 得物云原生全鏈路追蹤Trace2.0-采集篇
得物云原生全鏈路追蹤Trace2.0-采集篇
0
0xcc 開篇
2020 年 3月,得物技術團隊在三個月的時間內完成了整個交易體系的重構,交付了五彩石項目,業務系統也進入了微服務時代。系統服務拆分之后,雖然每個服務都會有不同的團隊各司其職,但服務之間的依賴也變得復雜,對服務治理等相關的基礎建設要求也更高。
對服務進行監控是服務治理、穩定性建設中的一個重要的環節,它能幫助提早發現問題,預估系統水位,以及對故障進行分析等等。從 2019 年末到現在,得物的應用服務監控系統經歷了三大演進階段,如今,整個得物的應用微服務監控體系已經全面融入云原生可觀測性技術 OpenTelemetry。

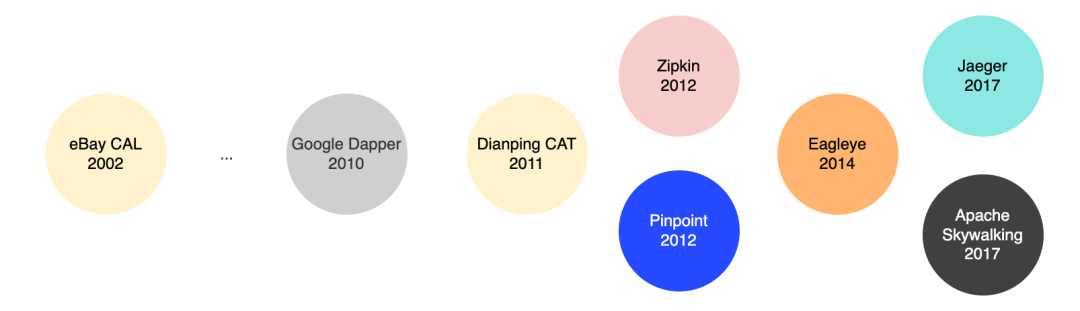
回顧過去十年間,應用服務監控行業的競爭也很激烈,相關產品如雨后春筍般涌現,如推特在 2012 年開源的 Zipkin,韓國最大的搜索引擎和門戶網站 Naver 開源的 Pinpoint,近幾年 Uber 公司開源的 Jaeger,以及我們國內吳晟開源的 SkyWalking。
有人說,這些其實都歸功于 Google 在 2010 年基于其內部大規模分布式鏈路追蹤系統 Dapper 實踐而發表的論文,它的設計理念是一切分布式調用鏈追蹤系統的始祖,但其實早在二十年前(2002年),當年世界上最大的電商平臺 eBay 就已擁有了調用鏈追蹤系統 CAL(Centralized Application Logging)。2011 年,原eBay的中國研發中心的資深架構師吳其敏跳槽至大眾點評,并且深入吸收消化了 CAL 的設計思想,主導研發并開源了CAT(Centralized Application Tracking)。
1
0x01 第一階段
從0~1基于CAT的實時應用監控
在得物五彩石項目交付之前,系統僅有基礎設施層面的監控,CAT 的引入,很好地彌補了應用監控盲區。它支持提供各個維度的性能監控報表,健康狀況檢測,異常統計,對故障問題排查起到了積極推動的作用,同時也提供簡單的實時告警的能力。
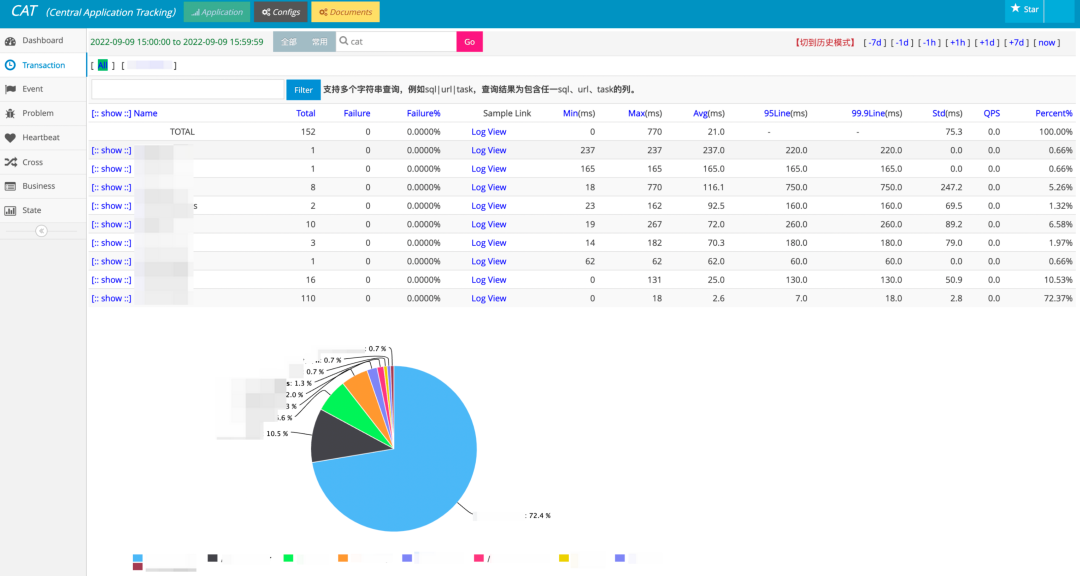
CAT 擁有指標分鐘級別的聚合統計的能力,從 UI 上不難看出,它擁有豐富的報表統計能力和問題排障能力。
但隨著公司業務規模逐步擴大,微服務粒度也不可避免地變小,我們發現,CAT 已經逐步無法滿足我們的使用場景了:
-
無法直觀呈現全鏈路視圖:
問題排障與日常性能分析的場景也越來越復雜,對于一個核心場景,其內部的調用鏈路通常復雜多變,站在流量角度上看,需要完整地知道它的來源,上下游鏈路,異步調用等等,這對于 CAT 來說可能略顯超綱。
- 缺少圖表定制化能力:
2
0x02 第二階段
持續創造 基于OpenTracing全鏈路采樣監控
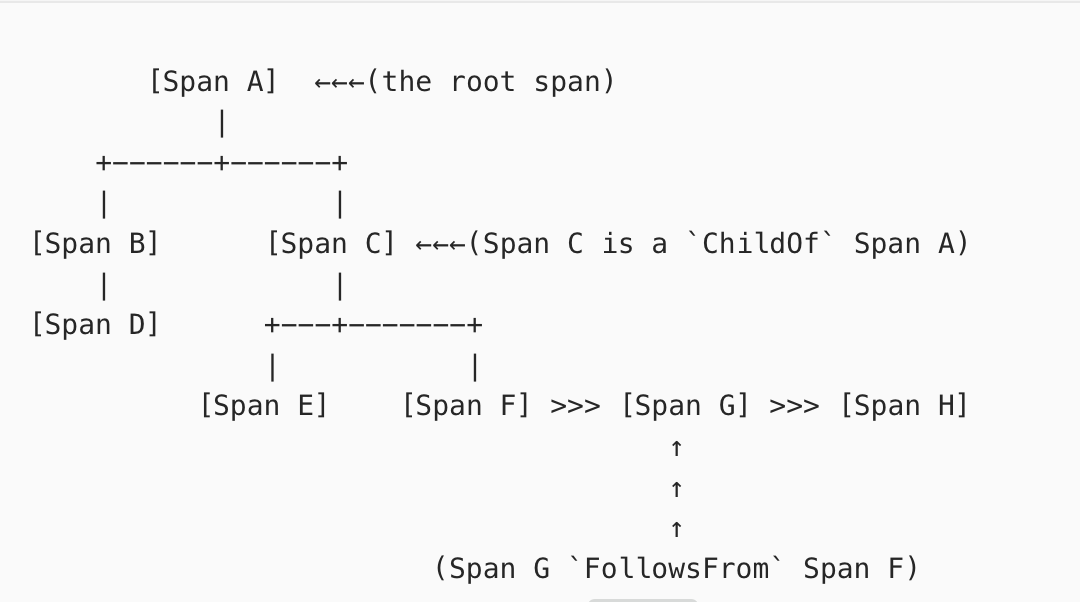
