 TOIST借助COCO掩碼將問題擴展到實例分割問題實現更精細的定位
TOIST借助COCO掩碼將問題擴展到實例分割問題實現更精細的定位
0. 引言
歸功于大規模視覺語言模型,名詞指代表達理解模型已經取得了巨大的進展。然而,在像智能服務機器人這樣的現實交互中,系統輸入通常較為隱晦(比如舒服得坐下這樣的動作),現代視覺語言模型設計是否能有效地理解動詞所指仍然有待探索。
1. 論文信息
2. 摘要
目前的指代表達理解算法可以有效地檢測或分割名詞所指的對象,但如何理解動詞指代仍然是一個有待探索的問題。因此,我們研究了具有挑戰性的面向任務的檢測問題,該問題旨在找到最好地由動詞所指示動作的對象,如舒適地坐在上面。為了更好地為機器人交互等下游應用服務,我們將問題擴展到面向任務的實例分割。這項任務的一個獨特要求是在可能的備選方案中選擇首選候選方案。因此,我們求助于transformer體系結構,它自然地對成對查詢關系進行建模,這構建了TOIST方法。為了利用預先訓練的名詞指代表達理解模型,以及我們可以在訓練期間訪問特權名詞基礎事實的事實,提出了一種新的名詞-代詞提取框架。名詞原型以無監督的方式生成,并且上下文代詞特征被訓練來選擇原型。因此,網絡在推理過程中保持名詞不可知。我們在面向任務的大規模數據集COCO-Tasks上進行測試并實現比最佳報告結果高出10.9%。提出的名詞代詞提取可以將mAPbox和mAPmask分別提高2.8%和3.8%。
3. 算法分析
3.1 任務描述
TOIST這篇文章目的是解決面向任務的檢測問題,那么什么是面向任務呢?如圖1右上角所示,當輸入為“涂抹黃油”時,系統會輸出叉子的檢測框,因為叉子可用于涂抹黃油。當然這只是COCO-Tasks提出的目標檢測問題,TOIST還借助現有的COCO掩碼將問題擴展到實例分割問題,以此來實現更精細的定位。例如當輸入為“舒服得坐著”時,系統會分割出沙發。因此,TOIST提出的面向任務的實例分割方案(圖1底部)可以很好得在點云分割和三維重建等領域發揮作用,對于下游機器人的交互應用具有重要意義。 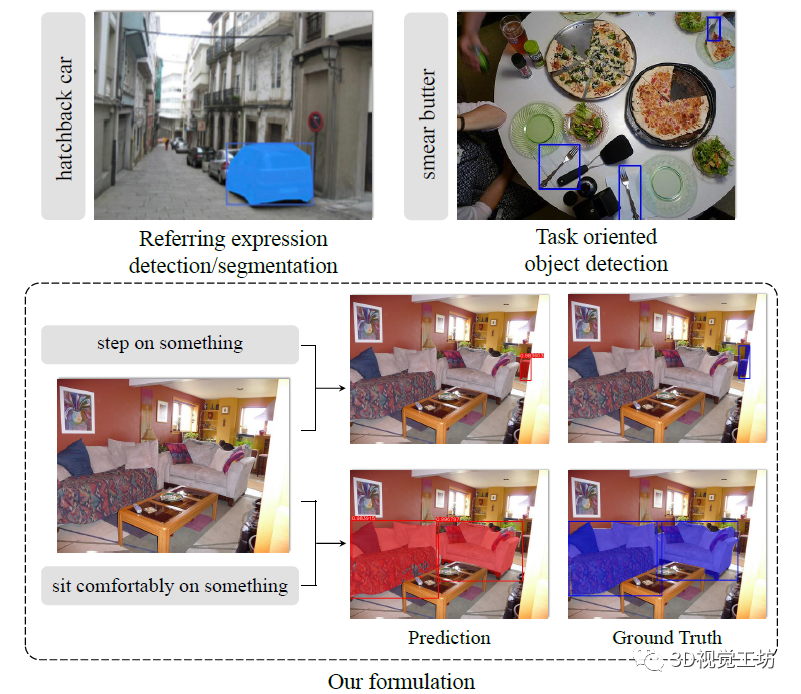 圖1 左上:名詞指代表達理解,右上:面向任務的檢測,下部:面向任務的實例分割。 