") NVIDIA為HPC和AI加強(qiáng)超級(jí)芯片工程
NVIDIA為HPC和AI加強(qiáng)超級(jí)芯片工程
NVIDIA Grace CPU 是 NVIDIA 開發(fā)的第一個(gè)數(shù)據(jù)中心 CPU 。它是從頭開始建造的,以創(chuàng)建 世界上第一個(gè)超級(jí)芯片 。
旨在提供卓越的性能和能效,以滿足現(xiàn)代數(shù)據(jù)中心工作負(fù)載的供電需求 數(shù)字孿生 , 云游戲和圖形 , 人工智能 和 高性能計(jì)算 ( HPC ) NVIDIA Grace CPU 具有 72 個(gè) Armv9 GPU 內(nèi)核,實(shí)現(xiàn) Arm 可伸縮向量擴(kuò)展第二版 ( SVE2 )指令集。核心還包括具有嵌套虛擬化功能和 S-EL2 支持的虛擬化擴(kuò)展。
NVIDIA Grace CPU 還符合以下 Arm 規(guī)范:
RAS v1.1 通用中斷控制器( GIC ) v4.1
內(nèi)存分區(qū)和監(jiān)視( MPAM )
系統(tǒng)內(nèi)存管理單元( SMMU ) v3.1
Grace CPU 被構(gòu)建為與 NVIDIA Hopper GPU 創(chuàng)建用于大規(guī)模人工智能訓(xùn)練、推理和高性能計(jì)算的 NVIDIA Grace CPU 超級(jí)芯片,或與另一個(gè) Grace CPU ,構(gòu)建高性能[Z1K22],以滿足高性能計(jì)算和云計(jì)算工作負(fù)載的需求。
繼續(xù)閱讀,了解 Grace CPU 的主要功能。
使用 NVLink-C2C 的高速芯片間互連
Grace Hopper 和 Grace 超級(jí)芯片均由 NVIDIA NVLink-C2C 高速芯片間互連,用作超級(jí)芯片通信的主干。
NVLink-C2C 擴(kuò)展 NVIDIA NVLink 用于連接服務(wù)器中的多個(gè) GPU ,以及使用 NVLink 交換機(jī)系統(tǒng)連接多個(gè) GPU 節(jié)點(diǎn)。
