") 用于視覺識別的Transformer風格的ConvNet
用于視覺識別的Transformer風格的ConvNet
本文旨在通過充分利用卷積探索一種更高效的編碼空域特征的方式:通過組合ConvNet與ViT的設計理念,本文利用卷積調(diào)制操作對自注意力進行了簡化,進而構(gòu)建了一種新的ConvNet架構(gòu)Conv2Former。ImageNet分類、COCO檢測以及ADE20K分割任務上的實驗結(jié)果表明:所提Conv2Former取得了優(yōu)于主流ConvNet(如ConvNeXt)、ViT(如Swin Transformer)的性能。
本文方案
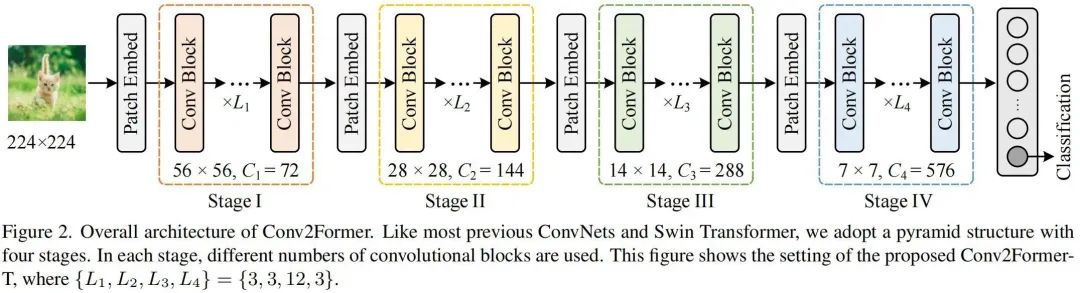
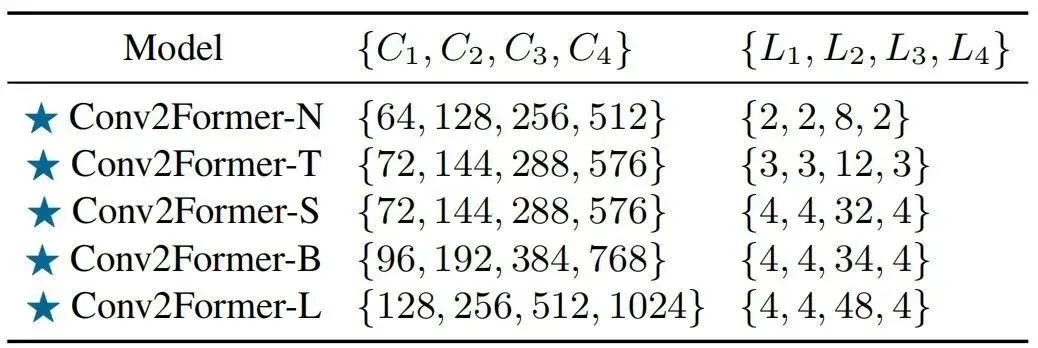
上圖給出了本文方案架構(gòu)示意圖,類似ConvNeXt、SwinT,Conv2Former采用了金字塔架構(gòu),即含四個階段、四種不同尺寸的特征,相鄰階段之間通過Patch Embedding模塊(其實就是一個卷積核與stride均為的卷積)進行特征空間分辨率與通道維度的惡變換。下表給出了不同大小Conv2Former的超參配置,
核心模塊
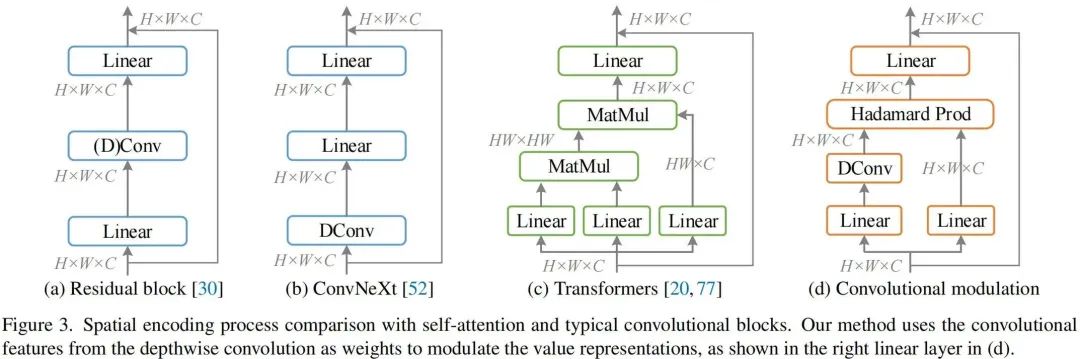
上圖給出了經(jīng)典模塊的架構(gòu)示意圖,從經(jīng)典的殘差模塊到自注意力模塊,再到新一代卷積模塊。自注意力模塊可以表示為如下形式:
盡管注意力可以更好的編碼空域相關(guān)性,但其計算復雜性隨N而爆炸性增長。