OpenTracing 為全鏈路追蹤 Trace 定制了完整的一套協議標準,本身并不提供實現細節。在 OpenTracing 協議中,Trace 被認為是 Span 的有向無環圖(DAG)。官方也例舉了以下 8 個 Span 的因果關系和他們組成的單 Trace示例圖:
在當時, OpenTracing 相關的開源社區也是異常活躍,它使用 Jaeger 來解決數據的收集,調用鏈則使用了甘特圖展示:
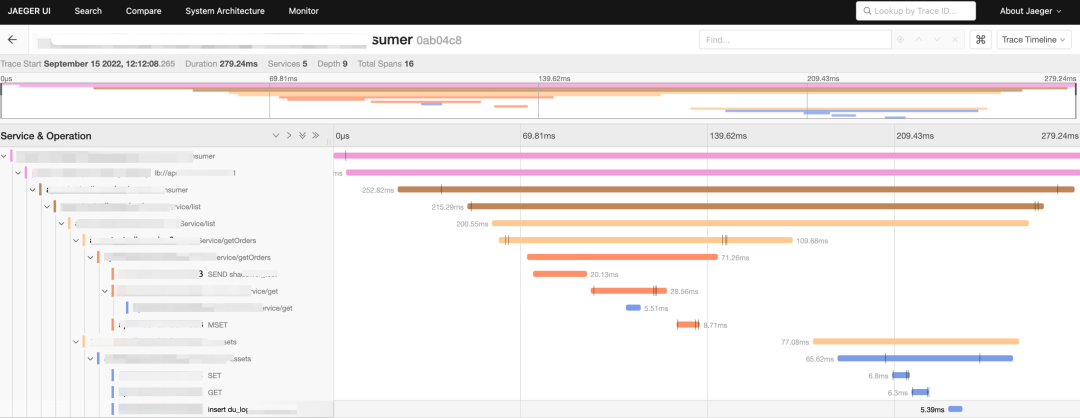
在 OpenTracing 生態中,我們對鏈路的采樣使用頭部采樣策略, 對于指標 Metrics,OpenTracing 并沒有制定它的規范,但在 Google SRE Book 里,關于 Monitoring Distributed System 章節中提到了四類黃金指標:
吞吐量:如每秒請求數,通常的實現方式是,設定一個計數器,每完成一次請求將自增。通過計算時間窗口內的變化率來計算出每秒的吞吐量。
延遲:處理請求的耗時。
錯誤率/錯誤數:如 HTTP 500 錯誤。當然,有些即便是 HTTP 200 狀態也需要根據特定業務邏輯來區分當前請求是否屬于“錯誤”請求。
飽和度:類似服務器硬件資源如CPU,內存,網絡的使用率等等。
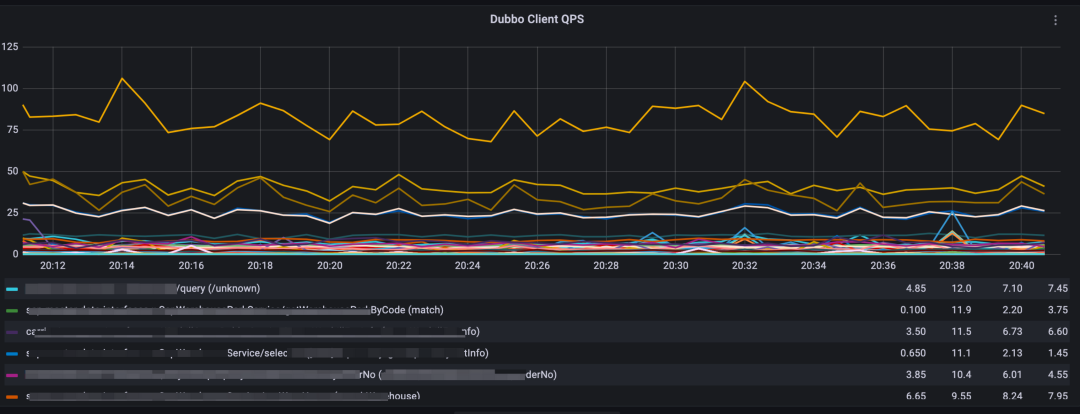
所以,我們決定使用 Micrometer 庫來對各個組件進行吞吐量,延遲和錯誤率的埋點,從而對 DB 類,RPC類的組件做性能監控。因此也可以說,我們第二階段的監控是以指標監控為主,調用鏈監控為輔的應用性能監控。2.1 使用 Endpoint 貫穿指標埋點幫助性能分析在指標埋點過程中,我們在所有的指標中引入了“流量入口(Endpoint)”標簽。這個標簽的引入,實現了根據不同流量入口來區分關聯 DB,緩存,消息隊列,遠程調用類的行為。通過流量入口,貫穿了一個實例的所有組件指標,基本滿足了以下場景的監控:
-
RPC 調用排障,調用方除了擁有下游接口信息,也可溯源自身觸發該調用的接口。
-
接口高耗時分析,根據指標,可還原出單位時間窗口的耗時分解圖快速查看耗時組件。

2.2 關于選型的疑問
你可能會問,鏈路監控領域在業內有現成的 APM 產品,比如 Zipkin, Pinpoint, SkyWalking 等,為什么當時會選擇 OpenTracing + Prometheus 自行埋點?主要有兩大因素:
第一,在當時,CAT 無法滿足全鏈路監控和一些定制化的報表分析,而得物交易鏈路五彩石項目交付也趨于尾聲,貿然去集成外部一款龐大的 APM 產品在沒有充分的驗證下,會給服務帶來穩定性風險,在極其有限的時間周期內不是個理智的選擇。
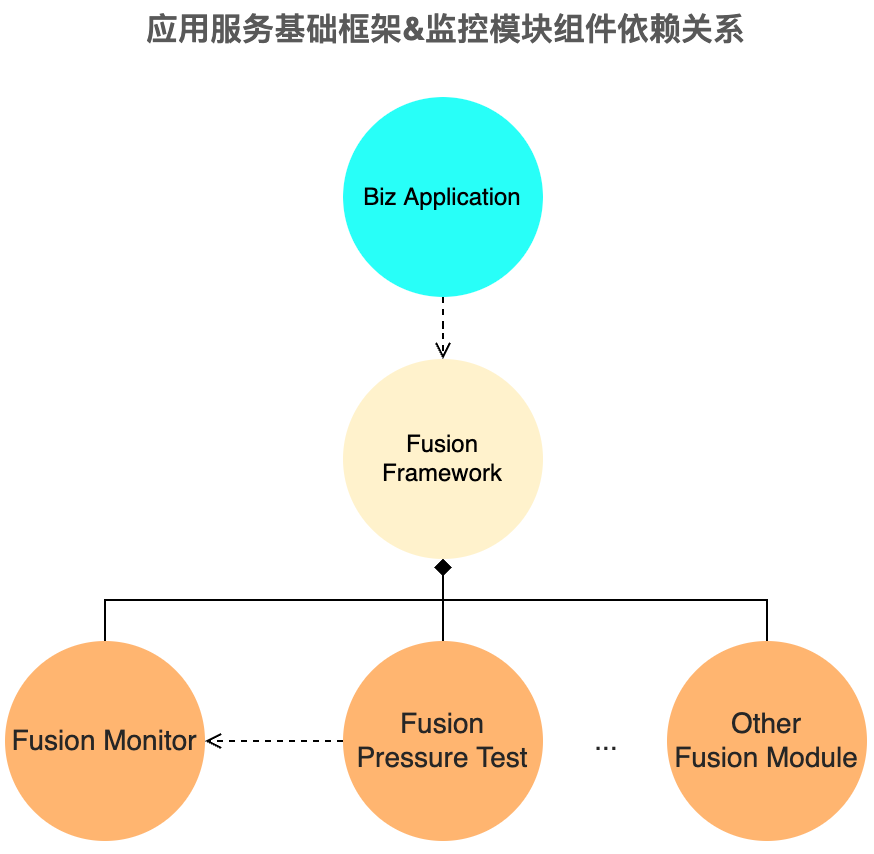
