") 基于圖文多模態(tài)領(lǐng)域典型任務(wù)
基于圖文多模態(tài)領(lǐng)域典型任務(wù)
圖文多模態(tài)領(lǐng)域典型任務(wù)如img-text retrieval、VQA、captioning、grounding等,目前的學(xué)術(shù)設(shè)定難度尚可。但是, 一旦知識(shí)范圍擴(kuò)展,到了open-ended scenario,任務(wù)難度立刻劇增 。但是DeepMind的Flamingo模型在這些挑戰(zhàn)場(chǎng)景中使用同一個(gè)模型便做到了。當(dāng)時(shí)看到論文中的這些例子,十分驚訝!

可以看到,F(xiàn)lamingo模型不僅可以做到open-ended captioning、VQA等,甚至可以計(jì)數(shù)、算數(shù)。其中很多額外的知識(shí),比如火烈鳥(niǎo)的發(fā)源地等知識(shí),對(duì)于單模態(tài)的語(yǔ)言模型如GPT-3、T5、Chinchilla等可以說(shuō)是難度不大。
但是對(duì)于傳統(tǒng)的多模態(tài)模型而言,很難通過(guò)傳統(tǒng)的img-text pair學(xué)到如此廣闊的外部知識(shí),因?yàn)楹芏嘀R(shí)是蘊(yùn)含在基于文本的單模態(tài)中的(如維基百科) 。所以,DeepMind在多模態(tài)領(lǐng)域的發(fā)力點(diǎn)就在 站人語(yǔ)言模型的巨人肩膀上,凍住超大規(guī)模訓(xùn)練的語(yǔ)言模型,將多模態(tài)模型設(shè)計(jì)向NLP大模型靠攏。
Frozen
要介紹Flamingo模型,不得不先介紹DeepMind在NeurIPS 2021發(fā)表的前作Frozen。Frozen模型十分簡(jiǎn)單,作者使用一個(gè)預(yù)訓(xùn)練好的語(yǔ)言模型,并且完全凍結(jié)參數(shù),只訓(xùn)練visual encoder。
模型結(jié)構(gòu):其中LM模型是在C4數(shù)據(jù)上訓(xùn)練的包含7B參數(shù)的transformer結(jié)構(gòu),visual encoder是NF-ResNet50。訓(xùn)練數(shù)據(jù):訓(xùn)練時(shí)只采用了CC3M數(shù)據(jù)集,包含300萬(wàn)img-text pair,預(yù)訓(xùn)練數(shù)據(jù)量不大。Frozen框架如下。其中視覺(jué)特征可以看作是LM模型的prompt,凍結(jié)的語(yǔ)言模型就在視覺(jué)特征的“提示”下,做出應(yīng)答。
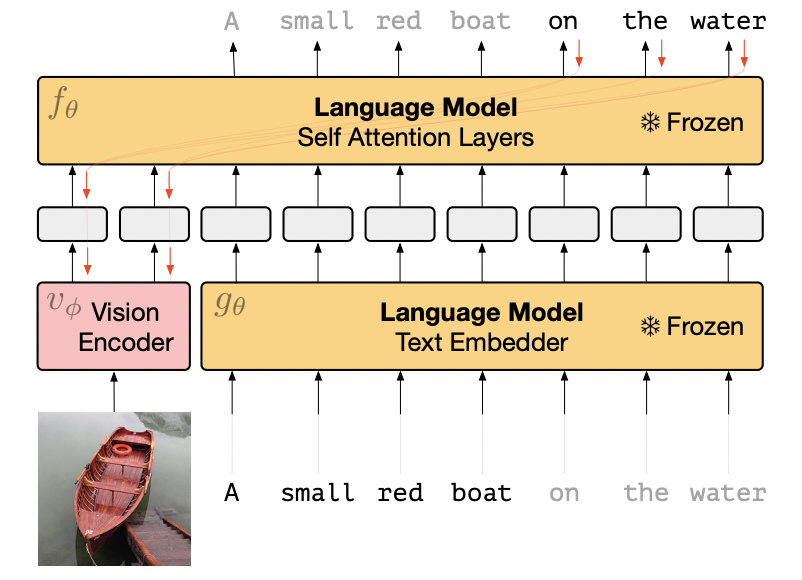
Frozen模型結(jié)構(gòu)
可以看到,通過(guò)一些img-text pair的約束,unfrozen的visual encoder是朝著frozen LM靠攏和對(duì)齊的。該算法在預(yù)訓(xùn)練時(shí)只使用了captioning語(yǔ)料CC3M,并且知識(shí)的豐富度也有限。那么,F(xiàn)rozen模型能做什么呢?
