 CogBERT:腦認知指導的預訓練語言模型
CogBERT:腦認知指導的預訓練語言模型
介紹
本文研究了利用認知語言處理信號(如眼球追蹤或 EEG 數據)指導 BERT 等預訓練模型的問題。現有的方法通常利用認知數據對預訓練模型進行微調,忽略了文本和認知信號之間的語義差距。為了填補這一空白,我們提出了 CogBERT 這個框架,它可以從認知數據中誘導出細粒度的認知特征,并通過自適應調整不同 NLP 任務的認知特征的權重將認知特征納入 BERT。
實驗結果表明:1)認知指導下的預訓練模型在 10 個 NLP 任務上可以一致地比基線預訓練模型表現更好;2)不同的認知特征對不同的 NLP 任務有不同的貢獻。基于這一觀察,我們給出為什么認知數據對自然語言理解有幫助的一個細化解釋;3)預訓練模型的不同 transformer 層應該編碼不同的認知特征,詞匯級的認知特征在 transformer 層底部,語義級的認知特征在 transformer 層頂部;4)注意力可視化證明了 CogBERT 可以與人類的凝視模式保持一致,并提高其自然語言理解能力。

▲ 圖1. 人類眼球動作捕捉數據示意圖
背景與簡介
隨著預訓練模型的出現,當代人工智能模型在諸多任務上得到了超越人類的表現。隨著預訓練模型取得越來越好的結果,但是研究人員對于預訓練模型卻并沒有知道更多。
另一方面,從語言處理的角度來看,認知神經科學研究人類大腦中語言處理的生物和認知過程。研究人員專門設計了預訓練的模型來捕捉大腦如何表示語言的意義。之前的工作主要是通過明確微調預訓練的模型來預測語言誘導的大腦記錄,從而納入認知信號。 然而,前人基于認知的預訓練模型的工作,其思路無法對認知數據為何對 NLP 有幫助進行精細的分析和解釋。