第二,監控組件是隨著統一的基礎框架來發布,同時,由另一團隊牽頭開發的全鏈路影子庫路由組件借助了 OpenTracing 隨行數據透傳機制,且與監控組件是強耦合關系,而基礎框架將統籌監控,壓測和其他模塊,借助Spring Boot Starter 機制,一定程度上做到了功能的開箱即用,無縫集成。而使用字節碼增強方式的 Pinpoint, SkyWalking,無法很好地做到與基礎框架集成,若并行開發,也會多出基礎框架與 Java Agent 兩邊的管理和維護成本,減緩迭代速度。
在之后將近兩年的時間里,應用服務監控覆蓋了得物技術部使用的將近 70% 的組件,為得物App在 2021 年實現全年 99.97% 的 SLA 提供了強有力的支持。現在看來,基于 OpenTracing + Prometheus 生態,很好地解決了分布式系統的調用鏈監控,借助 Grafana 圖表工具,做到了靈活的指標監控,融合基礎框架,讓業務方開箱即用…然而,我們說第二階段是基于 OpenTracing 全鏈路采樣監控,隨著業務的高速發展,這套架構的不足點也逐漸顯露出來。
2.3 架構特點
- 體驗層面
-
-
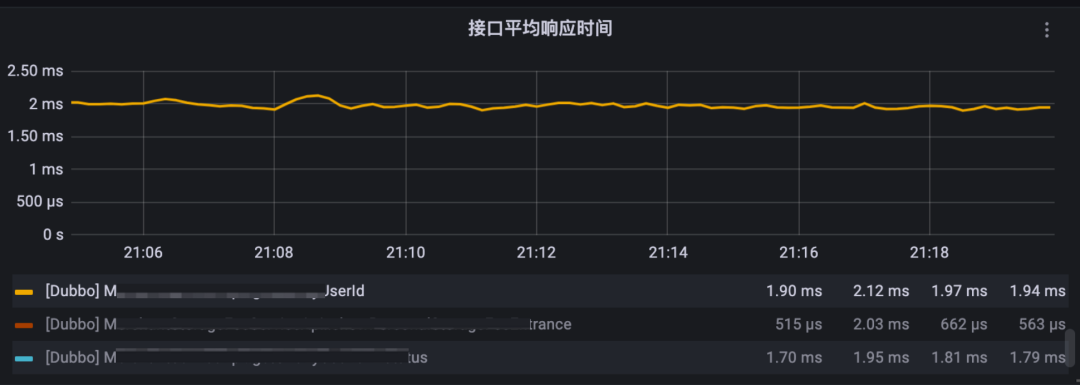
指標:覆蓋面廣,維度細,能清晰地根據各模塊各維度來統計分析,基本做到了監控靈活的圖表配置需求。但不可否認它是一種時序聚合數據,無法細化為個體。假如在某個時間點發生過幾次高耗時操作,當吞吐量達到一定時,平均耗時指標曲線仍然趨于平穩,沒有明顯的突出點,導致問題發現能力降低。
-
-
-
鏈路:1%的采樣率使得業務服務基本不會因調用鏈發送量大而導致性能問題,但同時也往往無法從錯誤,高耗時的場景中找到正好采樣的鏈路。期間,我們曾經考慮將頭部采樣策略改為尾部采樣,但面臨著非常高昂的 SDK 改造成本和復雜調用情況下(如異步)采樣策略的回溯,且無法保證發生每個高耗時,錯誤操作時能還原整個完整的調用鏈路。
-
集成方式:業務和基礎框架均采用 Maven 來構建項目,使用 Spring Boot Starter "all in one"開箱即用方式集成,極大降低了集成成本的同時,也給依賴沖突問題埋下了隱患。
-
- 項目迭代層面
迭代周期分化矛盾,與基礎框架的集成是當時快速推廣落地全鏈路監控的不二選擇,通過這種方式,Java 服務的接入率曾一度接近100%,但在業務高速發展的背景下,基礎框架的迭代速度已經遠遠跟不上業務迭代速度了,這也間接制約了整個監控系統的迭代。
- 數據治理層面
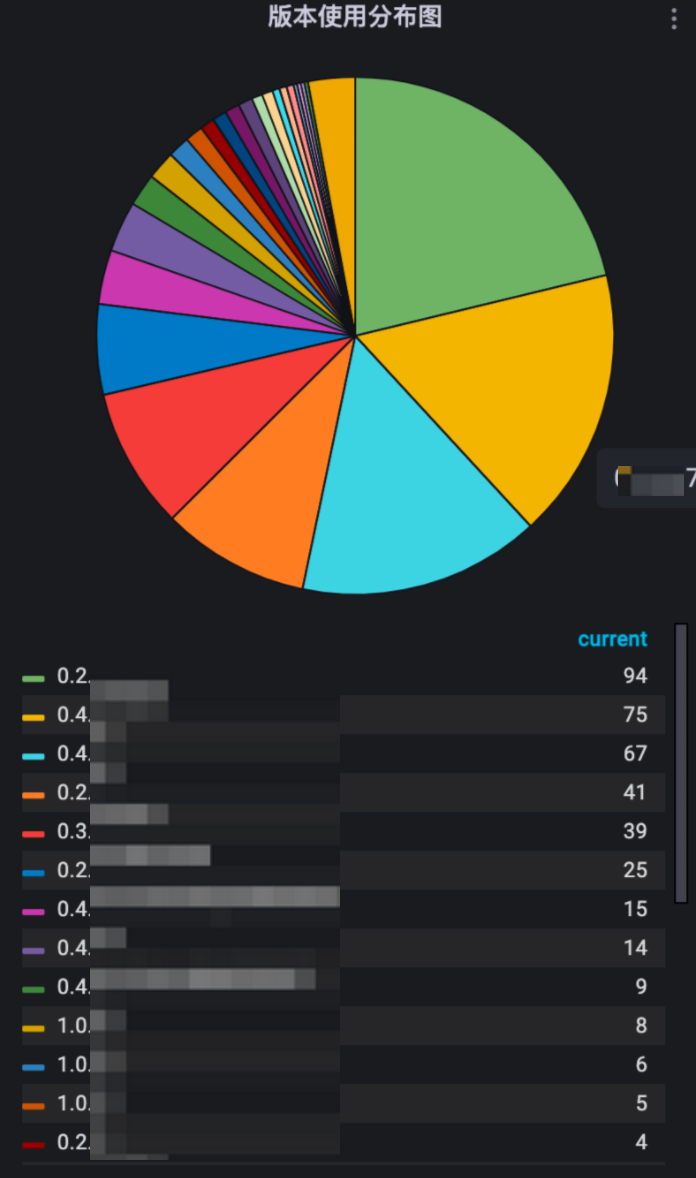
盡管監控系統在每一次迭代時都會盡可能保證最大的向后兼容,但將近兩年的迭代周期里,不同版本造成的數據差異也極大制約了監控門戶系統天眼的迭代,開發人員長時間奔波于數據上的妥協,在很多功能的實現上曲線救國。
- 穩定性層面
相關預案依托于 Spring 框架 Bean 的自動裝配邏輯,業務方理解成本低,便于變更,但缺少細粒度的預案,比如運行時期間特定邏輯降級等等。
-
-