NVLink-C2C 在封裝上的裸片之間具有 900GB / s 的原始雙向帶寬,提供了 PCIe Gen 5 x16 鏈路的 7 倍帶寬(與使用 NVLink 時(shí) NVIDIA Hopper GPU 之間可用的帶寬相同)和更低的延遲。 NVLink-C2C 還只需要傳輸 1.3 微微焦耳/位,這是 PCIe Gen 5 能效的 5 倍以上。
NVLink-C2C 也是一種相干互連,在使用 Grace CPU 超級(jí)芯片對(duì)標(biāo)準(zhǔn)相干[Z1K22]平臺(tái)以及使用 Grace Hopper 超級(jí)芯片的異構(gòu)編程模型進(jìn)行編程時(shí),能夠?qū)崿F(xiàn)一致性。
使用 NVIDIA Grace CPU 的符合標(biāo)準(zhǔn)的平臺(tái)
NVIDIA Grace CPU 超級(jí)芯片旨在為軟件開發(fā)人員提供符合標(biāo)準(zhǔn)的平臺(tái)。 Arm 提供了一套規(guī)范,作為其系統(tǒng)就緒計(jì)劃的一部分,旨在為 Arm 生態(tài)系統(tǒng)帶來標(biāo)準(zhǔn)化。
Grace CPU 以 Arm 系統(tǒng)標(biāo)準(zhǔn)為目標(biāo),提供與現(xiàn)成操作系統(tǒng)和軟件應(yīng)用程序的兼容性, Grace CPU 將從一開始就利用 NVIDIA Arm 軟件堆棧。
Grace CPU 還符合 Arm 服務(wù)器基礎(chǔ)系統(tǒng)架構(gòu)( SBSA ),以實(shí)現(xiàn)符合標(biāo)準(zhǔn)的硬件和軟件接口。此外,為了在基于 Grace CPU 的系統(tǒng)上啟用標(biāo)準(zhǔn)引導(dǎo)流, Grace CPU 被設(shè)計(jì)為支持 Arm 服務(wù)器基本引導(dǎo)要求( SBBR )。
對(duì)于緩存和帶寬分區(qū)以及帶寬監(jiān)控, Grace CPU 還支持 Arm 內(nèi)存分區(qū)和監(jiān)控( MPAM )。
Grace CPU 還包括 Arm 性能監(jiān)控單元,允許對(duì) GPU 內(nèi)核以及片上系統(tǒng)( SoC )架構(gòu)中的其他子系統(tǒng)進(jìn)行性能監(jiān)控。這使得標(biāo)準(zhǔn)工具(如 Linux perf )可以用于性能調(diào)查。
