 王井東:大模型已經成為自動駕駛能力提升核心驅動力
王井東:大模型已經成為自動駕駛能力提升核心驅動力
百度Apollo Day技術開放日
2022年11月29日,百度Apollo Day技術開放日活動線上舉辦。百度自動駕駛技術專家全景化展示Apollo技術實力及前沿技術理念,在業內首發文心大模型落地應用于自動駕駛的技術。
大模型技術是自動駕駛行業近年的熱議趨勢,但能否落地應用、能否用好是關鍵難題。百度自動駕駛依托文心大模型特色優勢,率先實現技術應用突破。百度自動駕駛技術專家王井東表示:文心大模型-圖文弱監督預訓練模型,背靠文心圖文大模型數千種物體識別能力,大幅擴充自動駕駛語義識別數據,如:特殊車輛(消防車、救護車)識別、塑料袋等,自動駕駛長尾問題解決效率指數級提升;此外,得益于文心大模型-自動駕駛感知模型10億以上參數規模,通過大模型訓練小模型,自動駕駛感知泛化能力顯著增強。
以下為演講全文
大家好,我是王井東,由我跟大家分享自動駕駛感知相關的內容,我演講的標題是:文心大模型在自動駕駛感知中的落地應用。
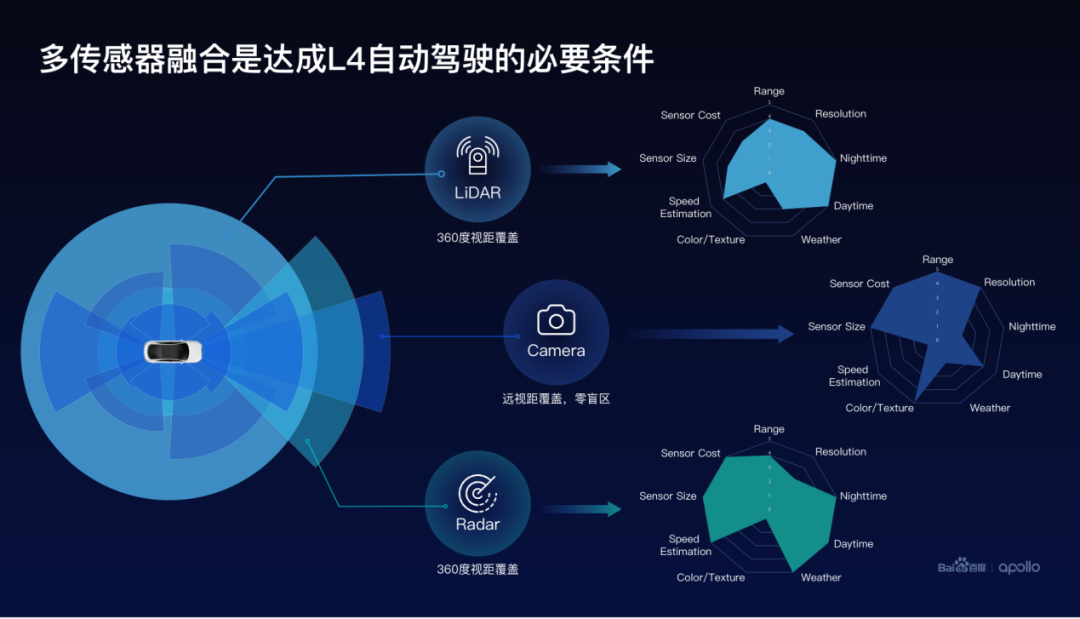