而這對于指導未來的認知啟發式 NLP 研究,即應該從認知數據中誘導出什么樣的認知特征,以及這些認知特征如何對 NLP 任務做出貢獻,具有重要意義,否則這只是相當于往預訓練模型加入更多的數據,而對認知數據如何幫助預訓練模型任然知之甚少。 例如,圖 1 顯示了以英語為母語的人的眼球追蹤數據,其中圖 1(a) 說明了人類正常閱讀時的關注次數。圖 2(b) 和 (c) 分別顯示了在 NLP 任務中的情感分類(SC)和命名實體識別(NER)的關注次數。我們可以看到,對于同一個句子,在不同的 NLP 任務下,人類的注意力是不同的。特別是,對于情感分類任務,人們更關注情感詞,如``terrible'和``chaos'。而對于 NER 任務,人們傾向于關注命名的實體詞,如``ISIS'和``Syria'。但是先前的研究不能通過簡單地在認知數據上微調預先訓練好的模型來給出這種細粒度的分析。 為了促進這一點,我們提出了 CogBERT,一個認知指導的預訓練模型。具體來說,我們專注于使用眼球追蹤數據的效果,該數據通過追蹤眼球運動和測量固定時間來提供母語者的凝視信息。我們沒有直接在認知數據上對 BERT 進行微調,而是首先根據認知理論提取心理語言學特征。
然后,我們在眼動數據中過濾掉統計學上不重要的特征(這意味著具有這些特征的單詞的人類注意力并不明顯高于/低于單詞的平均注意力)。隨后,我們通過在不同的 NLP 任務上進行微調,將這些經過認知驗證的特征納入 BERT。在微調過程中,我們將根據不同的 NLP 任務,為每一類特征學習不同的權重。
方法
本文的方法主要基于一個二階段的過程,其中一個階段被用來產生基于認知的特征模板,第二個階段在于將這些認知啟發的特征模板通過特殊設定的架構融入預訓練模型當中。3.1 方法心理語言學研究表明 [1],人類閱讀能力的獲得體現在兩個方面。