 如何以模型和場景為中心的方式控制數據生成
如何以模型和場景為中心的方式控制數據生成
訓練計算機視覺模型通常需要在各種場景配置和屬性下收集和標注大量圖像。這個過程非常耗時,確保捕獲的數據分布很好地映射到應用程序場景的目標域也是一個挑戰。
最近,合成數據已成為解決這兩個問題的一種方法。然而,現有的方法要么需要人類專家手動調整每個場景屬性,要么用幾乎沒有控制的自動方法;這需要渲染大量隨機的數據變異,其過程很慢,并且對于目標域來說通常是次優的。
作者提出了第一個完全可微分的合成數據流水線,在閉環中用神經輻射場(NERF),其具備目標應用的損失函數。這個方法按需生成數據,無需人力,最大限度地提高目標任務的準確性。
該方法在合成和真實目標檢測任務中具備有效性。一個新的“YCB-in-the-Wild”數據集和基準,為現實環境中具有不同姿態的目標檢測提供了測試場景。
最近,圖像生成技術神經輻射場(NeRF),作為用基于神經網絡的渲染器,替代傳統光柵化和光線跟蹤圖形學流水線的方法。這種方法可以生成高質量的場景新視圖,無需進行明確的3D理解。NeRF的最新進展允許控制其他渲染參數,如照明、材質、反照率、外觀等。因此,被廣泛應用于各種圖形和視覺任務。
NeRF及其變型具有一些誘人的特性:(i)可差分渲染,(ii)與GANs和VAEs不同的對場景屬性的控制,以及(iii)與傳統渲染器相比,數據驅動的模式,而傳統渲染器需要精心制作3D模型和場景。這些屬性適合于為給定目標任務按需生成最佳數據。
NeRF更適合學習生成合成數據集的優勢在于兩個方面。 首先,NeRF學習僅基于圖像數據和攝像頭姿態信息從新視圖生成數據。
相反,傳統的圖形學流水線需要目標的3D模型作為輸入。獲得具有正確幾何、材質和紋理屬性的精確3D模型通常需要人類專家(即藝術家或建模師)。這反過來限制了傳統圖形學流水線在許多新目標或場景的大規模渲染中的可擴展性。
其次,NeRF是一種可微分的渲染器,因此允許通過渲染流水線進行反向傳播,學習如何以模型和場景為中心的方式控制數據生成。 工作目標是自動合成最佳訓練數據,最大限度地提高目標任務的準確性,取名為Neural-Sim。