百度認為傳感器融合是實現L4自動駕駛的必要條件,激光點云、毫米波雷達和攝像頭這三種傳感器是如何實現互補關系的。激光點云和毫米波雷達點云不能夠提供很豐富的顏色信息和紋理信息,使得點云的識別效果一般。攝像頭可以提供豐富的顏色紋理等信息,能夠幫助提升語義識別的效果。
那激光點云和攝像頭在天氣不佳的條件下,如雨雪天氣,感知效果受到限制,這個時候毫米波雷達點云仍然能夠提供很好的效果,那毫米波雷達點云相對而言噪聲比較大,分辨率比較低,這個時候雷達和攝像頭提供了分辨率非常高的互補信息。
除此以外,攝像頭相對遠距離的感知效果比較友好。
百度自動駕駛感知經歷了兩代,第一代感知1.0,在感知1.0經過了三個階段:
第一階段
主要依賴激光雷達點云感知,輔助紅綠燈的識別,同時利用了毫米波目標陣列。
第二階段
增加了環視圖像的感知,與激光雷達點云感知形成了兩層的感知融合,提升了識別效果。
第三階段
自研了毫米波點云感知算法,形成了三層感知的融合,那這些多模感知實際上用的是后融合的方案。
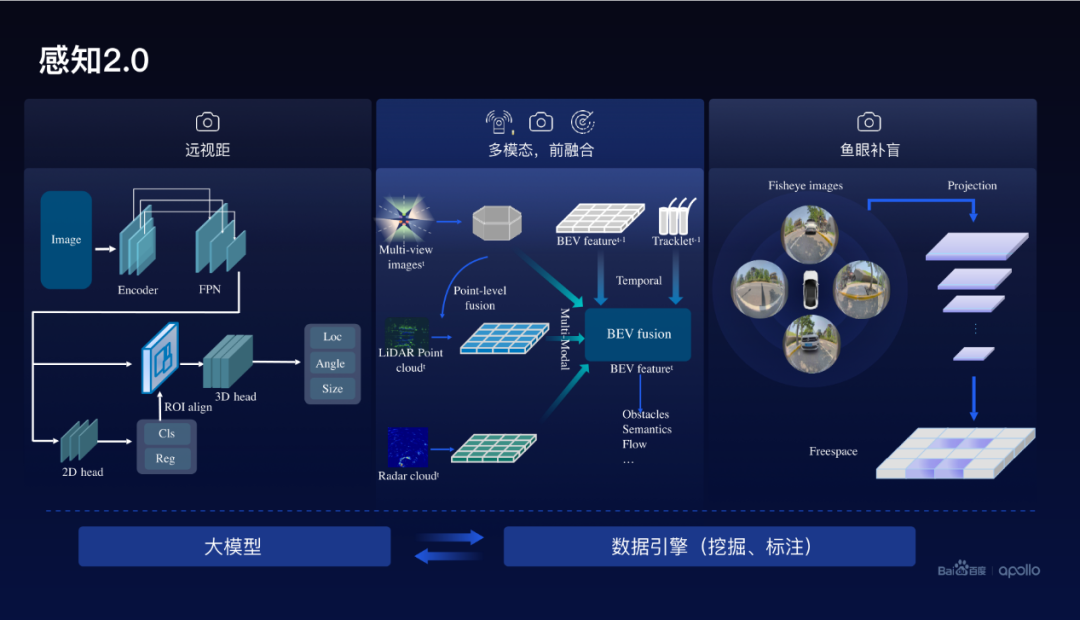
在后融合方案里面通常需要規則的方法,把這三種傳感器的感知結果融合在一起,那這種基于規則的方法是不可學習的,它相對而言它的泛化能力不夠。基于此,百度開發了基于前融合方案的新一代感知2.0。