底層線索 (ower strands) 和高層線索 (upper strands)。底層線索(包括語音學、形態學等)隨著閱讀者的重復和練習而變得準確和自動。同時,高層線索(包括語言結構、語義等)相互促進,并與底層線索交織在一起,形成一個熟練的讀者。即意味著,人類本質上的語言習得能力,其中一個重要的關鍵是對文本中的一系列特征進行越來越熟練的提取和識別。 這意味著,人類的眼球動作行為一定程度上可以被語言特征所反應,受以往工作的啟發,我們構建了一個初始的認知特征集,包括使用 spaCy 工具 [2] 從文本中提取的 46 個細粒度的認知特征,并將其分為下層特征(詞級)和上層特征(語義/語法級)。我們對這 46 種語言特征進行了廣泛的統計顯著性分析,找到了其中 14 個對于人類眼球動作有顯著影響的特征,并根據特征特點,將其分為了上層特征和下層特征,展示在下表 1 當中。
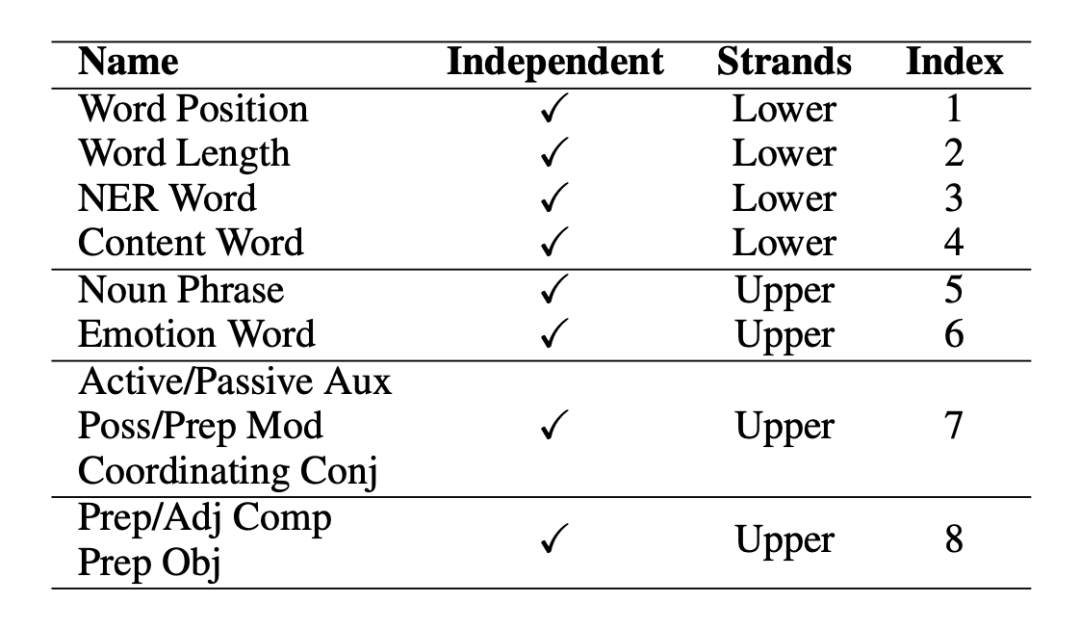
▲表1. 特征層級分類圖
3.2加權認知特征向量學習
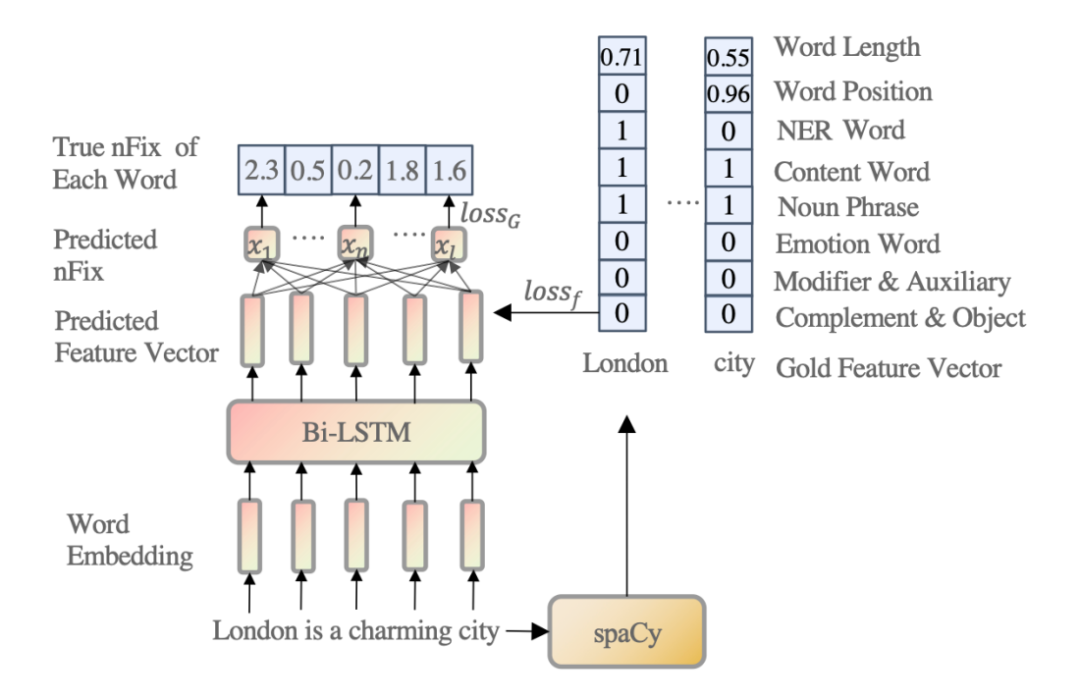
▲圖2. 加權認知特征向量學習模型
我們可以通過使用 spaCy 工具從文本中提取特征。然而,這些特征不應該被賦予相同或隨機的權重,因為它們對適應人類對句子的理解的貢獻是不同的。因此,如圖 2 所示,給定一個輸入句子,我們訓練一個四層的 Bi-LSTM [3],將每個單詞嵌入到一個加權的八維認知特征向量。根據前述的心里語言學理論,我們認為認知特征可以解釋人類眼動信息的分配。因此,我們使用眼球追蹤數據(Zuco 1.0、Zuco 2.0 和 Geco)[4,5,6] 的眼球動作信息中的關注次數 (nFix) 作為監督信號來訓練 Bi-LSTM 模型。