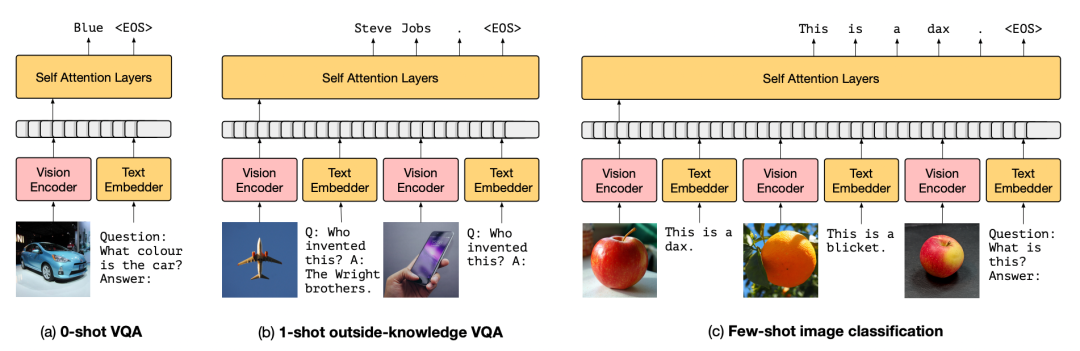
Frozen模型在下游場(chǎng)景的應(yīng)用
雖然由caption數(shù)據(jù)(CC3M)訓(xùn)練,它竟然可以做VQA甚至基于知識(shí)的VQA,比如上圖,你告訴它飛機(jī)是萊特兄弟發(fā)明的,它就能類(lèi)比出蘋(píng)果手機(jī)是喬布斯創(chuàng)造的。很顯然, 這種外部知識(shí)肯定不是CC3M中有限的img-text pair能夠給予的,無(wú)非是來(lái)源于從始至終未參與訓(xùn)練、凍結(jié)的LM模型 。接下來(lái)作者做了一系列實(shí)驗(yàn),可以看到,其實(shí)Frozen距離SOTA模型仍十分遙遠(yuǎn)。
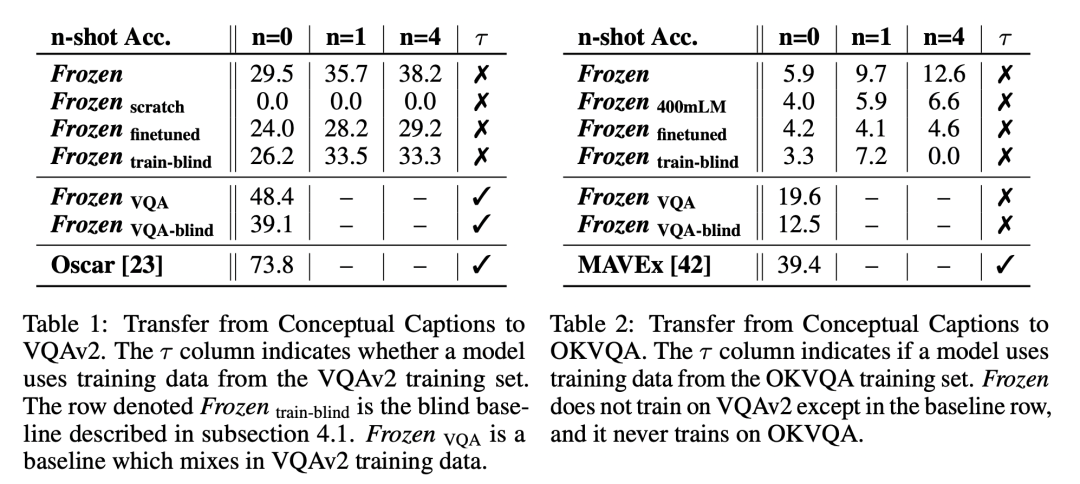
Frozen實(shí)驗(yàn)結(jié)果
可以看到,F(xiàn)rozen模型距離VQA和OKVQA數(shù)據(jù)集上的SOTA算法仍有十分巨大的gap。
幾個(gè)有意思的現(xiàn)象:
如果模型看不到圖片(blind模型),只依賴于LM模型,效果尚可,但是明顯低于看得見(jiàn)圖片的模型。 說(shuō)明Frozen確實(shí)對(duì)img-text模態(tài)進(jìn)行了對(duì)齊,學(xué)習(xí)到了如何參考圖片信息再做出應(yīng)答 ;
few-shot甚至zero-shot就可以達(dá)到還不錯(cuò)的性能;