帶 Grace Hopper 超級(jí)芯片的統(tǒng)一內(nèi)存
NVIDIA Grace Hopper 超級(jí)芯片將 Grace CPU 與 Hopper GPU 相結(jié)合,擴(kuò)展了 CUDA 在 CUDA 8.0 中首次引入的統(tǒng)一內(nèi)存編程模型。
NVIDIA Grace Hopper 超級(jí)芯片引入了具有共享頁(yè)表的統(tǒng)一內(nèi)存,允許 Grace CPU 和 Hopper GPU 與 CUDA 應(yīng)用程序共享地址空間甚至頁(yè)表。
Grace Hopper GPU 還可以訪問可分頁(yè)內(nèi)存分配。 Grace Hopper 超級(jí)芯片允許程序員使用系統(tǒng)分配器分配 GPU 內(nèi)存,包括與 GPU 交換指向malloc內(nèi)存的指針。
NVLink-C2C 支持 Grace CPU 和 Hopper GPU 之間的本機(jī)原子支持,釋放了 CUDA 10.2 中首次引入的 C ++原子的全部潛力。
NVIDIA 可伸縮一致性結(jié)構(gòu)
Grace CPU 介紹了 NVIDIA 可伸縮一致性結(jié)構(gòu)( SCF )。由 NVIDIA 設(shè)計(jì)的 SCF 是一種網(wǎng)格結(jié)構(gòu)和分布式緩存,旨在根據(jù)數(shù)據(jù)中心的需要進(jìn)行擴(kuò)展。 SCF 提供 3.2 TB / s 的二等分帶寬,以確保 NVLink-C2C 、 CPU 核心、內(nèi)存和系統(tǒng) IO 之間的數(shù)據(jù)流量。
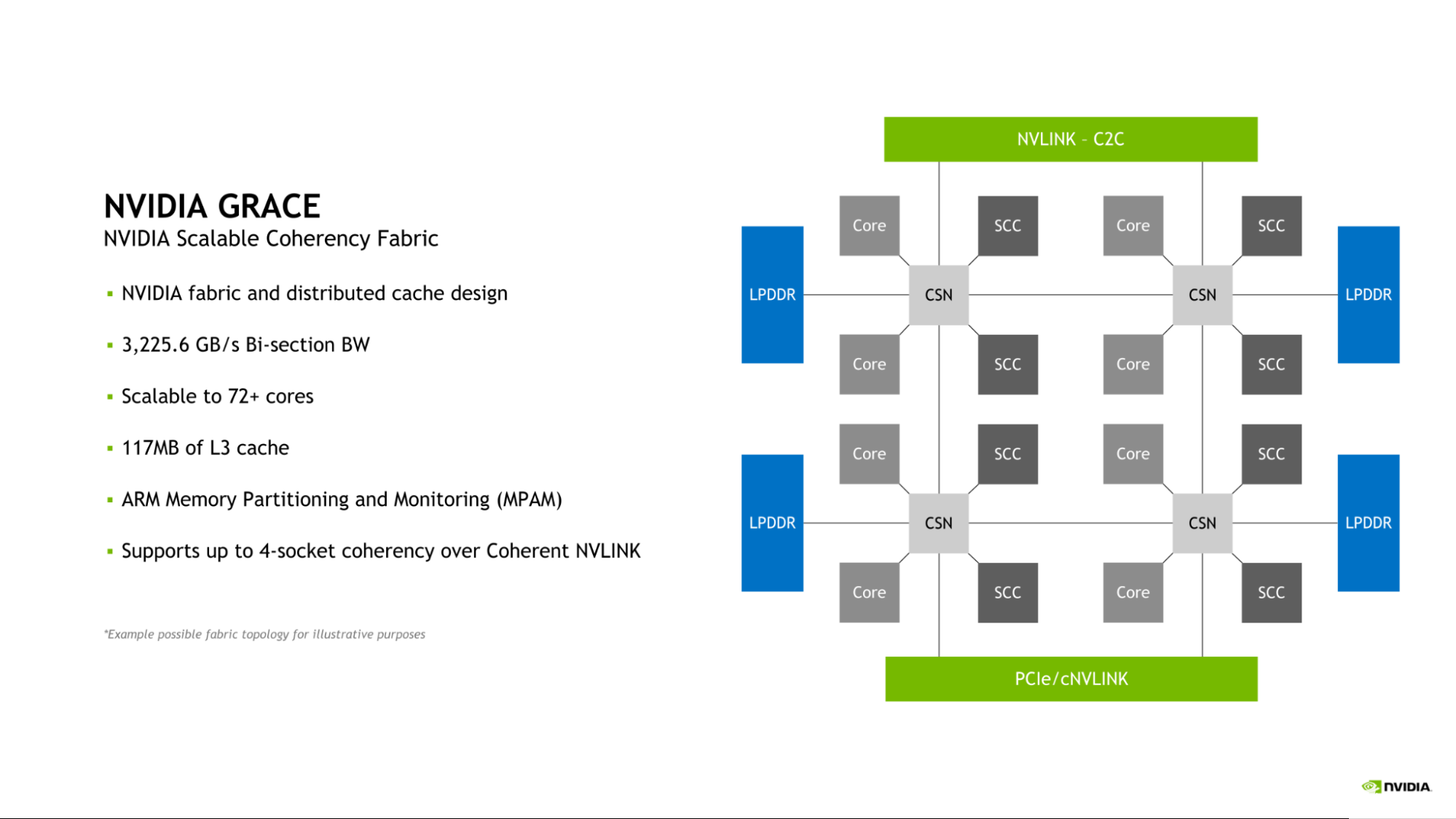
圖 1.隨 Grace CPU 引入的 NVIDIA 可伸縮一致性結(jié)構(gòu)圖