感知2.0主要的一個部分是多模態前融合端到端的方案,在點云和圖像的表征層次上進行融合。除此以外,還包括遠視距的視覺感知,通常在200米以上視覺的感知效果相對比較好。
另外,在近距離采用了魚眼感知,從魚眼感知實現了freespace的預測,百度把這三者有機的融合在一起,實現了近距離、中等距離和遠距離統統形成高質量的這種感知。
在做感知時候,需要豐富的數據、高質量的數據,基于此,百度在2.0還利用大模型進行數據挖掘和數據的自動標注。
下面看幾個例子,看看在自動駕駛感知里面遇到的一些挑戰。
首先遠距離的視覺感知,在較遠的地方,物體看起來是比較小的,分辨率是比較低的,這對識別和感知帶來非常大的挑戰。那在遠距離的情況下面,通常會遇到坡度比較大,對于感知也是非常大的挑戰。大部分的數據都是地平面的,道路是平的,那這里面往往會利用了地平面接地這樣一個重要的性質,去實現遠距離物體的感知。

下面再看看第二個挑戰,因為我們采用的激光雷達傳感器不斷的升級,那點云的空間分布也產生了非常大的變化,在早先激光雷達傳感器基于威力登,后來我們升級為兩種型號的禾賽,目前正在考慮啟用半固態的傳感器,這些傳感器升級帶來了點云空間的分布的變化,從原來的稀疏到現在的稠密,在點云空間去做3D的標注是非常困難的,能不能把以前舊的傳感器的標注在新的傳感器能很好利用起來,也成為技術上的一個重要挑戰。

下面是長尾數據挖掘的問題,這里面舉了三類典型的例子:
第一類是少見的車型,比如說異形車出現的頻率比較低,通常這種異型車它的形態、形狀不太規則,甚至有時候會有一些突出的部件,那這個時候會為感知、理解帶來挑戰,很難很好地定位這些異形車的空間位置以及距離。
第二類是各種形態、各種姿態的行人,這個時候可能是一群人在道路上面,這樣會帶來非常大的挑戰,同時也為后面的預測跟蹤帶來很大的挑戰。
第三類是低矮物體以及交通、施工的元素,那低矮物體一直是感知里面非常有挑戰的問題,那我們在實踐過程里面你會發現一些施工元素會對我們自動駕駛感知帶來一些問題,比如說道路中間的護欄,其實往往意味著這條路可能是不可通行的,那我們需要識別這樣的道路施工元素。

那如何解決剛才提到的這三種挑戰呢?百度利用了大模型技術來提升自動駕駛感知的能力,從兩個方面去解決這個自動駕駛感知遇到的挑戰。
第一個,利用文心大模型自動駕駛感知的技術,來提升車載小模型的感知能力,另外,在數據方面,利用了文心大模型圖像弱監督預訓練的模型來挖掘長尾數據,來提升模型訓練的效果。