當然了,面向任務的檢測/分割方法的一個有趣且具有挑戰性的特征是內在歧義。例如,在圖1的右上圖中,比薩餅皮也可以用來涂抹黃油。如果我們手邊既沒有叉子也沒有比薩餅皮,仍然可以用盤子涂抹黃油。以及如圖1底部所示。當我們考慮要踩的物體時,椅子是更好的選擇,因為沙發很軟,桌子移動起來很重。當需要舒適地坐著時,沙發顯然是最好的選擇。換句話說,提供動詞的對象是不明確的,算法需要對偏好進行建模。
圖1 左上:名詞指代表達理解,右上:面向任務的檢測,下部:面向任務的實例分割。 當然了,面向任務的檢測/分割方法的一個有趣且具有挑戰性的特征是內在歧義。例如,在圖1的右上圖中,比薩餅皮也可以用來涂抹黃油。如果我們手邊既沒有叉子也沒有比薩餅皮,仍然可以用盤子涂抹黃油。以及如圖1底部所示。當我們考慮要踩的物體時,椅子是更好的選擇,因為沙發很軟,桌子移動起來很重。當需要舒適地坐著時,沙發顯然是最好的選擇。換句話說,提供動詞的對象是不明確的,算法需要對偏好進行建模。
3.2 算法原理
近年來Transformer大火,TOIST的作者認為注意力機制可以很好得對候選對象之間的相對偏好進行建模,因此設計了一種面向任務的實例分割Transformer。 眾所周知,訓練Transformer需要大量數據,而大規模的具有相對偏好的動詞參考數據非常少見。因此作者從另一個角度出發,探索了在名詞指代表達理解模型中重用知識的可能性,即使用代詞如某物作為代理,并從聚類生成的名詞嵌入原型中提取知識。 具體來說,TOIST首先使用特權名詞訓練具有動詞-名詞輸入的TOIST模型(例如,踩在圖1底部的底部面板的椅子上)。但是在推理過程中,不能訪問名詞椅子,因此用動詞代詞輸入(例如,踩在某物上)訓練第二個TOIST模型,并從第一個TOIST模型中提取知識。因此,第二TOIST模型在推理期間保持名詞不可知,并且比直接用動詞-代詞輸入訓練模型獲得更好的性能。這個框架被稱為名詞-代詞提煉。總體來說,將特權名詞信息提取為代詞特征的想法非常新穎! 如圖2所示為TOIST網絡的具體架構,TOIST包含三個主要組成部分:多模態編碼器(棕色)用于提取標記化特征,Transformer編碼器(綠色)用于聚合兩個模態的特征,Transformer解碼器(藍色)用于預測具有注意力的最合適對象,其中cluster loss和soft binary target loss分別用于提取特權名詞知識和偏好知識。 