單個(gè) Grace CPU 包含 72 個(gè) GPU 內(nèi)核和 117MB 緩存,但 SCF 的設(shè)計(jì)可擴(kuò)展性超出此配置。當(dāng)兩個(gè) Grace CPU 組合形成一個(gè) Grace 超級(jí)芯片時(shí),這些數(shù)字分別增加到 144 個(gè) CPU 核和 234MB 的 L3 緩存。
CPU 核心和 SCF 緩存分區(qū)( SCC )分布在整個(gè)網(wǎng)格中。緩存交換節(jié)點(diǎn)( CSN )通過結(jié)構(gòu)路由數(shù)據(jù),并充當(dāng) CPU 核心、緩存內(nèi)存和系統(tǒng)其余部分之間的接口,從而實(shí)現(xiàn)整個(gè)系統(tǒng)的高帶寬。
內(nèi)存分區(qū)和監(jiān)視
Grace CPU 集成了對(duì)內(nèi)存系統(tǒng)資源分區(qū)和監(jiān)控( MPAM )功能的支持,這是 Arm 對(duì)系統(tǒng)緩存和內(nèi)存資源進(jìn)行分區(qū)的標(biāo)準(zhǔn)。
MPAM 通過向系統(tǒng)內(nèi)的請(qǐng)求者分配分區(qū) ID ( PartID )來工作。這種設(shè)計(jì)允許基于其各自的分區(qū)對(duì)資源(如緩存容量和內(nèi)存帶寬)進(jìn)行分區(qū)或監(jiān)控。
Grace CPU 中的 SCF 緩存支持使用 MPAM 對(duì)緩存容量和內(nèi)存帶寬進(jìn)行分區(qū)。此外,性能監(jiān)視組( PMG )可用于監(jiān)視資源使用情況。
利用內(nèi)存子系統(tǒng)提高帶寬和能效
為了提供卓越的帶寬和能效, Grace CPU 實(shí)現(xiàn)了 32 通道 LPDDR5X 內(nèi)存接口。這提供了高達(dá) 512GB 的內(nèi)存容量和高達(dá) 546GB / s 的內(nèi)存帶寬。
擴(kuò)展 GPU 存儲(chǔ)器
Grace Hopper 超級(jí)芯片的一個(gè)關(guān)鍵特征是引入了擴(kuò)展 GPU 內(nèi)存( EGM )。通過允許從更大的 NVLink 網(wǎng)絡(luò)連接的任何漏斗 GPU 訪問連接到 Grace Hopper 超級(jí)芯片中 Grace CPU 的 LPDDR5X 內(nèi)存,大大擴(kuò)展了 GPU 可用的內(nèi)存池。