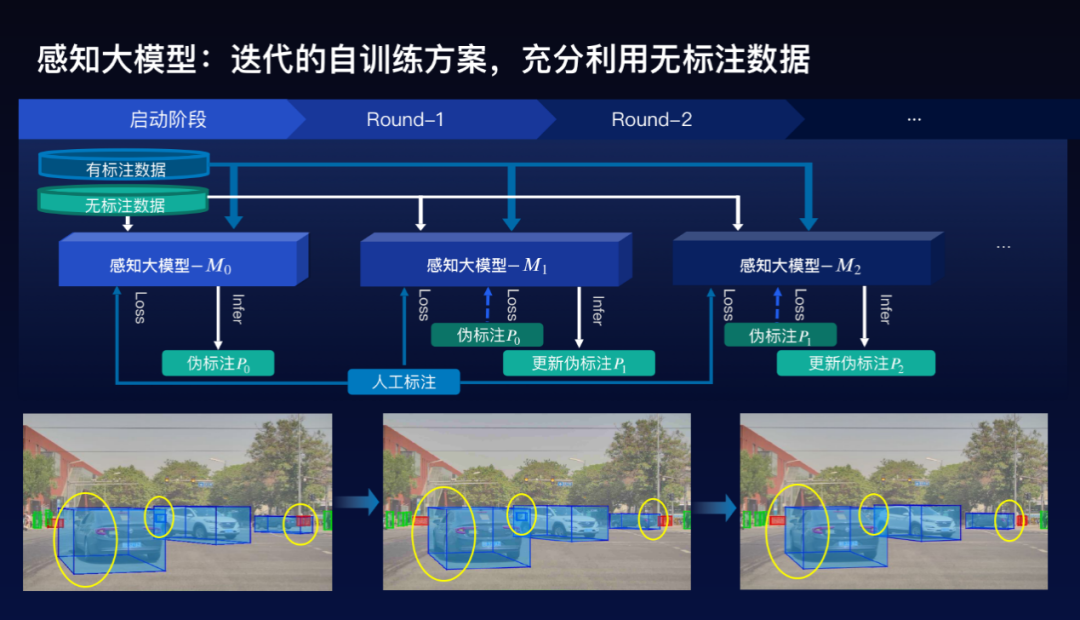
這個自動駕駛感知大模型是怎么訓練的。在自動駕駛感知里面,需要標注大量的數據,但是在這里面,往往相對而言容易獲得千萬量級的2D的標注數據,但對3D的標注數據來講相對比較困難,如何利用這些沒有3D標注的數據是成為一個很大的挑戰,百度采用半監督的方法來充分利用2D的標注和沒有3D標注的數據。
具體方案是采用迭代的自訓練方案。首先是在既有2D又有3D的訓練數據上面,去訓練一個感知大模型,給那些沒有3D標注的數據打上3D偽標注。然后再繼續訓練一個感知大模型出來,如此迭代,逐步把感知大模型的效果提升,同時也使得3D尾標注的效果越來越好,可以看到下面的三個圖的例子,結果實際上是變得越來越好。
這樣的一個感知大模型,不僅用于視覺,也用于點云,也用于我們后面要講的多模態端到端的方案。
在這個遠視覺感知方案里面,實際上也利用了編碼器和解碼器的預訓練方案,利用了公開的數據集Object 365和COCO這樣的預訓練。
那這里要提一下的是,百度基于這么一個編碼器和解碼器預訓練的方案,采用的方法Group DETR v2,實際上在標準的公開數據集上面首次突破了64.5mAP的一個效果。
我們看看大模型在三個方面的應用,首先是在遠視距方面。