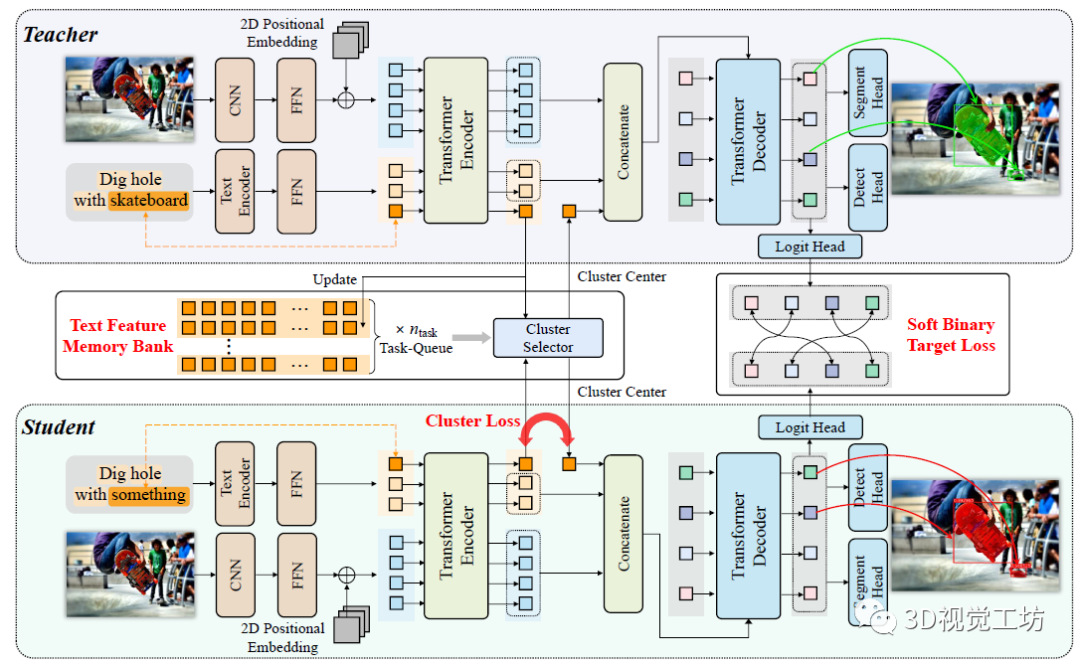 圖2 TOIST網絡架構和名詞-代詞提煉框架 概括起來,TOIST這篇文章有以下四個方面的貢獻: (1) 第一次將面向任務的檢測任務升級為面向任務的實例分割,這個新的解決方法對機器人交互應用有實用價值。 (2) 不同于現有的兩階段模型(先檢測對象然后排序),TOIST提出了第一個基于Transformer的方法來進行面向任務的檢測/分割。它只有一個階段,并且自然地在對象查詢上用自注意力來模擬相對偏好。 (3) 為了利用名詞指代表達理解模型中的特權信息,TOIST提出了一個新的名詞-代詞提取框架。它在mAP box和mAP mask分別提升了+2.8%和+3.8%。 (4) 在COCO-Tasks數據集上取得了SOTA結果,比mAP box的最佳結果高出10.9%。
圖2 TOIST網絡架構和名詞-代詞提煉框架 概括起來,TOIST這篇文章有以下四個方面的貢獻: (1) 第一次將面向任務的檢測任務升級為面向任務的實例分割,這個新的解決方法對機器人交互應用有實用價值。 (2) 不同于現有的兩階段模型(先檢測對象然后排序),TOIST提出了第一個基于Transformer的方法來進行面向任務的檢測/分割。它只有一個階段,并且自然地在對象查詢上用自注意力來模擬相對偏好。 (3) 為了利用名詞指代表達理解模型中的特權信息,TOIST提出了一個新的名詞-代詞提取框架。它在mAP box和mAP mask分別提升了+2.8%和+3.8%。 (4) 在COCO-Tasks數據集上取得了SOTA結果,比mAP box的最佳結果高出10.9%。
3.3 名詞代詞提煉
TOIST有兩種輸入形式,作者發現由于目標名稱(名詞)的特權信息,使用動名詞輸入的TOIST在mAP box和mAP mask上的表現提升了11.8 %和12.0 %,結果如表1所示。作者還進行了另外兩個預實驗:將動詞-名詞模型中的代詞特征lpron或ltr直接替換為動詞-名詞模型中對應的名詞特征lnoun或ltr,這種替換直接提高了性能。但是在推理過程中,基本真值對象的名詞是不可用的,作者認為一個合理的名詞-名詞蒸餾框架可以在不違反名詞不可知性約束的前提下利用動詞-名詞模型的豐富知識。 