在這項工作中,將目標檢測作為目標任務。此外,最近,NeRF及其變型(NeRFs)已用于合成復雜場景的高分辨率真實感圖像。這里提出了一種優化NERF渲染參數的技術,生成用于訓練目標檢測模型的最佳圖像集。
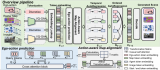
如圖所示:(a) 按需合成數據生成:給定目標任務和測試數據集,Neural- Sim使用完全可微分的合成數據生成流水線按需生成數據,最大限度地提高目標任務的精度。(b) 訓練/測試域間隙導致檢測精度顯著下降(黃色條至灰色條)。動態優化渲染參數(姿勢/縮放/照明),生成填充該間隙的最佳數據(藍色條)。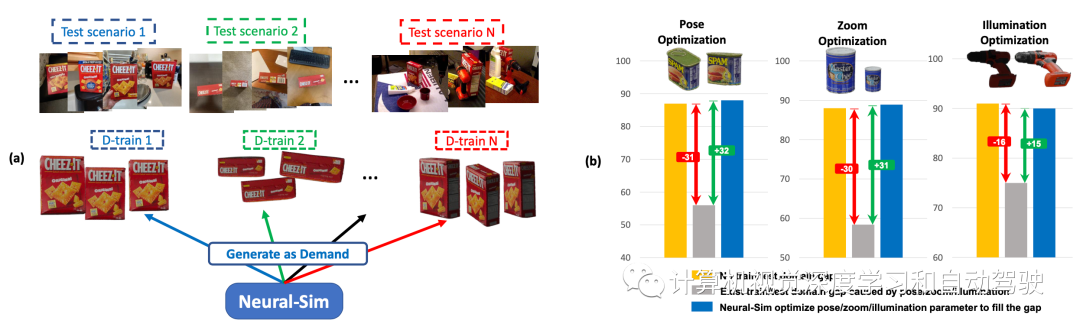
NeRF模型
NeRF表示為V =(φ,ρ),把觀察方向(或攝像頭姿態)作為輸入,并渲染沿V觀看的場景圖像x=NeRF(V)。注意,這里技術通常廣泛適用于不同的渲染器。這項工作中還優化了NeRF-in-the-wild(NeRF-w),允許外觀和照明變化以及姿勢變化。
合成訓練數據生成
考慮渲染參數V的參數概率分布pψ,其中ψ表示分布的參數。應注意,ψ對應于所有渲染參數,包括姿勢/縮放/照明,這里,為了簡單起見,ψ表示姿勢變量。為了生成合成訓練數據,首先采樣渲染參數V1、V2、…、VN~ pψ。然后,用NeRF生成具有各自渲染參數Vi的合成訓練圖像xi=NeRF(Vi)。 使用現成的前景提取器獲得標簽y1,y2,…,yN。由此生成的訓練數據集表示為Dtrain = {(x1,y1)、(x2,y2),…,(xN,yN)}。
優化合成數據生成
目標是優化渲染分布pψ,在Dtrain上訓練目標檢測模型使得在Dval上獲得良好的性能。如此構建一個兩層優化,即: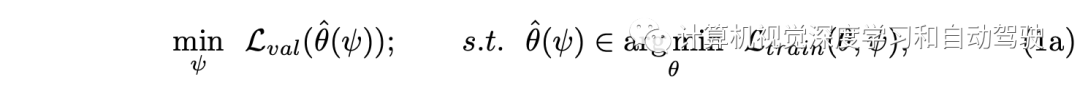
其中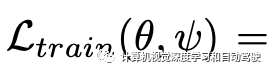
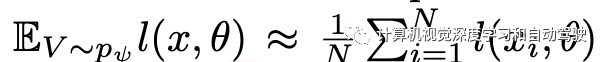