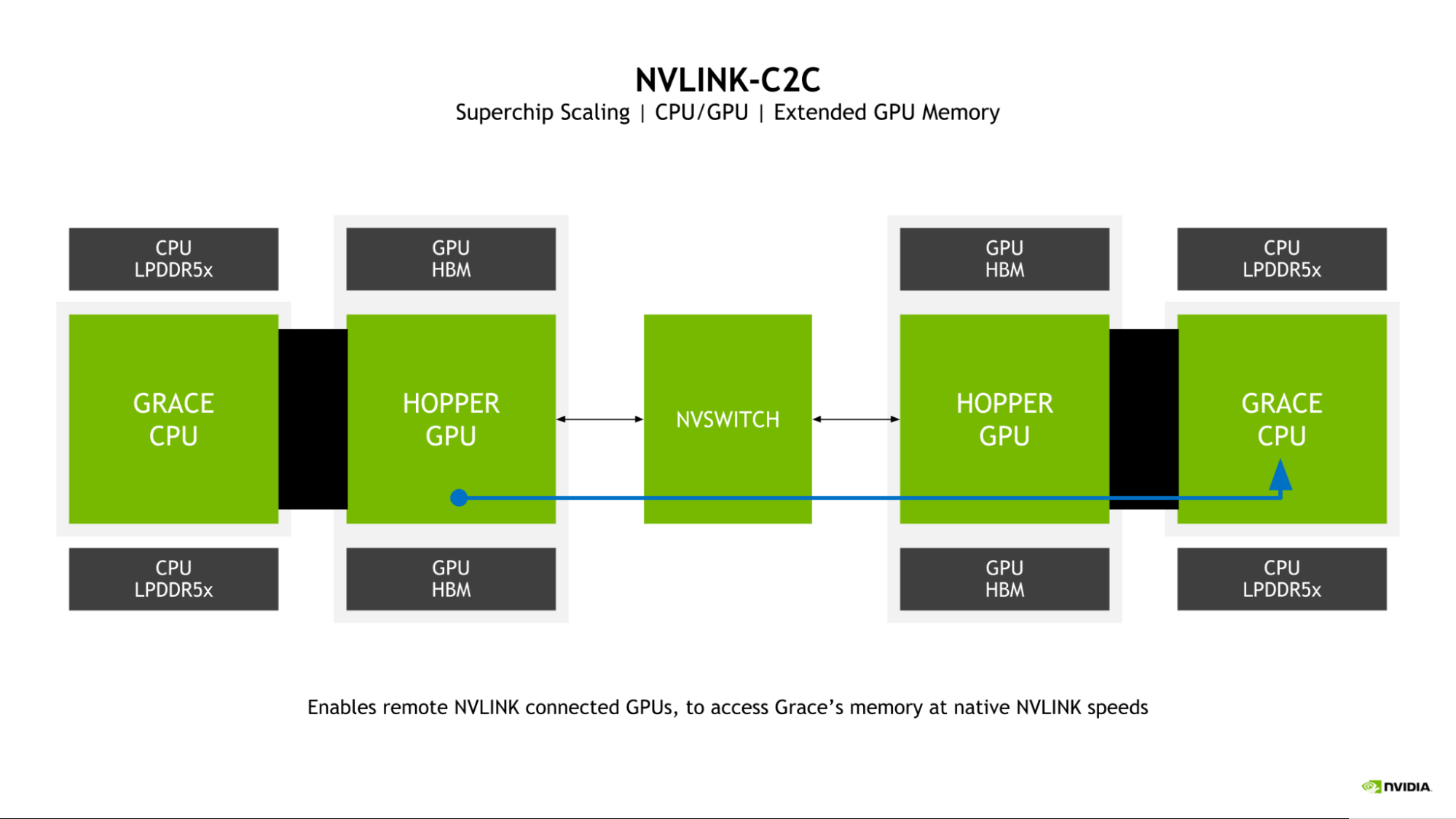
圖 2.漏斗 GPU 可以使用 NVLink-C2C 訪問遠(yuǎn)程 Grace CPU 的存儲(chǔ)器
GPU 到 – GPU NVLink 和 NVLink-C2C 雙向帶寬在超級(jí)芯片中匹配,這使得料斗 GPU 能夠以 NVLink 本地速度訪問 Grace CPU 存儲(chǔ)器。
使用 LPDDR5X 平衡帶寬和能效
為 Grace CPU 選擇 LPDDR5X 是因?yàn)樾枰诖笠?guī)模 AI 和 HPC 工作負(fù)載的帶寬、能效、容量和成本之間取得最佳平衡。
雖然四站點(diǎn) HBM2e 內(nèi)存子系統(tǒng)將提供大量?jī)?nèi)存帶寬和良好的能效,但其成本將是 DDR5 或 LPDDR5X 每 GB 成本的 3 倍以上。
此外,這種配置將僅限于 64GB 的容量,這是具有 LPDDR5X 的 Grace CPU 可用的最大容量的八分之一。
與更傳統(tǒng)的八通道 DDR5 設(shè)計(jì)相比, Grace CPU LPDDR5X 內(nèi)存子系統(tǒng)提供了高達(dá) 53% 的帶寬,并大大提高了功率效率,每千兆字節(jié)只需要八分之一的功率。
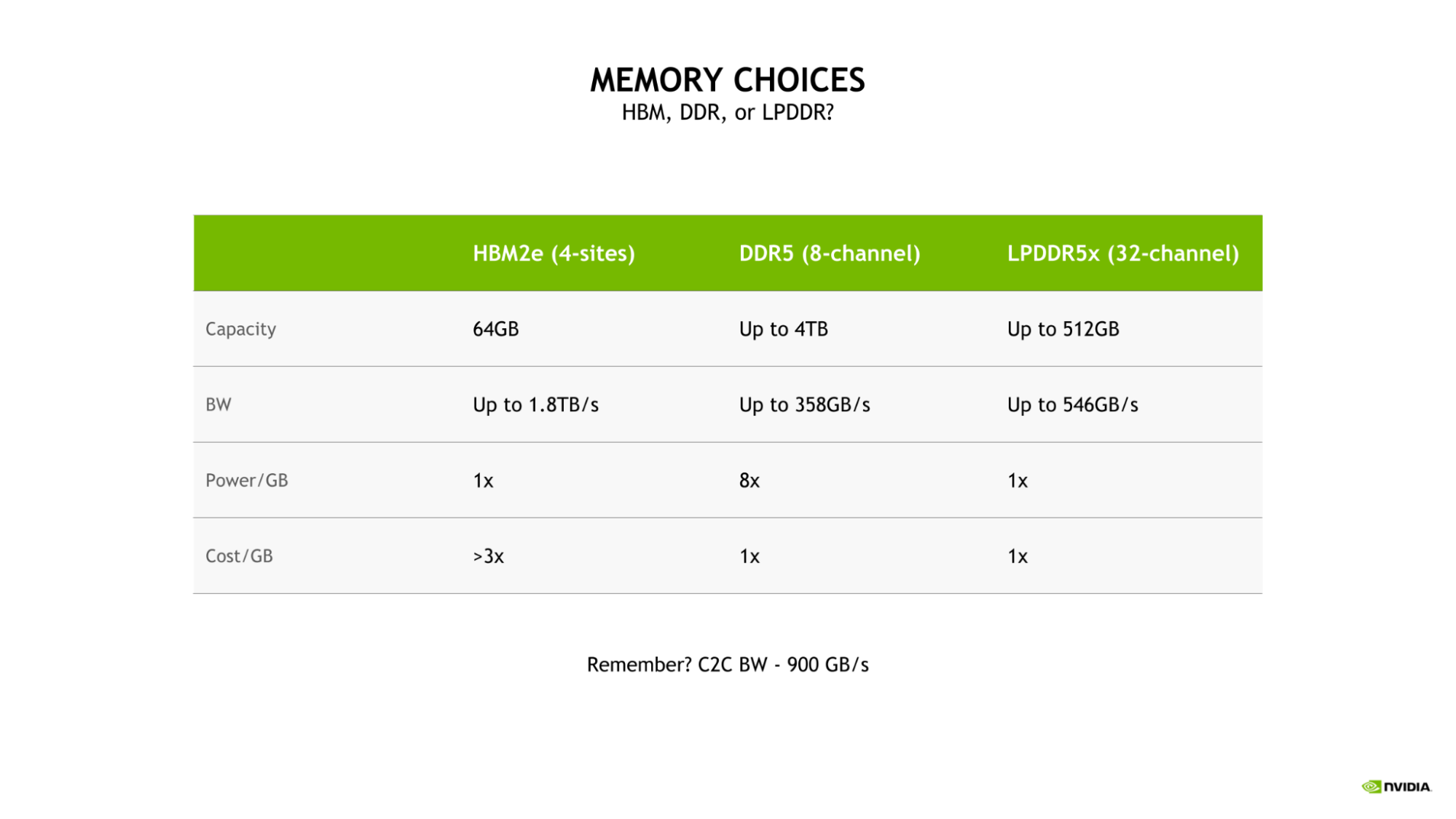
圖 3.HBM2e ( 4 個(gè)站點(diǎn))、 DDR5 ( 8 通道)和 LPDDR5x ( 32 通道)內(nèi)存選項(xiàng)的容量、帶寬、功率和成本比較
LPDDR5X 卓越的功率效率使得能夠?qū)⒏嗟目偣β暑A(yù)算分配給計(jì)算資源,例如 CPU 核或 GPU 流式多處理器( SMs )。
NVIDIA Grace CPU 輸入/輸出
Grace CPU 整合了一系列高速 I / O ,以滿足現(xiàn)代數(shù)據(jù)中心的需求。 Grace CPU SoC 提供多達(dá) 68 條 PCIe 連接通道和多達(dá) 4 條 PCIe Gen 5 x16 鏈路。每個(gè) PCIe Gen 5 x16 鏈路提供高達(dá) 128GB / s 的雙向帶寬,并可進(jìn)一步分叉為兩個(gè) PCIe Gen 5×8 鏈路,以實(shí)現(xiàn)額外的連接。