這部分的目的在實踐上實現前述所提到的理論,即人類的閱讀行為可以被特征解釋,同樣的,在模型層面上即意味著,模型要學會去利用語言特征的組合去逼近人類的閱讀行為。但是在本模型中,所需要的本不是最后對于眼球動作數據的逼近,而是需要其中通過眼球動作數據學來的特征向量。3.3 特征向量融入預訓練語言模型
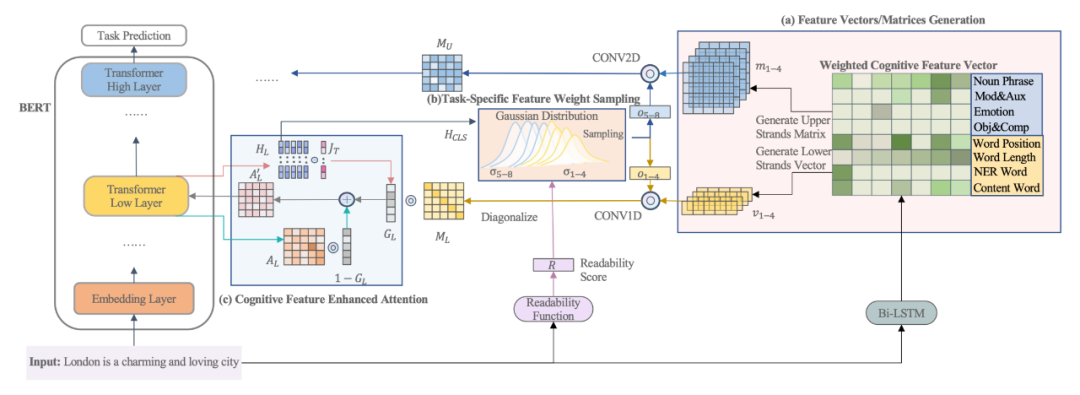
▲圖3. 特征向量融入預訓練語言模型
如圖 3(a) 所示,對于每個有單詞的輸入句子,我們可以從 Bi-LSTM 模型中獲得其對應的特征矩陣。對于每個底層特征(即詞長、詞位、NER 和內容詞),我們可以從 Bi-LSTM 模型中為其生成一個初始特征向量,隨后這些特征向量將會被對角化放在一個矩陣的對角線上。
對于每個上層特征(即 NP chunk、情感詞、Mod&Aux 和 Obj&Comp),我們可以從 Bi-LSTM 模型中分別為其生成一個初始的特征矩陣。如果相鄰的詞組成了一個上層特征,它在特征矩陣中的值是由 Bi-LSTM 模型得到的相鄰詞的平均特征得分,而其余數值都填為 0。同時對于每一個特征,會有一個經由高斯采樣出的權重每個特征進行放縮,用來提來該特征在該條數據或者任務當中的重要性。
經由上述過程生成的特征矩陣經過放縮后分別被卷積神經網絡進行處理用于提取特征形成基于特征的注意力矩陣,同時為了保留原始的模型注意力信息和特征的注意力矩陣,本文添加了一個門控向量,該向量會分別與模型原本的注意力矩陣和特征注意力矩陣進行相乘并求和,求得一個原注意力矩陣和當前注意力矩陣的線性加權。
同時可以注意到,本模型當中,底層特征將會融入在預訓練模型的底層,而高層特征則會融入在預訓練模型的高層。
實驗及分析4.1數據集