這里求解方法采用如下的梯度計算:其分成兩個項分別估計,?NeRF對應于通過從NeRF生成數據集的反向傳播,以及?TV對應于通過訓練和驗證的近似反向傳播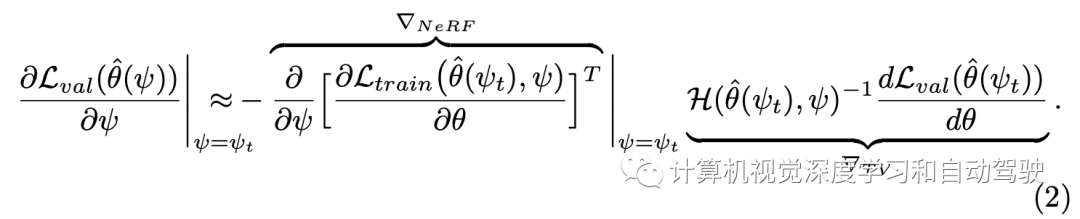
如圖所示Neural-Sim的流水線:從經過訓練的神經渲染器(NeRF)中找到生成視圖的最佳參數,用作目標檢測的訓練數據。目標是找到能夠生成合成訓練數據Dtrain的最佳NeRF渲染參數ψ,在Dtrain上訓練的模型(取RetinaNet為例)最大化驗證集Dval表示的下游任務的精度。
近似計算: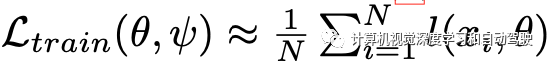
然后基于鏈式法則得到: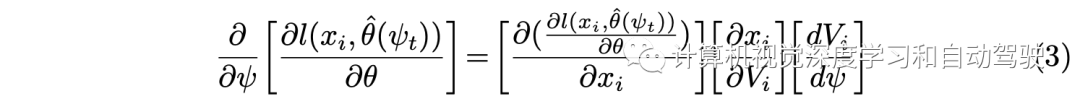
為計算采用一些近似方法:
對于位姿參數離散區間上的分布pψ,提出了一種ψ的重新參數化,提供了dVi/dψ的有效近似(工具 1)。
用一種兩次向前一次向后(twice-forward-once-backward)的方法(工具2),大大減少了(2)中梯度近似的內存和計算開銷。如果沒有這種新技術,實現中需要涉及大矩陣和計算圖的高計算開銷。
即使使用上述技術,在GPU內存方面,(3)中計算第一項和第二項的開銷很大,取決于圖像大小。用逐塊梯度計算方法(工具 3)克服了這一問題。
關于工具1中重新參數化的實現,采用bin-samplinng,如圖所示:首先將位姿空間離散為一組k個bins,然后對其進行采樣以生成NeRF的視圖參數。為了在采樣過程中反向傳播,用Gumble softmax的“重新參數化技巧”,從類別(即bin)分布中近似樣本。在每個bin中,均勻采樣。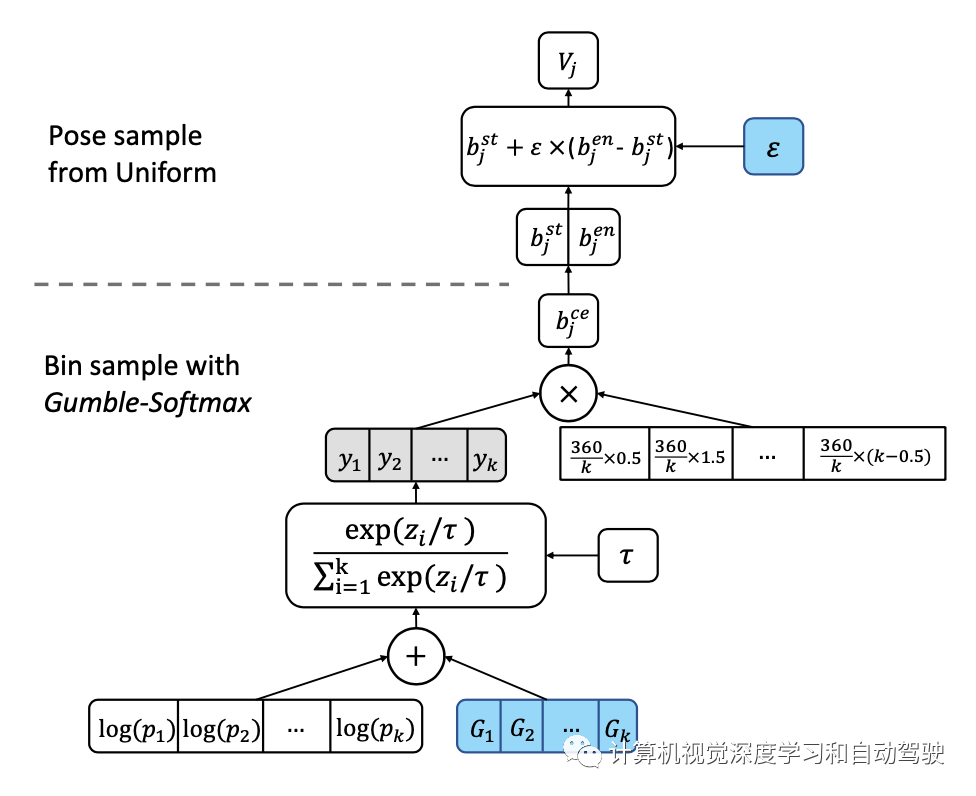
這里y的計算如下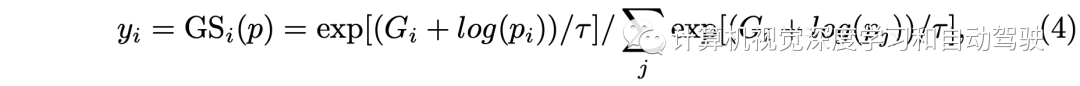
這樣?NeRF的計算變成: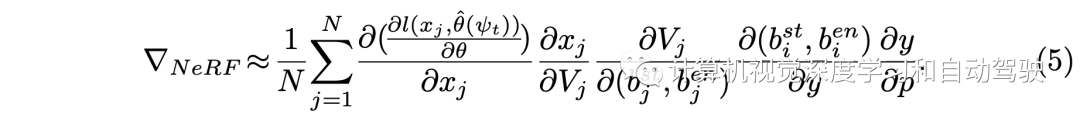
整個梯度計算包括三項:
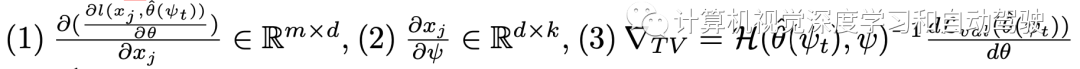 ?
?
