 一種基于卷積多層感知器(MLP)改進U型架構的方法
一種基于卷積多層感知器(MLP)改進U型架構的方法
隨著醫學圖像的解決方案變得越來越適用,我們更需要關注使深度網絡輕量級、快速且高效的方法。具有高推理速度的輕量級網絡可以被部署在手機等設備上,例如 POCUS(point-of-care ultrasound)被用于檢測和診斷皮膚狀況。這就是 UNeXt 的動機。
方法概述
之前我們解讀過基于 Transformer 的 U-Net 變體,近年來一直是領先的醫學圖像分割方法,但是參數量往往不樂觀,計算復雜,推理緩慢。這篇文章提出了基于卷積多層感知器(MLP)改進 U 型架構的方法,可以用于圖像分割。設計了一個 tokenized MLP 塊有效地標記和投影卷積特征,使用 MLPs 來建模表示。這個結構被應用到 U 型架構的下兩層中(這里我們假設縱向一共五層)。
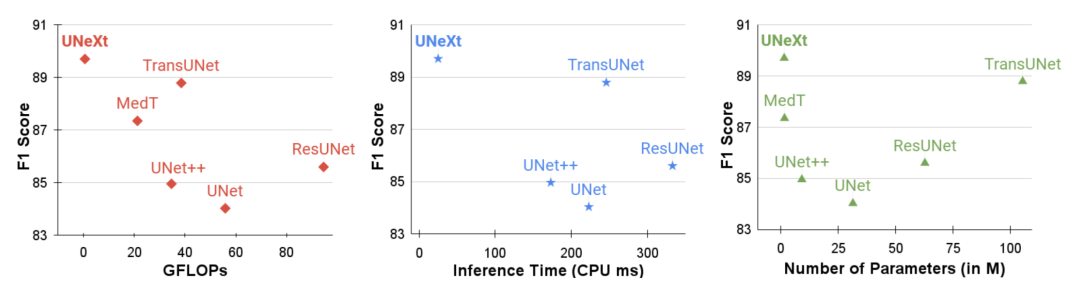
文章中提到,為了進一步提高性能,建議在輸入到 MLP 的過程中改變輸入的通道,以便專注于學習局部依賴關系特征。還有額外的設計就是跳躍連接了,并不是我們主要關注的地方。最終,UNeXt 將參數數量減少了 72 倍,計算復雜度降低了 68 倍,推理速度提高了 10 倍,同時還獲得了更好的分割性能,如下圖所示。
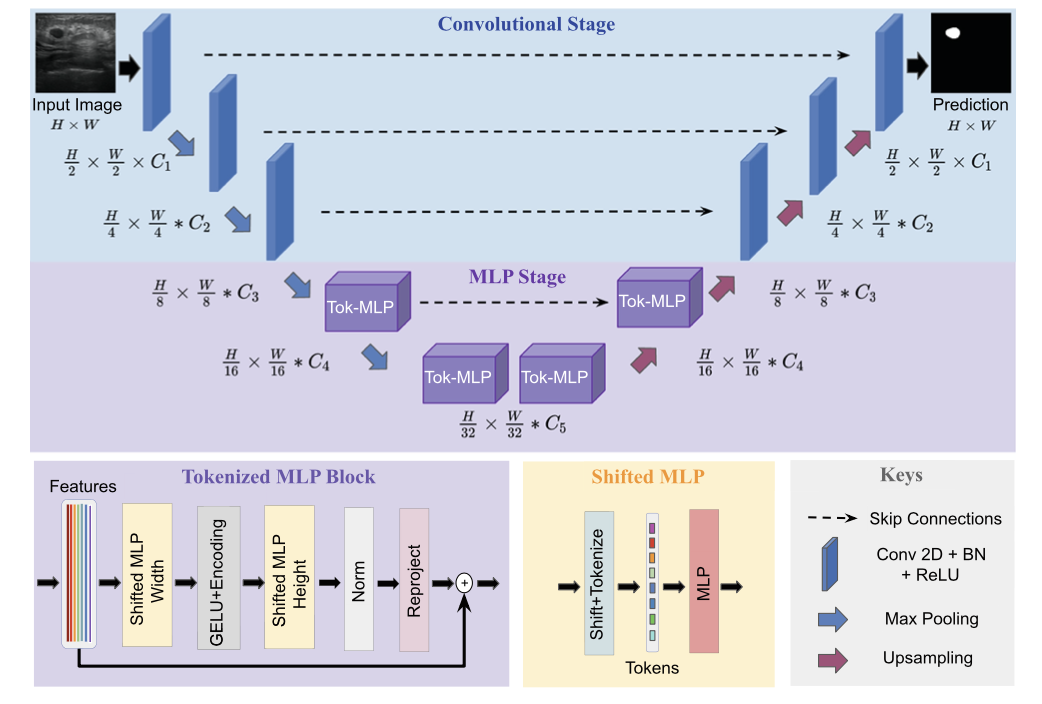
UNeXt 架構
UNeXt 的設計如下圖所示。縱向來看,一共有兩個階段,普通的卷積和 Tokenized MLP 階段。其中,編碼器和解碼器分別設計兩個 Tokenized MLP 塊。每個編碼器將分辨率降低兩倍,解碼器工作相反,還有跳躍連接結構。每個塊的通道數(C1-C5)被設計成超參數為了找到不掉點情況下最小參數量的網絡,對于使用 UNeXt 架構的實驗,遵循 C1 = 32、C2 = 64、C3 = 128、C4 = 160 和 C5 = 256。
TokMLP 設計思路
關于 Convolutional Stage 我們不做過多介紹了,在這一部分重點專注 Tokenized MLP Stage。從上一部分的圖中,可以看到 Shifted MLP 這一操作,其實思路類似于 Swin transformer,引入基于窗口的注意力機制,向全局模型中添加更多的局域性。下圖的意思是,Tokenized MLP 塊有 2 個 MLP,在一個 MLP 中跨越寬度移動特征,在另一個 MLP 中跨越高度移動特征,也就是說,特征在高度和寬度上依次移位。