表1 與文本相關的幾種不同設置下的定量結果 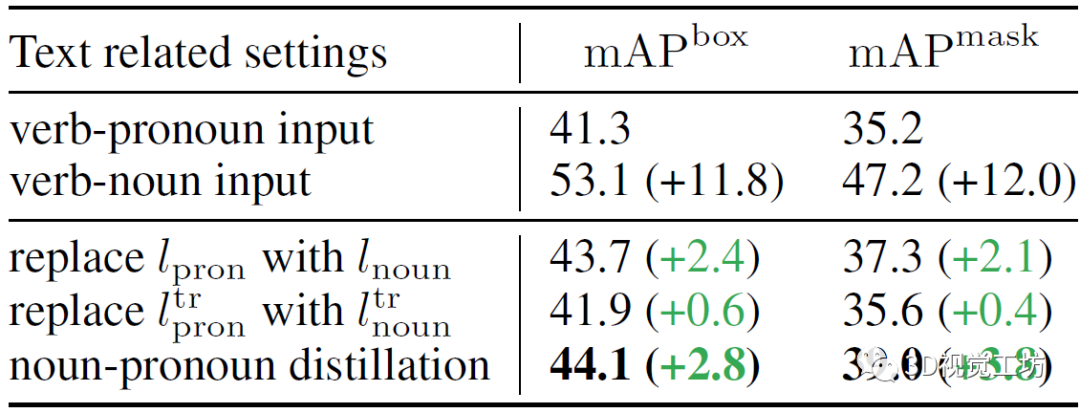 在圖2所示的網絡框架中,兩個TOIST模型被同時訓練。教師(圖2頂部)和學生(圖2底部)分別將動詞-名詞和動詞-代詞描述作為輸入,并使用具有記憶庫和聚類提取方法來提取從名詞到代詞的優先的以對象為中心的知識(圖2左中)。作者還使用一個軟二進制目標損失來提取偏好知識(圖2中右),其中Gpred是用于計算偏好得分Spred的對數。此外,由于一個任務可以由許多不同類別的對象承擔,因此作者建立了一個文本特征記憶庫來存儲名詞特征,通過它可以選擇一個原型來代替代詞特征和提取知識,作者稱這個過程為聚類蒸餾。
在圖2所示的網絡框架中,兩個TOIST模型被同時訓練。教師(圖2頂部)和學生(圖2底部)分別將動詞-名詞和動詞-代詞描述作為輸入,并使用具有記憶庫和聚類提取方法來提取從名詞到代詞的優先的以對象為中心的知識(圖2左中)。作者還使用一個軟二進制目標損失來提取偏好知識(圖2中右),其中Gpred是用于計算偏好得分Spred的對數。此外,由于一個任務可以由許多不同類別的對象承擔,因此作者建立了一個文本特征記憶庫來存儲名詞特征,通過它可以選擇一個原型來代替代詞特征和提取知識,作者稱這個過程為聚類蒸餾。
4. 實驗
TOIST模型在COCO-Tasks數據集上進行實驗,這應該是唯一涉及實例級偏好的數據集。COCO-Tasks數據集包含14個任務。對于每個任務,有3600個訓練圖像和900個測試圖像。在每個圖像中,首選對象(一個或多個)的框被用作檢測的基礎事實標簽。基于現有的COCO掩碼,作者將數據集擴展到實例分割版本。
4.1 與SOTA方法的比較
表2顯示,在COCO-Tasks上,帶有名詞-代詞蒸餾的TOIST取得了最好結果。TOIST提出的一階段方法達到了41.3%的mAP box和35.2% mAP mask,比之前最好的結果(Yolo+GGNN和Mask-RCNN+GGNN)分別提高了8.1%和2.8%。名詞-代詞蒸餾將TOIST的性能進一步提升至44.1% (+10.9%)的mAP box和39.0% (+6.6%)的mAP mask。 表2 在擴展的COCO-Tasks數據集上,TOIST與SOTA基線的比較。 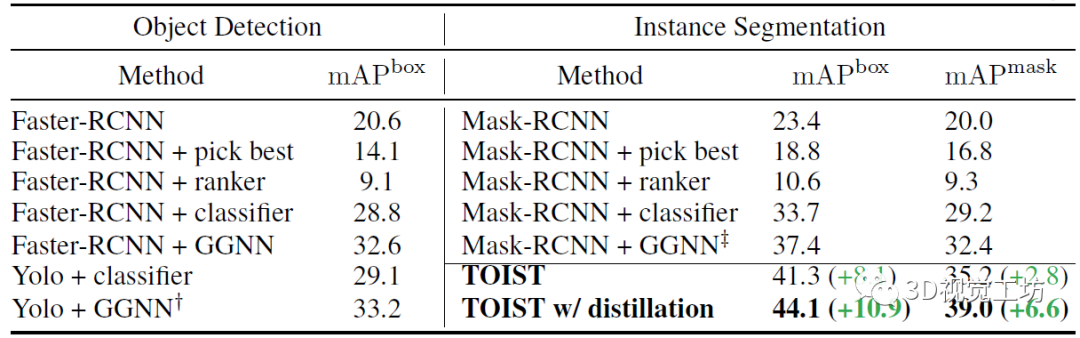
