") 二進制代碼相似度比較研究技術(shù)匯總
二進制代碼相似度比較研究技術(shù)匯總
在對二進制應(yīng)用程序進行安全分析過程中,二進制代碼相似度比較技術(shù)是重要的技術(shù)手段之一,基于此技術(shù),可以實現(xiàn)對惡意代碼極其變種的追蹤,已知漏洞檢測、補丁存在性檢測。該技術(shù)基礎(chǔ)理論依據(jù)是如果源代碼中存在的屬性(惡意代碼、已知漏洞、漏洞修復補丁)即使相同源代碼編譯出不同的二進制代碼(cpu架構(gòu)、OS、編譯選項等會直接導致編譯出來的二進制會存在較大的差別),這些屬性在二進制代碼中也是存在的(好像是廢話,不然編譯構(gòu)建工具就有問題了)。因此若在一個樣本二進制文件中已知存在上述類型的屬性,如果發(fā)現(xiàn)另外一個待檢測二進制代碼和樣本二進制代碼相似,那么可以認為待檢測二進制代碼也存在相同類型的屬性。
我們知道編譯生成二進制代碼的影響因素非常的多,同一套源代碼基于不同因素的組合可以生成非常多不同二進制程序。
CPU架構(gòu):X86、ARM、MIPS、PPC、RISC-V;
架構(gòu)位數(shù):32bits、64bits;
OS:Linux、Windows、Android、鴻蒙、VxWork;
編譯選項:O0~O3;
安全編譯選項:BIND_NOW、NX、PIC、PIE、RELRO、SP、FS、Ftrapv等;
按這些選項可以有5x2x5x4x8 =1600個組合,從中可以看出二進制代碼相似度比較技術(shù)不管是學術(shù)界還是工業(yè)界來說都是一個挑戰(zhàn)技術(shù)。但是基于廣闊的應(yīng)用前景,20多年來學術(shù)界一直在不停的探索和研究新的方法想來解決這個技術(shù)挑戰(zhàn),并且也取得了一定的成果,下面就該方面的技術(shù)進行一些梳理,讓大家對二進制代碼相似度比較技術(shù)有一個大致的了解。
源代碼到二進制代碼的生成過程
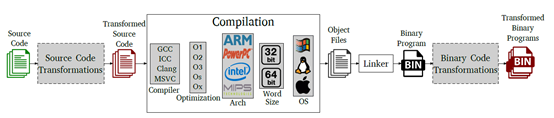
從源代碼編譯生成二進制過程中,有很多有助于理解代碼意圖的信息會被丟失,比如:函數(shù)名稱、變量名稱、數(shù)據(jù)結(jié)構(gòu)定義、變量類型定義、注釋信息等;因為二進制代碼是給CPU運行用的,因此這些信息對計算機來說不是必須的,但這些信息對人類來理解代碼是有很大幫助的,這就大大的提升了二進制代碼語義理解的難度。其次,為了更好的保護二進制代碼的知識產(chǎn)權(quán)或最大程度的提升對二進制代碼的理解難度,還會對二進制代碼進行混淆處理,使得混淆后的二進制代碼與編譯器編譯出來的二進制之間又存在很大的不同。
從歷史發(fā)表的二進制代碼相似度比較技術(shù)論文統(tǒng)計來看,有61種二進制代碼相似性比較方法,這些在不同研究場所發(fā)表的數(shù)百篇論文涵蓋了計算機安全、軟件工程、編程語言和機器學習等計算機科學領(lǐng)域,主要發(fā)表在IEEE S&P、ACM CCS、USENIX Security、NDSS、ACSAC、RAID、ESORICS、ASIACCS、DIMVA、ICSE、FSE、ISSTA、ASE、MSR等頂級刊物上。根據(jù)上述論文得到如下統(tǒng)計數(shù)據(jù):
輸入比較:一對一(21種)、一對多(30種)、多對多(10種);
比較方法:大多數(shù)方法使用單一類型的比較:相似性(42種)、等效性(5種)和相同(2種);即使方法中僅使用一種類型的比較,它也可能有不同的輸入比較不同;