2021 年下半年開始,為了充分平衡以上的收益與風險,我們決定將監控采集端與基礎框架解耦,獨立迭代。在此之前,在 CNCF(云原生計算基金會)的推動下,OpenTracing 也與 OpenCensus 合并成為了一個新項目 OpenTelemetry。
-

3
0x03 第三階段
向前一步 基于OpenTelemetry全鏈路應用性能監控
OpenTelemetry 的定位在于可觀測性領域中對遙測數據采集和語義規范的統一,有 CNCF (云原生計算基金會)的加持,近兩年里隨著越來越多的人關注和參與,整個體系也越發成熟穩定。
其實,我們在2020年底就已開始關注 OpenTelemetry 項目,只不過當時該項目仍處于萌芽階段, Trace, Metrics API 還在 Alpha 階段,有很多不穩定因素,考慮到需盡快投入生產使用,筆者曾在 2021 年中到年末期間也或多或少參與了 OpenTelemetry 社區相關 issue 的討論,遙測模塊的開發,底層數據協議的一致和一些 BUG 的修復。在這半年期間,相關 API 和 SDK 隨著越來越多的人參與也逐步趨于穩定。
OpenTelemetry架構(圖源自 opentelemetry.io)
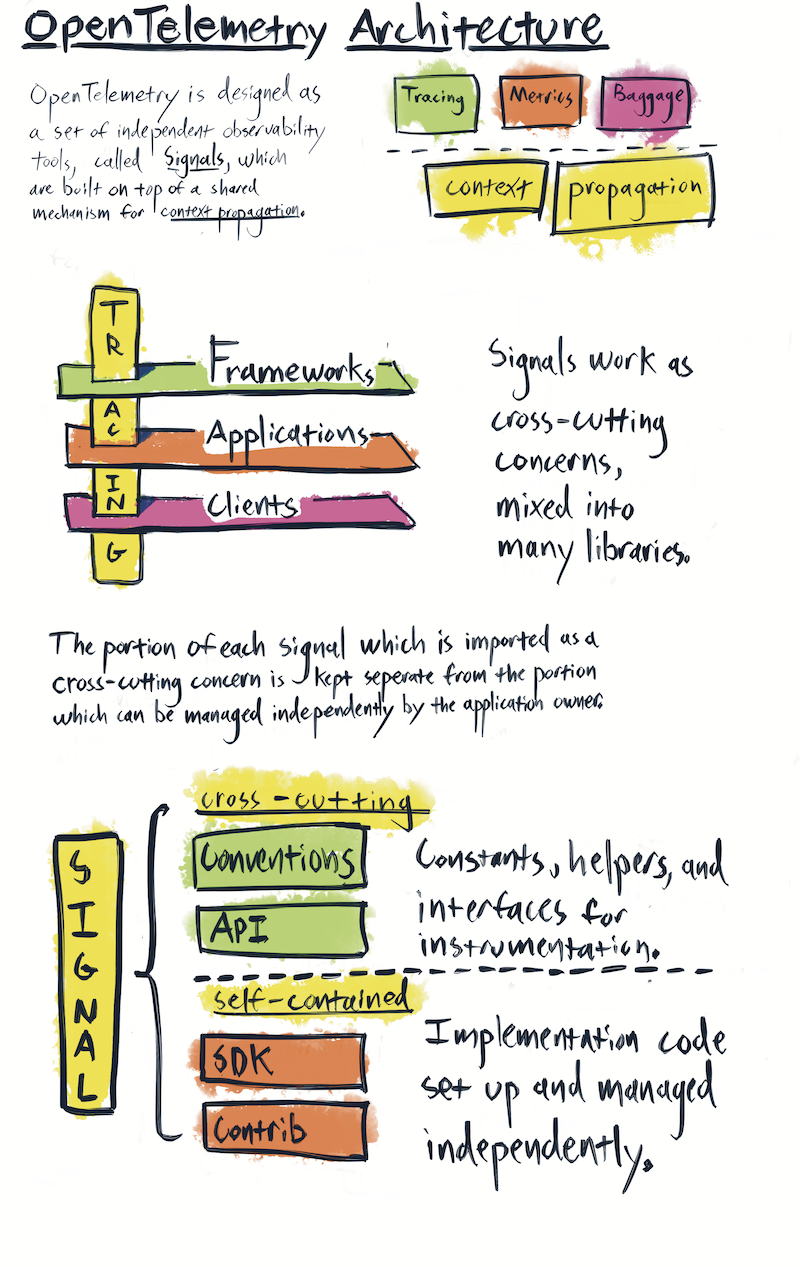
3.1 邁入 Trace2.0 時代
OpenTelemetry 的定位致力于將可觀測性三大要素 Metrics,Trace,Log 進行統一,在遙測 API 制定上,提供了統一的上下文以便 SDK 實現層去關聯。如 Metrics 與 Trace 的關聯,筆者認為體現在 OpenTelemetry 在 Metrics 的實現上包含了對 OpenMetrics 標準協議的支持,其中 Exemplar 格式的數據打通了 Trace 與 Metrics 的橋梁:
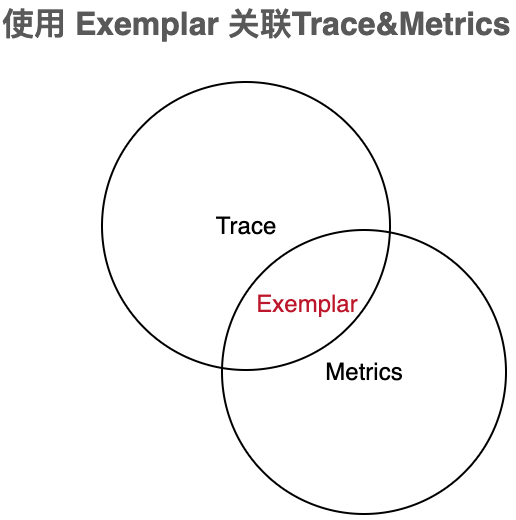
OpenMetrics 是建立在 Prometheus 格式之上的規范,做了更細粒度的調整,且基本向后兼容 Prometheus 格式。
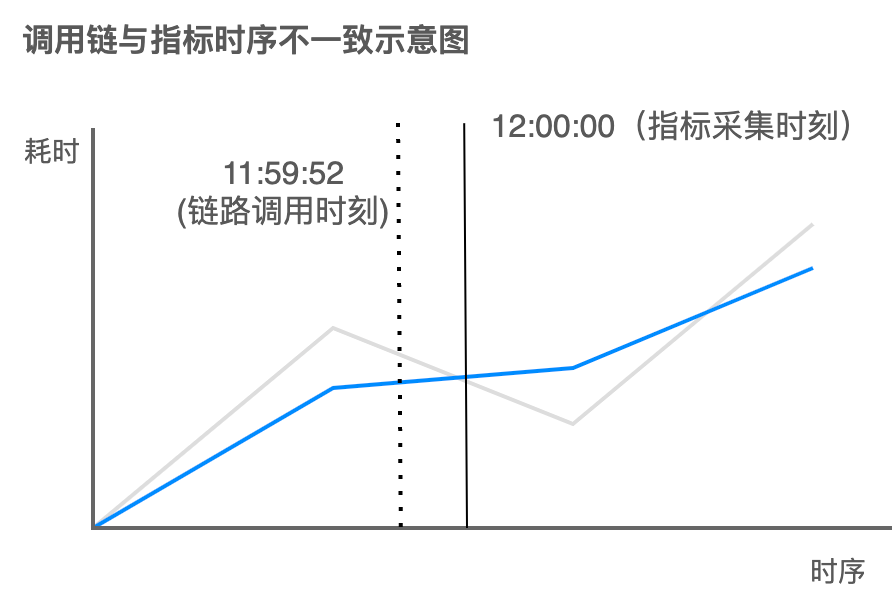
在這之前,Metrics 指標類型的數據無法精確關聯到具體某個或某些 Trace 鏈路,只能根據時間戳粗略關聯特定范圍內的鏈路。這個方案的缺陷源自指標采集器 vmagent 每隔 10s~30s 的 Pull 模式中,指標的時間戳取決于采集時刻,與 Trace 調用時間并不匹配。
shadower_virtual_field_map_operation_seconds_bucket{holder="Filter:Factory",key="WebMvcMetricsFilter",operation="get",tcl="AppClassLoader",value="Servlet3FilterMappingResolverFactory",le="0.2"} 3949.0 1654575981.216 # {span_id="48f29964fceff582",trace_id="c0a80355629ed36bcd8fb1c6c89dedfe"} 1.0 1654575979.751