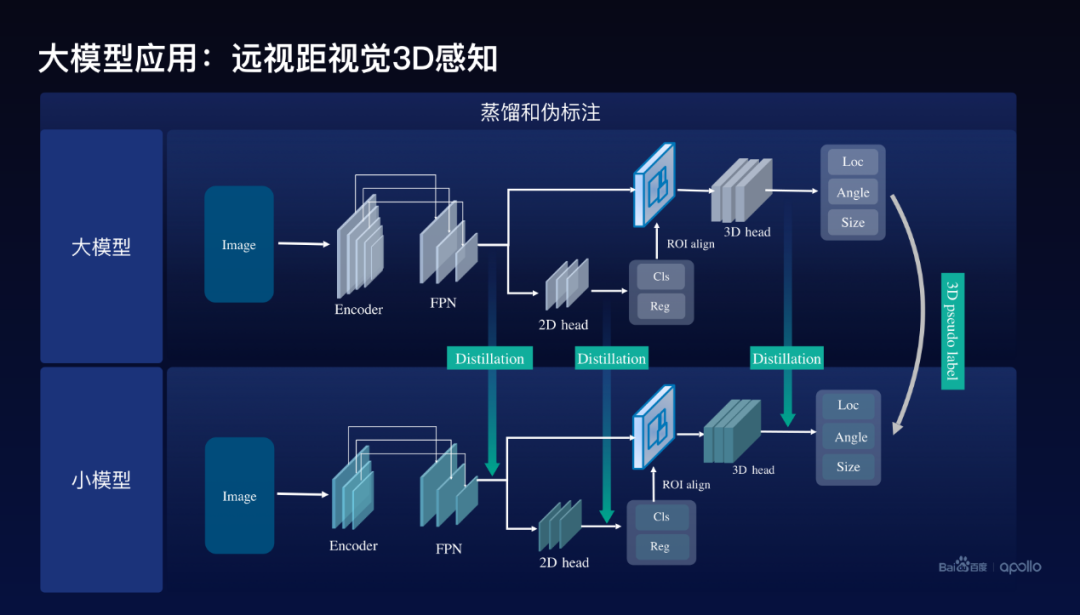
大模型怎么去幫助小模型,百度采用的方案是基于蒸餾和偽標注的方案,偽標注通過剛才訓練好的感知大模型,給這個圖像打上3D的偽標注,同時使用了蒸餾方案。在網絡架構里面通常會包含編碼器。還有2D檢測的Head,以及3D檢測的Head,百度分別在三個地方使用了蒸餾,第一個是在編碼器出來的地方,用大模型的特征去幫助訓練小模型的特征,除此以外在2D的Head上面與3D的Head上面分別去做大模型到小模型特征的蒸餾。
這里我們實際上在訓練這個模型的時候還使用了這么一個小的技巧,就是把大模型的Detection head,包括2D、3D里面的參數,直接作為小模型的初始化,進一步地提升訓練的效率和效果。
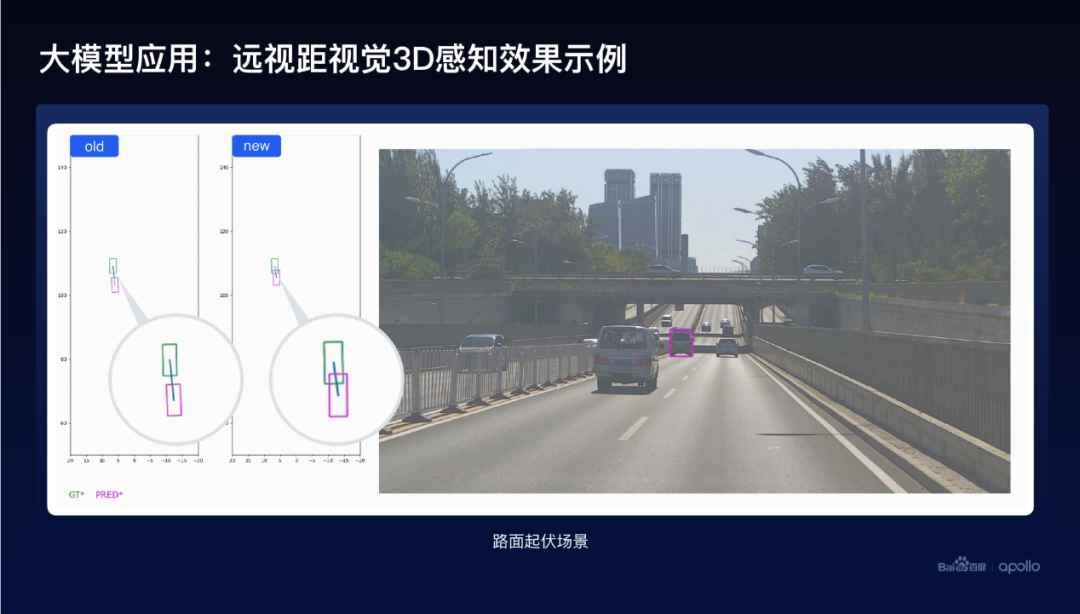
大模型幫助小模型帶來了一個效果,遠視距3D感知帶來的效果,遮擋的場景可以看到這個圖里面,左邊綠色的框是對應的Ground truth,紅色的是預測的,對比一下在舊模型和新模型的對比可以看到,新模型的效果從感知、預測車輛的距離等方面,效果提升是非常明顯的。
再看一看道路起伏的例子,仍然可以看到左邊這個舊模型和新模型效果的對比,跟前面對比起來,不僅僅預測的物體的車輛的距離變得更準確了,同時這個車輛的方向也預測得會更好,它的角度也會更好。