而工具2提出的“兩次向前一次向后“方法是這樣的:在第一個前向路徑中,不計算梯度,只渲染圖像形成Dtrain,保存用于渲染的y,φj的隨機樣本。然后,轉向梯度計算(3)。在第二次通路NeRF時,保持相同的樣本,去計算梯度(1)和(2)。 所謂工具3的逐塊梯度計算如下: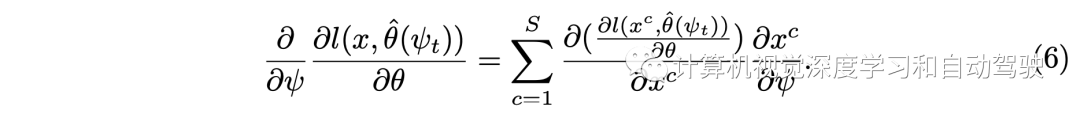
NeRF-in-the-wild(NeRF-w)擴展了普通NeRF模型,允許依賴于圖像的外觀和照明變化,從而可以顯式模擬圖像之間的光度差異。
NeRF-w沿觀看方向V作為輸入的是外觀嵌入,表示為l,圖像呈現為x=NeRF(V,l)。
對于NERF-w,位姿(V)的優化與上述相同。照明的有效優化,則利用NeRF-w的一個值得注意的特性:允許在顏色和照明之間進行平滑插值。這能夠將照明優化為連續變量,其中照明(l)可以寫成可用照明嵌入(li)的仿射函數,l = sum(ψi? li)其中sum(ψi)= 1。
為從等式(3)計算梯度,?xi/?l使用工具2和工具3,以與上述相同的方式計算l,并且dl/dψ項計算是直接的,并通過投影梯度下降(projected gradient descent)進行優化。
實現細節如下:用傳統渲染Blender-Proc,100幅具有不同攝像頭姿態和縮放因子的圖像,為每個YCB目標訓練一個NeRF-w模型。用RetinaNet作為下游目標檢測器。
為了加速優化,在訓練期間固定主干。在雙層優化步驟中,用Gumble softmax 溫度τ = 0.1。在每次優化迭代中,為每個目標類渲染50幅圖像,并訓練兩個epoch的 RetinaNet。
基線方法包括:提出的方法與學習模擬器參數的兩種流行方法進行比較。第一個基線是“Learning to simulate (LTS)“,它提出了一種基于REINFORCE的方法來優化模擬器參數。
還要注意,meta-sim是一種基于REINFORCE的方法。接下來,第二個考慮Auto-Sim,它提出了一種學習模擬器參數的有效優化方法。