本文則旨在對自注意力進行簡化:采用卷積特征對V進行調(diào)制。假設輸入,所提卷積調(diào)制模塊描述如下:
需要注意的是:上式中表示Hadamard乘積。上述卷積調(diào)制模塊使得每個位置的元素與其近鄰相關(guān),而通道間的信息聚合則可以通過線性層實現(xiàn)。下面給出了該核心模塊的實現(xiàn)代碼。
classConvMod(nn.Module):
def__init__(self,dim):
super().__init__()
self.norm=LayerNorm(dim,eps=1e-6,data_format='channel_first')
self.a=nn.Sequential(
nn.Conv2d(dim,dim,1),
nn.GELU(),
nn.Conv2d(dim,dim,11,padding=5,groups=dim)
)
self.v=nn.Conv2d(dim,dim,1)
self.proj=nn.Conv2d(dim,dim,1)
defforward(self,x):
B,C,H,W=x.shape
x=self.norm(x)
a=self.a(x)
v=self.v(x)
x=a*v
x=self.proj(x)
returnx
微觀設計理念
Larger Kernel than 如何更好的利用卷積對于CNN設計非常重要!自從VGG、ResNet以來,卷積成為ConvNet的標準選擇;Xception引入了深度分離卷積打破了該局面;再后來,ConvNeXt表明卷積核從3提升到7可以進一步改善模型性能。然而,當不采用重參數(shù)而進一步提升核尺寸并不會帶來性能性能提升,但會導致更高計算負擔。