本文在多個數據集上進行了大量的實驗,實驗結果包括了 GLUE Benchmark [7], CoNLL2000 Chunking [8] 以及 Eye-tracking [9] 和模型本身的一些分析。
4.2基線方法
1. BERT 不進行遷移,直接在目標領域上進行預測。RoBERTa 微調源領域模型的全部參數進行領域適應;
2. fMRI-EEG-BERT 一種認知數據增強的預訓練語言模型,利用了核磁共振與腦電磁場數據;
3. Eye-tracking BERT 一種認知數據增強的預訓練語言模型,利用了眼球動作捕捉進行微調后再在下游任務上微調;
4. CogBERT (Random) 本論文所提出的模型,但是特征分數并未經由一階段進行生成,而是隨機生成的。
4.3 實驗結果與分析
如表 2 所示,本文所提出的模型能夠在所有任務上超越模型的原本基線,同時超越大多數的認知增強的預訓練語言模型,并能夠在大多數任務上達到或者超越經由語法增強的預訓練語言模型,體現了本文所提出模型的有效性。
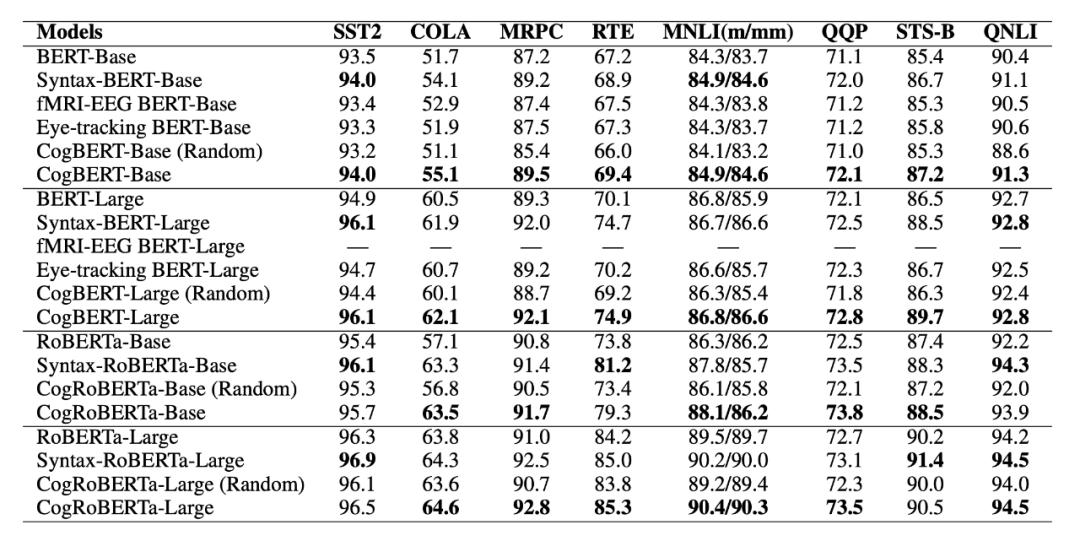
▲表2. GLUE Benchmark實驗結果
在 CoNLL 2000 Chunking 的數據集上,本文提出的模型可以超越 BERT 基線模型,同時本文提出的模型還可以超越先前專門用于序列標注而設計的模型。體現了認知增強的模型可以被用在廣泛的自然語言處理任務上。
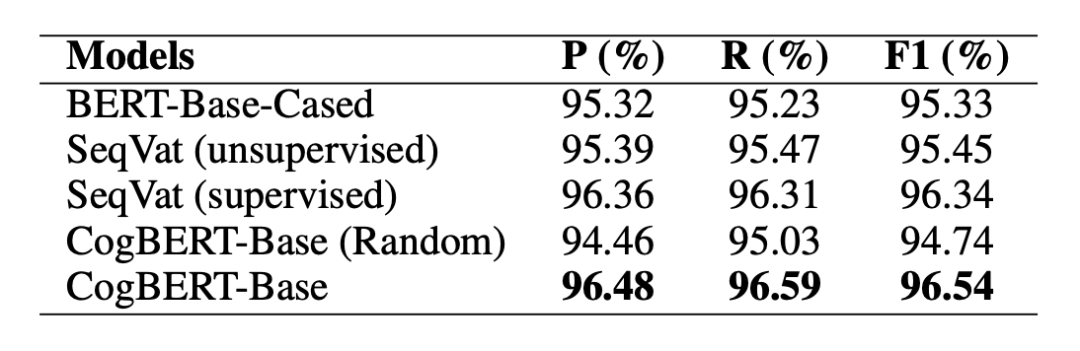
▲表3. CoNLL2000 Chunking實驗結果 同時,本文也在認知相關任務上進行了測試。在眼動數據預測的任務當中,本文所提出的模型可以在英語和荷蘭語的數據上超越相應的基線模型。