 RabbitMQ的多種交換機類型
RabbitMQ的多種交換機類型
RabbitMQ
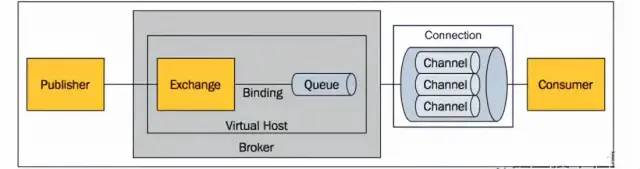
RabbitMQ各組件的功能
Broker :一個RabbitMQ實例就是一個Broker
Virtual Host :虛擬主機。相當于MySQL的DataBase,一個Broker上可以存在多個vhost,vhost之間相互隔離。每個vhost都擁有自己的隊列、交換機、綁定和權限機制。vhost必須在連接時指定,默認的vhost是/。
Exchange :交換機,用來接收生產者發送的消息并將這些消息路由給服務器中的隊列。
Queue :消息隊列,用來保存消息直到發送給消費者。它是消息的容器。一個消息可投入一個或多個隊列。
Banding :綁定關系,用于消息隊列和交換機之間的關聯。通過路由鍵(Routing Key)將交換機和消息隊列關聯起來。
Channel :管道,一條雙向數據流通道。不管是發布消息、訂閱隊列還是接收消息,這些動作都是通過管道完成。因為對于操作系統來說,建立和銷毀TCP都是非常昂貴的開銷,所以引入了管道的概念,以復用一條TCP連接。
Connection :生產者/消費者 與broker之間的TCP連接。
Publisher :消息的生產者。
Consumer :消息的消費者。
Message :消息,它是由消息頭和消息體組成。消息頭則包括Routing-Key、Priority(優先級)等。
RabbitMQ的多種交換機類型
Exchange 分發消息給 Queue 時, Exchange 的類型對應不同的分發策略,有3種類型的 Exchange :Direct、Fanout、Topic。
Direct:消息中的 Routing Key 如果和 Binding 中的 Routing Key 完全一致, Exchange 就會將消息分發到對應的隊列中。
Fanout:每個發到 Fanout 類型交換機的消息都會分發到所有綁定的隊列上去。Fanout交換機沒有 Routing Key 。它在三種類型的交換機中轉發消息是最快的。
Topic:Topic交換機通過模式匹配分配消息,將 Routing Key 和某個模式進行匹配。它只能識別兩個通配符:"#"和"*"。### 匹配0個或多個單詞, * 匹配1個單詞。
TTL
TTL(Time To Live):生存時間。RabbitMQ支持消息的過期時間,一共2種。
在消息發送時進行指定。通過配置消息體的 Properties ,可以指定當前消息的過期時間。
在創建Exchange時指定。從進入消息隊列開始計算,只要超過了隊列的超時時間配置,那么消息會自動清除。
生產者的消息確認機制
Confirm機制:
消息的確認,是指生產者投遞消息后,如果Broker收到消息,則會給我們生產者一個應答。
生產者進行接受應答,用來確認這條消息是否正常的發送到了Broker,這種方式也是消息的可靠性投遞的核心保障!
如何實現Confirm確認消息?
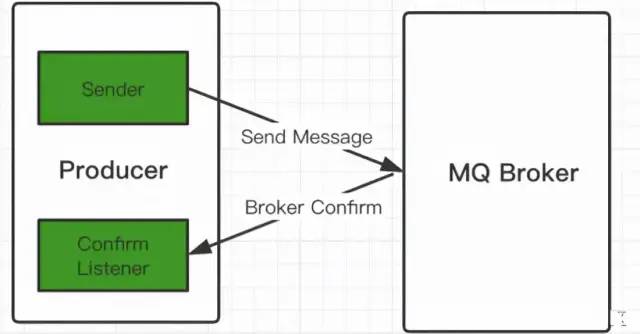
在channel上開啟確認模式:channel.confirmSelect()
在channel上開啟監聽:addConfirmListener ,監聽成功和失敗的處理結果,根據具體的結果對消息進行重新發送或記錄日志處理等后續操作。
Return消息機制:
Return Listener用于處理一些不可路由的消息。
我們的消息生產者,通過指定一個Exchange和Routing,把消息送達到某一個隊列中去,然后我們的消費者監聽隊列進行消息的消費處理操作。
但是在某些情況下,如果我們在發送消息的時候,當前的exchange不存在或者指定的路由key路由不到,這個時候我們需要監聽這種不可達消息,就需要使用到Returrn Listener。
基礎API中有個關鍵的配置項 Mandatory :如果為true,監聽器會收到路由不可達的消息,然后進行處理。如果為false,broker端會自動刪除該消息。
同樣,通過監聽的方式, chennel.addReturnListener(ReturnListener rl) 傳入已經重寫過handleReturn方法的ReturnListener。
消費端ACK與NACK
消費端進行消費的時候,如果由于業務異常可以進行日志的記錄,然后進行補償。但是對于服務器宕機等嚴重問題,我們需要手動ACK保障消費端消費成功。
// deliveryTag:消息在mq中的唯一標識 // multiple:是否批量(和qos設置類似的參數) // requeue:是否需要重回隊列。或者丟棄或者重回隊首再次消費。 publicvoidbasicNack(longdeliveryTag,booleanmultiple,booleanrequeue)
如上代碼,消息在消費端重回隊列是為了對沒有成功處理消息,把消息重新返回到Broker。一般來說,實際應用中都會關閉重回隊列(避免進入死循環),也就是設置為false。
死信隊列DLX
死信隊列(DLX Dead-Letter-Exchange):當消息在一個隊列中變成死信之后,它會被重新推送到另一個隊列,這個隊列就是死信隊列。