作者認為:ConvNeXt從大于卷積中受益極小的原因在于使用空域卷積的方式。對于Conv2Former,從到,伴隨核尺寸的提升可以觀察到Conv2Former性能一致提升。該現(xiàn)象不僅發(fā)生在Conv2Former-T(),同樣在Conv2Former-B得到了體現(xiàn)()。考慮到模型效率,作者將默認尺寸設置為。
Weighting Strategy 正如前面圖示可以看到:作者采用Depthwise卷積的輸出對特征V進行加權(quán)調(diào)制。需要注意的是,在Hadamard乘積之前并未添加任務規(guī)范化層(如Sigmoid、),而這是取得優(yōu)異性能的重要因素(類似SENet添加Sigmoid會導致性能下降超0.5%)。
Normalization and Activations 對于規(guī)范化層,作者參考ViT與ConvNeXt采用了Layer Normalization,而非卷積網(wǎng)絡中常用的Batch Normalization;對于激活層,作者采用了GELU(作者發(fā)現(xiàn),LN+GELU組合可以帶來0.1%-0.2%的性能提升)。
本文實驗
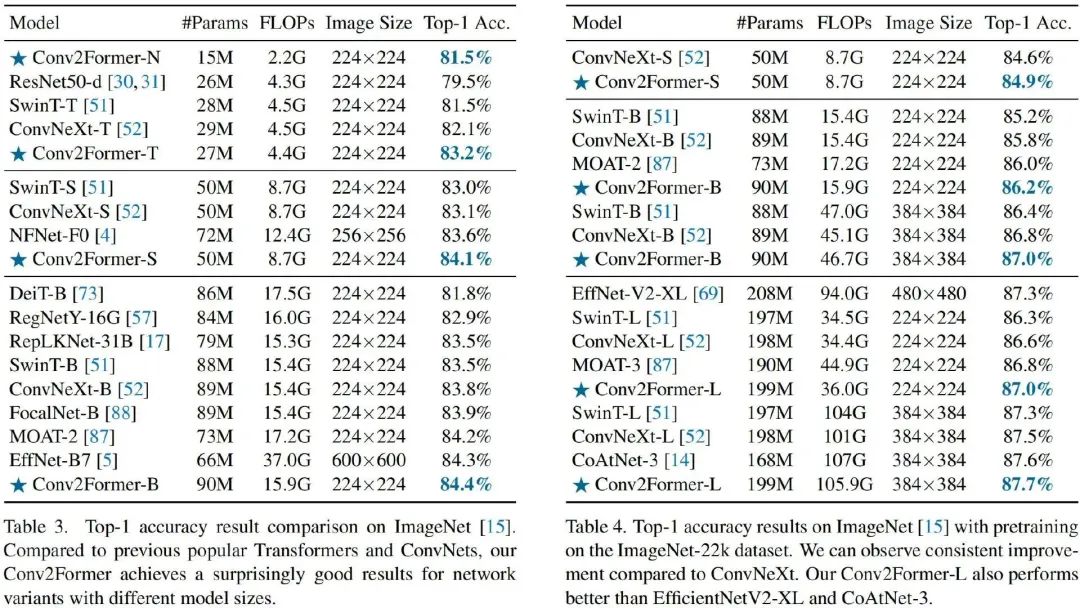
上述兩表給出了ImageNet分類任務上不同方案的性能對比,從中可以看到:
-