這邊僅僅給大家展示了兩個例子,在實際里面會發現更多非常好的效果,下面看看大模型在多模態前融合端到端感知上面的一個應用。多模態前融合的方案對應的大模型實際上是用前面我們講到的方案,通過半監督的方案,迭代的自訓練的方案去訓練出來的。
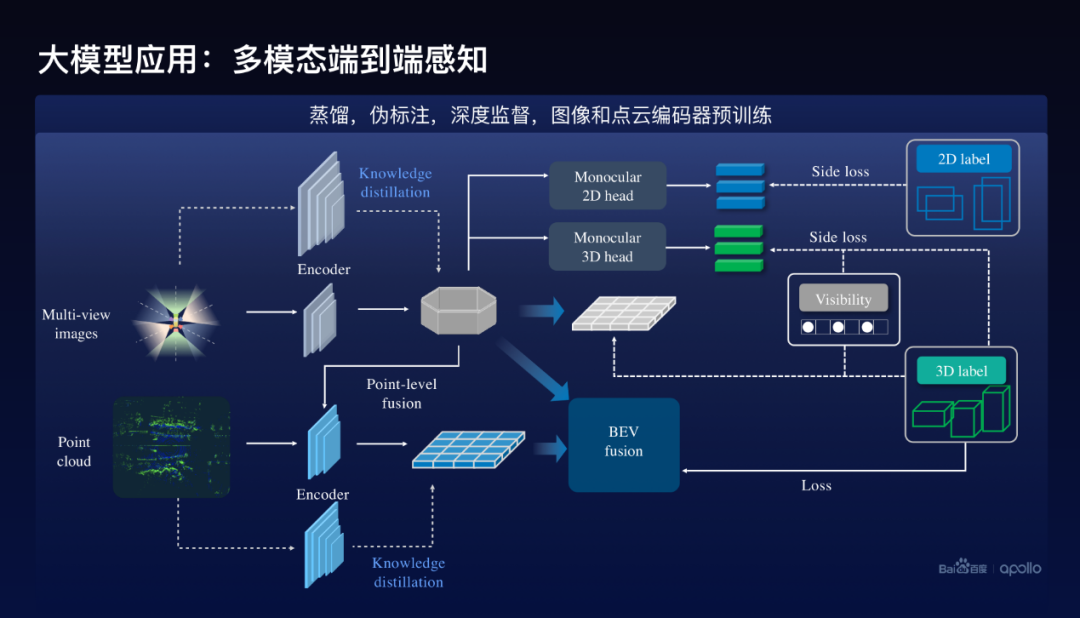
在這個地方怎么去幫助小模型的訓練呢?除了蒸餾方案以外,在編碼器做蒸餾以外,也使用了偽標注,就是用大模型對數據進行偽標注,然后去幫助訓練。這里面要特別提到的其他幾點:第一個我們使用了深度監督的方法,分別在圖像端和點云端做了3D的預測,比如說在圖像端對每個圖像進行2D的跟3D的預測,我們稱之為Side loss,這樣能夠很好的提升訓練的效果。
還有一點百度還使用了預訓練的方案,因為在多模態方案里面,既有圖像的編碼器,也有點云的編碼器,這個時候圖像的編碼器實際上不是在多模態下面訓練出來的編碼器,來作為它的初始化,類似的點云也是同樣。

要跟大家分享的是,把這樣的一個方案降級到多視角圖像的端到端的感知里面去。這樣一個方案,在公開的nuScenes數據集上面取得了非常好的一個效果,目前在nuScenes 3D檢測里面multi-view的情況下面取得了最好的效果,能夠把這樣的一個方案應用到nuScenes里面的跟蹤tracking里面去,也取得了非常好的效果。現在目前是在這個tracking榜單里面排名第一的。
那下面看看點云感知的效果,在多模態前融合方案里面,我們使用了點云感知的編碼器的預訓練,如果只是在點云里面使用大模型的方案帶來了一個效果,這里面我們可以看到從舊模型和新模型的對比,在路測的誤檢方面我們改進得非常多,同時在中間的比如說綠化硬隔離帶也會有一些誤檢,那這樣子我們通過大模型幫助小模型以后,可以解決很多問題。