4.2 影響因素
圖3(a)驗證了自注意力機制能夠自然地建模偏好的能力,其中兩個普通的TOIST模型分別訓練,其中一個不包含自注意力。需要注意的是,移除自注意力不會影響參數的數量。作者認為,對于具有自注意力的TOIST,隨著偏好分數的來源變得更加深入,性能逐漸提升:從29.6% mAP box和25.0% mAP mask提升到41.3%和35.2%。TOIST解碼器中的自注意力建模了對象候選之間的成對相對偏好。隨著解碼器的深入,對象候選之間的偏好關系逐漸被自注意力提取出來。在表3 (b)中,與基線相比,帶有軟二元目標損失的偏好蒸餾獲得了2.1% mAP box和2.8% mAP mask的提升。 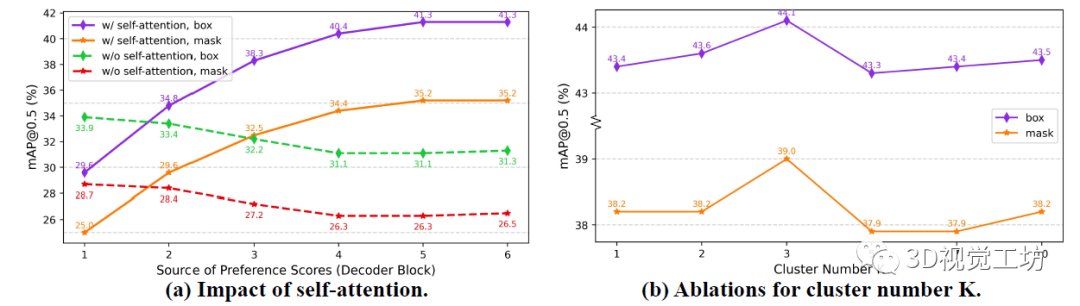 圖3 (a)自注意力和(b)集群數量影響的實驗 表3展示了使用聚類損失和用聚類中心(名詞原型)替換代詞特征的效果。在(c)和(e)中,單獨使用兩個成分比基準(a)分別增加了0.7% mAP box、1.9% mAP mask和0.7% mAP box、1.8% mAP mask。在(g)中性能提升1.0% mAP box和2.3% mAP mask。這些結果表明,聚類蒸餾方法可以提高學生的TOIST和增強動詞指稱表達式的理解。 表3 針對聚類的消融實驗
圖3 (a)自注意力和(b)集群數量影響的實驗 表3展示了使用聚類損失和用聚類中心(名詞原型)替換代詞特征的效果。在(c)和(e)中,單獨使用兩個成分比基準(a)分別增加了0.7% mAP box、1.9% mAP mask和0.7% mAP box、1.8% mAP mask。在(g)中性能提升1.0% mAP box和2.3% mAP mask。這些結果表明,聚類蒸餾方法可以提高學生的TOIST和增強動詞指稱表達式的理解。 表3 針對聚類的消融實驗 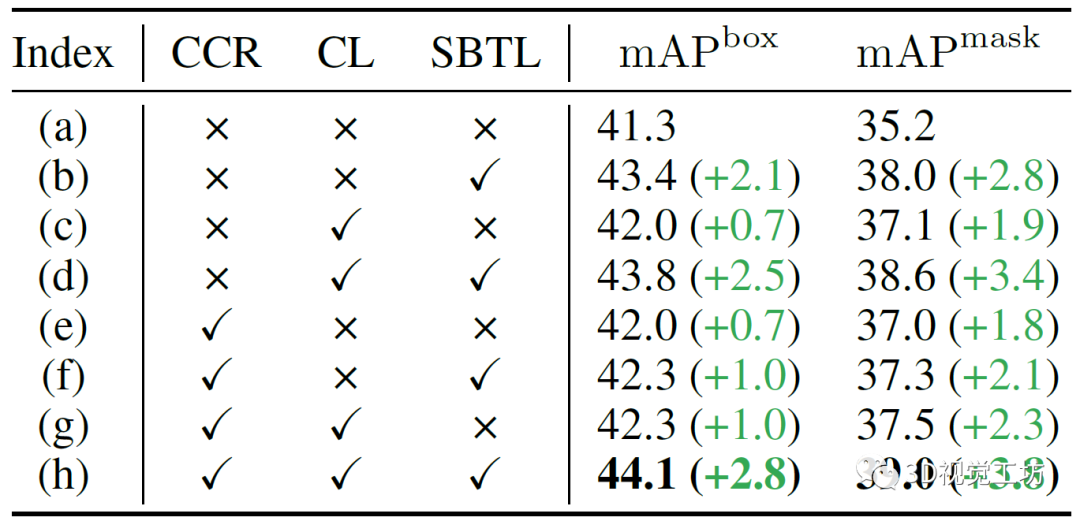 在圖4中,作者可視化了預測結果(通過0.9的偏好閾值過濾)和代詞標記的注意力圖。在第一行中,當沒有聚類蒸餾時,TOIST錯誤地偏好花朵而不是杯子,注意圖也證實了這一點。