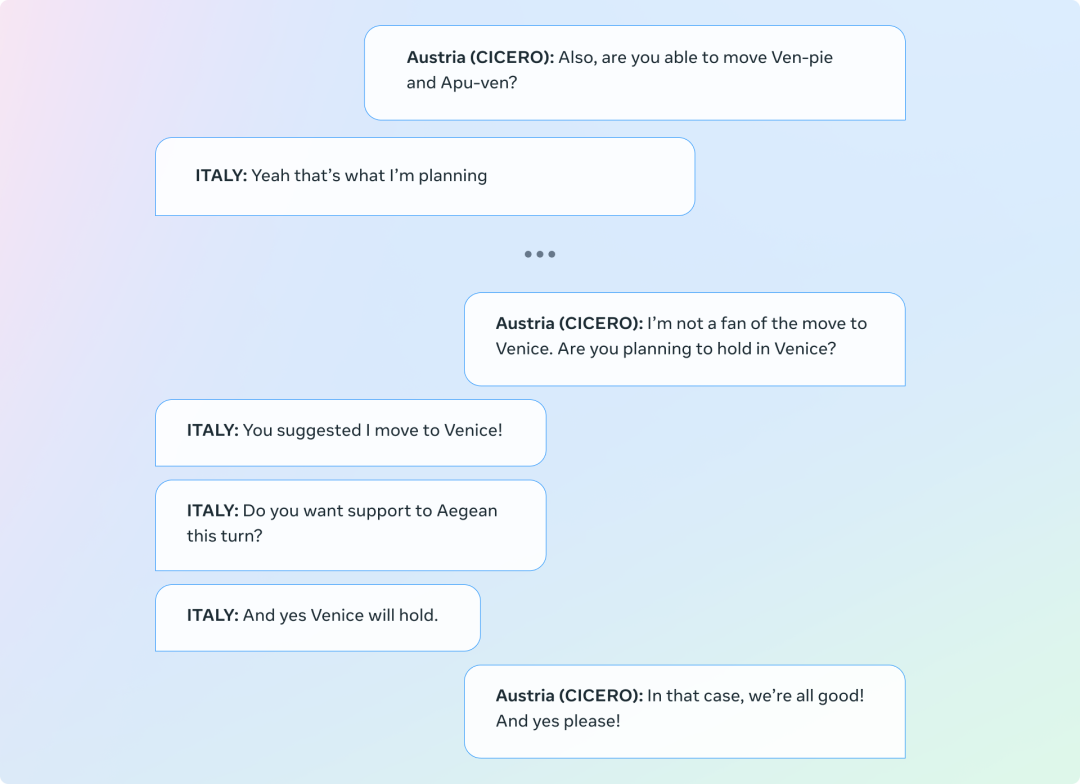
必須認(rèn)識到,CICERO 有時(shí)也會(huì)生成不一致的對話,妨礙目標(biāo)的達(dá)成。在下面的例子中,CICERO 扮演的是奧地利,它與自己的第一條信息(要求意大利移到威尼斯)前后矛盾了。雖然我們的過濾器套件就是用于檢測這類錯(cuò)誤,但它并不完美。
將 Diplomacy 作為促進(jìn) 人類與人工智能互動(dòng)的沙盒
在競合類游戲中,以目標(biāo)為導(dǎo)向的對話系統(tǒng)的出現(xiàn),對于協(xié)調(diào) AI 與人類的意圖和目標(biāo)提出了重要的社交和技術(shù)挑戰(zhàn)。Diplomacy 為研究這一問題提供了一個(gè)特別有趣的環(huán)境,因?yàn)橥嬗螒蛐枰谙嗷_突的目標(biāo)中艱難應(yīng)對,并將這些復(fù)雜的目標(biāo)翻譯成自然語言。舉個(gè)簡單的例子,玩家可能會(huì)為了維持一個(gè)盟友關(guān)系而選擇在短期利益上做出妥協(xié),目的是希望這個(gè)盟友能夠在下個(gè)回合中幫助他們?nèi)〉酶欣牡匚弧?/p>
雖然我們在這項(xiàng)工作中取得了重大的進(jìn)展,但是,將語言模型與具體意圖緊密結(jié)合的能力,以及確定這些意圖的技術(shù)(和規(guī)范)挑戰(zhàn),仍然是有待解決的重要問題。通過開放 CICERO 的源代碼,我們希望人工智能研究人員能夠基于我們的工作以負(fù)責(zé)任的方式繼續(xù)研究下去。通過使用我們的對話模型進(jìn)行零樣本分類,我們已經(jīng)在這個(gè)新領(lǐng)域中圍繞檢測和刪除有毒信息做了一些初步的工作。我們希望,Diplomacy 可以作為一個(gè)安全的沙盒來推進(jìn)人類與人工智能互動(dòng)的研究。
未來展望
雖然 CICERO 只會(huì)玩 Diplomacy 這個(gè)游戲,但這項(xiàng)成果背后的技術(shù)涉及到現(xiàn)實(shí)世界的許多應(yīng)用。比如,通過規(guī)劃和 RL 控制自然語言生成,減少人類和人工智能驅(qū)動(dòng)的代理之間的溝通障礙。再比如,如今的人工智能助手只擅長回答簡單的問題,如告訴你天氣,但如果他們能維持長時(shí)間的對話,并以教給你一個(gè)新技能為目標(biāo),那會(huì)怎樣?另外,想象有一個(gè)視頻游戲,其中的非玩家角色(NPC)可以像人一樣計(jì)劃和交談——理解你的動(dòng)機(jī)并相應(yīng)地調(diào)整對話——以幫助你完成攻打城堡的任務(wù)。
我們非常看好這些領(lǐng)域未來的發(fā)展?jié)摿Γ蚕M梢钥吹狡渌嘶谖覀兊难芯块_展進(jìn)一步的工作。
審核編輯 :李倩
-
人工智能
+關(guān)注
關(guān)注
1805文章
48932瀏覽量
248267 -
語言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10747
原文標(biāo)題:能與人類談判、游戲水平媲美真人,Meta 是如何構(gòu)建新人工智能 CICERO 的?
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論