分析粒度:分為輸入粒度、方法粒度;有8中不同的比較粒度,分別是指令級、基本快、函數(shù)以及相關(guān)集合、執(zhí)行軌跡、程序。最常見的輸入粒度是函數(shù)(26個),然后是整個程序(25個)和相關(guān)的基本塊(4)。最常見的方法粒度是函數(shù)(30個),然后是基本塊(20);
語法相似性:通過語法方法來捕獲代碼表示的相似性,更具體地說,它們比較指令序列。最常見的是序列中的指令在虛擬地址空間中是連續(xù)的,屬于同一函數(shù)。
語義相似性:語義相似性是指所比較的代碼是否具有類似的效果,而語法相似性則是指代碼表示中的相似性。其中有26種計算語義相似度的方法。它們中的大多數(shù)以基本塊粒度捕獲語義,因為基本塊是沒有控制流的直線代碼。有三種方法用于捕獲語義:指令分類、輸入-輸出對和符號公式。
結(jié)構(gòu)相似度:結(jié)構(gòu)相似性計算二進制代碼的圖表示上的相似性。它位于句法和語義相似性之間,因為圖可以捕獲同一代碼的多個句法表示,并可以用語義信息注釋。結(jié)構(gòu)相似性可以在不同的圖上計算。常見的有控制流圖CFG、過程間控制流圖ICFG、調(diào)用圖CG;(子)圖同構(gòu)—大多數(shù)結(jié)構(gòu)相似性方法是檢查圖同構(gòu)的變化,其中涉及到方法有K子圖匹配、路徑相似性、圖嵌入。
基于特征的相似度:計算相似性的常見方法(28種)是將一段二進制代碼表示為向量或一組特征,使得類似的二進制代碼具有相似的特征向量或特征集。這里應(yīng)用最多的是利用機器學習來實現(xiàn)。
Hash匹配相似度:對于多維向量數(shù)據(jù)相似度快速匹配,通常使用局部敏感hash算法LSH來實現(xiàn)。
跨架構(gòu)比較方法:對不同CPU架構(gòu)二進制代碼的相似度比較,通常跨體系結(jié)構(gòu)方法通過計算語義相似性來實現(xiàn)。方法之一是通過轉(zhuǎn)換成與架構(gòu)無關(guān)的中間語言IR來處理(7種),另外一種是使用基于特征的相似性方法(9種)。
分析類型:從分析類型來看有:靜態(tài)分析、動態(tài)分析、數(shù)據(jù)流分析3種類型;
歸一化方法:語法相似性方法通常會對指令進行規(guī)范化,來盡量減少語法上的差異;有33種方法使用指令規(guī)范化。具體的包括操作數(shù)移除法、操作數(shù)歸一化法、助記符歸一化法
論文發(fā)表的時間、發(fā)表刊物、技術(shù)方法匯總
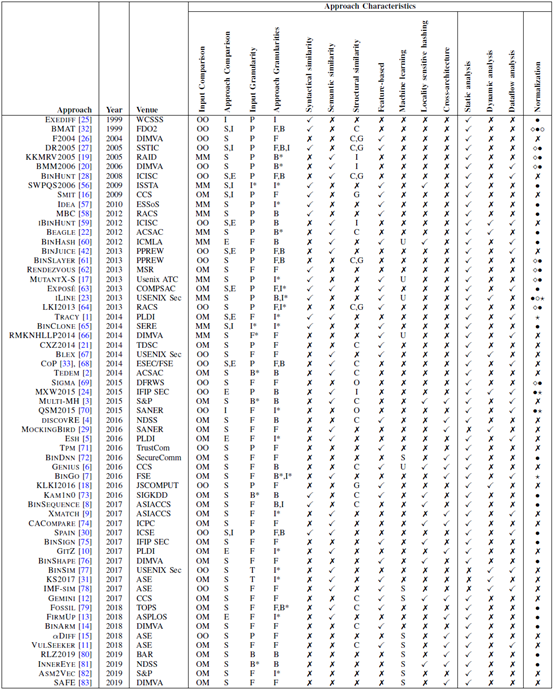
不同二進制代碼相似度比較方法的具體應(yīng)用情況
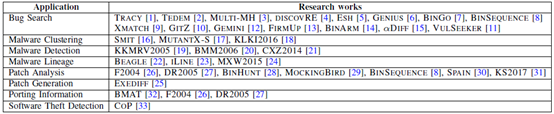
從上表中可以看出二進制代碼相似度比較主要應(yīng)用于漏洞查找,其次是補丁分析和惡意代碼分析;
針對上述不同的技術(shù)方法,分別從魯棒性、準確度評估與比較、性能指標3個維度進行評測,結(jié)果如下:
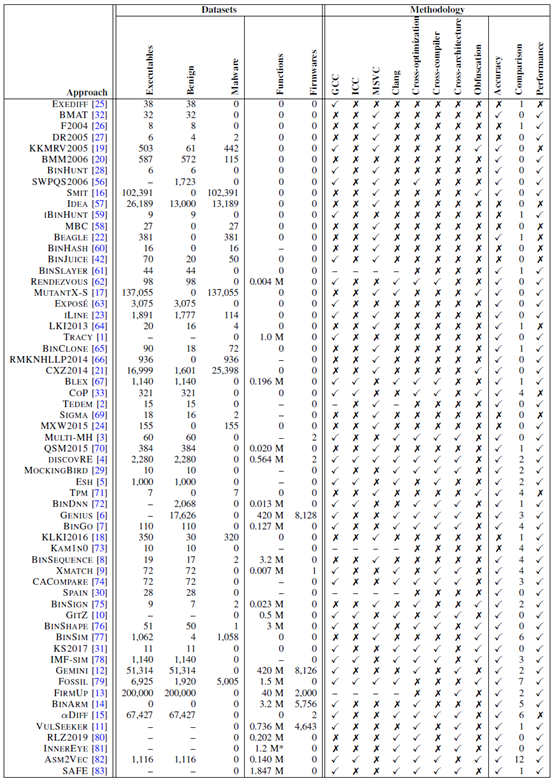
總結(jié):二進制代碼相似性比較技術(shù)隨著研究的持續(xù)進行,學術(shù)界雖然取得的一定的進步和成果,但仍然還有很多挑戰(zhàn)在等著攻克,小片段的二進制代碼比較,源代碼與二進制的相似度比較、數(shù)據(jù)相似度比較、語義關(guān)系、可擴展性、混淆、比較方法等等都是后續(xù)需要持續(xù)研究的方向。
審核編輯:湯梓紅
-
二進制
+關(guān)注
關(guān)注
2文章
803瀏覽量
42122 -
代碼
+關(guān)注
關(guān)注
30文章
4886瀏覽量
70216
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論