但是聚類蒸餾的TOIST正確地選擇了杯子,而對花的注意力被削弱了。這表明聚類蒸餾使學生TOIST能夠減少動詞-代詞指稱表達式的歧義。在第二行中,刀的邊界框由兩個模型正確檢測。然而,在沒有蒸餾的情況下,在盒子內的勺子和叉子上預測額外的實例面具。相反,隨著蒸餾,TOIST預測的面具集中在刀上,注意力更集中在它上面。這表明,在集群蒸餾的情況下,TOIST可以更好地將任務研磨到對象框內的像素。同時,即使盒子是正確的,預測的掩模也可能是不準確的,這一事實使得機器人在執行特定任務時準確地抓住優選的物體具有挑戰性。這證明了將面向任務的對象檢測擴展到實例分割的重要性。
在圖4中,作者可視化了預測結果(通過0.9的偏好閾值過濾)和代詞標記的注意力圖。在第一行中,當沒有聚類蒸餾時,TOIST錯誤地偏好花朵而不是杯子,注意圖也證實了這一點。但是聚類蒸餾的TOIST正確地選擇了杯子,而對花的注意力被削弱了。這表明聚類蒸餾使學生TOIST能夠減少動詞-代詞指稱表達式的歧義。在第二行中,刀的邊界框由兩個模型正確檢測。然而,在沒有蒸餾的情況下,在盒子內的勺子和叉子上預測額外的實例面具。相反,隨著蒸餾,TOIST預測的面具集中在刀上,注意力更集中在它上面。這表明,在集群蒸餾的情況下,TOIST可以更好地將任務研磨到對象框內的像素。同時,即使盒子是正確的,預測的掩模也可能是不準確的,這一事實使得機器人在執行特定任務時準確地抓住優選的物體具有挑戰性。這證明了將面向任務的對象檢測擴展到實例分割的重要性。 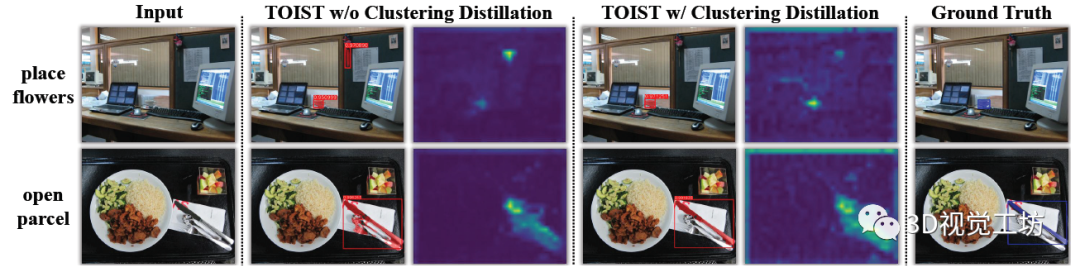 圖4 代詞標記的預測結果和注意力圖的可視化
圖4 代詞標記的預測結果和注意力圖的可視化
4.3 消融研究和定性結果
表4顯示了不同代詞輸入下的TOIST結果。在普通TOIST和帶有蒸餾的TOIST中,使用某物、它或它們會導致類似的結果。而一個毫無意義的字符串abcd產生較少的改進,證明了魯棒性。 表4 針對代詞輸入的消融實驗 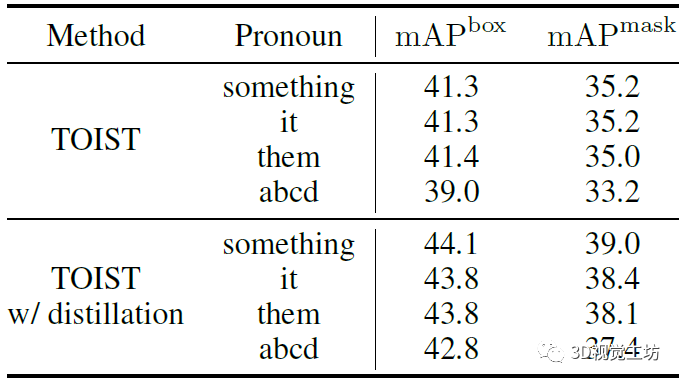 表5顯示了不同任務數的消融研究,其中第一行對應于沒有蒸餾的純TOIST,其他行顯示了不同數目下蒸餾的結果。總體而言,較小的n會帶來更好的性能,這是因為不同任務之間的交互更少而降低了問題的復雜性,這使得通過名詞-代詞蒸餾更容易提高模型理解動詞的能力。 表5 面向任務的目標檢測任務數消融實驗