DLX也是一個正常的Exchange,和一般的Exchange沒有區別,它能在任何的隊列上被指定,實際上就是設置某個隊列的屬性。
當這個隊列中有死信時,RabbitMQ就會自動的將這個消息重新發布到設置的Exchange上去,進而被路由到另一個隊列。
RocketMQ
阿里巴巴雙十一官方指定消息產品,支撐阿里巴巴集團所有的消息服務,歷經十余年高可用與高可靠的嚴苛考驗,是阿里巴巴交易鏈路的核心產品。
Rocket:火箭的意思。
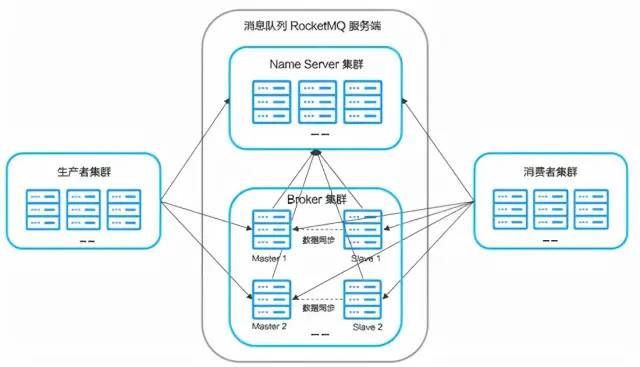 RocketMQ的核心概念
RocketMQ的核心概念
他有以下核心概念:Broker 、 Topic 、 Tag 、 MessageQueue 、 NameServer 、 Group 、 Offset 、 Producer 以及 Consumer 。
下面來詳細介紹。
Broker:消息中轉角色,負責存儲消息,轉發消息。Broker是具體提供業務的服務器,單個Broker節點與所有的NameServer節點保持長連接及心跳,并會定時將Topic信息注冊到NameServer,順帶一提底層的通信和連接都是基于Netty實現的。Broker負責消息存儲,以Topic為緯度支持輕量級的隊列,單機可以支撐上萬隊列規模,支持消息推拉模型。官網上有數據顯示:具有上億級消息堆積能力,同時可嚴格保證消息的有序性。
Topic:主題!它是消息的第一級類型。比如一個電商系統可以分為:交易消息、物流消息等,一條消息必須有一個 Topic 。Topic與生產者和消費者的關系非常松散,一個 Topic 可以有0個、1個、多個生產者向其發送消息,一個生產者也可以同時向不同的 Topic 發送消息。一個 Topic 也可以被 0個、1個、多個消費者訂閱。
Tag:標簽!可以看作子主題,它是消息的第二級類型,用于為用戶提供額外的靈活性。使用標簽,同一業務模塊不同目的的消息就可以用相同Topic而不同的Tag來標識。比如交易消息又可以分為:交易創建消息、交易完成消息等,一條消息可以沒有Tag。標簽有助于保持您的代碼干凈和連貫,并且還可以為RabbitMQ提供的查詢系統提供幫助。
MessageQueue:一個Topic下可以設置多個消息隊列,發送消息時執行該消息的Topic,RocketMQ會輪詢該Topic下的所有隊列將消息發出去。消息的物理管理單位。一個Topic下可以有多個Queue,Queue的引入使得消息的存儲可以分布式集群化,具有了水平擴展能力。
NameServer:類似Kafka中的ZooKeeper,但NameServer集群之間是沒有通信的,相對ZK來說更加輕量。它主要負責對于源數據的管理,包括了對于Topic和路由信息的管理。每個Broker在啟動的時候會到NameServer注冊,Producer在發送消息前會根據Topic去NameServer獲取對應Broker的路由信息,Consumer也會定時獲取 Topic 的路由信息。
Producer:生產者,支持三種方式發送消息:同步、異步和單向單向發送 :消息發出去后,可以繼續發送下一條消息或執行業務代碼,不等待服務器回應,且沒有回調函數。異步發送 :消息發出去后,可以繼續發送下一條消息或執行業務代碼,不等待服務器回應,有回調函數。同步發送 :消息發出去后,等待服務器響應成功或失敗,才能繼續后面的操作。
Consumer:消費者,支持 PUSH 和 PULL 兩種消費模式,支持集群消費和廣播消費集群消費 :該模式下一個消費者集群共同消費一個主題的多個隊列,一個隊列只會被一個消費者消費,如果某個消費者掛掉,分組內其它消費者會接替掛掉的消費者繼續消費。廣播消費 :會發給消費者組中的每一個消費者進行消費。相當于RabbitMQ的發布訂閱模式。
Group:分組,一個組可以訂閱多個Topic。分為ProducerGroup,ConsumerGroup,代表某一類的生產者和消費者,一般來說同一個服務可以作為Group,同一個Group一般來說發送和消費的消息都是一樣的
Offset:在RocketMQ中,所有消息隊列都是持久化,長度無限的數據結構,所謂長度無限是指隊列中的每個存儲單元都是定長,訪問其中的存儲單元使用Offset來訪問,Offset為Java Long類型,64位,理論上在 100年內不會溢出,所以認為是長度無限。也可以認為Message Queue是一個長度無限的數組,Offset就是下標。
延時消息
開源版的RocketMQ不支持任意時間精度,僅支持特定的level,例如定時5s,10s,1min等。其中,level=0級表示不延時,level=1表示1級延時,level=2表示2級延時,以此類推。
延時等級如下:
messageDelayLevel=1s5s10s30s1m2m3m4m5m6m7m8m9m10m20m30m1h2h
順序消息
消息有序指的是可以按照消息的發送順序來消費(FIFO)。RocketMQ可以嚴格的保證消息有序,可以分為 分區有序 或者 全局有序 。
事務消息
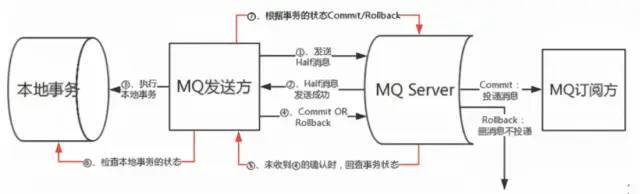
