 OneFlow 將 Stable Diffusion的推理性能推向了一個全新的SOTA
OneFlow 將 Stable Diffusion的推理性能推向了一個全新的SOTA

OneFlow 將 Stable Diffusion 的推理性能推向了一個全新的 SOTA。
第一輛汽車誕生之初,時速只有 16 公里,甚至不如馬車跑得快,很長一段時間,汽車尷尬地像一種“很酷的玩具”。人工智能作圖的出現也是如此。
AI 作圖一開始的 “風格化” 本身就為 “玩” 而生,大家普遍興致勃勃地嘗試頭像生成、磨皮,但很快就失去興趣。直到擴散模型的降臨,才給 AI 作圖帶來質變,讓人們看到了 “AI 轉成生產力” 的曙光:畫家、設計師不用絞盡腦汁思考色彩、構圖,只要告訴 Diffusion 模型想要什么,就能言出法隨般地生成高質量圖片。
然而,與汽車一樣,如果擴散模型生成圖片時“馬力不足”,那就沒法擺脫玩具的標簽,成為人類手中真正的生產工具。
起初,AI 作圖需要幾天,再縮減到幾十分鐘,再到幾分鐘,出圖時間在不斷加速,問題是,究竟快到什么程度,才會在專業的美術從業者甚至普通大眾之間普及開來?
顯然,現在還無法給出具體答案。即便如此,可以確定的是 AI 作圖在技術和速度上的突破,很可能已經接近甚至超過閾值,因為這一次,OneFlow 帶來了字面意義上 “一秒出圖” 的 Stable Diffusion 模型。
OneFlow Stable Diffusion 使用地址:https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion
OneFlow 地址:https://github.com/Oneflow-Inc/oneflow/
比快更快,OneFlow 一馬當先
下面的圖表分別展示了在 A100 (PCIe 40GB / SXM 80GB)、RTX 2080 和 T4 不同類型的 GPU 硬件上,分別使用 PyTorch, TensorRT, AITemplate 和 OneFlow 四種深度學習框架或者編譯器,對 Stable Diffusion 進行推理時的性能表現。
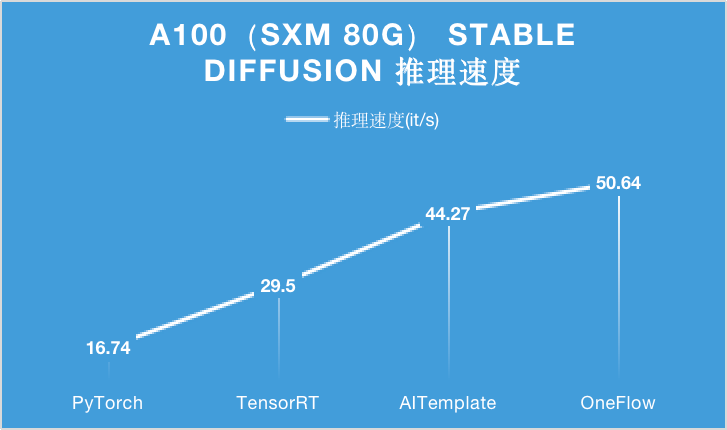
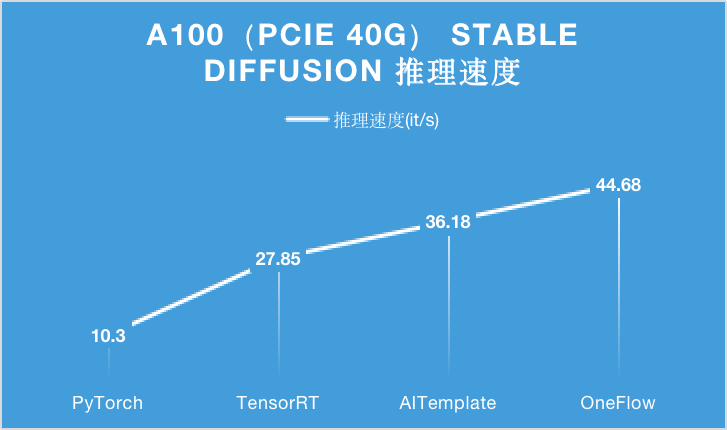
對于 A100 顯卡,無論是 PCIe 40GB 的配置還是 SXM 80GB 的配置,OneFlow 的性能可以在目前的最優性能之上繼續提升 15% 以上。
特別是在 SXM 80GB A100 上,OneFlow 首次讓 Stable Diffusion 的推理速度達到了 50it/s 以上,首次把生成一張圖片需要采樣 50 輪的時間降到 1 秒以內,是當之無愧的性能之王。
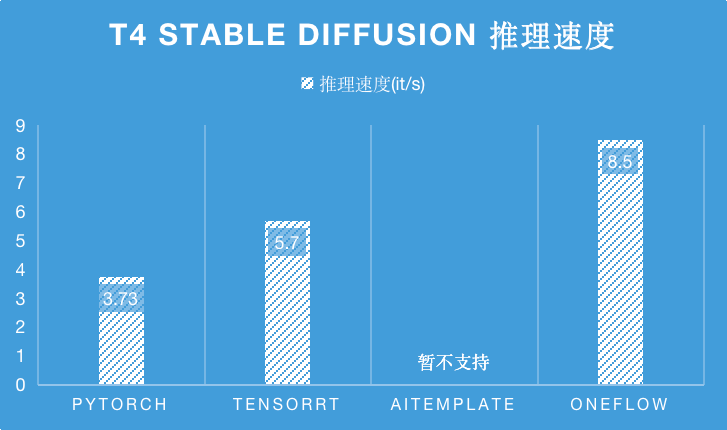
在 T4 推理卡上,由于 AITemplate 暫不支持 Stable Diffsuion,相比于目前 SOTA 性能的 TensorRT,OneFlow 的性能是它的 1.5 倍。