下面看看多模態前融合感知的整體的效果,這里舉了一個非常困難的一個例子,大家看看左邊實際上是一個灑水車,灑水車的前面實際上有噴霧。那在舊的方案里面,如果沒有使用我們這個多模態前融合端到端的方案,很容易把這個噴霧識別成車輛,但是用了新方案以后,這樣的誤檢就會消失。
最后看看大模型在數據挖掘里面的使用,這是整個自動駕駛感知的數據閉環的流程圖。這里主要分享一下數據挖掘方面的這么一個技術。


在數據挖掘里面采用了大模型的方案,跟前面的感知的方案相關,但不完全一樣,這使用了基于圖文弱監督預訓練模型去幫助做長尾數據的挖掘。怎么去做預訓練的模型,通常里面會有大量的圖文,把圖像送到一個我們稱之為圖像編碼器里面去,圖文對里面對應的文本也送到文本編碼器里面,通過優化所謂的對比損失來訓練這個文本編碼器和圖像編碼器。
這樣訓練出來的編碼器有非常好的一個效果,可以處理稱之為開放集的語義識別,不同于傳統的比如說在ImageNet上面,通常ImageNet-1K可以處理1000類,那這樣訓練出來的圖文預訓練模型可以處理1000類以外,甚至成千上萬的類別,正是利用了這么一個性質去幫助做數據挖掘。
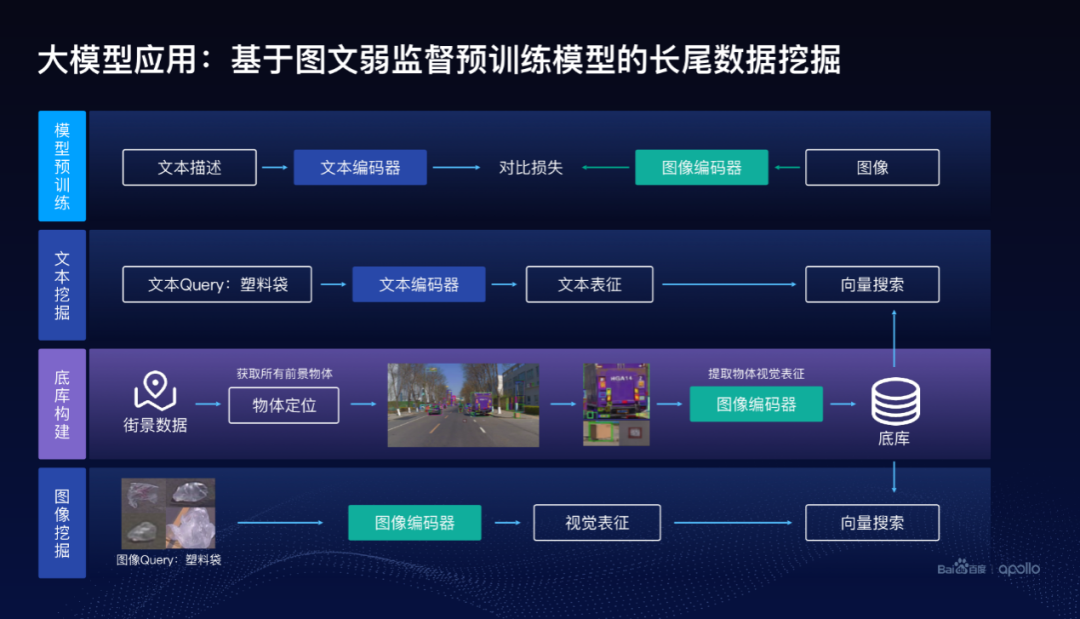
當訓練好這么一個模型以后,在自動駕駛數據庫里面,經過我們的底庫構建,怎么做呢?
我們把街景數據,比如這里面圖像,首先做一步物體定位,把這個圖像里面可能的物體都給找出來,這里面使用了叫Group DETRv2的檢測方案,很好地把可能的物體給定位出來。把可能的物體定位出來以后,物體所在的圖像塊摳出來,放到圖像編碼器里面,形成一個向量,這就是底庫的構建。
做數據挖掘的時候可以采用兩種:一種是沒有所需要挖掘的圖像時,可以直接通過文本去進行挖掘,比如,把塑料袋輸入到文本編碼器里面,形成一個文本特征,變成一個文本表征的向量,然后通過快速的向量搜索算法,在底庫里面很快找到可能是塑料袋的圖像出來。
慢慢的已經找到了一些塑料袋圖像以后,這個時候也可以把圖像輸入到圖像編碼器里面,抽取視覺表征,然后類似的進行向量搜索。
在這樣的過程中,剛開始搜索出來的圖像效果準確率不見得那么高,隨著搜索越來越多,回來的圖像數量越來越多,可以訓練一個稱之為fine classifier完成進一步的篩選,最終不斷地提升數據挖掘的效果。
看看數據挖掘一些例子,以及最終怎么幫助自動駕駛感知能力的提升呢?左邊是給了一些典型的例子。比如說小孩在路面上面,比如說快遞車、輪椅、地面上有塑料袋,還有消防車、救護車等,是百度在數據挖掘的例子。

