") 大規(guī)模推理時(shí)代深度學(xué)習(xí)加速的天花板在哪?
大規(guī)模推理時(shí)代深度學(xué)習(xí)加速的天花板在哪?
從數(shù)據(jù)分析、經(jīng)典機(jī)器學(xué)習(xí)到搜索、推薦,再到語(yǔ)言處理和圖像識(shí)別,每個(gè) AI 任務(wù)運(yùn)行的背后都需要海量的數(shù)學(xué)計(jì)算。可以說(shuō),AI 真的就是數(shù)學(xué),但卻是很多很多的數(shù)學(xué)。 尤其是在 AI 進(jìn)入大模型時(shí)代的當(dāng)下,模型的大規(guī)模訓(xùn)練和推理更是對(duì)計(jì)算資源有著巨大的需求。但同時(shí),算力的掣肘正在阻礙著 AI 走向大規(guī)模落地。 當(dāng)前 AI 面臨的“數(shù)學(xué)題”都是何種難度?“算珠”又該如何撥弄得更快才能追得上不斷增長(zhǎng)的計(jì)算需求呢? 讓我們從 CPU 的 AI 算力談起。
1
大規(guī)模推理時(shí)代
深度學(xué)習(xí)加速的天花板在哪?
人工智能迎來(lái)第三次浪潮后,以深度學(xué)習(xí)為代表的AI已經(jīng)進(jìn)入應(yīng)用階段。而深度學(xué)習(xí) AI 需要進(jìn)行大量矩陣乘法以訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型,并利用推理將這些模型應(yīng)用于實(shí)際任務(wù)。
也就是說(shuō),深度學(xué)習(xí)分為訓(xùn)練和推理兩個(gè)階段,而推理則是推動(dòng)AI大規(guī)模走向落地的關(guān)鍵。
訓(xùn)練深度學(xué)習(xí)模型可能需要數(shù)小時(shí)或數(shù)天的算力。而深度學(xué)習(xí)推理可能需要幾分之一秒到幾分鐘,具體取決于模型的復(fù)雜程度和對(duì)結(jié)果的準(zhǔn)確度的要求。在推理過(guò)程中,計(jì)算機(jī)將輸入數(shù)據(jù)與模型進(jìn)行比較,然后推斷數(shù)據(jù)的含義。
讓人工智能落地更多是推理層面的工作,無(wú)論是推薦引擎、圖像識(shí)別、媒體分析、語(yǔ)言翻譯 、自然語(yǔ)言處理、強(qiáng)化學(xué)習(xí)等負(fù)載中推理性能的大幅提升對(duì)落地應(yīng)用的貢獻(xiàn)都十分重要。
在此背景下,硬件架構(gòu)將成為AI落地的重中之重。
而做大規(guī)模推理,CPU平臺(tái)具有較大優(yōu)勢(shì)——用戶(hù)學(xué)習(xí)門(mén)檻低、部署速度快等,在類(lèi)似推薦系統(tǒng)的應(yīng)用中,CPU也擔(dān)當(dāng)著算力支撐,那么如何提升CPU的AI算力?