end-to-end finetune LM模型效果會(huì)下降,說(shuō)明由大量單模態(tài)訓(xùn)練出的LM模型參數(shù)很容易被少量的img-text數(shù)據(jù)破壞掉。證明了本文觀點(diǎn),LM模型需要Frozen才能保留文本信息學(xué)到的知識(shí)!
Flamingo
介紹完了Frozen,那么DeepMind團(tuán)隊(duì)再接再厲,創(chuàng)造效果驚艷的Flamingo模型就順理成章了。相比于Frozen,F(xiàn)lamingo模型的幾點(diǎn)改進(jìn):
更強(qiáng)的LM模型: 70B參數(shù)的語(yǔ)言模型Chinchilla;
更多的可訓(xùn)練參數(shù): visual encoder這次也凍結(jié)了,但是圖片特征采樣模型可以訓(xùn)練,更重要的是LM模型的各層中也嵌入了可學(xué)習(xí)的參數(shù),可訓(xùn)練參數(shù)總量高達(dá)10B;
更恐怖的訓(xùn)練數(shù)據(jù):不僅加入了ALIGN算法的18億img-text pair,數(shù)百萬(wàn)的video-text pair。此外,還有大量的不匹配的圖文信息,來(lái)源于MultiModal MassiveWeb (M3W) dataset,其中圖片數(shù)量上億,文本大概有182 GB。可以使用unpaired img-text數(shù)據(jù)進(jìn)行訓(xùn)練也是Flamingo模型的一大亮點(diǎn)。總而言之,它的數(shù)據(jù)量十分恐怖,已經(jīng)遠(yuǎn)遠(yuǎn)超過(guò)目前業(yè)界的多模態(tài)算法比如CLIP、ALIGN、SimVLM、BLIP等。