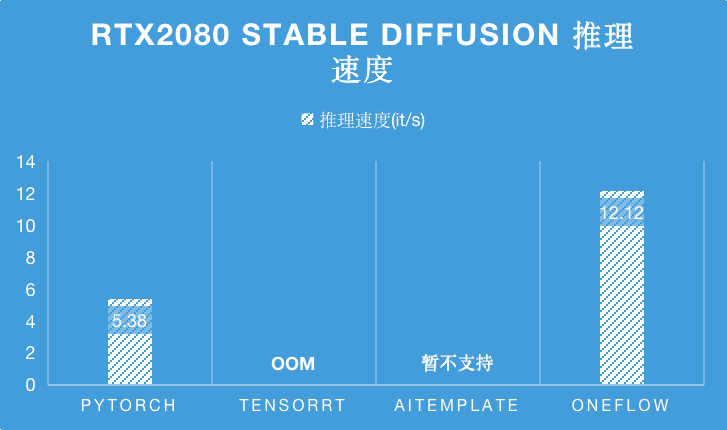
而在 RTX2080 上,TensorRT 在編譯 Stable Diffsuion 時會 OOM ,相比于目前 SOTA 性能的 PyTorch,OneFlow 的性能是它的 2.25 倍。
綜上,在各種硬件以及更多框架的對比中,OneFlow 都將 Stable Diffusion 的推理性能推向了一個全新的 SOTA。
生成圖片展示
利用 OneFlow 版的 Stable Diffusion,你可以把天馬行空的想法很快轉化成藝術圖片,譬如:
以假亂真的陽光、沙灘和椰樹:
倉鼠救火員、長兔耳朵的狗子:
在火星上吃火鍋:
未來異世界 AI:
集齊 OneFlow 七龍珠:
圖片均基于 OneFlow 版 Stable Diffusion 生成。如果你一時沒有好的 idea,可以在 lexica 上參考一下廣大網友的創意,不僅有生成圖片還提供了對應的描述文字。
無縫兼容 PyTorch 生態,實現一鍵模型遷移
想體驗 OneFlow Stable Diffusion?只需要修改三行代碼,你就可以將 HuggingFace 中的 PyTorch Stable Diffusion 模型改為 OneFlow 模型,分別是將 import torch 改為 import oneflow as torch 和將 StableDiffusionPipeline 改為 OneFlowStableDiffusionPipeline:
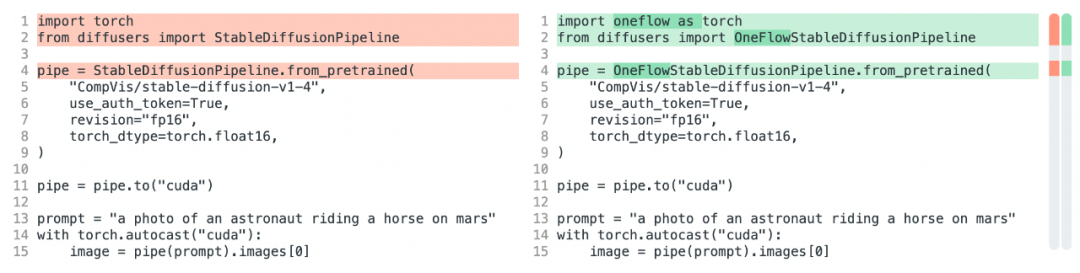
之所以能這么輕松遷移模型,是因為 OneFlow Stable Diffusion 有兩個出色的特性:
OneFlowStableDiffusionPipeline.from_pretrained 能夠直接使用 PyTorch 權重。
OneFlow 本身的 API 也是和 PyTorch 對齊的,因此 import oneflow as torch 之后,torch.autocast、torch.float16 等表達式完全不需要修改。
上述特性使得 OneFlow 兼容了 PyTorch 的生態,這不僅在 OneFlow 對 Stable Diffusion 的遷移中發揮了作用,也大大加速了 OneFlow 用戶遷移其它許多模型,比如在和 torchvision 對標的 flowvision 中,許多模型只需通過在 torchvision 模型文件中加入 import oneflow as torch 即可得到。
此外,OneFlow 還提供全局 “mock torch” 功能,在命令行運行 eval $(oneflow-mock-torch) 就可以讓接下來運行的所有 Python 腳本里的 import torch 都自動指向 oneflow。
使用 OneFlow 運行 Stable Diffusion
在 docker 中使用 OneFlow 運行 StableDiffusion 模型生成圖片:
docker run --rm -it --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ${HF_HOME}:${HF_HOME} -v ${PWD}:${PWD} -w ${PWD} -e HF_HOME=${HF_HOME} -e HUGGING_FACE_HUB_TOKEN=${HUGGING_FACE_HUB_TOKEN} oneflowinc/oneflow-sd:cu112 python3 /demos/oneflow-t2i.py # --prompt "a photo of an astronaut riding a horse on mars"
更詳盡的使用方法請參考:https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion
后續工作
后續 OneFlow 團隊將積極推動 OneFlow 的 diffusers(https://github.com/Oneflow-Inc/diffusers.git) 和 transformers(https://github.com/Oneflow-Inc/transformers.git) 的 fork 倉庫內容合并到 huggingface 上游的的對應倉庫。這也是 OneFlow 首次以 transformers/diffusers 的后端的形式開發模型,歡迎各位開發者朋友在 GitHub 上反饋意見。
值得一提的是,在優化和加速 Stable Diffusion 模型的過程中使用了 OneFlow 自研編譯器,不僅讓 PyTorch 前端搭建的 Stable Diffusion 在 NVIDIA GPU 上跑得更快,而且也可以讓這樣的模型在國產 AI 芯片和 GPU 上跑得更快,這些將在之后的文章中揭秘技術細節。
審核編輯 :李倩
-
AI
+關注
關注
88文章
35284瀏覽量
280608 -
人工智能
+關注
關注
1807文章
49052瀏覽量
250023 -
開源
+關注
關注
3文章
3711瀏覽量
43888
原文標題:1秒出圖,這個開源項目太牛了!
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
中軟國際智算中心成功完成華為EP方案驗證
如何在Ollama中使用OpenVINO后端
英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型

探討DeepSeek-R1滿血版的推理部署與優化策略

NVIDIA Jetson Orin Nano開發者套件的新功能

利用Arm Kleidi技術實現PyTorch優化

解鎖NVIDIA TensorRT-LLM的卓越性能

Arm KleidiAI助力提升PyTorch上LLM推理性能
Arm成功將Arm KleidiAI軟件庫集成到騰訊自研的Angel 機器學習框架
澎峰科技高性能大模型推理引擎PerfXLM解析

開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能






 工商網監
工商網監
評論