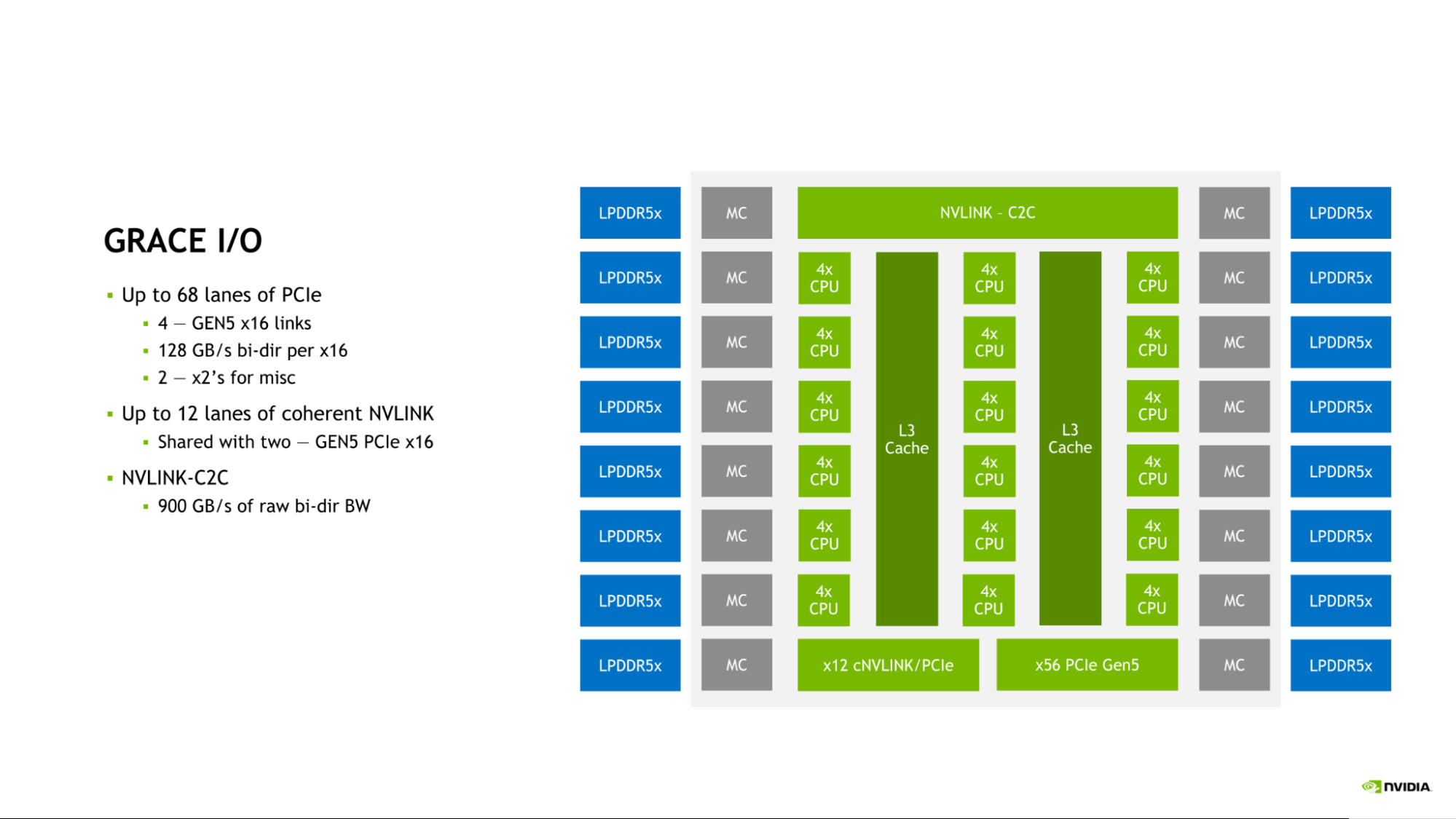
圖 4.Grace I / O 功能多達(dá) 68 條 PCIe 通道、 12 條相干 NVLINK 通道和 NVLINK-C2C
這種連接是對(duì)片上 NVLink-C2C 鏈路的補(bǔ)充,該鏈路可用于將 Grace CPU 連接到另一個(gè) Grace CPU ,或連接到 NVIDIA Hopper GPU 。
NVLink 、 NVLink-C2C 和 PCIe Gen 5 的組合為 Grace CPU 提供了豐富的連接選項(xiàng)套件和擴(kuò)展現(xiàn)代數(shù)據(jù)中心性能所需的充足帶寬。
NVIDIA Grace CPU 性能
NVIDIA Grace CPU 設(shè)計(jì)用于在單芯片和 Grace 超級(jí)芯片配置中提供卓越的計(jì)算性能,估計(jì)SPECrate2017_int_base得分分別為 370 和 740 。這些預(yù)硅估計(jì)基于 GNU 編譯器集合( GCC )的使用。
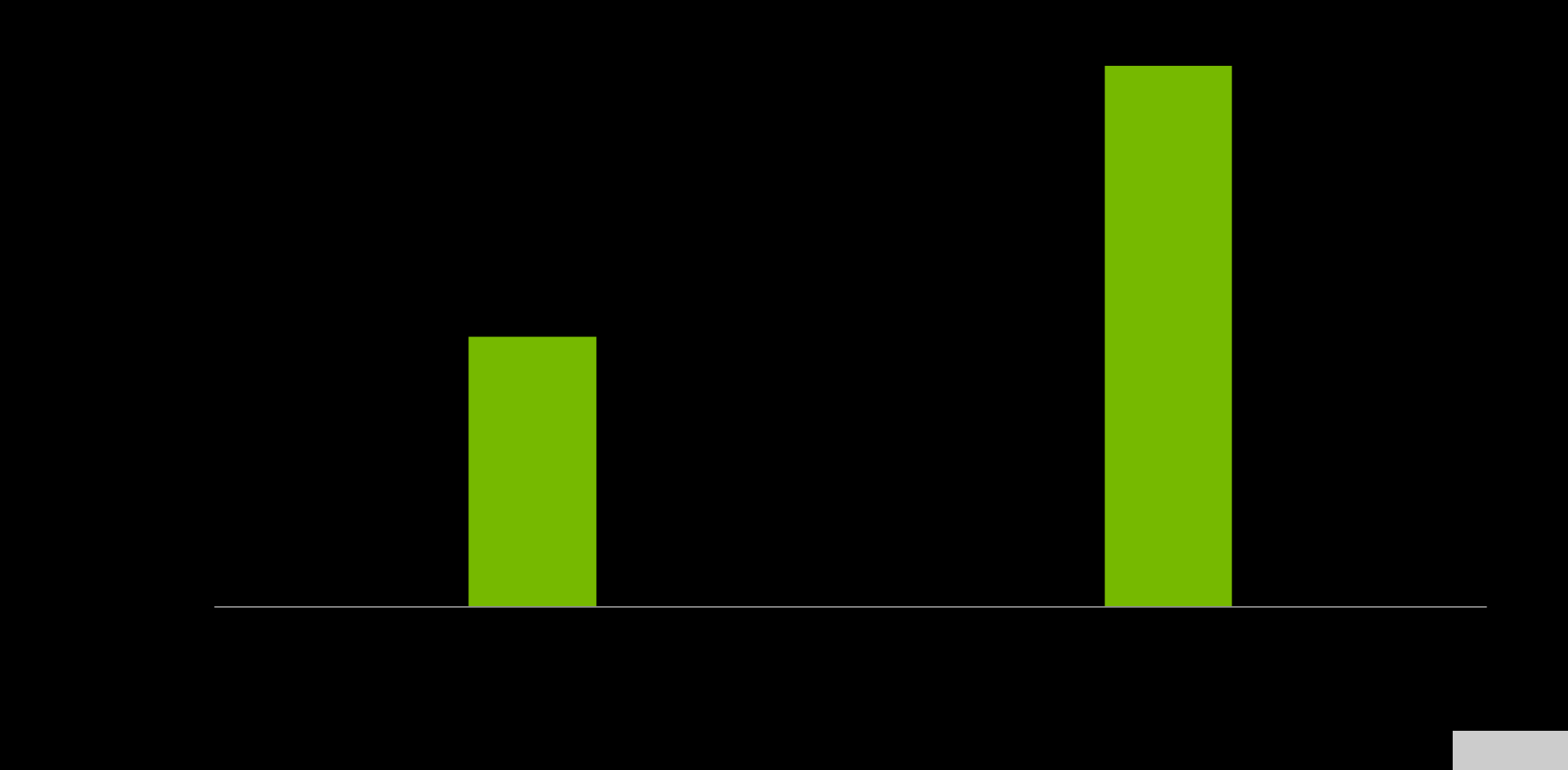
圖 5.單個(gè) Grace CPU (左)和 Grace 超級(jí)芯片(右)的規(guī)格速率估計(jì)。 來源:預(yù)硅估計(jì)性能(可能會(huì)更改)。
內(nèi)存帶寬對(duì)于設(shè)計(jì) Grace CPU 的工作負(fù)載至關(guān)重要,在流基準(zhǔn)測(cè)試中,單個(gè) Grace CPU ,預(yù)計(jì)可提供高達(dá) 536GB / s 的實(shí)際帶寬,占芯片峰值理論帶寬的 98% 以上。
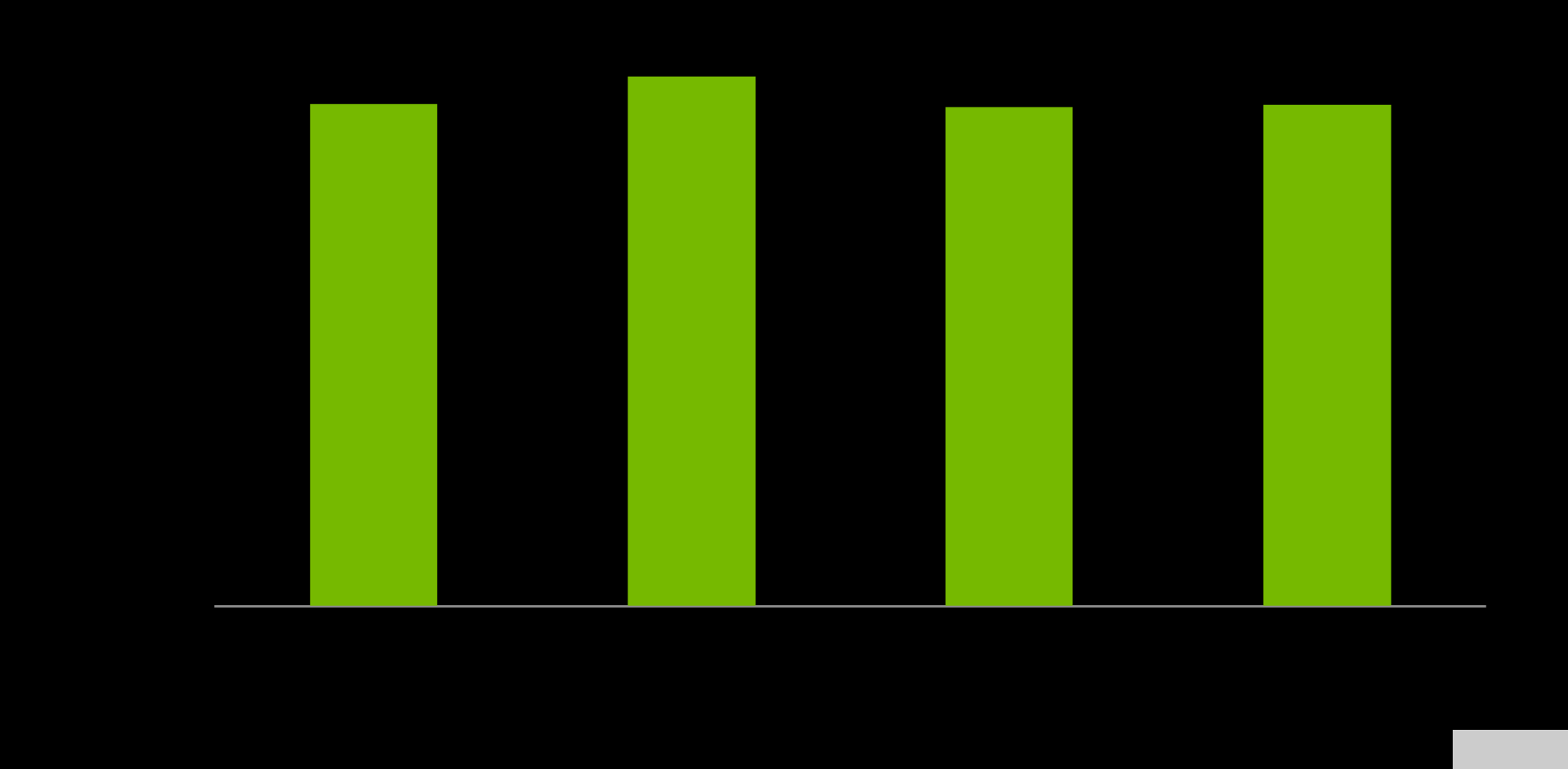
圖 6.MemRead 、 MemSet 、 MemCopy 和 MemTriad 的 Grace CPU 內(nèi)存基準(zhǔn)測(cè)試結(jié)果(從左到右)