CPU的算力取決于 CPU 特定加速指令集或運(yùn)算單元的持續(xù)引入及改進(jìn),那么通過(guò)強(qiáng)化算力單元和增加算力單元數(shù)量并舉,即Scale-Up與Scale-Out相結(jié)合,提升CPU的AI算力。
回望英特爾歷代至強(qiáng) 可擴(kuò)展處理器的深度學(xué)習(xí)加速技術(shù)(即DL Boost),已經(jīng)將這一提升路徑充分實(shí)踐并拉高優(yōu)化天花板:從第一代至強(qiáng)可擴(kuò)展處理器引入的AVX-512——中低端型號(hào)每核心配備1個(gè)FMA單元、高端型號(hào)每核心配備2個(gè)FMA單元,到代號(hào)Ice Lake-SP的雙路第三代至強(qiáng)可擴(kuò)展處理器將此類(lèi)配置擴(kuò)展到全系列產(chǎn)品,并將最高核心數(shù)從28增加至40個(gè),CPU的向量處理能力得以大幅提升。
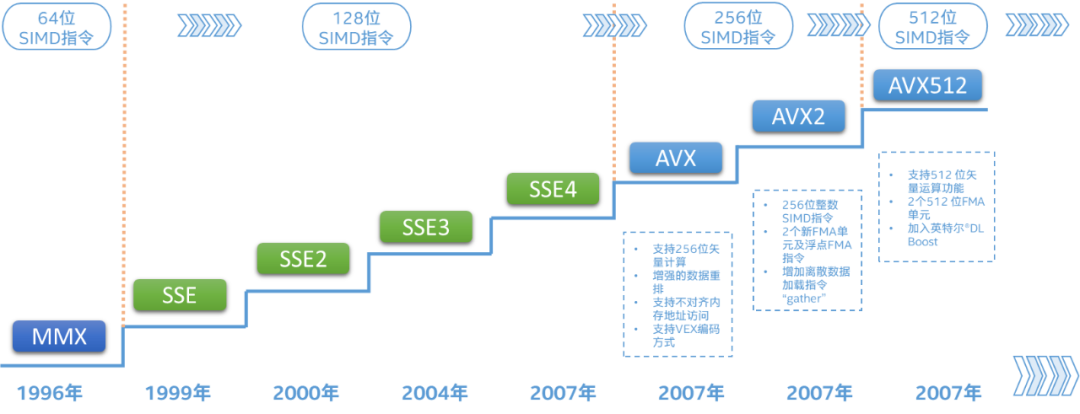
指令優(yōu)化方面,第二代英特爾至強(qiáng) 可擴(kuò)展處理器引入了簡(jiǎn)稱(chēng)VNNI(Vector Neural Network Instruction,矢量神經(jīng)網(wǎng)絡(luò)指令)的擴(kuò)展,提高了數(shù)據(jù)格式INT8推理的效率;代號(hào)Cooper Lake的第三代英特爾至強(qiáng)可擴(kuò)展處理器又引入了數(shù)據(jù)格式bfloat16(BF16)加速功能,可以用于推理和訓(xùn)練。 目前,前三代英特爾至強(qiáng) 可擴(kuò)展處理器的加速路徑,主要依靠現(xiàn)有的計(jì)算單元,即AVX-512,配合指令集、算法和數(shù)據(jù)上的優(yōu)化,輸出AI算力。 但加速的天花板就到此為止了嗎?
還有別的思路——內(nèi)置硬件加速器,且與本就高性能的CPU內(nèi)核無(wú)縫配合,疊加buff推高天花板。
2
硬件直接“貼貼”加速
第四代至強(qiáng)內(nèi)置多種專(zhuān)用加速器
在今年11月,英特爾宣布將在2023年1月11日發(fā)布代號(hào)為Sapphire Rapids的全新第四代英特爾至強(qiáng) 可擴(kuò)展處理器。
Sapphire Rapids將為廣泛的標(biāo)量和并行工作負(fù)載提供跨越式的性能提升,更重要的是,它的基本架構(gòu)旨在實(shí)現(xiàn)彈性計(jì)算模型(如容器化微服務(wù))的突破性性能,以及在所有形式的以數(shù)據(jù)為中心的計(jì)算中快速擴(kuò)展 AI 的使用。
第四代英特爾至強(qiáng)可擴(kuò)展處理器的核心數(shù)量有顯著增長(zhǎng),并支持DDR5、PCIe 5.0和CXL 1.1等下一代內(nèi)存和接口標(biāo)準(zhǔn),在內(nèi)置硬件加速上,Sapphire Rapids也集成了5項(xiàng)加速器:
用于AI的高級(jí)矩陣擴(kuò)展(Advanced Matrix Extensions),簡(jiǎn)稱(chēng)AMX;
用于數(shù)據(jù)分析的存內(nèi)分析加速器(In-Memory Analytics Accelerator),簡(jiǎn)稱(chēng)IAA;
用于5G/網(wǎng)絡(luò)的數(shù)據(jù)流加速器(Data Streaming Accelerator),簡(jiǎn)稱(chēng)DSA;
用于存儲(chǔ)的動(dòng)態(tài)負(fù)載均衡器(Dynamic Load Balancer),簡(jiǎn)稱(chēng)DLB;