在tiny-size(<30M)方面,相比ConvNeXt-T與SwinT-T,Conv2Former-T分別取得了1.1%與1.7%的性能提升。值得稱道的是,Conv2Former-N僅需15M參數(shù)量+2.2GFLOPs取得了與SwinT-T(28M參數(shù)量+4.5GFLOPs)相當?shù)男阅堋?/p>
-
在base-size方面,相比ConvNeXt-B與SwinT-B,Conv2Former-B仍取得了0.6%與0.9%的性能提升。
-
相比其他主流模型,在相近大小下,所提Conv2Former同樣表現(xiàn)更優(yōu)。值得一提的是,相比EfficientNet-B7,Conv2Former-B精度稍有(84.4% vs 84.3%),但計算量大幅減少(15G vs 37G)。
-
當采用ImageNet-22K預訓練后,Conv2Former的性能可以進一步提升,同時仍比其他方案更優(yōu)。Conv2Former-L甚至取得了87.7% 的優(yōu)異指標。
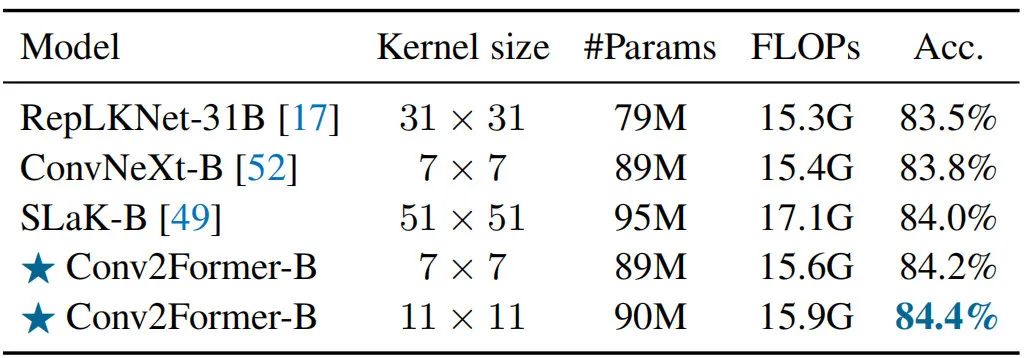
采用大核卷積是一種很直接的輔助CNN構(gòu)建長程相關(guān)性的方法,但直接使用大核卷積使得所提模型難以優(yōu)化。從上表可以看到:當不采用其他訓練技術(shù)(如重參數(shù)、稀疏權(quán)值)時,Conv2Former采用時已可取得更好的性能;當采用更大的核時,Conv2Former取得了進一步的性能提升。
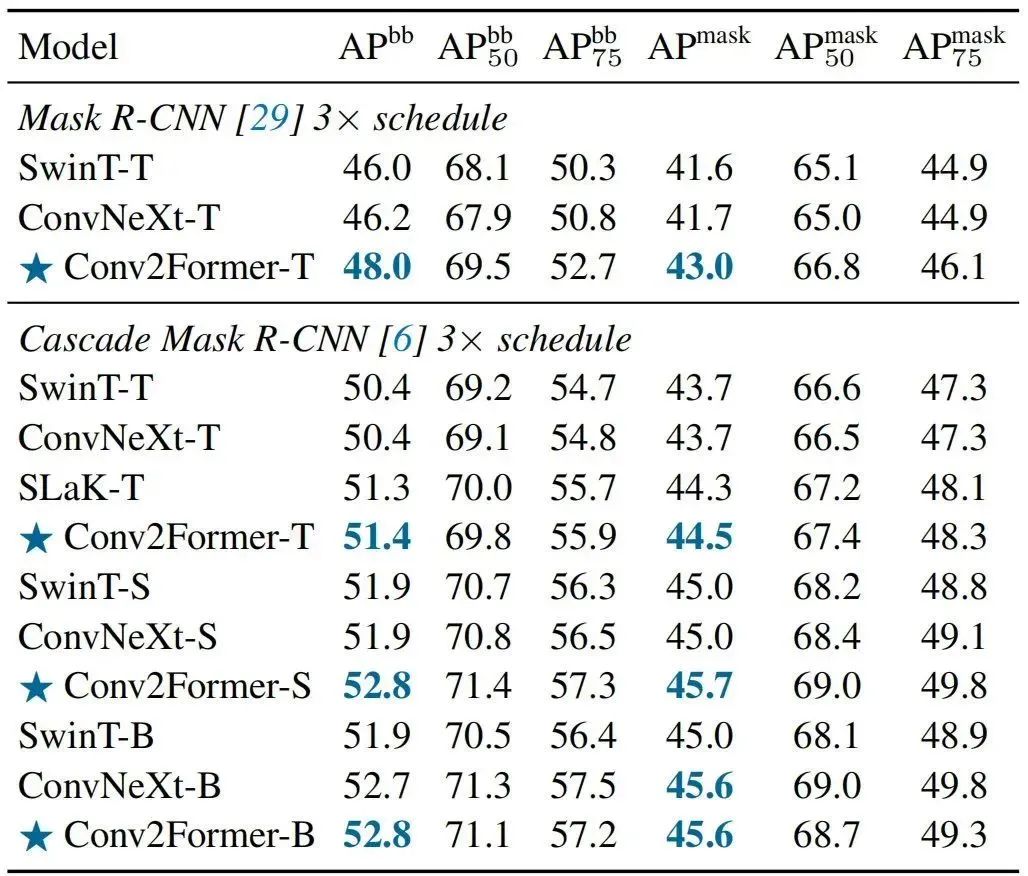
上表給出了COCO檢測任務上不同方案的性能對比,從中可以看到:
-