表5顯示了不同任務數的消融研究,其中第一行對應于沒有蒸餾的純TOIST,其他行顯示了不同數目下蒸餾的結果。總體而言,較小的n會帶來更好的性能,這是因為不同任務之間的交互更少而降低了問題的復雜性,這使得通過名詞-代詞蒸餾更容易提高模型理解動詞的能力。 表5 面向任務的目標檢測任務數消融實驗 
5. 結論
在2022 NeurIPS論文“Centroid Distance Keypoint Detector for Colored Point Clouds”中,作者基于Transformer研究了面向任務的實例分割問題。TOIST在COCO-Tasks數據集上取得了SOTA結果,雖然沒有更大數據集上的評估,但這對于許多機器人交互應用來說已經足夠。
-
機器人
+關注
關注
213文章
29508瀏覽量
211633 -
模型
+關注
關注
1文章
3488瀏覽量
50021 -
數據集
+關注
關注
4文章
1223瀏覽量
25283
原文標題:NIPS2022開源!TOIST:通過蒸餾實現面向任務的實例分割Transformer
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何將范圍從萬到FFFF擴展到FRQQUPWM=44100
如何利用BTA06-600C將BT131的負載能力120W擴展到200W以上?
可以將ESP Basic擴展到ESP32嗎?

AMD稱其融聚渠道計劃將擴展到行業與OEM渠道
蘋果將iPhone 的保修范圍擴展到全球
三星借助MicroLED技術可擴展到292英寸,顯示屏與周圍環境無縫融合!
蘋果可能正在尋求將蘋果地圖的范圍擴展到其iDevices之外
AN-1529:使用AD9215高頻VGA將10位65 MSPS ADC的動態范圍擴展到100 dB以上

用于實例分割的Mask R-CNN框架
將5G安全地擴展到戰場空間
基于通用的模型PADing解決三大分割任務

基于SAM設計的自動化遙感圖像實例分割方法

通過應用頻率將TPS92210的調光范圍擴展到通用AC范圍





 工商網監
工商網監
評論