") 對(duì)比兩個(gè)基于Redis下的存儲(chǔ)方案在性能方面的優(yōu)劣
對(duì)比兩個(gè)基于Redis下的存儲(chǔ)方案在性能方面的優(yōu)劣
現(xiàn)代的開(kāi)發(fā)語(yǔ)言除了C++以外,大部分都對(duì)內(nèi)存管理做好了封裝,一般的開(kāi)發(fā)者根本都接觸不到內(nèi)存的底層操作。更何況現(xiàn)在各種優(yōu)秀的開(kāi)源組件應(yīng)用越來(lái)越多,例如mysql、redis等,這些甚至都不需要大家動(dòng)手開(kāi)發(fā),直接拿來(lái)用就好了。所以有些同學(xué)也會(huì)覺(jué)得作為應(yīng)用層開(kāi)發(fā)的同學(xué)沒(méi)有學(xué)習(xí)的必要去學(xué)習(xí)底層。
但我想通過(guò)本文的實(shí)際案例告訴大家,哪怕不直接接觸內(nèi)存底層操作,就只是用一些開(kāi)源的工具,如果你能理解底層的工作原理,你也能夠用到極致。
1 用于訪問(wèn)歷史存儲(chǔ)需求
假如現(xiàn)在有這樣一個(gè)業(yè)務(wù)需求,用戶(hù)每次刷新都需要獲得要消費(fèi)的新數(shù)據(jù),但是不能和之前訪問(wèn)過(guò)的歷史重復(fù)。你可以把它和你經(jīng)常在用的今日頭條之類(lèi)的信息流app聯(lián)系起來(lái)。每次都要看到新的新聞,但是你肯定不想看到過(guò)去已經(jīng)看過(guò)的文章。這樣在功能實(shí)現(xiàn)的時(shí)候,就必要保存用戶(hù)的訪問(wèn)歷史。當(dāng)用戶(hù)再來(lái)刷新的時(shí)候,首先得獲取用戶(hù)的歷史記錄,要保證推給用戶(hù)的數(shù)據(jù)和之前的不重復(fù)。當(dāng)推薦完成的時(shí)候,也需要把這次新推薦過(guò)的數(shù)據(jù)id記錄到歷史里。
為了適當(dāng)降低實(shí)現(xiàn)復(fù)雜度,我們可以規(guī)定每個(gè)用戶(hù)只要不和過(guò)去的一萬(wàn)條記錄重復(fù)就可以了。這樣每個(gè)用戶(hù)最多只需要保存一萬(wàn)條歷史id,如果存滿(mǎn)了就把最早的歷史記錄擠掉。我們進(jìn)一步具體化一下這個(gè)需求的幾個(gè)關(guān)鍵點(diǎn):
每個(gè)數(shù)據(jù)id是一個(gè)int整數(shù)來(lái)表示
每個(gè)用戶(hù)要保存1萬(wàn)條id
每次用戶(hù)刷新開(kāi)始的時(shí)候需要將這1萬(wàn)條歷史全部讀取出來(lái)過(guò)濾一遍
每次用戶(hù)刷新結(jié)束的時(shí)候需要將新訪問(wèn)過(guò)的10條寫(xiě)入一遍,如果超過(guò)1萬(wàn)需將最早的記錄擠掉
可見(jiàn),每次用戶(hù)訪問(wèn)的時(shí)候,會(huì)涉及到一個(gè)1萬(wàn)規(guī)模的數(shù)據(jù)集上的一次讀取和一次寫(xiě)入操作。好了,需求描述完了,我們?cè)趺礃舆M(jìn)行我們的技術(shù)方案的設(shè)計(jì)呢?相信你也能想到很多實(shí)現(xiàn)方案,我們今天來(lái)對(duì)比兩個(gè)基于Redis下的存儲(chǔ)方案在性能方面的優(yōu)劣。
2 Redis方案一:用list存儲(chǔ)
首先能想到的第一個(gè)辦法就是用Redis的List來(lái)保存。因?yàn)檫@個(gè)數(shù)據(jù)結(jié)構(gòu)設(shè)計(jì)的太適合上面的場(chǎng)景了。List下的lrange命令可以實(shí)現(xiàn)一次性讀取用戶(hù)的所有數(shù)據(jù)id的需求。
$redis->lrange('TEST_KEY', 0,9999);
lpush命令可以實(shí)現(xiàn)新的數(shù)據(jù)id的寫(xiě)入,ltrim可以保證將用戶(hù)的記錄數(shù)量不超過(guò)1萬(wàn)條。

我們準(zhǔn)備一個(gè)用戶(hù),提前存好一萬(wàn)條id。寫(xiě)入的時(shí)候每次只寫(xiě)入10條新的id,讀取的時(shí)候通過(guò)lrange一次全部讀取出來(lái)。進(jìn)行一下性能耗時(shí)測(cè)試,結(jié)果如下。

3 Redis方案二:用string存儲(chǔ)
我能想到的另外一個(gè)技術(shù)方案就是直接用String來(lái)存。我們可以把1萬(wàn)個(gè)int表示的數(shù)據(jù)id拼接成一個(gè)字符串,用一個(gè)特殊的字符把他們分割開(kāi)。例如:"100000_100001_10002"這種。存儲(chǔ)的時(shí)候,拼接一下,然后把這個(gè)大字符串寫(xiě)到Redis里。讀取的時(shí)候,把大字符串整體讀取出來(lái),然后再用字符切割成數(shù)組來(lái)使用。
由于用string存儲(chǔ)的時(shí)候,保存前多了一個(gè)拼接字符串的操作,讀取后多了一步將字符串分割成數(shù)組的操作。在測(cè)試string方案的時(shí)候,為了公平起見(jiàn),我們把需要把這兩步的開(kāi)銷(xiāo)也考慮進(jìn)來(lái)。核心代碼如下:

耗時(shí)測(cè)試結(jié)果如下

4 結(jié)論
我們?cè)僦庇^對(duì)比下兩個(gè)技術(shù)方案的性能數(shù)據(jù)。
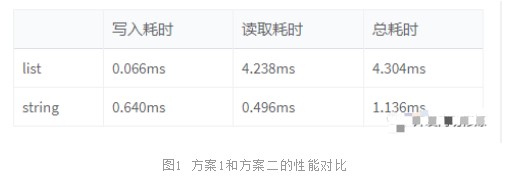
基于list的方案里,寫(xiě)入速度非常快,只需要0.066ms,因?yàn)閮H僅只需要寫(xiě)入新添加的10條記錄就可以了,再加一次鏈表的截?cái)嗖僮鳎亲x取性能可就要慢很多了,超過(guò)了4ms。原因之一是因?yàn)樽x取需要整體遍歷,但其實(shí)還有第二個(gè)原因。我們本案例中的數(shù)據(jù)量過(guò)大,所以Redis在內(nèi)部實(shí)際上是用雙端鏈表來(lái)實(shí)現(xiàn)的。
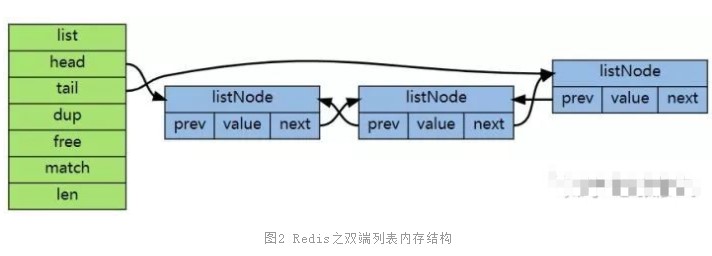
通過(guò)上圖你可能看出來(lái),鏈表是通過(guò)指針串起來(lái)的。大量的node之間極大可能是隨機(jī)地分布在內(nèi)存的各個(gè)位置上,這樣你遍歷整個(gè)鏈表的時(shí)候,實(shí)際上大概率會(huì)導(dǎo)致內(nèi)存的隨機(jī)模式下工作。
基于string方案在寫(xiě)入的時(shí)候耗時(shí)比list要高,因?yàn)槊看味嫉眯枰獙?萬(wàn)條全部寫(xiě)入一遍。但是讀取性能卻比list高了10倍,總體上耗時(shí)加起來(lái)大約只有方案一的1/4左右。為什么?我們?cè)賮?lái)看下redis string數(shù)據(jù)結(jié)構(gòu)的內(nèi)存布局
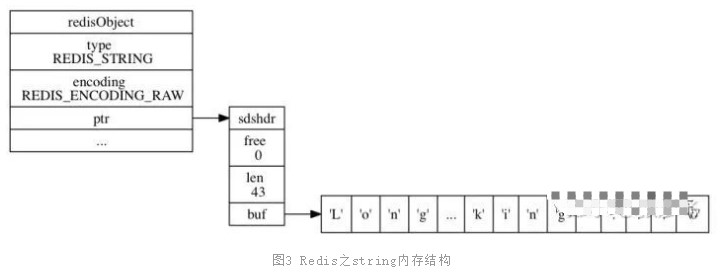
可見(jiàn),如果用string來(lái)存儲(chǔ)的話,不管用戶(hù)的數(shù)據(jù)id有多少,訪問(wèn)將全部都是順序IO。順序IO的好處有兩點(diǎn):
1. 一內(nèi)存的順序IO的耗時(shí)大約只是隨機(jī)IO的1/3-1/4左右,
2. 對(duì)于讀取來(lái)說(shuō),順序訪問(wèn)將極大地提升CPU的L1、L2、L3的cache命中率
所以如果你深入了內(nèi)存的工作原理,哪怕你不能直接去操作內(nèi)存,即使只是用一些開(kāi)源的軟件,你也能夠?qū)⑺男阅馨l(fā)揮到極致~
審核編輯:劉清
-
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7634瀏覽量
166399 -
字符串
+關(guān)注
關(guān)注
1文章
589瀏覽量
21106 -
Redis
+關(guān)注
關(guān)注
0文章
384瀏覽量
11316
發(fā)布評(píng)論請(qǐng)先 登錄
【幸狐Omni3576邊緣計(jì)算套件試用體驗(yàn)】Redis最新8.0.2版本源碼安裝及性能測(cè)試
redis三種集群方案詳解
石墨膜和銅VC散熱性能和應(yīng)用方面的區(qū)別

DLP4710和DLP4710LC,在兩個(gè)套件中的DMD是不是一樣的呢?
Redis實(shí)戰(zhàn)筆記

華為云Flexus X實(shí)例,Redis性能加速評(píng)測(cè)及對(duì)比
Redis使用重要的兩個(gè)機(jī)制:Reids持久化和主從復(fù)制

Redis緩存與Memcached的比較
ad如何設(shè)置兩個(gè)元器件的距離
使用ADS8691有兩個(gè)參數(shù)方面的疑問(wèn)求解
雙穩(wěn)態(tài)電路的兩個(gè)穩(wěn)定狀態(tài)是什么
雙穩(wěn)態(tài)觸發(fā)器的兩個(gè)基本性質(zhì)是什么
可以在單個(gè)esp8266上安裝兩個(gè)NON OS SDK應(yīng)用程序嗎?
紅外熱成像與微光夜視優(yōu)劣勢(shì)對(duì)比






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論