下面看看Flamingo的模型結(jié)構(gòu):
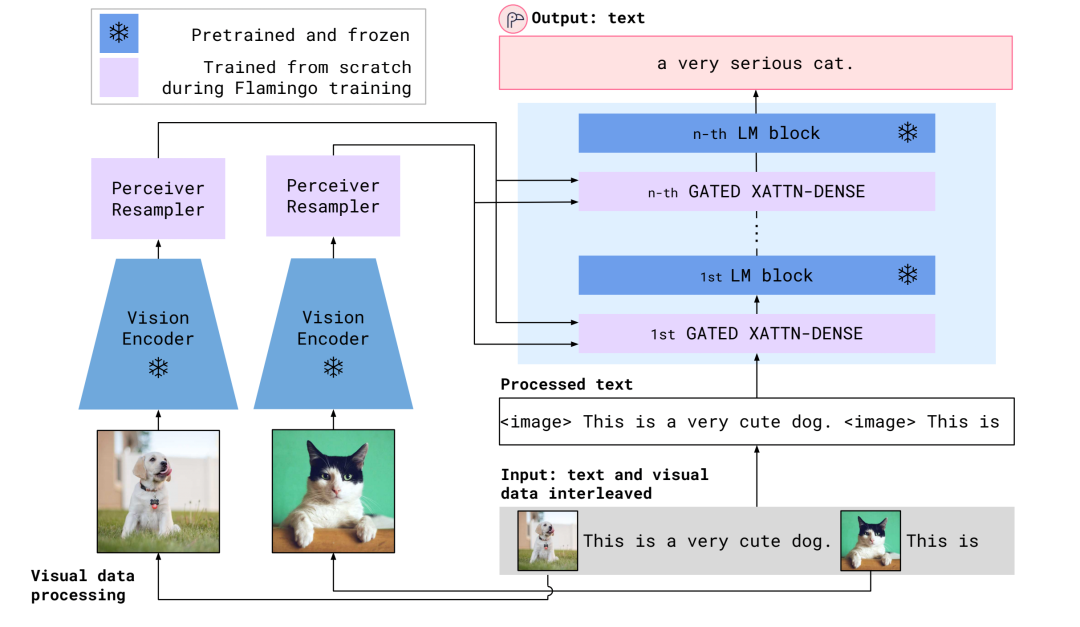
Flamingo模型結(jié)構(gòu)
可以看到, 不同于Frozen,這一次visual encoder也是凍結(jié)的。參數(shù)可以學(xué)習(xí)的就兩部分,一個(gè)是Perceiver Resampler,一個(gè)是嵌入在LM模型中的Gated Block。Perceiver Resampler結(jié)構(gòu)如下:
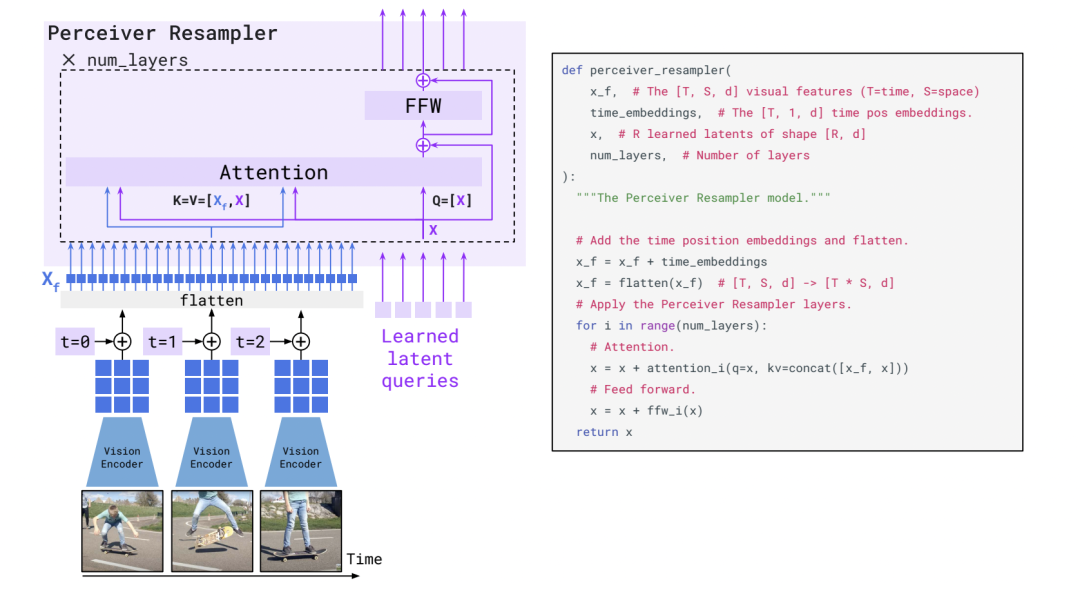
Perceiver Resampler結(jié)構(gòu)
Perceiver Resampler結(jié)構(gòu)一目了然,一些可學(xué)習(xí)的embedding作為query,然后圖片特征或者時(shí)續(xù)的視頻特征attend到query上,作為最后的輸出。
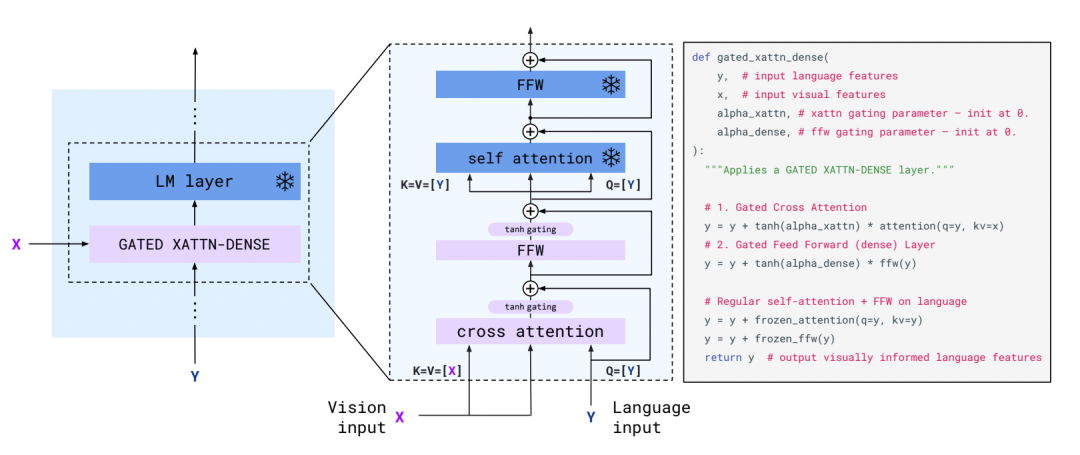
gated xattn-dense結(jié)構(gòu)
嵌入在LM模型中的gated xattn-dense的結(jié)構(gòu)同樣一目了然,使用文本信息作為query去aggregate視覺(jué)信息。其中text embedding作為query,visual embedding作為key和value。類(lèi)比于transformer結(jié)構(gòu),唯一小的差別就是cross-attention和FFN之后額外加了一個(gè)gate。