在tiny-size方面,相比SwinT-T與ConvNeXt-T,Conv2Former-T取得了2% 的檢測指標提升,實例分割指標提升同樣超過1%;
-
當采用Cascade Mask R-CNN框架時,Conv2Former仍具有超1%的性能提升。
-
當進一步增大模型時,性能優(yōu)勢則變得更為明顯;
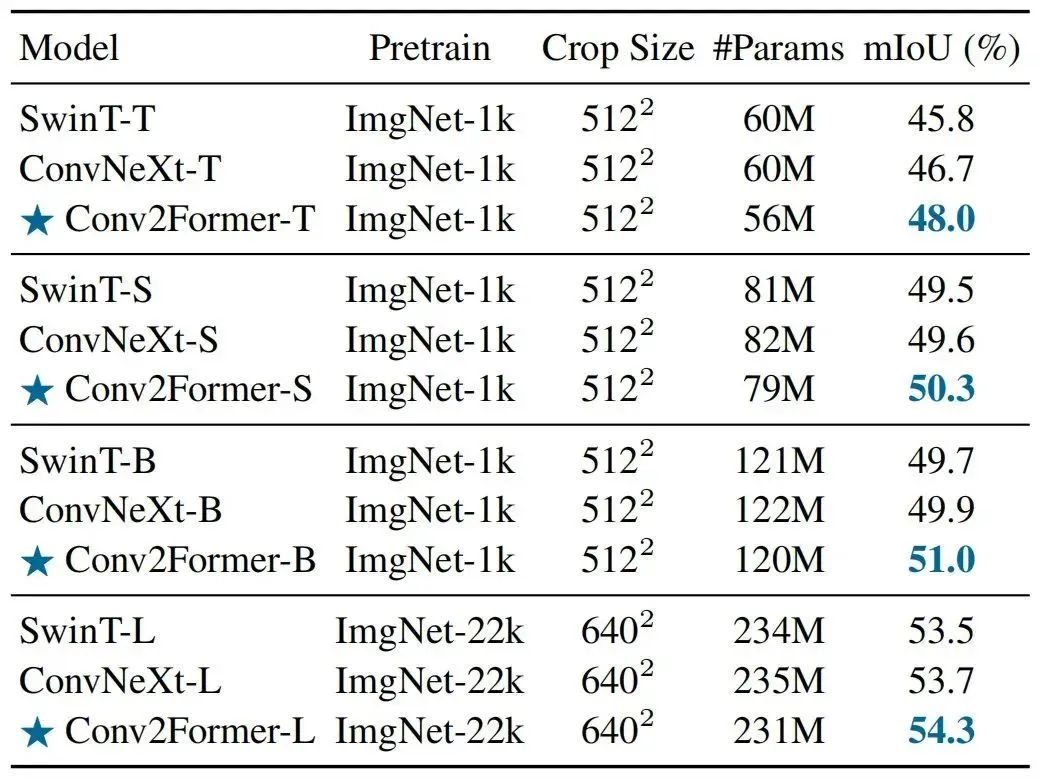
上表給出了ADE20K分割任務上的性能對比,從中可以看到:
-
在不同尺度模型下,Conv2Former均具有比SwinT與ConvNeXt更優(yōu)的性能;
-
相比ConvNeXt,在tiny尺寸方面性能提升1.3%mIoU,在base尺寸方面性能提升1.1%;
-
當進一步提升模型尺寸,Conv2Former-L取得了54.3%mIoU,明顯優(yōu)于Swin-L與ConvNeXt-L。
一點疑惑解析
到這里,關(guān)于Conv2Former的介紹也就結(jié)束了。但是,心里仍有一點疑惑存在:Conv2Former與VAN的區(qū)別到底是什么呢?關(guān)于VAN的介紹可參考筆者之前的分享:《優(yōu)于ConvNeXt,南開&清華開源基于大核注意力的VAN架構(gòu)》。
先來看一下兩者的定義,看上去兩者并無本質(zhì)上的區(qū)別(均為點乘操作),均為大核卷積注意力。
-
VAN:
-
Conv2Former
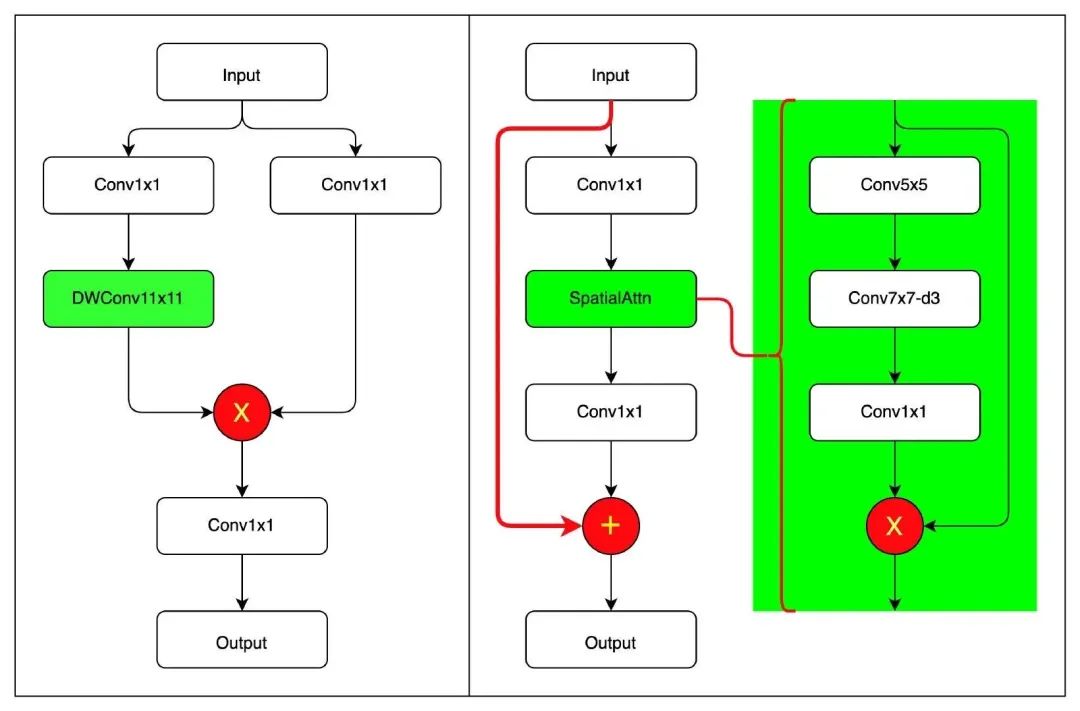
結(jié)合作者開源代碼,筆者繪制了上圖,左圖為Conv2Former核心模塊,右圖為VAN核心模塊。兩者差別還是比較明顯的!