為了采集 Exemplar 格式指標,同時又需防止分桶標簽“le”產生的高基數問題,我們二次開發了指標采集 vmagent,額外過濾攜帶 Exemplar 數據的指標,并將這類數據異步批量發送到了 Kafka,經過 Flink 消費后落入 Clickhouse 后,由天眼監控門戶系統提供查詢接口和UI。
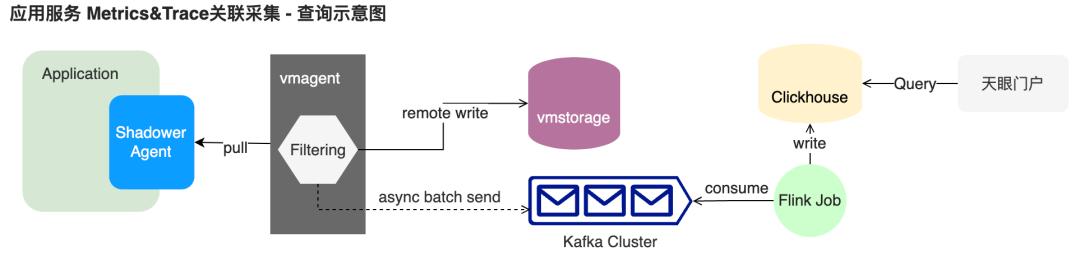
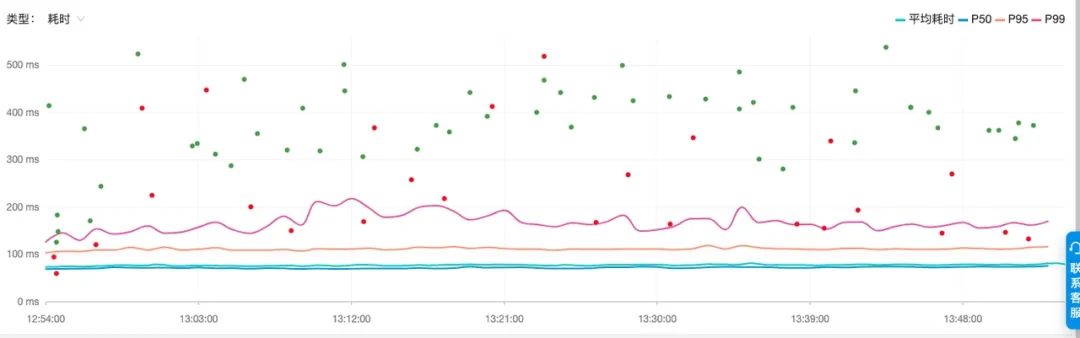
分位線統計與Exemplar 數據關聯UI示意圖
在數據上報層,OpenTelemetry Java SDK 使用了比 JDK 原生的阻塞隊列性能更好的 Mpsc (多生產單消費)隊列,它使用大量的 long 類型字段來做內存區域填充,用空間換時間解決了偽共享問題,減少了并發情況下的寫競爭來提高性能。
在流量高峰時期,鏈路數據的發送隊列這一塊的性能從火焰圖上看 CPU 占比平均小于2%,日常服務CPU整體水位與0采樣相比幾乎沒有明顯差距,因此我們經過多方面壓測對比后,決定在生產環境客戶端側開放鏈路數據的全量上報,實現了在得物技術史上的全鏈路 100% 采樣,終結了一直以來因為低采樣率導致問題排查困難的問題,至此,在第三階段,得物的全鏈路追蹤技術正式邁入 Trace2.0 時代。
得益于 OpenTelemetry 整體的可插拔式 API 設計,我們二次開發了 OpenTelemetry Java Instrumentation 項目 Shadower Java,擴展了諸多功能特性:
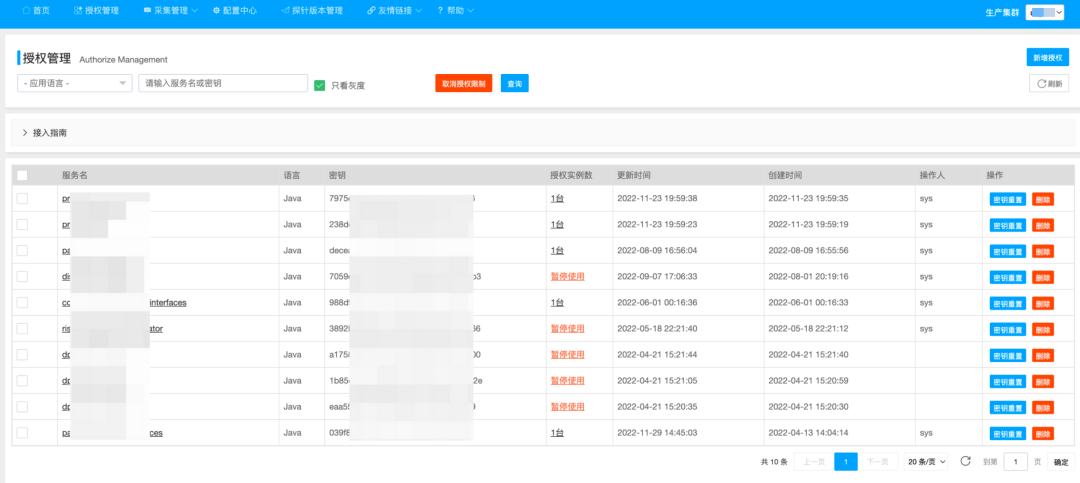
3.2 引入控制平面管理客戶端采集行
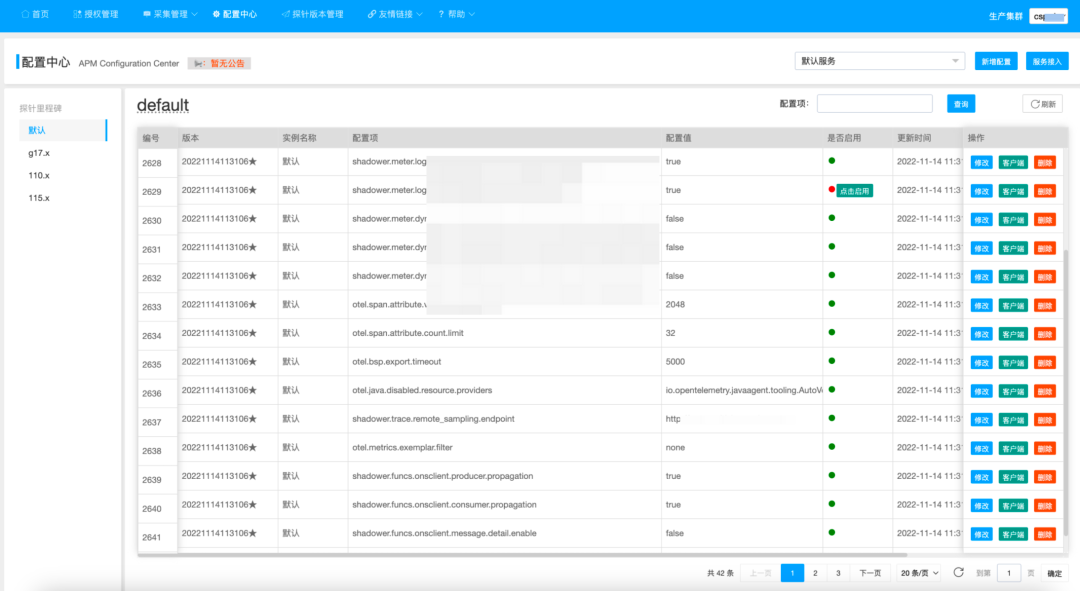
使用控制平面,通過客戶端監聽機制來確保配置項的下發動作,包括:
- 實時動態采樣控制
- 診斷工具 Arthas 行為控制
- 實時全局降級預案
- 遙測組件運行時開關
- 實時 RPC 組件出入參收集開關
- 實時高基數指標標簽的降級控制
- 按探針版本的預案管理
- 基于授權數的灰度接入策略。
- ... ...
控制平面的引入,彌補了無降級預案的空白,也提供了更加靈活的配置,支持了不同流量場景下快速變更數據采集方案:
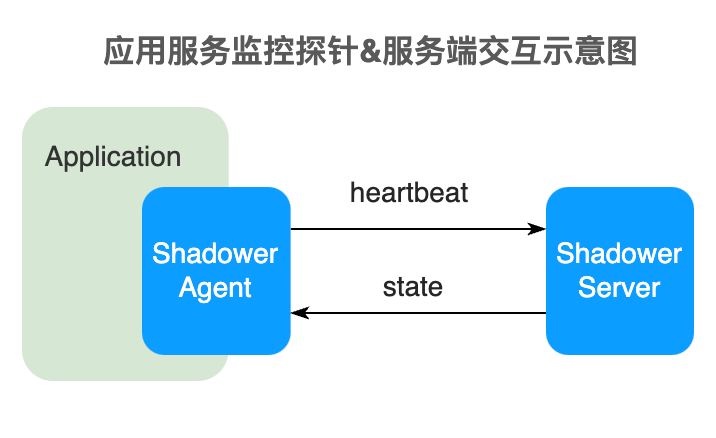
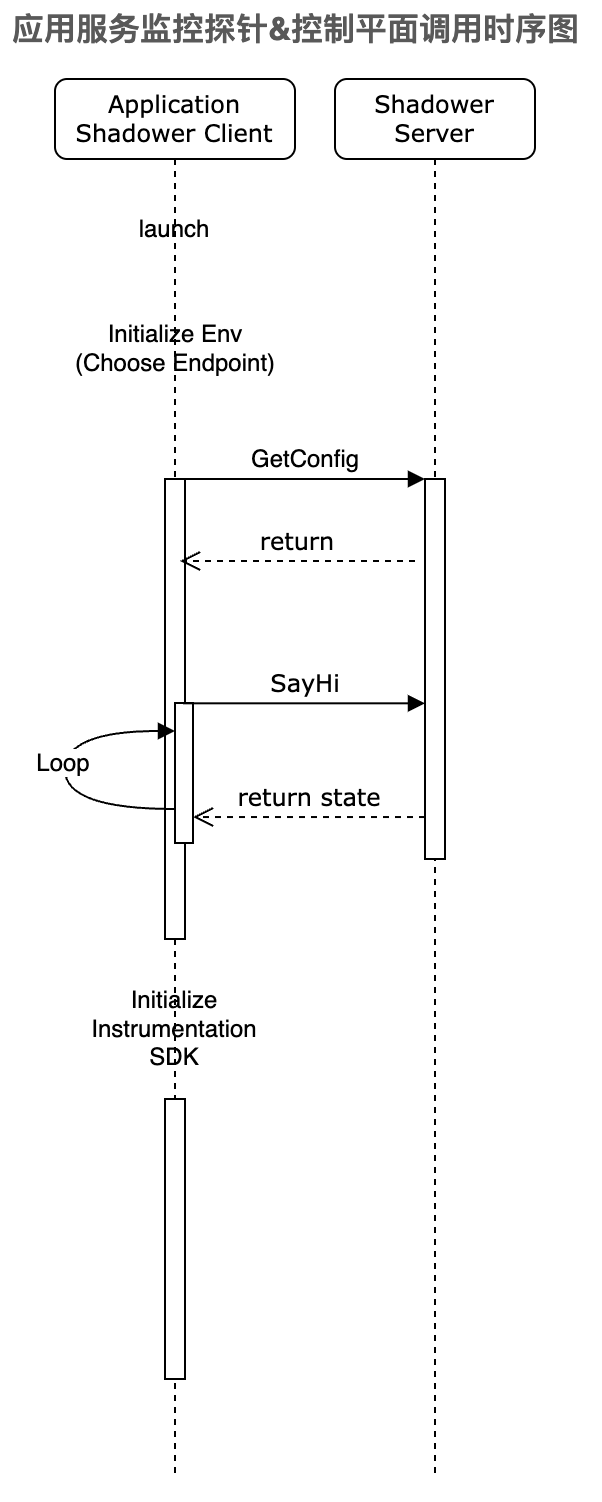
3.3 獨立的啟動模塊
為了解決業務方因集成基礎框架而長期面臨的依賴沖突問題,以及多版本共存引起的數據格式分散與兼容問題,我們自研了無極探針工具箱 Promise, 它是個通用的 javaagent launcher, 結合遠端存儲,支持可配置化任意 javaagent 的下載,更新,安裝和啟動:
[plugins]
enables = shadower,arthas,pyroscope,chaos-agent
[shadower]
artifact_key = /javaagent/shadower-%s-final.jar
boot_class = com.shizhuang.apm.javaagent.bootstrap.AgentBootStrap
classloader = system
default_version = 115.16
[arthas]
artifact_key = /tools/arthas-bin.zip
;boot_class = com.taobao.arthas.agent334.AgentBootstrap
boot_artifact = arthas-agent.jar
premain_args = .attachments/arthas/arthas-core.jar;;ip=127.0.0.1
[pyroscope]
artifact_key = /tools/pyroscope.jar
[chaos-agent]
artifact_key = /javaagent/chaos-agent.jar
boot_class = com.chaos.platform.agent.DewuChaosAgentBootstrap
classloader = system
apply_envs = dev,test,local,pre,xdw

3.4 基于 Otel API 的擴展
3.4.1 豐富的組件度量
在第二階段 OpenTracing 時期,我們使用 Endpoint 貫穿了多個組件的指標埋點,這個優秀的特性也延續至第三階段,我們基于底層 Prometheus SDK 設計了一套完善的指標埋點 SDK,并且借助字節碼插樁的便捷,優化并豐富了更多了組件庫。(在此階段,OpenTelemetry SDK 主版本是 1.3.x ,相關 Metrics SDK 還處于Alpha 階段)
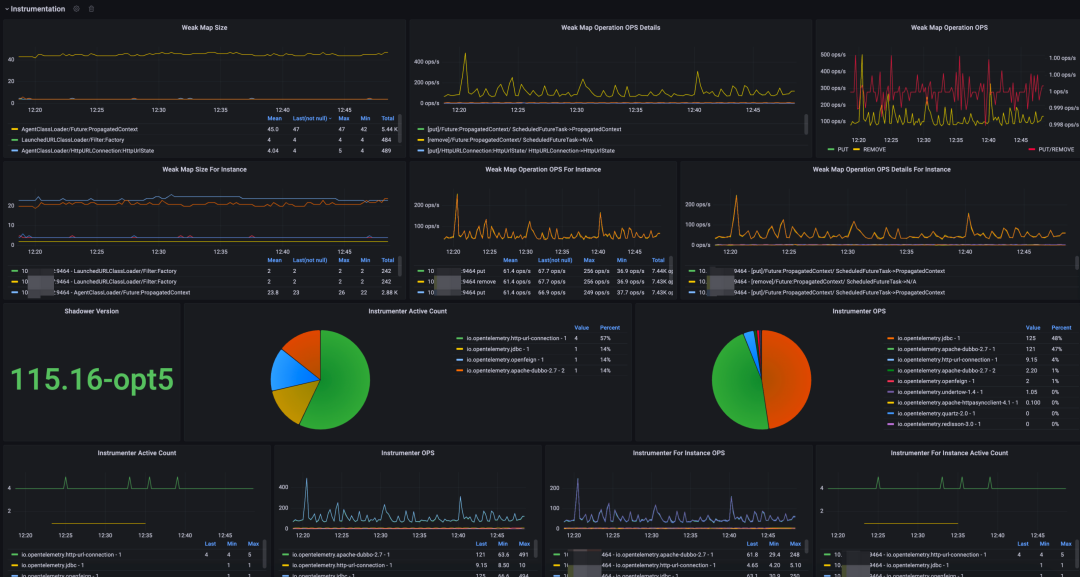
Otel 的 Java Instrumnetation 主要使用 WeakConcurrentMap 來做異步鏈路上下文數據傳遞和同線程上下文關聯的容器,由于 Otel 對許多流行組件庫做了增強,因此 WeakConcurrentMap 的使用頻率也是非常高的,針對這個對象的 size 做監控,有助于排查因探針導致的內存泄露問題,且它的增長率一旦達到我們設定的閾值便會告警,提早進行人工干預,執行相關預案,防止線上故障發生。
部分自監控面板
3.4.2擴展鏈路透傳協
1) 引入RPC ID