消息隊列MQ提供類似X/Open XA的分布式事務功能,通過消息隊列MQ事務消息能達到分布式事務的最終一致。上圖說明了事務消息的大致流程:正常事務消息的發送和提交、事務消息的補償流程。另外,搜索公眾號前端技術精選后臺回復“前端”,獲取一份驚喜禮包。
事務消息發送及提交:
發送half消息
服務端響應消息寫入結果
根據發送結果執行本地事務(如果寫入失敗,此時half消息對業務不可見,本地邏輯不執行);
根據本地事務狀態執行Commit或Rollback(Commit操作生成消息索引,消息對消費者可見)。
事務消息的補償流程:
對沒有Commit/Rollback的事務消息(pending狀態的消息),從服務端發起一次“回查”;
Producer收到回查消息,檢查回查消息對應的本地事務的狀態。
根據本地事務狀態,重新Commit或RollBack
其中,補償階段用于解決消息Commit或Rollback發生超時或者失敗的情況。
事務消息狀態:
事務消息共有三種狀態:提交狀態、回滾狀態、中間狀態:
TransactionStatus.CommitTransaction:提交事務,它允許消費者消費此消息。
TransactionStatus.RollbackTransaction:回滾事務,它代表該消息將被刪除,不允許被消費。
TransactionStatus.Unkonwn:中間狀態,它代表需要檢查消息隊列來確定消息狀態。
RocketMQ的高可用機制
RocketMQ是天生支持分布式的,可以配置主從以及水平擴展。
Master角色的Broker支持讀和寫,Slave角色的Broker僅支持讀,也就是 Producer只能和Master角色的Broker連接寫入消息;Consumer可以連接 Master角色的Broker,也可以連接Slave角色的Broker來讀取消息。
消息消費的高可用(主從):
在Consumer的配置文件中,并不需要設置是從Master讀還是從Slave讀,當Master不可用或者繁忙的時候,Consumer會被自動切換到從Slave讀。有了自動切換Consumer這種機制,當一個Master角色的機器出現故障后,Consumer仍然可以從Slave讀取消息,不影響Consumer程序。這就達到了消費端的高可用性。RocketMQ目前還不支持把Slave自動轉成Master,如果機器資源不足,需要把Slave轉成Master,則要手動停止Slave角色的Broker,更改配置文件,用新的配置文件啟動Broker。
消息發送高可用(配置多個主節點):
在創建Topic的時候,把Topic的多個Message Queue創建在多個Broker組上(相同Broker名稱,不同 brokerId的機器組成一個Broker組),這樣當一個Broker組的Master不可用后,其他組的Master仍然可用,Producer仍然可以發送消息。
主從復制:
如果一個Broker組有Master和Slave,消息需要從Master復制到Slave 上,有同步和異步兩種復制方式。
同步復制:同步復制方式是等Master和Slave均寫成功后才反饋給客戶端寫成功狀態。如果Master出故障, Slave上有全部的備份數據,容易恢復同步復制會增大數據寫入延遲,降低系統吞吐量。
異步復制:異步復制方式是只要Master寫成功 即可反饋給客戶端寫成功狀態。在異步復制方式下,系統擁有較低的延遲和較高的吞吐量,但是如果Master出了故障,有些數據因為沒有被寫 入Slave,有可能會丟失
通常情況下,應該把Master和Save配置成同步刷盤方式,主從之間配置成異步的復制方式,這樣即使有一臺機器出故障,仍然能保證數據不丟,是個不錯的選擇。
負載均衡
Producer負載均衡:
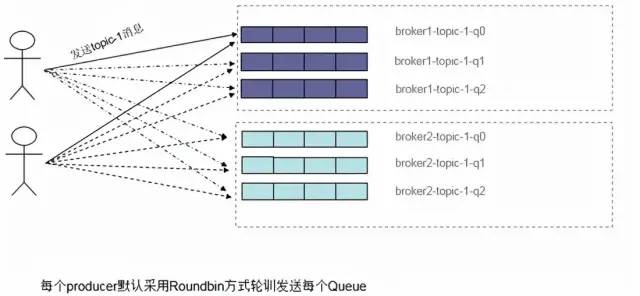
Producer端,每個實例在發消息的時候,默認會輪詢所有的Message Queue發送,以達到讓消息平均落在不同的Queue上。而由于Queue可以散落在不同的Broker,所以消息就發送到不同的Broker下,如下圖:
 Consumer負載均衡:
Consumer負載均衡:
如果Consumer實例的數量比Message Queue的總數量還多的話,多出來的Consumer實例將無法分到Queue,也就無法消費到消息,也就無法起到分攤負載的作用了。所以需要控制讓Queue的總數量大于等于Consumer的數量。
消費者的集群模式:啟動多個消費者就可以保證消費者的負載均衡(均攤隊列)
默認使用的是均攤隊列:會按照Queue的數量和實例的數量平均分配Queue給每個實例,這樣每個消費者可以均攤消費的隊列,如下圖所示6個隊列和三個生產者。
另外一種平均的算法環狀輪流分Queue的形式,每個消費者,均攤不同主節點的一個消息隊列,如下圖所示:
對于廣播模式并不是負載均衡的,要求一條消息需要投遞到一個消費組下面所有的消費者實例,所以也就沒有消息被分攤消費的說法。
死信隊列
當一條消息消費失敗,RocketMQ就會自動進行消息重試。而如果消息超過最大重試次數,RocketMQ就會認為這個消息有問題。但是此時,RocketMQ不會立刻將這個有問題的消息丟棄,而會將其發送到這個消費者組對應的一種特殊隊列:死信隊列。死信隊列的名稱是 %DLQ%+ConsumGroup 。