-
雖然大核卷積注意力均是其核心,但Conv2Former延續(xù)了自注意力的設計范式,大核卷積注意力是其核心;而VAN則是采用傳統(tǒng)Bottleneck設計范式,大核卷積注意力的作用類似于SE。
-
從大核卷積內(nèi)在機理來看,Conv2Former僅考慮了的空域建模,而VAN則同時考慮了空域與通道兩個維度;
-
在規(guī)范化層方面,Conv2Former采用了Transformer一貫的LayerNorm,而VAN則采用了CNN一貫的BatchNorm;
-
值得一提的是:兩者在大核卷積注意力方面均未使用Sigmoid激活函數(shù)。兩者均發(fā)現(xiàn):使用Sigmoid激活會導致0.2%左右的性能下降。
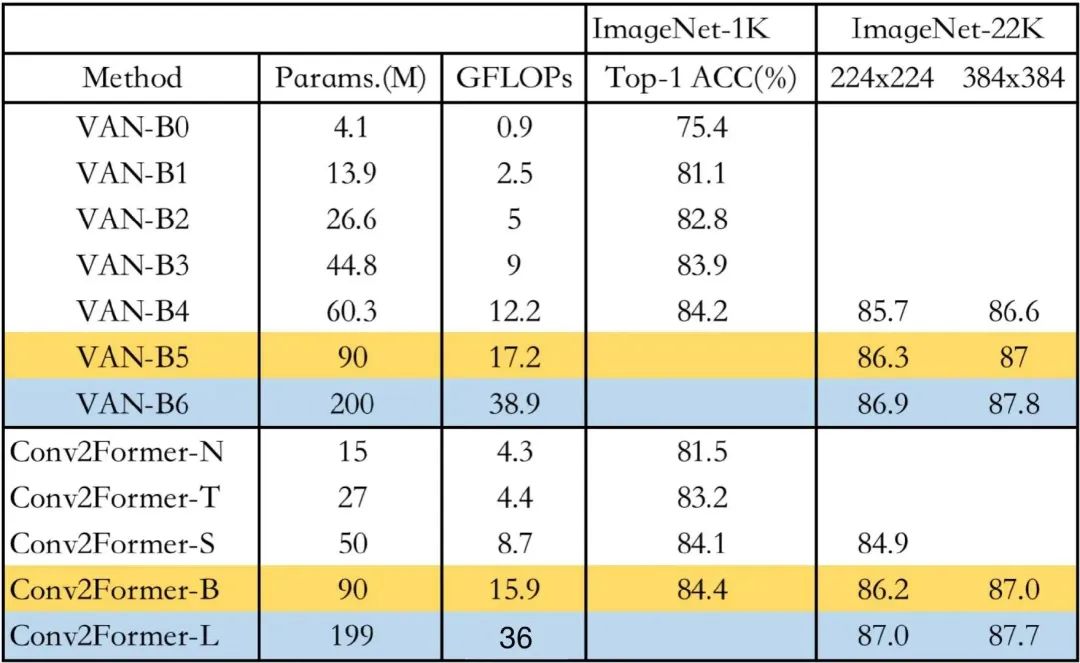
為更好對比Conv2Former與VAN的性能,特匯總上表(注:GFLOPs列僅匯總了)在Image輸入時的計算量Net-1K上的指標進行了對比,可以看到:在同等參數(shù)量前提下,兩者基本相當,差別僅在0.1%。此外,考慮到作者所提到的“LN+GELU的組合可以帶來0.1%-0.2%的性能提升”,兩者就算是打成平手了吧,哈哈。
審核編輯 :李倩
-
模塊
+關(guān)注
關(guān)注
7文章
2783瀏覽量
49643 -
編碼
+關(guān)注
關(guān)注
6文章
967瀏覽量
55513 -
視覺識別
+關(guān)注
關(guān)注
3文章
103瀏覽量
16978
原文標題:超越ConvNeXt!Conv2Former:用于視覺識別的Transformer風格的ConvNet
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于LockAI視覺識別模塊:C++條碼識別
基于LockAI視覺識別模塊:C++條碼識別

基于LockAI視覺識別模塊:C++二維碼識別
基于LockAI視覺識別模塊:C++同時識別輪廓和色塊
開源項目 ! 利用邊緣計算打造便攜式視覺識別系統(tǒng)
適用于機器視覺應用的智能機器視覺控制平臺

ASR與傳統(tǒng)語音識別的區(qū)別
使用 TMP1826 嵌入式 EEPROM 替換用于模塊識別的外部存儲器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論