") mW范圍內的機器視覺使物聯(lián)網(wǎng)端點推理變得切實可行
mW范圍內的機器視覺使物聯(lián)網(wǎng)端點推理變得切實可行
機器視覺已經(jīng)在世界上迅速找到了自己的位置。從樹上看到和采摘橙子。注視檢測針對危險不明的駕駛員。在工廠車間移動的工業(yè)機器人依靠它進行安全障礙物檢測。
物聯(lián)網(wǎng)端點位于嵌入式視覺的前沿。而且,與其他前沿領域一樣,也存在挑戰(zhàn),其中最重要的是電源效率。是否可以在不超出節(jié)點功率容量的情況下在極端邊緣進行推理?
這個問題值得考慮。這是因為在邊緣進行推理可以避免不加選擇地將數(shù)據(jù)(其中只有一些是可操作的)傳輸?shù)皆七M行分析。這降低了存儲成本。此外,訪問云會損害延遲并抑制實時功能。傳輸數(shù)據(jù)是易受攻擊的數(shù)據(jù),因此端點處理更可取。這對于降低支付給網(wǎng)絡運營商的成本也是有利的。
一種全新的 SoC 架構方法
然而,對于所有這些好處,一個主要的絆腳石仍然存在。使用傳統(tǒng)微控制器的器件的功耗限制阻礙了極端邊緣的神經(jīng)網(wǎng)絡推理。
傳統(tǒng)的微控制器(MCU)性能無法達到周期密集型操作。方法喚醒解決方案可能依賴于機器視覺進行對象分類,而機器視覺又需要卷積神經(jīng)網(wǎng)絡 (CNN) 執(zhí)行矩陣乘法運算,從而轉換為數(shù)百萬乘法累加 (MAC) 計算(圖 1)。
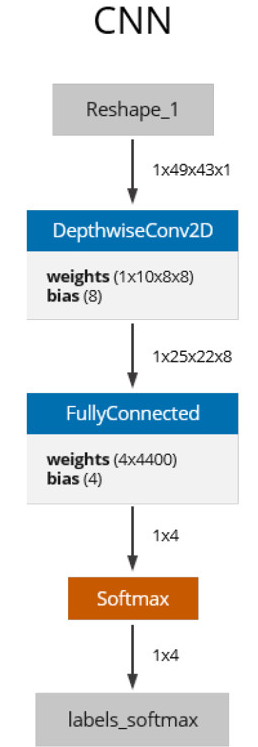
圖 1.到目前為止,微控制器無法承受大容量乘法累加(MAC)的效率問題一直是絆腳石。
MCU存在各種各樣的神經(jīng)網(wǎng)絡。但是,這些未能作為生產(chǎn)就緒的解決方案流行起來,因為所需的性能無法超越電源障礙。
克服功耗-性能難題是為什么對處理器角色和 SoC 架構采用全新方法的解決方案是有意義的。采用這種新方法需要了解物聯(lián)網(wǎng)端點有三個工作負載需要處理才能成功推理。一個是程序性的,一個是用于數(shù)字信號處理的,一個是執(zhí)行大量的MAC操作。滿足每個工作負載獨特需求的一種方法是在 SoC 中將用于信號處理和機器學習的雙 MAC 16 位 DSP 和用于程序負載的 Arm Cortex-M CPU 組合在一起。
這種混合多核架構充分利用了 DSP 雙存儲體、零環(huán)路開銷和復雜地址生成。有了它,可以處理工作負載的任意組合:例如,網(wǎng)絡堆棧,RTOS,數(shù)字濾波器,時頻轉換,RNN,CNN以及傳統(tǒng)的類似人工智能的搜索,決策樹和線性回歸。圖 2 顯示了當 DSP 架構優(yōu)勢發(fā)揮作用時,神經(jīng)網(wǎng)絡計算性能如何提高 2 倍甚至 3 倍。
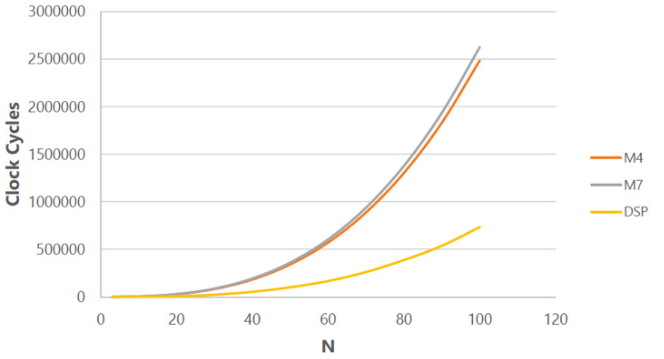
圖 2.矩陣乘法 (NxN) 基準測試。
僅靠架構更改是不夠的
無論是對于嵌入式視覺系統(tǒng)還是依賴于顯著提高神經(jīng)網(wǎng)絡效率的任何其他系統(tǒng),實施混合多核架構都很重要。但是,當目標是將功耗降至mW范圍時,必須做更多的工作。認識到這一需求,埃塔計算獲得了專利的連續(xù)電壓和頻率調節(jié)(CVFS)。
CVFS 克服了動態(tài)電壓頻率縮放或 DVFS 遇到的問題。DVFS確實利用了降低功率的選項,即降低電壓。缺點是,當執(zhí)行此選項時,最大頻率會降低。這個問題將DVFS的有效性固定在一個狹窄的范圍內——一個由嚴格限制數(shù)量的預定義離散電壓電平定義,并束縛在幾百mV的電壓范圍內。