死信隊列具有以下特性:
一個死信隊列對應一個Group ID, 而不是對應單個消費者實例。
如果一個Group ID未產生死信消息,消息隊列RocketMQ不會為其創建相應的死信隊列。
一個死信隊列包含了對應Group ID產生的所有死信消息,不論該消息屬于哪個Topic
Kafka
Kafka是一個分布式、支持分區的、多副本的,基于ZooKeeper協調的分布式消息系統。
它最大的特性就是可以實時的處理大量數據以滿足各種需求場景:比如基于Hadoop的批處理系統、低延遲的實時系統、Storm/Spark流式處理引擎,Web/Nginx日志、訪問日志,消息服務等等,用Scala語言編寫。屬于Apache基金會的頂級開源項目。
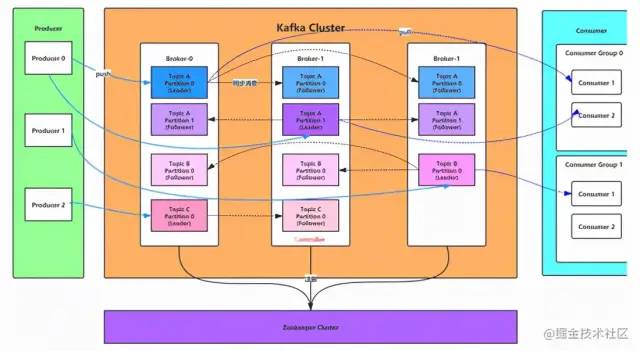
先看一下Kafka的架構圖 :
Kafka的核心概念
在Kafka中有幾個核心概念:
Broker:消息中間件處理節點,一個Kafka節點就是一個Broker,一個或者多個Broker可以組成一個Kafka集群
Topic:Kafka根據topic對消息進行歸類,發布到Kafka集群的每條消息都需要指定一個topic
Producer:消息生產者,向Broker發送消息的客戶端
Consumer:消息消費者,從Broker讀取消息的客戶端
ConsumerGroup:每個Consumer屬于一個特定的ConsumerGroup,一條消息可以被多個不同的ConsumerGroup消費,但是一個ConsumerGroup中只能有一個Consumer能夠消費該消息
Partition:物理上的概念,一個topic可以分為多個partition,每個partition內部消息是有序的
Leader:每個Partition有多個副本,其中有且僅有一個作為Leader,Leader是負責數據讀寫的Partition。
Follower:Follower跟隨Leader,所有寫請求都通過Leader路由,數據變更會廣播給所有Follower,Follower與Leader保持數據同步。如果Leader失效,則從Follower中選舉出一個新的Leader。當Follower與Leader掛掉、卡住或者同步太慢,Leader會把這個Follower從 ISR列表 中刪除,重新創建一個Follower。
Offset:偏移量。Kafka的存儲文件都是按照offset.kafka來命名,用Offset做名字的好處是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。
可以這么來理解Topic,Partition和Broker:
一個Topic,代表邏輯上的一個業務數據集,比如訂單相關操作消息放入訂單Topic,用戶相關操作消息放入用戶Topic,對于大型網站來說,后端數據都是海量的,訂單消息很可能是非常巨量的,比如有幾百個G甚至達到TB級別,如果把這么多數據都放在一臺機器上可定會有容量限制問題,那么就可以在Topic內部劃分多個Partition來分片存儲數據,不同的Partition可以位于不同的機器上,相當于分布式存儲。每臺機器上都運行一個Kafka的進程Broker。
Kafka核心總控制器Controller
在Kafka集群中會有一個或者多個Broker,其中有一個Broker會被選舉為控制器(Kafka Controller),可以理解為 Broker-Leader ,它負責管理整個 集群中所有分區和副本的狀態。
Partition-Leader
Controller選舉機制
在Kafka集群啟動的時候,選舉的過程是集群中每個Broker都會嘗試在ZooKeeper上創建一個 /controller臨時節點,ZooKeeper會保證有且僅有一個Broker能創建成功,這個Broker就會成為集群的總控器Controller。
當這個Controller角色的Broker宕機了,此時ZooKeeper臨時節點會消失,集群里其他Broker會一直監聽這個臨時節 點,發現臨時節點消失了,就競爭再次創建臨時節點,就是我們上面說的選舉機制,ZooKeeper又會保證有一個Broker成為新的Controller。具備控制器身份的Broker需要比其他普通的Broker多一份職責,具體細節如下:
監聽Broker相關的變化。為ZooKeeper中的/brokers/ids/節點添加BrokerChangeListener,用來處理Broker增減的變化。
監聽Topic相關的變化。為ZooKeeper中的/brokers/topics節點添加TopicChangeListener,用來處理Topic增減的變化;為ZooKeeper中的/admin/delete_topics節點添加TopicDeletionListener,用來處理刪除Topic的動作。
從ZooKeeper中讀取獲取當前所有與Topic、Partition以及Broker有關的信息并進行相應的管理 。對于所有Topic所對應的ZooKeeper中的/brokers/topics/節點添加PartitionModificationsListener,用來監聽Topic中的分區分配變化。
