 談一談浮點數的精度問題
談一談浮點數的精度問題
最近進行代碼的review過程中看到同事在代碼中直接拿浮點數相等來作為條件,其他同事提醒他的時候,他還迷迷糊糊不知道為什么,所以就有了今天這篇文章。
1、浮點數據的不均勻
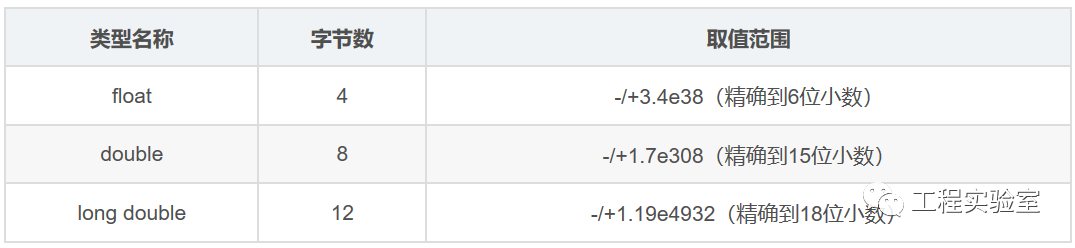
我們經常會談到浮點數的精度問題,float-單精度,double-雙精度,double類型相比float類型精度更高,相應的需要的內存字節個數也越多,談到精度的問題,其實也就說明這種數據類型并不能夠連續的標識任何的點,整形數就不用說了,小數部分直接不能標識。
毒王這篇文章基本上可以從浮點數的存儲到表意來較好的認識浮點數數據類型,但是中間部分對于浮點數精度部分的介紹并不是很形象,所以今天再詳細一點說明一下。
首先我們要認識到通常float類型的變量占據四個字節,而uint32_t的整形類型也是占據四個字節,既然都是四個字節,那他們所能表示的不同數據個數是一樣的。
如果不太理解,可以把float看成4個bit,uint32_t也是4個bit,那么他們不管經過什么變換,每個數據類型都只能夠標識16個數。
好,如下圖以4字節float的數據存儲模型所示:

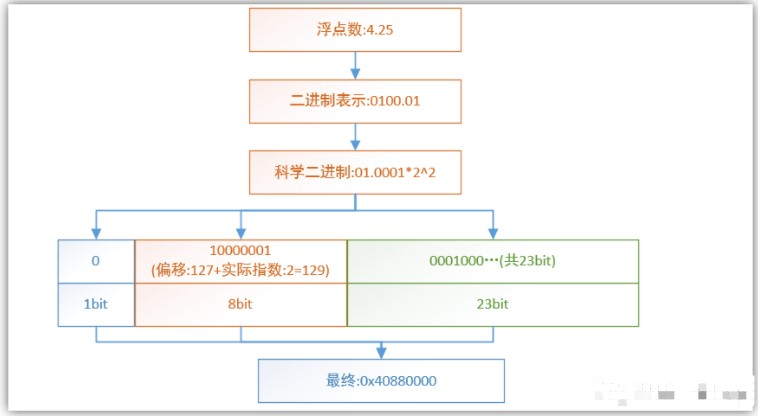
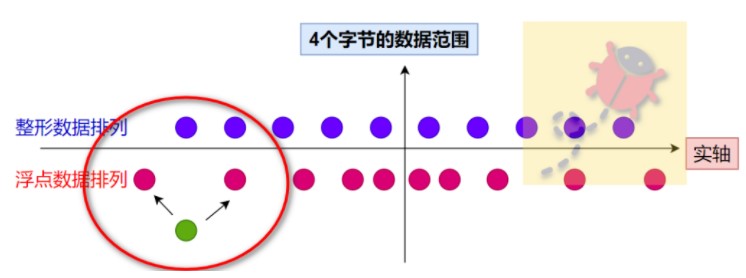
4個字節的浮點數,不像無符號整形所有的bit都是數據區,并且以每個數據之間相差1均勻分布,而浮點數把這4個字節分為了不同的區來起到不同的作用,從而用另外一種方式表達數據。
其指數部分越大,表示的數據就越大,但是尾數部分只能表示到23位,這樣的話導致數據的精度就越差,如果不太理解可以用一個較大的數通過上面的轉換方式進行換算,便能理解。
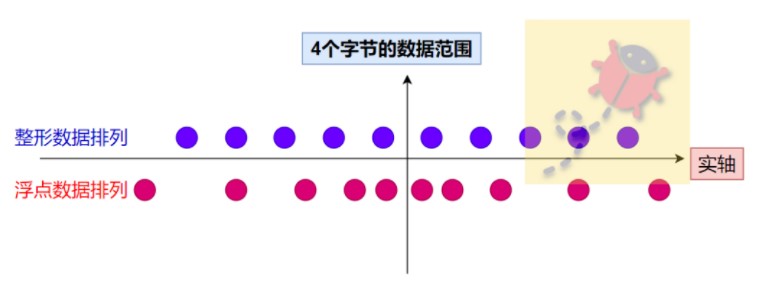
所以同樣是4個字節,根據浮點數的表示,越接近0就越稠密,越遠離0就越稀疏,呈現一種不均勻的數據排列狀態,如上圖所示,同樣它也也不能標識實軸上任意的點。
2、驗證一下不均勻
好了,講了這么多理論,多多少少得來點程序驗證一下:
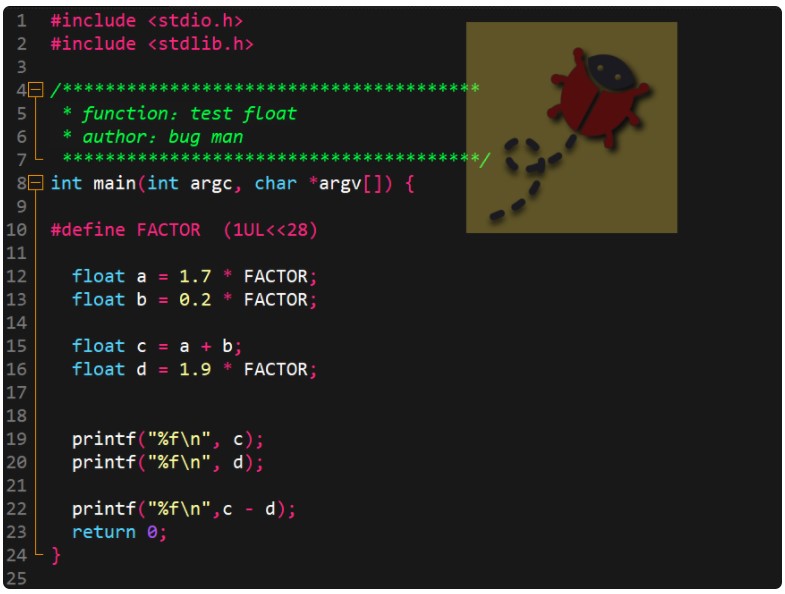
看看上面的代碼,這還用說,肯定這兩個數相等呀,相減也等于0,然而看一下輸出結果:

結果并不相等,并且相差還不少。
其結果也就說明了浮點數在大數的標識精度不好,只能近似標識,同時也說明了為什么一般不使用浮點數相等來進行判斷的原因。
這也是為什么有時候明明我們采用直接編碼用準確的浮點數,到了浮點數變量里面卻損失了精度,因為4個字節的float標識不了,只能近似處理。
3、非要判斷相等
由于有些應用非要使用浮點數進行相等的處理,我們不應該直接使用浮點數進行等于號的判斷,而是要在一定的誤差和精度范圍內進行滿足。
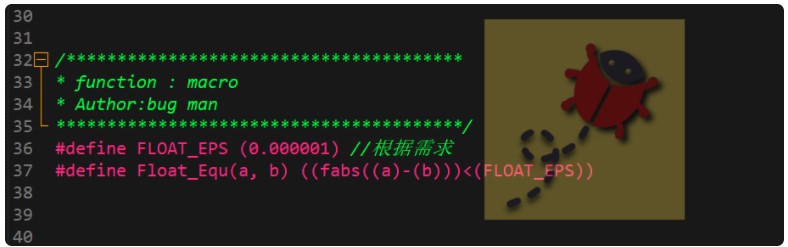
如上圖所示代碼是比較常用的處理辦法,在往期的文章中,bug菌沒有詳細的講解這個誤差宏的定義,前面了解到當數據比較大的時候相鄰的差值會比較大,這樣就存在兩個浮點數的差值大于所設置的誤差范圍而無法判斷相等。
所以這樣的處理辦法來判斷浮點數近似相等會存在一些局限性。
那有沒有相對更好一點的辦法呢?
當然是有的,不然接下來沒得寫了。
還是要從浮點數的存儲和標識出發來處理該問題,既然浮點數天然就存在一定的誤差,而有時候計算又無法獲得唯一的數值,如下圖所示,浮點數計算出來的實軸上的值都會因為浮點數無法存儲標識而近似到其相鄰的可以標識的數值上。
從浮點的存儲模型來看,指數部分代表著浮點數的范圍,尾數部分代表著浮點數的精度,那么尾數的最后一位其實就表示了浮點數的當前數值附近的精度。
于是對浮點的近似相等進行了算法上的修改,如下代碼所示:
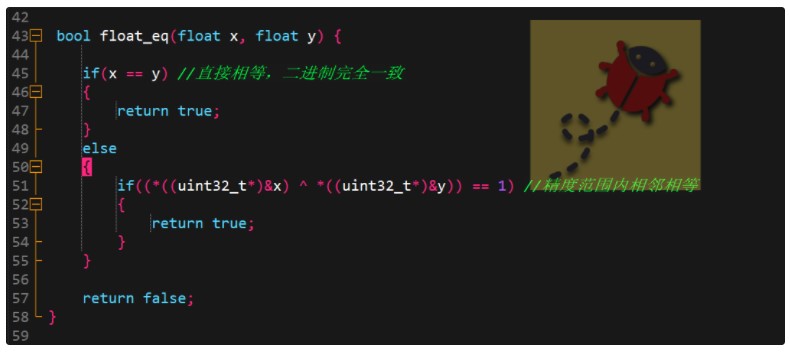
解釋一下 :
如果直接相等,說明浮點數各數據位都相等;而如果不相等可能相鄰,于是強制轉化為整形,比較尾數最后一位是否不同。
這里使用一個小技巧,采用異或的處理辦法,如果其他位都相同,而最后一位不同,結果就等于1,認為兩個浮點數近似相等。
本文到此結束,我相信大家應該對浮點數有了一個更加深入的了解,面對一些問題心中也會有一些答案,比如浮點數為什么不能作為switch的參數,也是同樣的原因。
但總的來說還是建議大家不要判斷浮點數相等,非要用也要特別小心。
審核編輯:劉清
-
Switch
+關注
關注
1文章
535瀏覽量
59254 -
數據存儲
+關注
關注
5文章
997瀏覽量
51608 -
浮點數
+關注
關注
0文章
61瀏覽量
16074
發布評論請先 登錄
官方例程modbus slave rtu,浮點數精度不對是怎么回事?
浮點數的表示方法


什么是浮點數
定點數和浮點數的概念 浮點數二進制序列與指數表達式之間的轉化
modbus浮點數怎么讀取
一文帶你秒懂IEEE 754浮點數






 工商網監
工商網監
評論