相比之下,為了在最有效的電壓下實現(xiàn)一致的 SoC 操作,CVFS 使用自定時邏輯。通過自定時邏輯,每個器件都可以在連續(xù)的范圍內自動調整電壓和頻率。CVFS比DVFS更有效,也比亞閾值設計更容易實施,CVFS在另一個重要方面也與這些不同。這個關鍵的區(qū)別在于,上面提到的混合多核架構使CVFS已經(jīng)做的好處成倍增加。
生產(chǎn)級極致邊緣
極端邊緣的端點(例如用于人員檢測的端點)具有特定需求。雖然已發(fā)布的神經(jīng)網(wǎng)絡可供任何人用于這些物聯(lián)網(wǎng)端點,但它們并未針對這些需求進行優(yōu)先級排序。使用領先的設計技術優(yōu)化這些網(wǎng)絡可以解決這個問題。
除了使用先進的設計方法外,我們在Eta計算中采用的神經(jīng)網(wǎng)絡優(yōu)化方法還集中在我們的生產(chǎn)級神經(jīng)傳感器處理器ECM3532上(圖3)。它融合了混合多核架構和 CVFS 技術的所有優(yōu)勢。
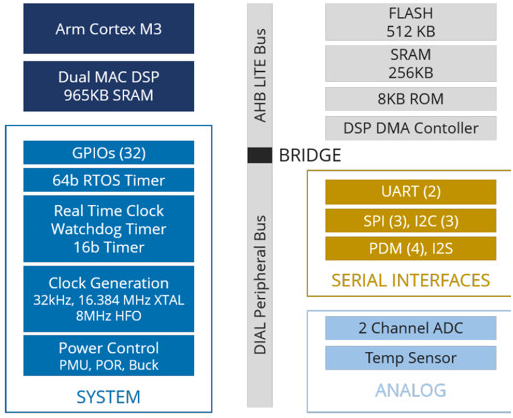
圖 3.Eta Compute ECM3532 神經(jīng)傳感器處理器采用混合多核架構,其中 Arm Cortex-M3 處理器、恩智浦 CoolFlux DSP、512KB 閃存、352KB SRAM 和支持外設集成在 SoC 中,可實現(xiàn)在 mW 范圍內的極端邊緣進行推理。
獲得的知識
圖4所示的測試結果表明,為了將深度學習引入嵌入式視覺系統(tǒng),電力成本不必上升到不可接受的水平。雖然沒有一根魔杖可以滿足耗電的神經(jīng)網(wǎng)絡的需求,但將MCU能效和DSP優(yōu)勢與網(wǎng)絡優(yōu)化相結合的方法可以幫助應用程序避免僅依靠云計算而導致的安全性,延遲和低效率問題。
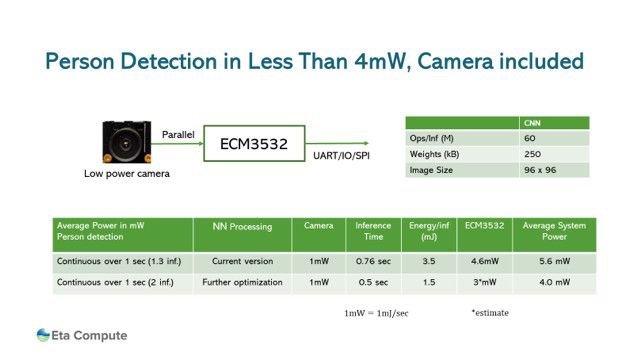
圖 4.在對人員檢測模型的測試中,包括攝像頭在內的平均系統(tǒng)功率達到5.6mW。對于此測試,速率為每秒 1.3 次推理,但進一步優(yōu)化應將平均系統(tǒng)功耗降低到 4mW,同時將速率提高到每秒 2 次推理。
審核編輯:郭婷
-
mcu
+關注
關注
146文章
17851瀏覽量
360700 -
物聯(lián)網(wǎng)
+關注
關注
2927文章
45910瀏覽量
388296 -
機器視覺
+關注
關注
163文章
4514瀏覽量
122306
發(fā)布評論請先 登錄
NXP技術白皮書:AIoT人工智能物聯(lián)網(wǎng) 將人工智能與現(xiàn)實世界相連

村田NPO電容在哪些頻率范圍內具有較好的性能?
蜂窩物聯(lián)網(wǎng)怎么選
為什么選擇蜂窩物聯(lián)網(wǎng)
宇樹科技在物聯(lián)網(wǎng)方面
《具身智能機器人系統(tǒng)》第7-9章閱讀心得之具身智能機器人與大模型
ad7124上電開啟診斷結果,顯示LDO不在范圍內,是哪里出錯了?
ADS1230怎么處理才能使信號在芯片量程范圍內?
請問ldc1101是否能夠檢測到圓球在擺幅范圍內不同位置的相對距離?
ADS131A02 0-50的溫度范圍內,ADC輸出漂移0.1%是怎么回事?
中國蜂窩物聯(lián)網(wǎng)連接數(shù)領跑全球
全天候全覆蓋的衛(wèi)星通訊方案如何在物聯(lián)網(wǎng)系統(tǒng)中應用
機器人視覺的應用范圍
芯品# 物聯(lián)網(wǎng)市場性能最高的 NPU





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論