在能力提升方面把它分為兩大類:一類是本來有這么一個能力,通過這樣的數據挖掘以后這個能力得到了很大的提升,比如說對兒童的檢測,比如說對塑料袋的誤檢,因為塑料袋檢測是非常重要的,如果說不能夠很好的把塑料袋跟其他的比如說非常硬的物體給區分開來,那對后面的PNC會帶來很大的挑戰,會容易出現急剎的情況。
另外一個能力的提升,就是說本來可能沒有這樣的能力,通過數據挖掘以后,就有這樣的能力了,比方說消防車和救護車這樣的例子,以前可能并不區分消防車和救護車,消防車和救護車在路上會有較高的路權,這個時候如果很好地把它識別出來以后,對后面下游的駕駛策略調整會起到很大的幫助。
另外一個,在實踐里面就會發現一些有意思的現象,道路上有時候會出現一些小動物,比如說我們在成都二環路上會發現,成都二環路上的馬,還有我們在路上會發現少見的羊群,比如說我們在順義區路上會發現的羊群,這樣都是感知長尾問題,通過這樣的數據挖掘,現在有了這個能力,充分增強了自動駕駛感知的效果。
最后,我用這么一句話來結束我今天的報告。大模型,已經成為自動駕駛能力提升的核心驅動力。
審核編輯 :李倩
-
自動駕駛
+關注
關注
788文章
14206瀏覽量
169597 -
毫米波雷達
+關注
關注
107文章
1083瀏覽量
65177 -
Apollo
+關注
關注
5文章
347瀏覽量
18709 -
大模型
+關注
關注
2文章
3030瀏覽量
3834
原文標題:百度Apollo Day|王井東:大模型已經成為自動駕駛能力提升核心驅動力
文章出處:【微信號:baiduidg,微信公眾號:Apollo智能駕駛】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛安全基石:ODD
新能源車軟件單元測試深度解析:自動駕駛系統視角

“兩會”熱議“機器人和飛行汽車”,核心動力電機可能會火
自動駕駛大模型中常提的Token是個啥?對自動駕駛有何影響?
小馬智行開通廣州自動駕駛示范運營專線
自動駕駛規控算法驗證到底需要什么樣的場景仿真軟件?

標貝科技:自動駕駛中的數據標注類別分享

標貝科技:自動駕駛中的數據標注類別分享

連接視覺語言大模型與端到端自動駕駛

激光雷達與純視覺方案,哪個才是自動駕駛最優選?
速程精密直線旋轉執行器:工業自動化的核心驅動力
新能源自動駕駛編隊運輸聯盟成立,圖達通攜手卡爾動力共塑自動駕駛貨運新未來






 工商網監
工商網監
評論