同時由于本文模型是基于 BERT 單語言版本,實驗證明我們的模型也能夠超越 BERT 多語言版本,同時能夠超越 XLM-17 這一在 17 種語言上預訓練的模型,最終能以僅單語言的模型版本達到可比或者超越 XLM-100 這一在 100 種語言上預訓練的模型。證明了融入認知數據對于認知任務具有強力的增益。
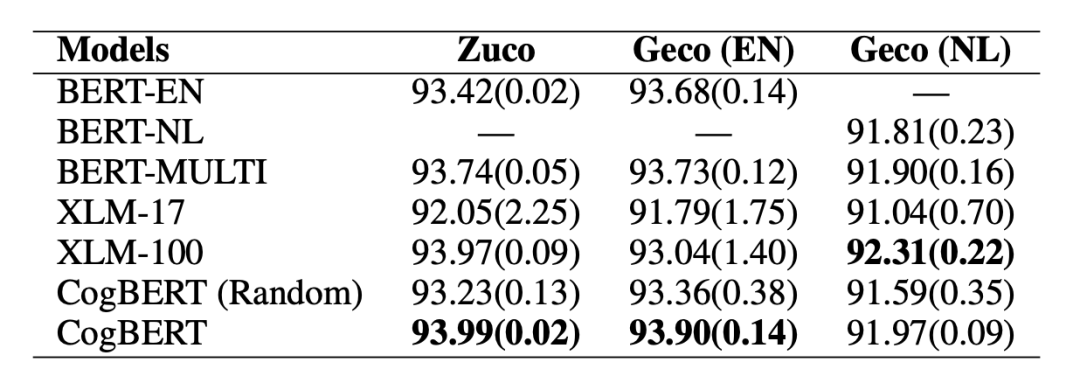
▲表4. Eye-tracking Prediction實驗結果
在對于模型本身的分析方面,首先展示在模型學習中不同任務里,不同特征所得到的權重。在 COLA(語法可接受性)上,本文的模型對語法相關特征給出了高權值。在 MRPC(轉述句識別)上,模型認為命名實體是最為重要的特征,即可能如果兩個句子并不在描述同一個實體,那么兩個句子大概率不是轉述句。在 RTE(文本蘊含)中,模型認為名詞短語是最為重要的特征,這可能意味著如果兩個句子具有類似的名詞短語結構,那么兩個句子具有較大的概率是蘊含關系。在 CoNLL 2000 Chunking 和 CoNLL 2003 NER 任務當中,模型可以很直觀的給出名詞短語和實體詞為最重要特征,符合了任務的設計。

▲表5. 特征權重分析實驗結果
我們觀察到,替換下層或上層的認知特征會降低模型的性能,而去除所有層的認知特征會進一步影響模型的性能。我們還注意到,盡管可讀性對于我們的模型來說沒有認知特征那么重要,但去除它也會損害模型的性能。不分層的融入特征意味著我們將所有的特征整合到 BERT 的每一層,不分層的糟糕表現表明,以分層的方式整合特征是認知引導的 NLP 的一個有效方法。
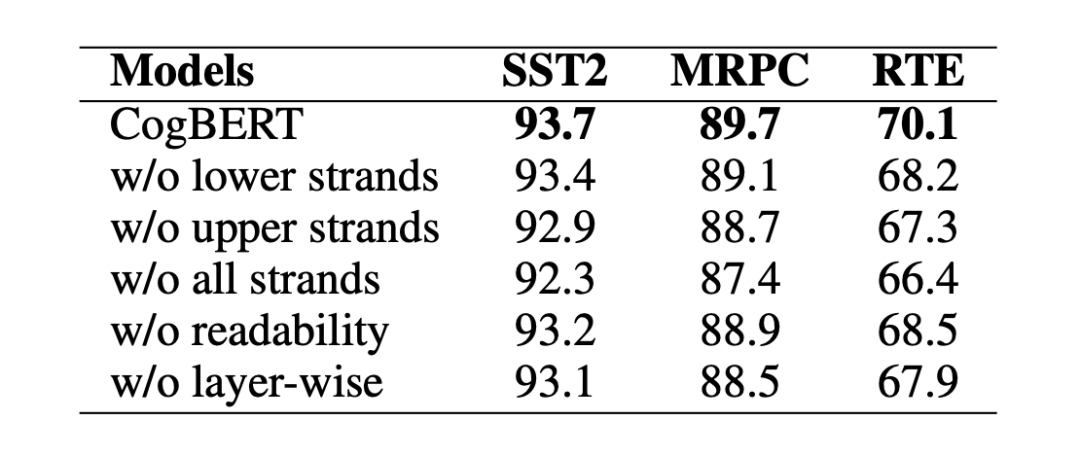
▲表6. 消融實驗結果