論文中是這么說的:“我們將特征分成 h 個不同的分區,并根據指定的軸線將它們移到 j=5 的位置”。其實就是創建了隨機窗口,這個圖可以理解為灰色是特征塊的位置,白色是移動之后的 padding。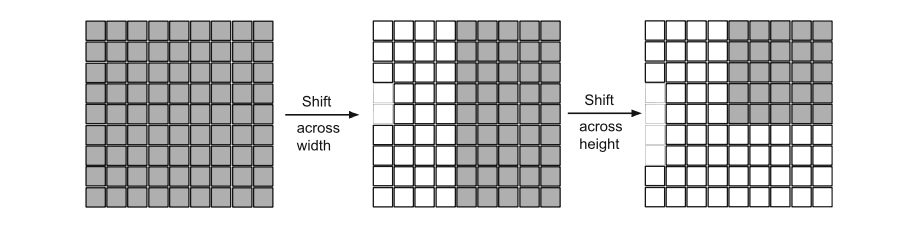
解釋過 Shifted MLP 后,我們再看另一部分:tokenized MLP block。首先,需要把特征轉換為 tokens(可以理解為 Patch Embedding 的過程)。為了實現 tokenized 化,使用 kernel size 為 3 的卷積,并將通道的數量改為 E,E 是 embadding 嵌入維度( token 的數量),也是一個超參數。然后把這些 token 送到上面提到的第一個跨越寬度的 MLP 中。
這里會產生了一個疑問,關于 kernel size 為 3 的卷積,使用的是什么樣的卷積層?答:這里還是普通的卷積,文章中提到了 DWConv(DepthWise Conv),是后面的特征通過 DW-Conv 傳遞。使用 DWConv 有兩個原因:(1)它有助于對 MLP 特征的位置信息進行編碼。MLP 塊中的卷積層足以編碼位置信息,它實際上比標準的位置編碼表現得更好。像 ViT 中的位置編碼技術,當測試和訓練的分辨率不一樣時,需要進行插值,往往會導致性能下降。(2)DWConv 使用的參數數量較少。
這時我們得到了 DW-Conv 傳遞過來的特征,然后使用 GELU 完成激活。接下來,通過另一個 MLP(跨越height)傳遞特征,該 MLP 把進一步改變了特征尺寸。在這里還使用一個殘差連接,將原始 token 添加為殘差。然后我們利用 Layer Norm(LN),將輸出特征傳遞到下一個塊。LN 比 BN 更可取,因為它是沿著 token 進行規范化,而不是在 Tokenized MLP 塊的整個批處理中進行規范化。上面這些就是一個 tokenized MLP block 的設計思路。
此外,文章中給出了 tokenized MLP block 涉及的計算公式: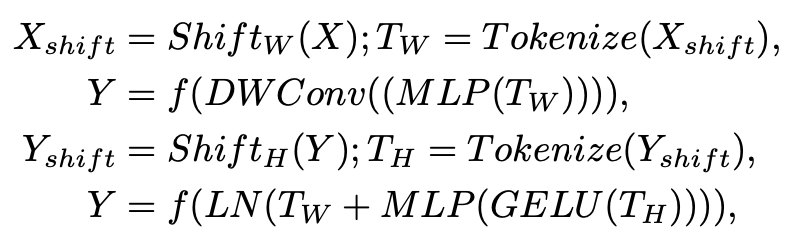
其中 T 表示 tokens,H 表示高度,W 表示寬度。值得注意的是,所有這些計算都是在 embedding 維度 H 上進行的,它明顯小于特征圖的維度 HN×HN,其中 N 取決于 block 大小。在下面的實驗部分,文章將 H 設置為 768。
實驗部分
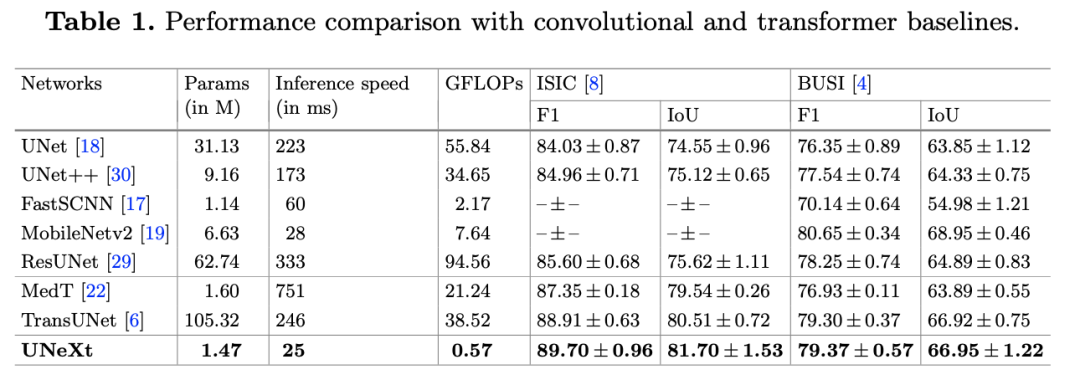
實驗在 ISIC 和 BUSI 數據集上進行,可以看到,在 GLOPs、性能和推理時間都上表現不錯。
下面是可視化和消融實驗的部分。可視化圖可以發現,UNeXt 處理的更加圓滑和接近真實標簽。