更新集群的元數據信息,同步到其他普通的Broker節點中
Partition副本選舉Leader機制
Controller感知到分區Leader所在的Broker掛了,Controller會從ISR列表(參數 unclean.leader.election.enable=false的前提下)里挑第一個Broker作為Leader(第一個Broker最先放進ISR列表,可能是同步數據最多的副本),如果參數unclean.leader.election.enable為true,代表在ISR列表里所有副本都掛了的時候可以在ISR列表以外的副本中選Leader,這種設置,可以提高可用性,但是選出的新Leader有可能數據少很多。副本進入ISR列表有兩個條件:
副本節點不能產生分區,必須能與ZooKeeper保持會話以及跟Leader副本網絡連通
副本能復制Leader上的所有寫操作,并且不能落后太多。(與Leader副本同步滯后的副本,是由replica.lag.time.max.ms配置決定的,超過這個時間都沒有跟Leader同步過的一次的副本會被移出ISR列表)
消費者消費消息的Offset記錄機制
每個Consumer會定期將自己消費分區的Offset提交給Kafka內部Topic:consumer_offsets,提交過去的時候,key是consumerGroupId+topic+分區號,value就是當前Offset的值,Kafka會定期清理Topic里的消息,最后就保留最新的那條數據。
因為__consumer_offsets可能會接收高并發的請求,Kafka默認給其分配50個分區(可以通過 offsets.topic.num.partitions設置),這樣可以通過加機器的方式抗大并發。
消費者Rebalance機制
Rebalance就是說 如果消費組里的消費者數量有變化或消費的分區數有變化,Kafka會重新分配消費者與消費分區的關系 。比如consumer group中某個消費者掛了,此時會自動把分配給他的分區交給其他的消費者,如果他又重啟了,那么又會把一些分區重新交還給他。
注意:Rebalance只針對subscribe這種不指定分區消費的情況,如果通過assign這種消費方式指定了分區,Kafka不會進行Rebalance。
如下情況可能會觸發消費者Rebalance:
消費組里的Consumer增加或減少了
動態給Topic增加了分區
消費組訂閱了更多的Topic
Rebalance過程中,消費者無法從Kafka消費消息,這對Kafka的TPS會有影響,如果Kafka集群內節點較多,比如數百 個,那重平衡可能會耗時極多,所以應盡量避免在系統高峰期的重平衡發生。
Rebalance過程如下
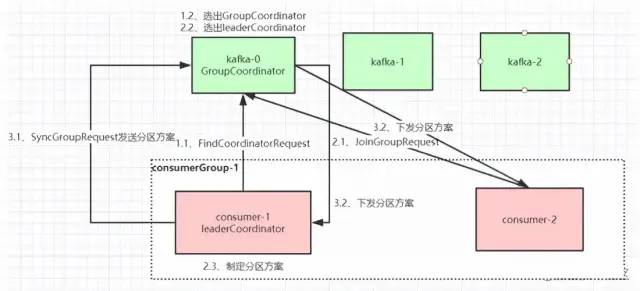
當有消費者加入消費組時,消費者、消費組及組協調器之間會經歷以下幾個階段:
 第一階段:選擇組協調器
第一階段:選擇組協調器
組協調器GroupCoordinator:每個consumer group都會選擇一個Broker作為自己的組協調器coordinator,負責監控這個消費組里的所有消費者的心跳,以及判斷是否宕機,然后開啟消費者Rebalance。consumer group中的每個consumer啟動時會向Kafka集群中的某個節點發送FindCoordinatorRequest請求來查找對應的組協調器GroupCoordinator,并跟其建立網絡連接。組協調器選擇方式:通過如下公式可以選出consumer消費的Offset要提交到__consumer_offsets的哪個分區,這個分區Leader對應的Broker就是這個consumer group的coordinator公式:
hash(consumer group id) % 對應主題的分區數
第二階段:加入消費組JOIN GROUP
在成功找到消費組所對應的GroupCoordinator之后就進入加入消費組的階段,在此階段的消費者會向GroupCoordinator發送JoinGroupRequest請求,并處理響應。然后GroupCoordinator從一個consumer group中選擇第一個加入group的consumer作為Leader(消費組協調器),把consumer group情況發送給這個Leader,接著這個Leader會負責制定分區方案。另外,搜索公眾號Python人工智能技術后臺回復“名著”,獲取一份驚喜禮包。
第三階段(SYNC GROUP)
consumer leader通過給GroupCoordinator發送SyncGroupRequest,接著GroupCoordinator就把分區方案下發給各個consumer,他們會根據指定分區的Leader Broker進行網絡連接以及消息消費。
消費者Rebalance分區分配策略
主要有三種Rebalance的策略:range 、 round-robin 、 sticky 。默認情況為range分配策略。
假設一個主題有10個分區(0-9),現在有三個consumer消費:
range策略:按照分區序號排序分配 ,假設n=分區數/消費者數量 = 3, m=分區數%消費者數量 = 1,那么前 m 個消 費者每個分配 n+1 個分區,后面的(消費者數量-m )個消費者每個分配 n 個分區。比如分區0~ 3給一個consumer,分區4~ 6給一個consumer,分區7~9給一個consumer。
round-robin策略:輪詢分配 ,比如分區0、3、6、9給一個consumer,分區1、4、7給一個consumer,分區2、5、 8給一個consumer
sticky策略:初始時分配策略與round-robin類似,但是在rebalance的時候,需要保證如下兩個原則:
分區的分配要盡可能均勻 。
分區的分配盡可能與上次分配的保持相同。
當兩者發生沖突時,第一個目標優先于第二個目標 。這樣可以最大程度維持原來的分區分配的策略。比如對于第一種range情況的分配,如果第三個consumer掛了,那么重新用sticky策略分配的結果如下:consumer1除了原有的0~ 3,會再分配一個7 consumer2除了原有的4~ 6,會再分配8和9。
Producer發布消息機制剖析
1、寫入方式
producer采用push模式將消息發布到broker,每條消息都被append到patition中,屬于順序寫磁盤(順序寫磁盤 比 隨機寫 效率要高,保障 kafka 吞吐率)。

牛逼啊!接私活必備的 N 個開源項目!趕快收藏吧
2、消息路由
producer發送消息到broker時,會根據分區算法選擇將其存儲到哪一個partition。其路由機制為:
hash(key)%分區數
3、寫入流程
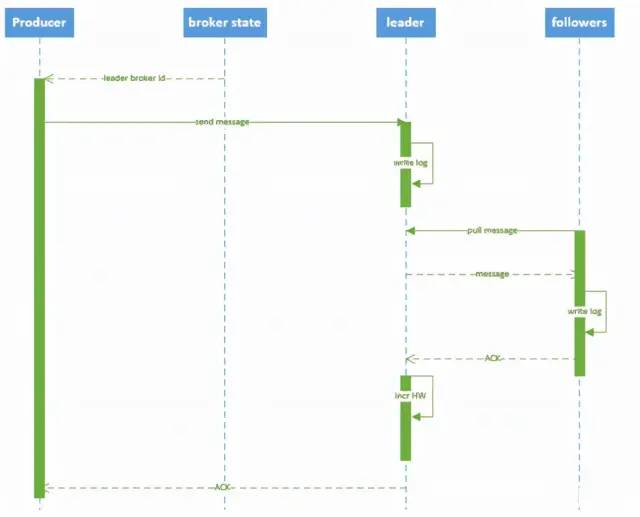
producer先從ZooKeeper的 "/brokers/…/state" 節點找到該partition的leader
producer將消息發送給該leader
leader將消息寫入本地log
followers從leader pull消息,寫入本地log后向leader發送ACK
leader收到所有ISR中的replica的ACK后,增加HW(high watermark,最后commit的offset)并向producer發送ACK
HW與LEO
HW俗稱高水位 ,HighWatermark的縮寫,取一個partition對應的ISR中最小的LEO(log-end-offset)作為HW, consumer最多只能消費到HW所在的位置。另外每個replica都有HW,leader和follower各自負責更新自己的HW的狀 態。對于leader新寫入的消息,consumer不能立刻消費,leader會等待該消息被所有ISR中的replicas同步后更新HW, 此時消息才能被consumer消費。這樣就保證了如果leader所在的broker失效,該消息仍然可以從新選舉的leader中獲取。對于來自內部broker的讀取請求,沒有HW的限制。
日志分段存儲
Kafka一個分區的消息數據對應存儲在一個文件夾下,以topic名稱+分區號命名,消息在分區內是分段存儲的, 每個段的消息都存儲在不一樣的log文件里,Kafka規定了一個段位的log文件最大為1G,做這個限制目的是為了方便把log文件加載到內存去操作:
1###部分消息的offset索引文件,kafka每次往分區發4K(可配置)消息就會記錄一條當前消息的offset到index文件, 2###如果要定位消息的offset會先在這個文件里快速定位,再去log文件里找具體消息 300000000000000000000.index 4###消息存儲文件,主要存offset和消息體 500000000000000000000.log 6###消息的發送時間索引文件,kafka每次往分區發4K(可配置)消息就會記錄一條當前消息的發送時間戳與對應的offset到timeindex文件, 7###如果需要按照時間來定位消息的offset,會先在這個文件里查找 800000000000000000000.timeindex 9 1000000000000005367851.index 1100000000000005367851.log 1200000000000005367851.timeindex 13 1400000000000009936472.index 1500000000000009936472.log 1600000000000009936472.timeindex
這個9936472之類的數字,就是代表了這個日志段文件里包含的起始 Offset,也就說明這個分區里至少都寫入了接近1000萬條數據了。Kafka Broker有一個參數,log.segment.bytes,限定了每個日志段文件的大小,最大就是1GB。一個日志段文件滿了,就自動開一個新的日志段文件來寫入,避免單個文件過大,影響文件的讀寫性能,這個過程叫做log rolling,正在被寫入的那個日志段文件,叫做active log segment。
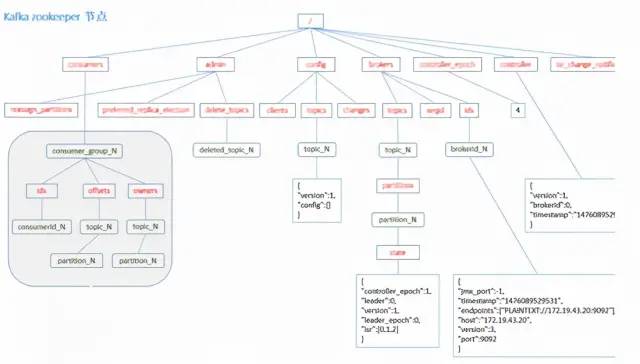
最后附一張ZooKeeper節點數據圖
MQ帶來的一些問題、及解決方案
如何保證順序消費?