在本文中,由于下層特征融入到預訓練模型的底層,而上層特征融入到高層當中,因此有必要去尋找合適的分層邊界。本文量化地討論了 BERT 的哪一層應該是下層和上層認知特征的邊界,并對 SST2、MRPC、QNLI 和 STS-B 任務的開發集進行了比較實驗,并在圖中說明了結果。Y 軸是不同 NLP 任務的性能。X 軸是層數。例如,如果層數為 6,我們將下層的認知特征納入 BERT 的 1-6 層,將上層的認知特征納入其余層。
研究發現,當層數邊界在 4 左右時,所有任務都達到了最佳性能,這意味著 BERT 的低層更適合納入下層認知特征,而當我們將上層認知特征納入更高的層數時,它們更有用。這些結果可以有效地指導未來認知強化預訓練模型的研究,同時也進一步驗證了前人關于預訓練模型的相關研究 [10]。
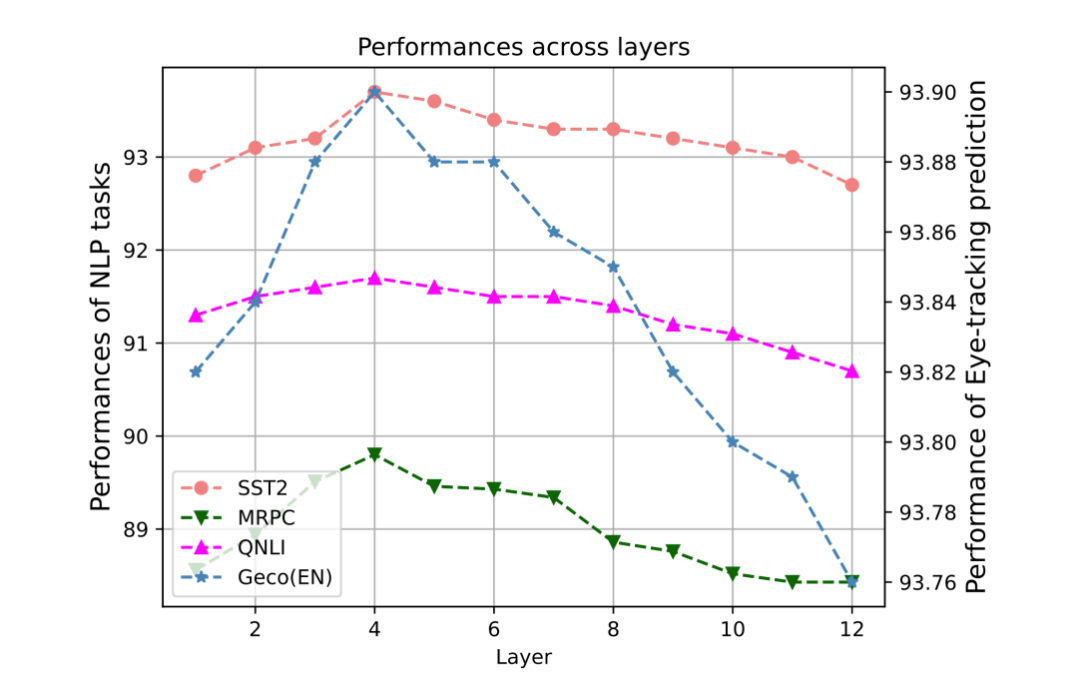
▲圖4. 任務表現與特征層數分析圖
為了定性地分析我們方法的有效性,我們將 CogBERT 的注意力可視化,并與 BERT 和人類進行比較。我們從 SST2、NER 和 MRPC 任務中選擇案例。為了與人類的認知進行比較,給定一個特定的 NLP 任務,我們要求四個注釋者在閱讀句子時突出他們的注意詞。對于 BERT 和 CogBERT,我們從預訓練模型的較高層次中選擇注意力得分,這可以捕捉到任務的特定特征。SST2 和 NER 的注意力可視化圖。
圖 (a) 展示了 CoNLL-2003 NER 任務的注意力可視化,說明 CogBERT 像人類一樣對 NER 詞 "Asian Cup"、"Japan"和 "Syria"給予了更多的關注,而 BERT 對這些詞的關注很少。圖 (b) 說明了 SST2 任務的注意力可視化,顯示 CogBERT 捕獲了關鍵的情感詞`fun'和`okay',而這兩個詞從人類的判別行為來說對人類的判斷也很重要。