用于數(shù)據(jù)壓縮和加解密的QuickAssist技術(shù),英特爾數(shù)據(jù)保護(hù)與壓縮加速技術(shù),簡(jiǎn)稱(chēng)QAT。
首先,內(nèi)置加速器可以消除在將數(shù)據(jù)從 CPU 移至協(xié)處理器加速器時(shí)產(chǎn)生的大部分開(kāi)銷(xiāo)。
同時(shí),Sapphire Rapids還引入了加速器接口架構(gòu) (AIA),解決了無(wú)縫集成加速引擎和高性能核心時(shí)面臨的關(guān)鍵挑戰(zhàn)——能夠處理 CPU 內(nèi)核與內(nèi)置加速器之間的數(shù)據(jù)高效調(diào)度、同步和信令傳遞,而不是高開(kāi)銷(xiāo)內(nèi)核模式。
內(nèi)置的硬件加速器也易獲得更出色的性能,而不必將時(shí)間浪費(fèi)在進(jìn)行片外傳輸設(shè)置上。
AMX與上述其他4個(gè)加速器的一大區(qū)別,就是它本身就集成在了CPU核心內(nèi),與AVX-512一樣,隨核心數(shù)同步增長(zhǎng),線性提升處理能力。
3
開(kāi)啟全新計(jì)算單元
AMX升維加速深度學(xué)習(xí)工作負(fù)載
AMX與AVX-512又有什么區(qū)別?
AMX是全新的計(jì)算單元,有自己的存儲(chǔ)和操作電路,并行度高,以便為AI工作負(fù)載加速Tensor運(yùn)算,支持bfloat16和INT8兩種數(shù)據(jù)類(lèi)型。
Tensor處理是深度學(xué)習(xí)算法的核心,AMX功能可以實(shí)現(xiàn)每個(gè)循環(huán)2000次int8運(yùn)算和1000次bfloat16運(yùn)算。
同時(shí),AMX的寄存器(名為T(mén)ile)是二維的,寄存器組是三維的,均比AVX-512高一個(gè)維度,寄存器組存儲(chǔ)的數(shù)據(jù)相當(dāng)于一個(gè)小型矩陣,這樣AMX 能夠在每個(gè)時(shí)鐘周期執(zhí)行更多矩陣乘法以每時(shí)鐘周期來(lái)看。
理論上,AMX的TMUL(矩陣乘法運(yùn)算)對(duì)AVX-512的2個(gè)FMA(融合乘加操作)單元,INT8性能高達(dá)8倍;處理浮點(diǎn)數(shù)據(jù),AMX使用動(dòng)態(tài)范圍與FP32相當(dāng)?shù)腂F16,性能可達(dá)AVX-512的16倍。
如此,有全新可擴(kuò)展二維寄存器文件和全新矩陣乘法指令,可增強(qiáng)各種深度學(xué)習(xí)工作負(fù)載中推理及訓(xùn)練性能,也就代表著計(jì)算能力的大幅提升,這些計(jì)算能力可以通過(guò)行業(yè)標(biāo)準(zhǔn)框架和運(yùn)行時(shí)無(wú)縫訪問(wèn)。
據(jù)今年1月數(shù)據(jù)表明,基于TensorFlow框架,INT8 精度下每秒檢測(cè)的圖像的數(shù)量增幅以及高達(dá) 6 倍多 BF16 精度下進(jìn)行對(duì)象檢測(cè)時(shí)每秒檢測(cè)的圖像的數(shù)量增幅明顯增加:
56核的第四代英特爾 至強(qiáng)可擴(kuò)展處理器全新的AMX,對(duì)比40核的第三代英特爾 至強(qiáng)可擴(kuò)展處理器,在SSD-ResNet34上進(jìn)行實(shí)時(shí)推理時(shí),每秒處理的圖像數(shù)量增加高達(dá)4.5倍。(注:實(shí)際性能受使用情況、配置和其他因素的差異影響,且性能測(cè)試結(jié)果基于配置信息中顯示的日期進(jìn)行的測(cè)試[1])