RabbitMQ:一個Queue對應一個Consumer即可解決。
RocketMQhash(key)%隊列數
Kafka:hash(key)%分區數
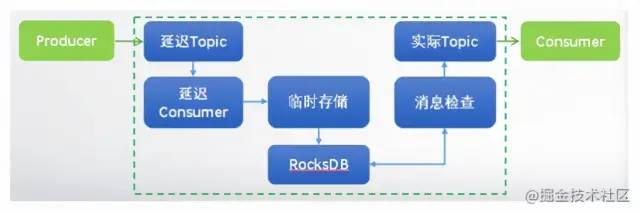
如何實現延遲消費?
RabbitMQ:兩種方案 死信隊列 + TTL引入RabbitMQ的延遲插件
RocketMQ:天生支持延時消息。
Kafka:步驟如下 專門為要延遲的消息創建一個Topic新建一個消費者去消費這個Topic消息持久化再開一個線程定時去拉取持久化的消息,放入實際要消費的Topic實際消費的消費者從實際要消費的Topic拉取消息。
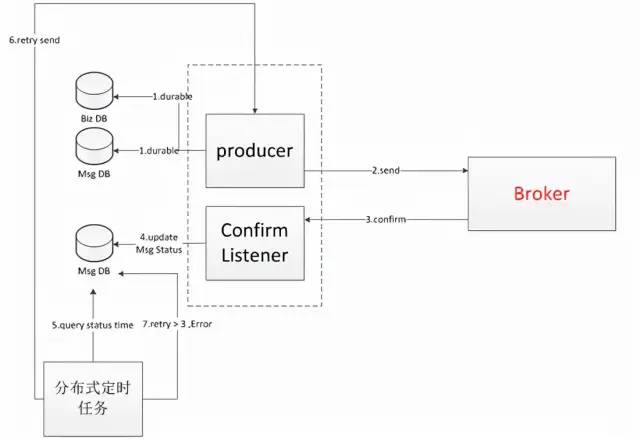
如何保證消息的可靠性投遞
RabbitMQ:
Broker-->消費者:手動ACK
生產者-->Broker:兩種方案
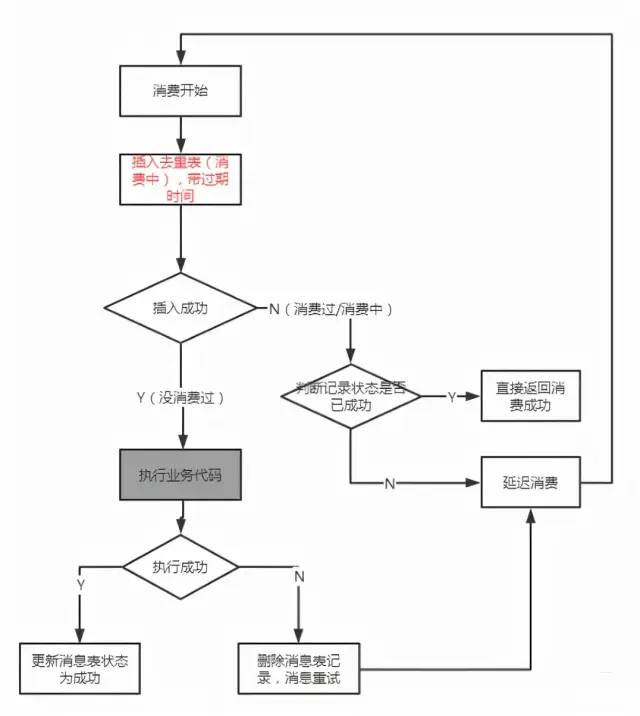
數據庫持久化:
1.將業務訂單數據和生成的Message進行持久化操作(一般情況下插入數據庫,這里如果分庫的話可能涉及到分布式事務) 2.將Message發送到Broker服務器中 3.通過RabbitMQ的Confirm機制,在producer端,監聽服務器是否ACK。 4.如果ACK了,就將Message這條數據狀態更新為已發送。如果失敗,修改為失敗狀態。 5.分布式定時任務查詢數據庫3分鐘(這個具體時間應該根據的時效性來定)之前的發送失敗的消息 6.重新發送消息,記錄發送次數 7.如果發送次數過多仍然失敗,那么就需要人工排查之類的操作。
優點:能夠保證消息百分百不丟失。
缺點:第一步會涉及到分布式事務問題。
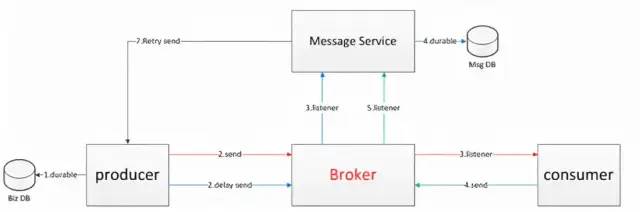
消息的延遲投遞:
流程圖中,顏色不同的代表不同的message 1.將業務訂單持久化 2.發送一條Message到broker(稱之為主Message),再發送相同的一條到不同的隊列或者交換機(這條稱為確認Message)中。 3.主Message由實際業務處理端消費后,生成一條響應Message。之前的確認Message由MessageService應用處理入庫。 4~6.實際業務處理端發送的確認Message由MessageService接收后,將原Message狀態修改。 7.如果該條Message沒有被確認,則通過rpc調用重新由producer進行全過程。
優點:相對于持久化方案來說響應速度有所提升
缺點:系統復雜性有點高,萬一消息都失敗了,消息存在丟失情況,仍需Confirm機制做補償。擴展:接私活兒
RocketMQ
生產者弄丟數據:
Producer在把Message發送Broker的過程中,因為網絡問題等發生丟失,或者Message到了Broker,但是出了問題,沒有保存下來。針對這個問題,RocketMQ對Producer發送消息設置了3種方式:
同步發送 異步發送 單向發送
Broker弄丟數據:
Broker接收到Message暫存到內存,Consumer還沒來得及消費,Broker掛掉了。
可以通過 持久化 設置去解決:
創建Queue的時候設置持久化,保證Broker持久化Queue的元數據,但是不會持久化Queue里面的消息
將Message的deliveryMode設置為2,可以將消息持久化到磁盤,這樣只有Message支持化到磁盤之后才會發送通知Producer ack