NS是指提出的方法沒有做兩層優化的情況,NSO是指提出的方法采用兩層優化的情況。
實驗結果如下: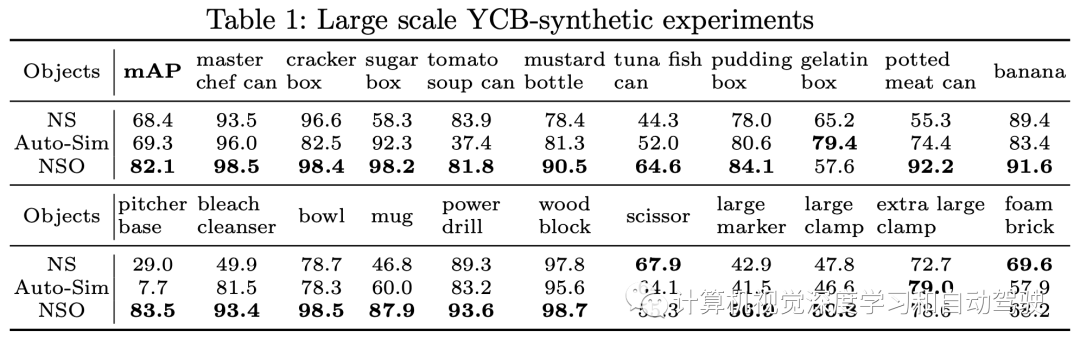
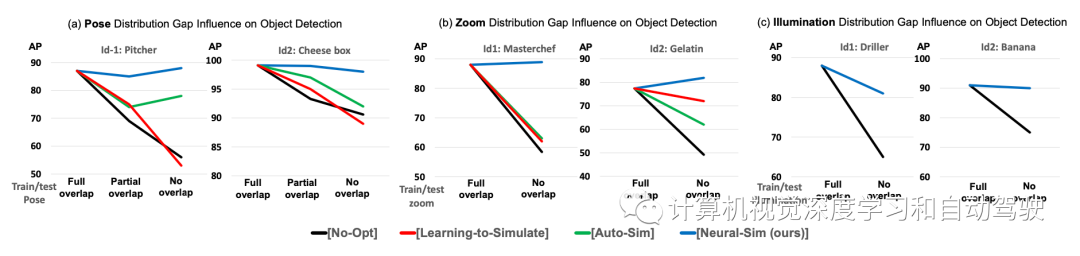
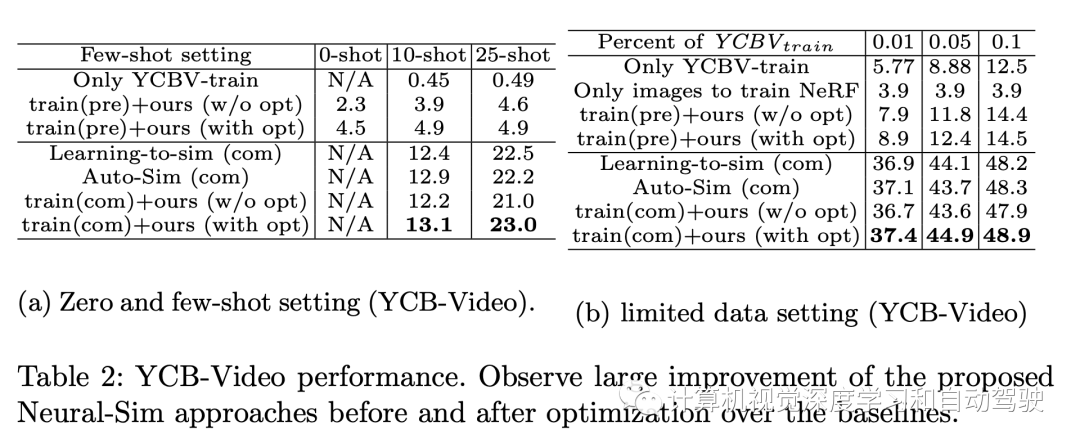
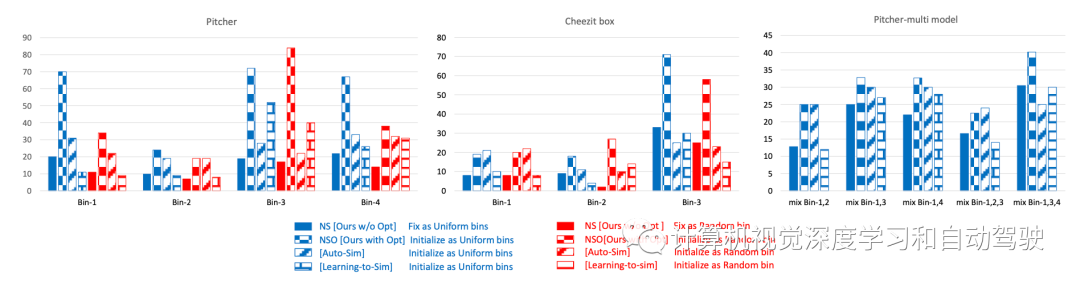
審核編輯:劉清
-
gpu
+關注
關注
28文章
4912瀏覽量
130661 -
攝像頭
+關注
關注
61文章
4951瀏覽量
97668 -
3D模型
+關注
關注
1文章
72瀏覽量
16314 -
提取器
+關注
關注
0文章
14瀏覽量
8177
原文標題:Neural-Sim: 采用NeRF學習如何生成訓練數據
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
KaihongOS操作系統FA模型與Stage模型介紹
適用于數據中心和AI時代的800G網絡
一種多模態駕駛場景生成框架UMGen介紹
英偉達GTC2025亮點 NVIDIA推出Cosmos世界基礎模型和物理AI數據工具的重大更新
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
AN-715::走近IBIS模型:什么是IBIS模型?它們是如何生成的?

【「大模型啟示錄」閱讀體驗】營銷領域大模型的應用
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
NVIDIA Isaac Sim滿足模型的多樣化訓練需求
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型

深度學習模型有哪些應用場景
AI時代,我們需要怎樣的數據中心?AI重新定義數據中心






 工商網監
工商網監
評論