介紹完了Flamingo的模型結(jié)構(gòu),簡(jiǎn)單看看它的爆表性能吧,可以說(shuō),下游場(chǎng)景中只用few-shot的情況下做到這種程度,讓人驚訝...... 在一些答案集合固定的任務(wù)中,比如傳統(tǒng)的VQAv2中優(yōu)勢(shì)不明顯, 但是open-ended的knowledge-based VQA任務(wù)中,比如OKVQA,只用few-shot就可以刷新當(dāng)前SOTA 。 在盲人場(chǎng)景的VizWiz以及OCR信息特別多的TextVQA等任務(wù)中,效果同樣可圈可點(diǎn)。一些基于視頻的QA比如NextQA和iVQA效果同樣刷新當(dāng)前最好性能......
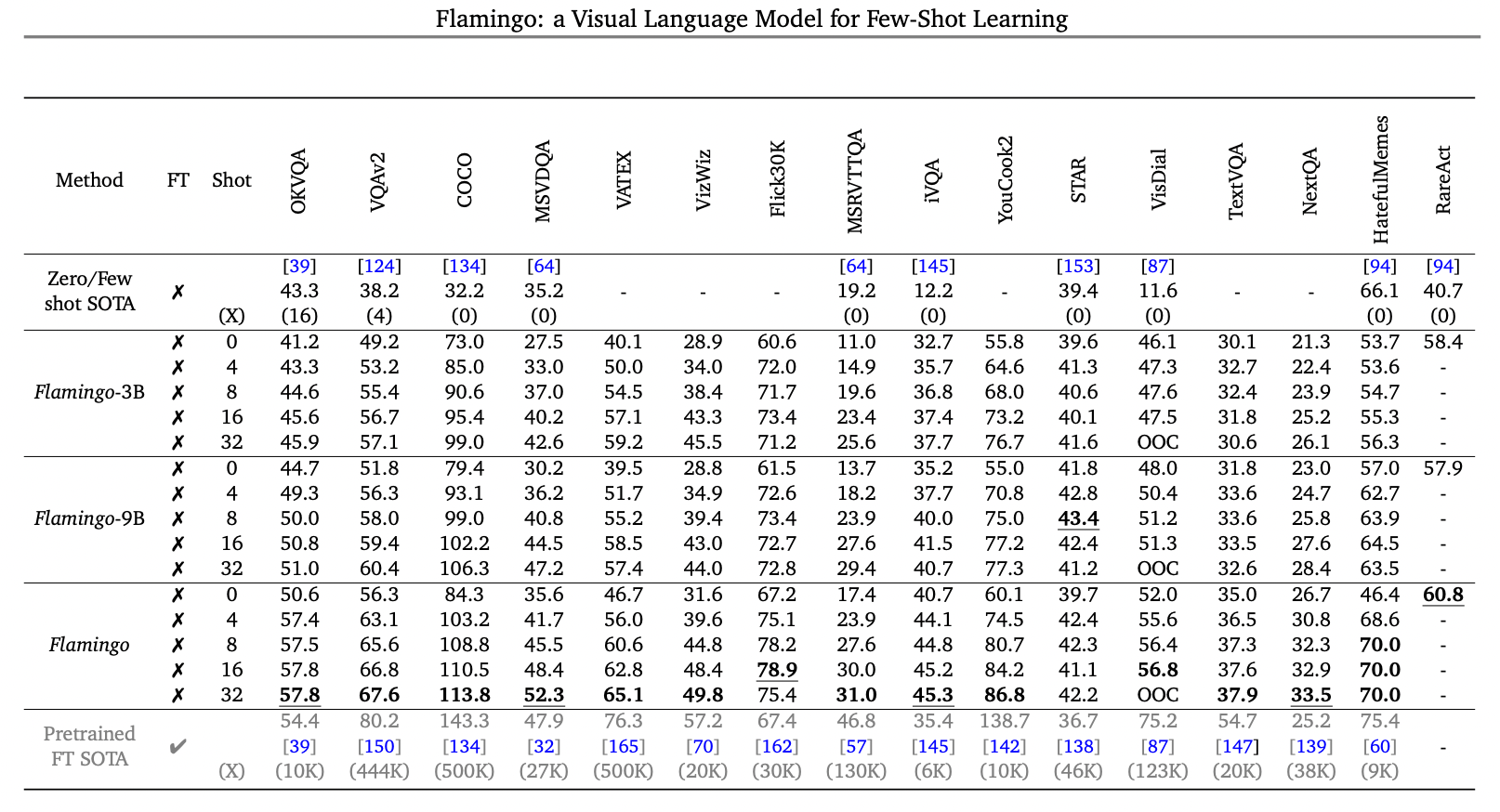
如果Flamingo不使用few-shot模式,而進(jìn)行fine-tune模式,論文中顯示,同樣可以刷新不少業(yè)界SOTA指標(biāo),這里就不列舉了。最后再列出幾個(gè)讓人驚嘆的示例結(jié)束本文,準(zhǔn)備再去好好研究一番論文細(xì)節(jié)。
多模態(tài)描述,多模態(tài)問(wèn)答,多模態(tài)對(duì)話,多模態(tài)推薦……以前很多人覺(jué)得很遙遠(yuǎn),但是近年來(lái)進(jìn)展飛速,距離實(shí)際場(chǎng)景的gap也在逐步縮小,未來(lái)可期~


-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10647 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25259 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22464
原文標(biāo)題:站在NLP巨人模型的肩膀才是多模態(tài)的未來(lái)?
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄

多文化場(chǎng)景下的多模態(tài)情感識(shí)別
如何讓Transformer在多種模態(tài)下處理不同領(lǐng)域的廣泛應(yīng)用?
簡(jiǎn)述文本與圖像領(lǐng)域的多模態(tài)學(xué)習(xí)有關(guān)問(wèn)題
如何使用多模態(tài)信息做prompt
DocumentAI的模型、任務(wù)和基準(zhǔn)數(shù)據(jù)集
一個(gè)真實(shí)閑聊多模態(tài)數(shù)據(jù)集TikTalk
中文多模態(tài)對(duì)話數(shù)據(jù)集
如何利用LLM做多模態(tài)任務(wù)?
更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開(kāi)源,在多模態(tài)序列中「補(bǔ)全一切」

基于視覺(jué)的多模態(tài)觸覺(jué)感知系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論