相比之下,BERT 未能關注這些詞。這些實驗結果表明,盡管預訓練模型在眾多 NLP 任務中取得了可喜的改進,但它們離人類智能的水平還很遠。通過學習人類閱讀中的注意力機制,認知引導的預訓練模型可以提供一種接近人類認知的有效方法。
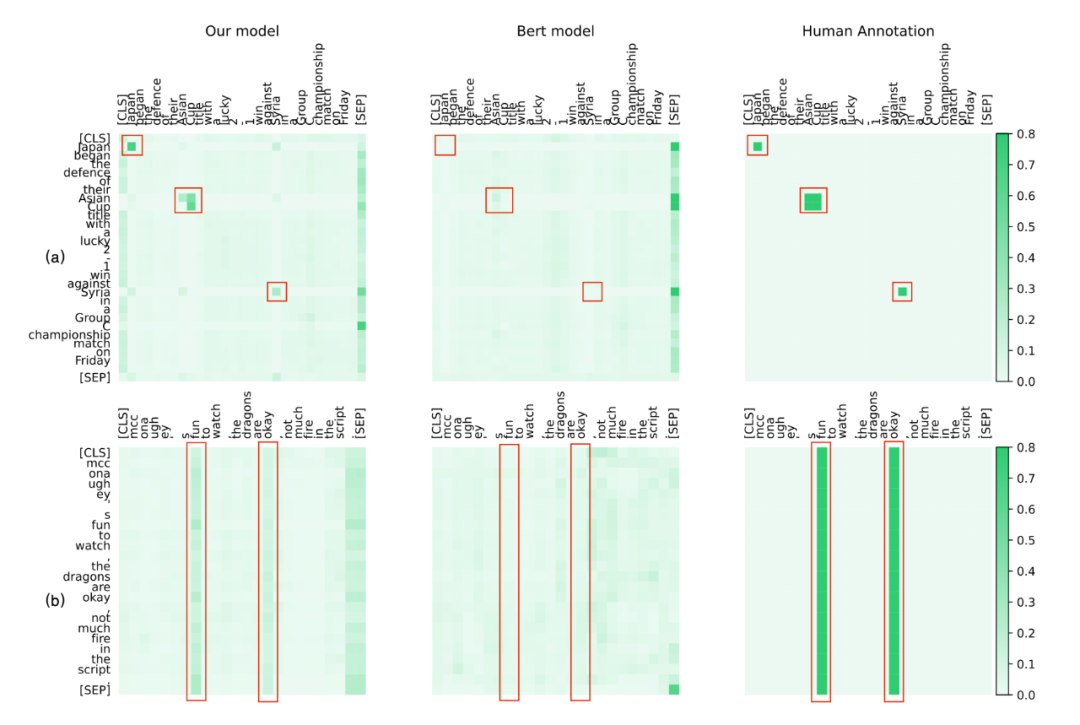
▲圖5. 注意力可視化
結論
我們提出了 CogBERT,一個能夠有效地將認知信號納入預訓練模型的框架。實驗結果表明,CogBERT 在多個 NLP 基準數據集上取得了超越基線的結果,同時模型表明證明對認知任務同樣有用。分析表明,CogBERT 可以自適應地學習特定任務的認知特征權重,從而對認知數據在 NLP 任務中的工作方式做出精細的解釋。這項工作為學習認知增強的預訓練模型提供了一個新的方法,廣泛闡述的實驗可以指導未來的研究。
審核編輯 :李倩 ·
-
語言模型
+關注
關注
0文章
558瀏覽量
10655 -
數據集
+關注
關注
4文章
1222瀏覽量
25267
原文標題:COLING'22 | CogBERT:腦認知指導的預訓練語言模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

從Open Model Zoo下載的FastSeg大型公共預訓練模型,無法導入名稱是怎么回事?
小白學大模型:訓練大語言模型的深度指南

用PaddleNLP在4060單卡上實踐大模型預訓練技術

騰訊公布大語言模型訓練新專利
KerasHub統一、全面的預訓練模型庫

從零開始訓練一個大語言模型需要投資多少錢?

直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論