為了更好地關聯上下游應用,讓每個流量都有“身份”,我們擴展了 TextMapPropagator 接口,讓每個流量在鏈路上都知道請求的來源,這對跨區域,環境調用排障場景起到關鍵性作用。
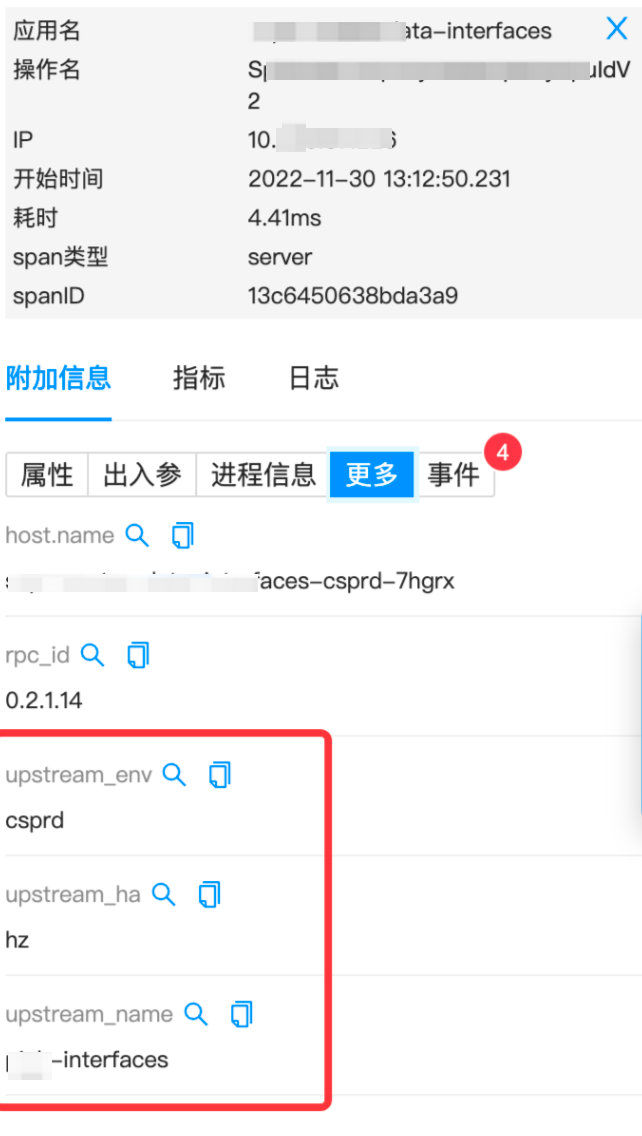
此外,對于跨端場景,我們參考了阿里鷹眼調用鏈RPCID模型,增加了RpcID字段,這個字段在每次發生跨端調用時末尾數值會自增,而對于下游應用,字段本身的層級自增:
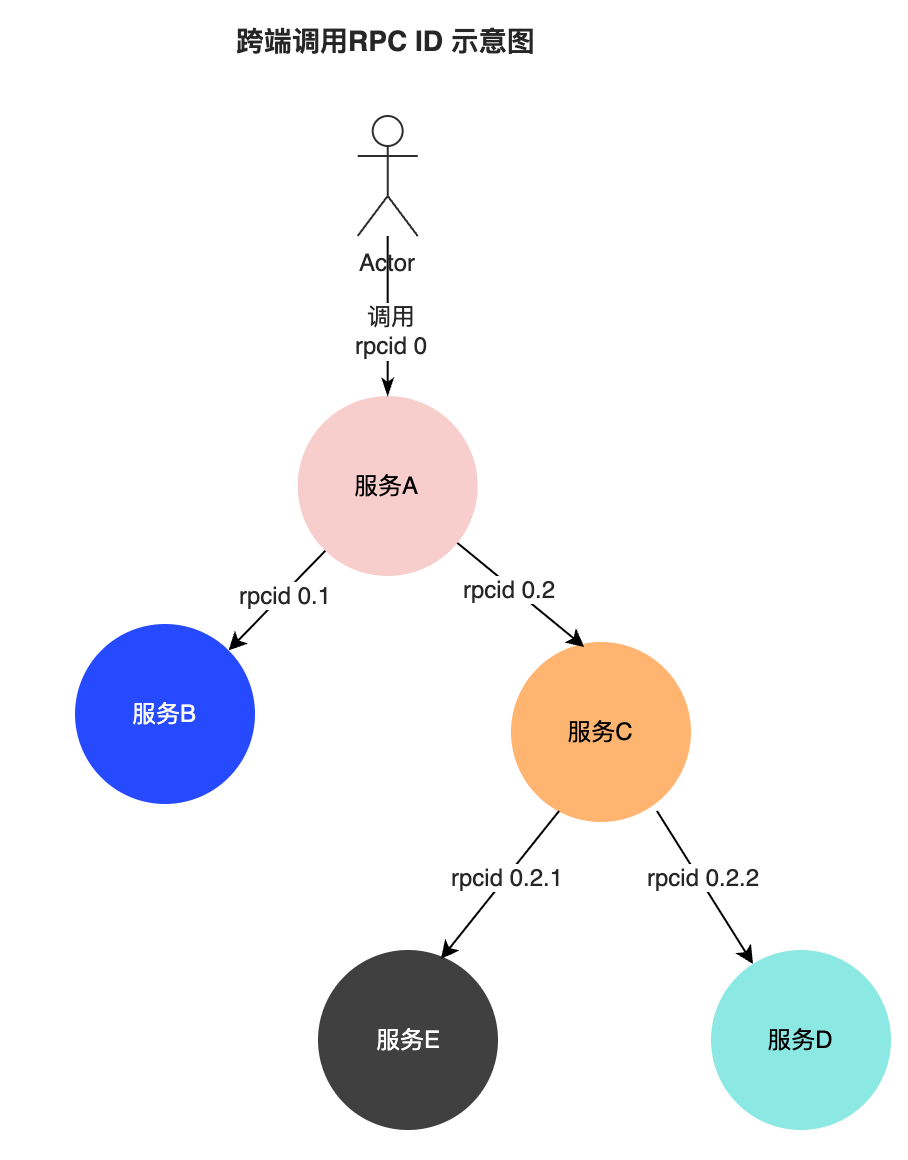
該字段擁有以下作用:
支持提供精簡化的調用鏈路視圖,查詢臃腫鏈路(如那些涉及緩存,DB調用大于 2000 Span的鏈路)時只提供 RPC 調用節點和調用層次關系。
鏈路保真,客戶端鏈路數據上報隊列并不是個無界限隊列,當客戶端自身調用頻繁時,若上報隊列堆積達到閾值即會丟棄,這會造成整個鏈路的不完整,當然這是預期內的現象,但若沒有RpcID字段,鏈路視圖將無法關聯丟失的節點,從而導致整個鏈路層級混亂失真。
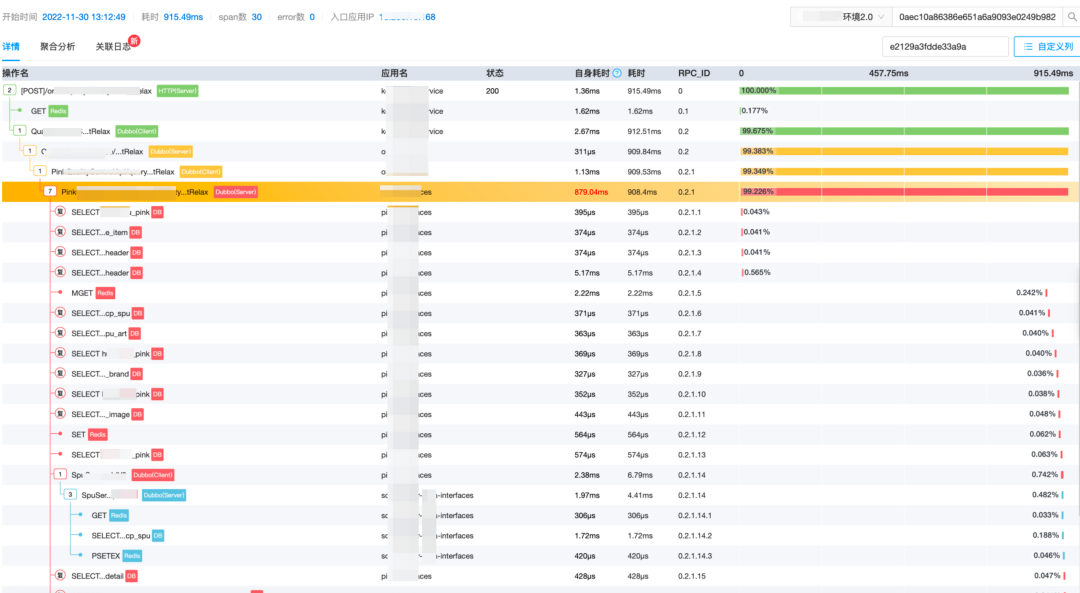
2) 自定義 Trace ID
為了實現鏈路詳情頁高效的檢索效率,我們擴展 TraceID 生成邏輯,ID的前8位使用實例IP,中8位使用當前時間戳,后16位采用隨機數生成。
32位自定義traceId:c0a8006b62583a724327993efd1865d8
c0a8006b 62583a72 4327993efd1865d8
| | |
高8位(IP) 中8位(Timestmap) 低16位(Random)
這樣的好處有兩點:
通過 TraceID 反向解析時間戳,鎖定時間范圍,有助于提高存儲庫 Clickhouse 的檢索效率,此外也能幫助決定當前的 Trace 應該查詢熱庫還是冷庫。
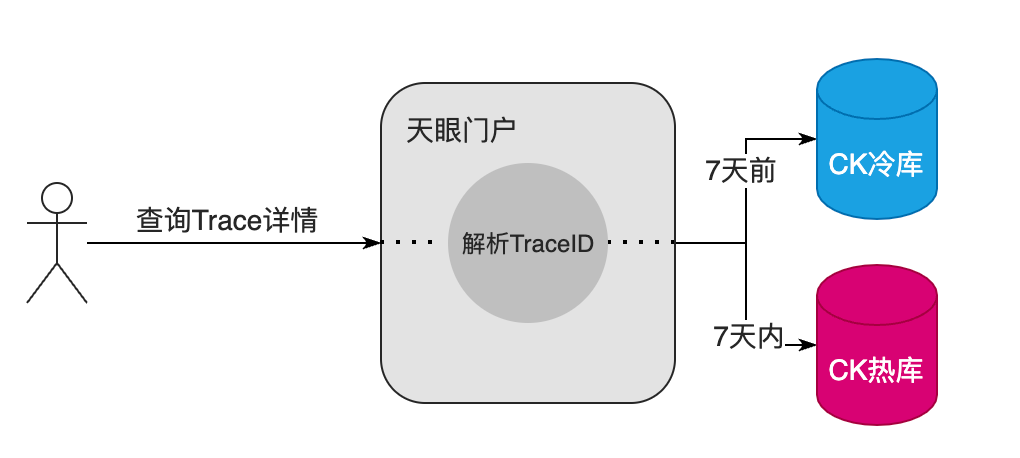
綁定實例 IP,有助于關聯當前 Trace 流量入口所屬的實例,在某些極端場景,當鏈路上的節點檢索不到時,也能通過實例和時間兩個要素來做溯源。
3) 異步調用識別
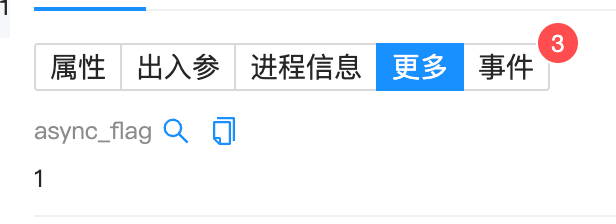
業務系統為了提高服務吞吐量,充分運用硬件資源,異步調用場景可謂無處不在。我們基于Otel實現的異步鏈路上下文傳遞的基礎上,額外擴充了"async_flag"字段來標識當前節點相對于父節點的調用關系,從而在展示層上能迅速找出發生異步調用的場景
3.4.3 更清晰的調用鏈結構
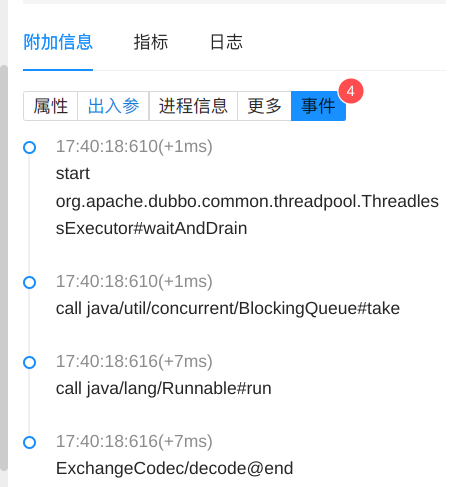
在 Otel 支持的部分組件中,有些操作不涉及到網絡調用,或者具有非常頻繁的操作,如 MVC 過程,數據庫連接獲取等,通常來說這類節點在鏈路詳情主視圖中的意義不大,因此我們對這類節點的產生邏輯進行了優化調整,使得整個鏈路主體結構聚焦于“跨端”,同時,對部分核心組件關鍵內部方法細節做了增強,以“事件”的形式掛載于它們的父節點上,便于更細粒度的排查:
RPC 調用關鍵內部事件
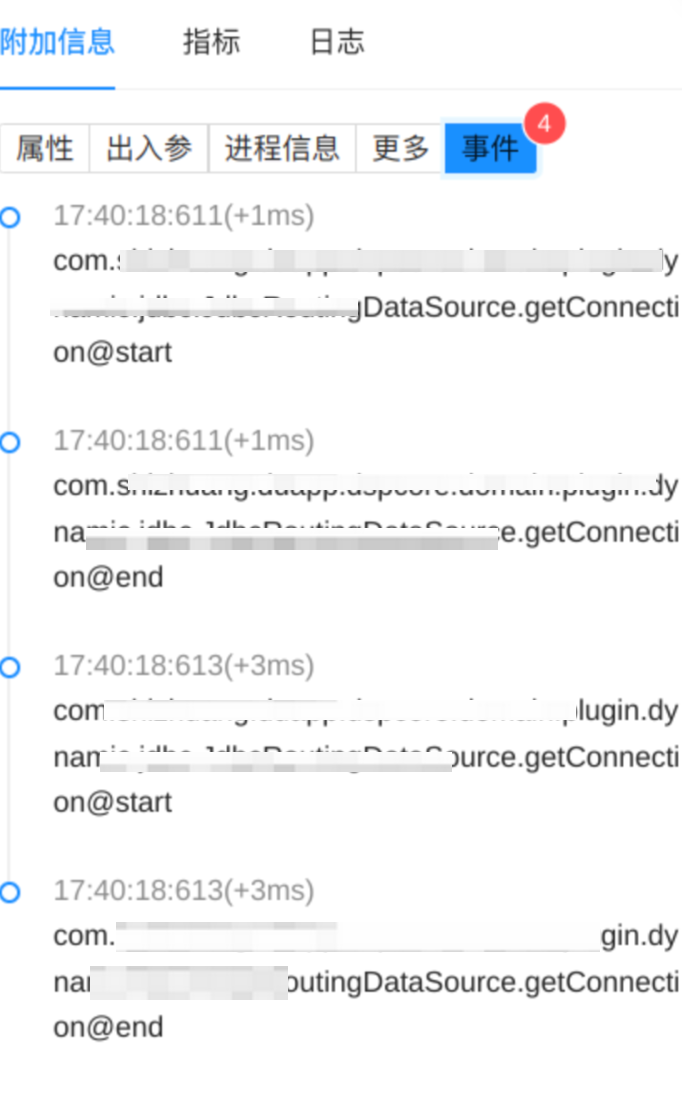
DB 調用連接獲取事件
3.4.4 profiling 的支持
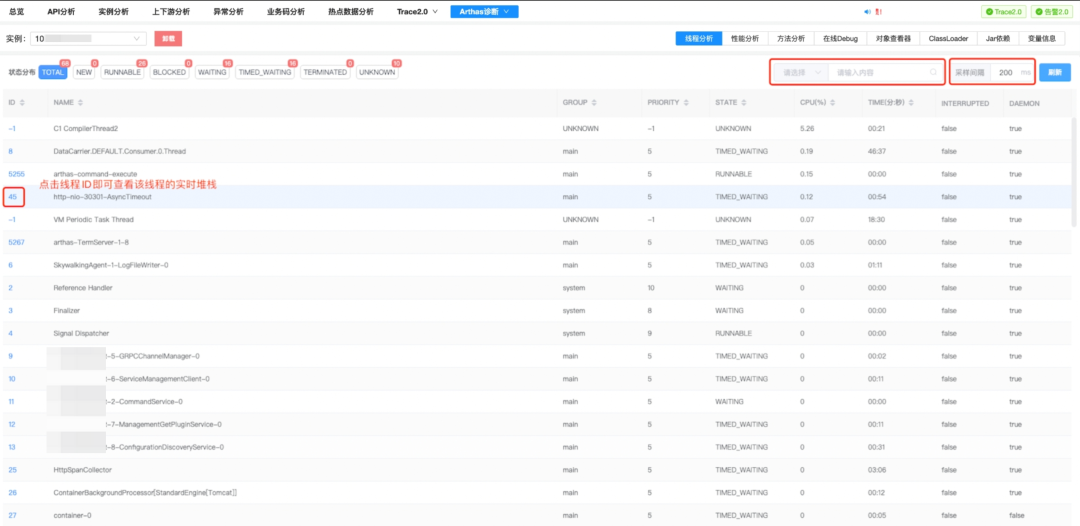
1)線程棧分析的集成。通過集成 Arthas 這類工具,可以很方便地查看某個實例線程的實時堆棧信息,同時對采樣間隔做控制,避免頻繁抓取影響業務自身性能。
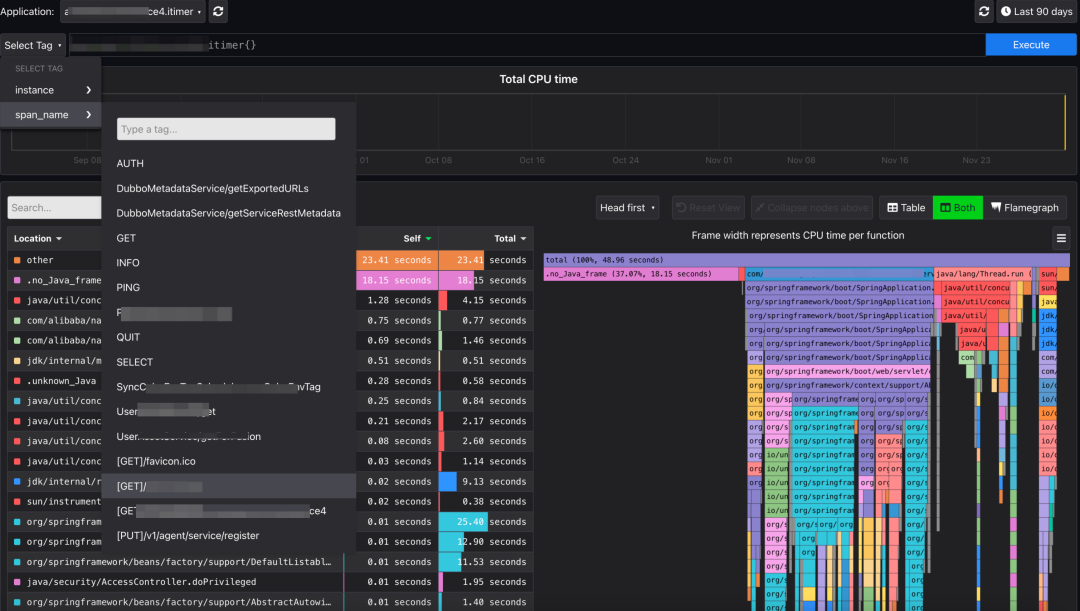
2)通過集成 pyroscope,打通高延遲性能排查最后一公里。Pyroscope 對 async profiler 做了二次開發,同時也支持 Otel 去集成,但截至目前,官方并沒有實現完整的 Profiling 行為的生命周期,而 Profiling 行為一定程度上會影響性能,于是我們對官方 Pyroscope 的生命周期做了擴展,實現“停止”行為的同時,采用時間輪算法來檢測特定操作的耗時,當達到期望的閾值將觸發開啟 profiling, 待操作結束或超過最大閾值則停止。

關于性能診斷相關的運用,請期待后續診斷專題。
4
0xff 結語
縱觀得物在應用監控采集領域的三大里程碑迭代,第一階段的 CAT 則是 0~1 的過程,它提供了應用服務對自身觀測的途徑,讓業務方第一次真實地了解了服務運行狀況,而第二階段開始,隨著業務發展的飛速提升,業務方對監控系統的要求就不僅只是從無到有了,而是要精細,準確。
因此,快速迭代的背景下,功能與架構演進層面的矛盾,加上外部云原生大背景下可觀測領域的發展因素,促使我們進行了基于 OpenTelemetry 體系的第三階段的演進。功能,產品層面均取得了優異的結果。如今,我們即將進行下一階段的演進,深度結合調用鏈與相關診斷工具,以第三階段為基礎,讓得物全鏈路追蹤技術正式邁入性能分析診斷時代。
審核編輯 :李倩
-
監控系統
+關注
關注
21文章
4033瀏覽量
181332 -
cat
+關注
關注
1文章
75瀏覽量
21539 -
微服務
+關注
關注
0文章
145瀏覽量
7673
原文標題:得物云原生全鏈路追蹤Trace2.0-采集篇
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
PolarDB×ADB雙擎驅動 華鼎冷鏈打造冷鏈數據智能反應堆
云原生在汽車行業的優勢
云原生AI服務怎么樣
云原生LLMOps平臺作用
如何選擇云原生機器學習平臺
什么是云原生MLOps平臺
梯度科技入選2024云原生企業TOP50榜單
軟通動力榮登2024云原生企業TOP50榜單
云原生和數據庫哪個好一些?
k8s微服務架構就是云原生嗎?兩者是什么關系
云原生和非云原生哪個好?六大區別詳細對比
京東云原生安全產品重磅發布
從積木式到裝配式云原生安全
基于DPU與SmartNic的云原生SDN解決方案





 工商網監
工商網監
評論