最后,料斗 GPU 和 Grace CPU 之間的帶寬對(duì)于最大化 Grace 料斗超級(jí)芯片的性能至關(guān)重要。 GPU 對(duì) – CPU 內(nèi)存的讀和寫預(yù)計(jì)分別為 429GB / s 和 407GB / s ,分別代表 NVLink-C2C 峰值理論單向傳輸速率的 95% 和 90% 以上。
綜合讀寫性能預(yù)計(jì)為 506GB / s ,占單個(gè) NVIDIA Grace CPU SoC 可用峰值理論內(nèi)存帶寬的 92% 以上。
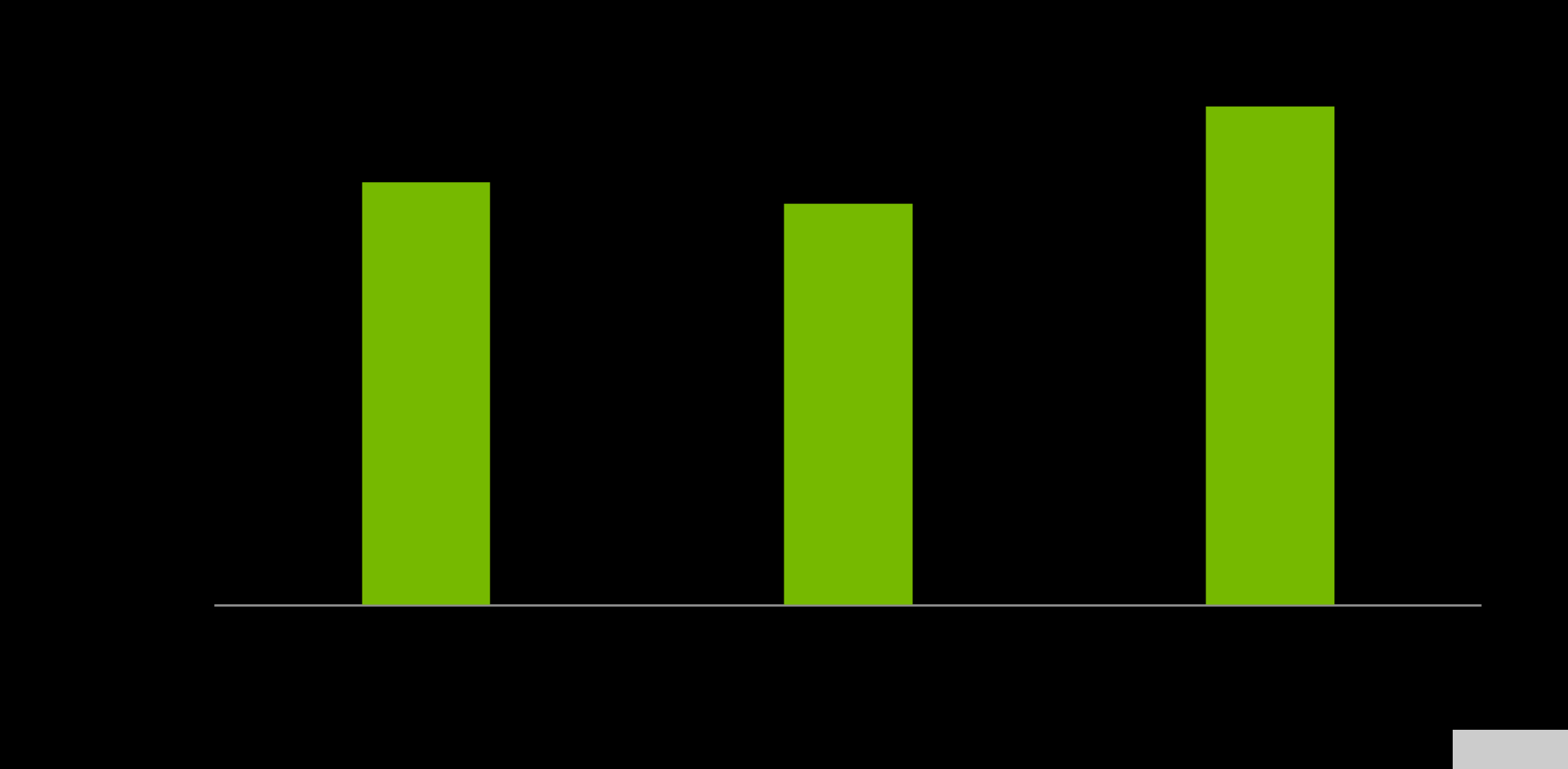
圖 7.Hopper GPU 到 Grace memory 基準(zhǔn)測(cè)試結(jié)果
NVIDIA Grace CPU 超級(jí)芯片的優(yōu)勢(shì)
NVIDIA Grace CPU 超級(jí)芯片擁有 144 個(gè)核心和 1TB / s 的內(nèi)存帶寬,將為基于 CPU 的高性能計(jì)算應(yīng)用提供前所未有的性能。 HPC 應(yīng)用程序是計(jì)算密集型應(yīng)用程序,需要性能最高的核心、最高的內(nèi)存帶寬和每個(gè)核心的正確內(nèi)存容量,以加快結(jié)果。
NVIDIA 正在與領(lǐng)先的 HPC 、超級(jí)計(jì)算、超尺度和云客戶合作,開發(fā) Grace CPU 超級(jí)芯片。 Grace CPU 超級(jí)芯片和 Grace Hopper 超級(jí)芯片預(yù)計(jì)將于 2023 年上半年上市。
關(guān)于作者
Jonathon Evans 是 NVIDIA 杰出工程師,也是 NVIDIA Grace CPU 的架構(gòu)主管。 Jonathon 于 2007 年加入 NVIDIA ,成為 GPU 架構(gòu)團(tuán)隊(duì)的成員。他之前在 GPU 方面的工作包括領(lǐng)導(dǎo) GPU 的上下文管理和調(diào)度硬件團(tuán)隊(duì),以及對(duì)異步計(jì)算、統(tǒng)一內(nèi)存、多實(shí)例 GPU 和 WDDM 硬件調(diào)度的貢獻(xiàn)。