當(dāng)然AVX-512本身就以FP32、FP64等高精度浮點(diǎn)數(shù)據(jù)的運(yùn)算見(jiàn)長(zhǎng),依然可以專(zhuān)注于如數(shù)據(jù)分析、科學(xué)計(jì)算、經(jīng)典機(jī)器學(xué)習(xí)等高精度計(jì)算。
如今第三代人工智能浪潮是以深度學(xué)習(xí)為代表,并非只有深度學(xué)習(xí),AI的范圍正在不斷擴(kuò)大,計(jì)算需求也在多元化,當(dāng)人工智能的工作負(fù)載出現(xiàn)混合精度計(jì)算需求,AMX和AVX-512就可搭配使用,發(fā)展各自長(zhǎng)處。
對(duì)于數(shù)據(jù)精度不高但要求高準(zhǔn)確度的推理場(chǎng)景,如圖像識(shí)別、推薦引擎、媒體分析、語(yǔ)言翻譯、自然語(yǔ)言處理(NLP)、強(qiáng)化學(xué)習(xí)等典型AI應(yīng)用場(chǎng)景,AMX其實(shí)屬于降維打擊,可發(fā)揮空間很大。
根據(jù)預(yù)告,英特爾第四代至強(qiáng)可擴(kuò)展處理器是處理AI等更現(xiàn)代化、更新興并行工作負(fù)載的基礎(chǔ)設(shè)施,在進(jìn)行整體設(shè)計(jì)時(shí)也考慮到了未來(lái)技術(shù)發(fā)展趨勢(shì)——絕大多數(shù)新的可擴(kuò)展服務(wù)將采用容器化微服務(wù)等彈性計(jì)算模型進(jìn)行開(kāi)發(fā)。
新版Windows、Linux Kernel和虛擬化軟件也確實(shí)都具備支持AMX指令集的條件,所謂“引領(lǐng)”就是要更先一步到達(dá)未來(lái)。
1月11號(hào),讓我們期待至強(qiáng)新品的發(fā)布和更多信息吧~可以先點(diǎn)擊閱讀原文,提前了解至強(qiáng)產(chǎn)品組合~
審核編輯 :李倩
-
cpu
+關(guān)注
關(guān)注
68文章
11033瀏覽量
215993 -
人工智能
+關(guān)注
關(guān)注
1804文章
48701瀏覽量
246458 -
算力
+關(guān)注
關(guān)注
2文章
1142瀏覽量
15446
原文標(biāo)題:明年1月,推高CPU人工智能算力天花板
文章出處:【微信號(hào):AI_Architect,微信公眾號(hào):智能計(jì)算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
車(chē)企激戰(zhàn)高壓平臺(tái)!比亞迪要把“超充戰(zhàn)”打到天花板

谷歌第七代TPU Ironwood深度解讀:AI推理時(shí)代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
游戲體驗(yàn)天花板,一加 Ace 5 系列售價(jià) 2299 元起

NPU在深度學(xué)習(xí)中的應(yīng)用
使用EMBark進(jìn)行大規(guī)模推薦系統(tǒng)訓(xùn)練Embedding加速

GPU深度學(xué)習(xí)應(yīng)用案例
FPGA加速深度學(xué)習(xí)模型的案例
深度學(xué)習(xí)GPU加速效果如何
【「大模型時(shí)代的基礎(chǔ)架構(gòu)」閱讀體驗(yàn)】+ 第一、二章學(xué)習(xí)感受

FPGA在人工智能中的應(yīng)用有哪些?
深度學(xué)習(xí)編譯器和推理引擎的區(qū)別
深度學(xué)習(xí)模型量化方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論