消融實驗可以發現,從原始的 UNet 開始,然后只是減少過濾器的數量,發現性能下降,但參數并沒有減少太多。接下來,僅使用 3 層深度架構,既 UNeXt 的 Conv 階段。顯著減少了參數的數量和復雜性,但性能降低了 4%。加入 tokenized MLP block 后,它顯著提高了性能,同時將復雜度和參數量是一個最小值。
接下來,我們將 DWConv 添加到 positional embedding,性能又提高了。接下來,在 MLP 中添加 Shifted 操作,表明在標記化之前移位特征可以提高性能,但是不會增加任何參數或復雜性。注意:Shifted MLP 不會增加 GLOPs。
一些理解和總結
在這項工作中,提出了一種新的深度網絡架構 UNeXt,用于醫療圖像分割,專注于參數量的減小。UNeXt 是一種基于卷積和 MLP 的架構,其中有一個初始的 Conv 階段,然后是深層空間中的 MLP。具體來說,提出了一個帶有移位 MLP 的標記化 MLP 塊。在多個數據集上驗證了 UNeXt,實現了更快的推理、更低的復雜性和更少的參數數量,同時還實現了最先進的性能。
我在讀這篇論文的時候,直接注意到了它用的數據集。我認為 UNeXt 可能只適用于這種簡單的醫學圖像分割任務,類似的有 Optic Disc and Cup Seg,對于更復雜的,比如血管,軟骨,Liver Tumor,kidney Seg 這些,可能效果達不到這么好,因為運算量被極大的減少了,每個 convolutional 階段只有一個卷積層。MLP 魔改 U-Net 也算是一個嘗試,在 Tokenized MLP block 中加入 DWConv 也是很合理的設計。
審核編輯:劉清
-
編解碼器
+關注
關注
0文章
272瀏覽量
24651 -
感知器
+關注
關注
0文章
34瀏覽量
11966 -
MLP
+關注
關注
0文章
57瀏覽量
4491
原文標題:MICCAI 2022:基于 MLP 的快速醫學圖像分割網絡 UNeXt
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
探討一下深度學習在嵌入式設備上的應用
如何使用Keras框架搭建一個小型的神經網絡多層感知器
介紹一種用于密集預測的mlp架構CycleMLP
一種改進的基于卷積神經網絡的行人檢測方法
人工智能–多層感知器基礎知識解讀
上海邏迅官網資訊:門磁感知器SG6AD系統架構方案有哪些?
解讀CV架構回歸多層感知機;自動生成模型動畫

多層感知機(MLP)的設計與實現

使用多層感知器進行機器學習






 工商網監
工商網監
評論