Ashraf Eassa 是NVIDIA 加速計(jì)算集團(tuán)內(nèi)部的高級(jí)產(chǎn)品營(yíng)銷經(jīng)理。
審核編輯:郭婷
-
控制器
+關(guān)注
關(guān)注
114文章
16963瀏覽量
182891 -
cpu
+關(guān)注
關(guān)注
68文章
11033瀏覽量
215984 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5240瀏覽量
105768
發(fā)布評(píng)論請(qǐng)先 登錄
使用NVIDIA CUDA-X庫(kù)加速科學(xué)和工程發(fā)展
NVIDIA 宣布推出 DGX Spark 個(gè)人 AI 計(jì)算機(jī)

MediaTek與NVIDIA攜手設(shè)計(jì)GB10 Grace Blackwell超級(jí)芯片
MediaTek與NVIDIA攜手打造超級(jí)芯片
MediaTek與NVIDIA攜手打造GB10 Grace Blackwell超級(jí)芯片
NVIDIA推出個(gè)人AI超級(jí)計(jì)算機(jī)Project DIGITS
聯(lián)發(fā)科與NVIDIA合作 為NVIDIA 個(gè)人AI超級(jí)計(jì)算機(jī)設(shè)計(jì)NVIDIA GB10超級(jí)芯片
NVIDIA 推出高性價(jià)比的生成式 AI 超級(jí)計(jì)算機(jī)

賴耶科技通過NVIDIA AI Enterprise平臺(tái)打造超級(jí)AI工廠
NVIDIA助力xAI打造全球最大AI超級(jí)計(jì)算機(jī)
維諦技術(shù)(Vertiv):未來HPC,你想象不到的酷炫變革!

NVIDIA 以太網(wǎng)加速 xAI 構(gòu)建的全球最大 AI 超級(jí)計(jì)算機(jī)

NVIDIA助力丹麥發(fā)布首臺(tái)AI超級(jí)計(jì)算機(jī)
NVIDIA攜手Meta推出AI服務(wù),為企業(yè)提供生成式AI服務(wù)
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論