這兩步過后,即使Broker掛了,Producer肯定收不到ack的,就可以進行重發。
消費者弄丟數據:
Consumer有消費到Message,但是內部出現問題,Message還沒處理,Broker以為Consumer處理完了,只會把后續的消息發送。這時候,就要 關閉autoack,消息處理過后,進行手動ack , 多次消費失敗的消息,會進入 死信隊列 ,這時候需要人工干預。
Kafka
生產者弄丟數據
設置了 acks=all ,一定不會丟,要求是,你的 leader 接收到消息,所有的 follower 都同步到了消息之后,才認為本次寫成功了。如果沒滿足這個條件,生產者會自動不斷的重試,重試無限次。
Broker弄丟數據
Kafka 某個 broker 宕機,然后重新選舉 partition 的 leader。大家想想,要是此時其他的 follower 剛好還有些數據沒有同步,結果此時 leader 掛了,然后選舉某個 follower 成 leader 之后,不就少了一些數據?這就丟了一些數據啊。
此時一般是要求起碼設置如下 4 個參數:
replication.factor min.insync.replicas acks=all retries=MAX
我們生產環境就是按照上述要求配置的,這樣配置之后,至少在 Kafka broker 端就可以保證在 leader 所在 broker 發生故障,進行 leader 切換時,數據不會丟失。
消費者弄丟數據
你消費到了這個消息,然后消費者那邊自動提交了 offset,讓 Kafka 以為你已經消費好了這個消息,但其實你才剛準備處理這個消息,你還沒處理,你自己就掛了,此時這條消息就丟咯。
這不是跟 RabbitMQ 差不多嗎,大家都知道 Kafka 會自動提交 offset,那么只要 關閉自動提交 offset,在處理完之后自己手動提交 offset,就可以保證數據不會丟。但是此時確實還是可能會有重復消費,比如你剛處理完,還沒提交 offset,結果自己掛了,此時肯定會重復消費一次,自己保證冪等性就好了。
如何保證消息的冪等?
以 RocketMQ 為例,下面列出了消息重復的場景:
發送時消息重復
當一條消息已被成功發送到服務端并完成持久化,此時出現了網絡閃斷或者客戶端宕機,導致服務端對客戶端應答失敗。如果此時生產者意識到消息發送失敗并嘗試再次發送消息,消費者后續會收到兩條內容相同并且Message ID也相同的消息。
投遞時消息重復
消息消費的場景下,消息已投遞到消費者并完成業務處理,當客戶端給服務端反饋應答的時候網絡閃斷。為了保證消息至少被消費一次,消息隊列RocketMQ版的服務端將在網絡恢復后再次嘗試投遞之前已被處理過的消息,消費者后續會收到兩條內容相同并且Message ID也相同的消息。
負載均衡時消息重復(包括但不限于網絡抖動、Broker重啟以及消費者應用重啟)
當消息隊列RocketMQ版的Broker或客戶端重啟、擴容或縮容時,會觸發Rebalance,此時消費者可能會收到重復消息。
那么,有什么解決方案呢?直接上圖。
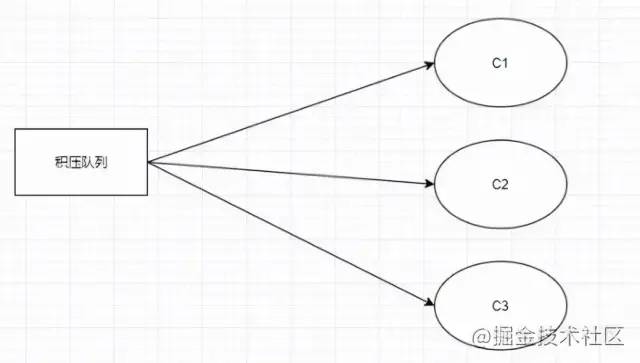
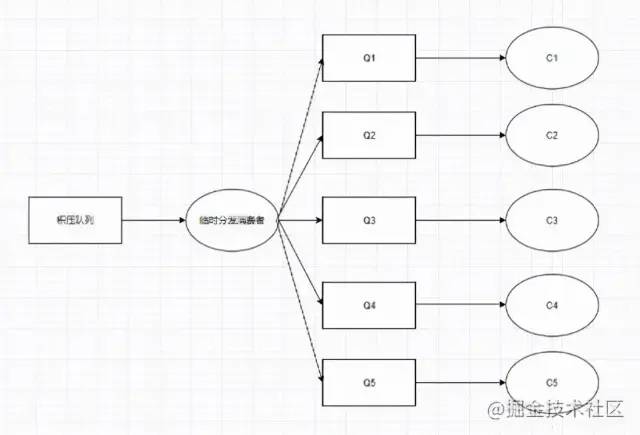
如何解決消息積壓的問題?
關于這個問題,有幾個點需要考慮:
如何快速讓積壓的消息被消費掉?
臨時寫一個消息分發的消費者,把積壓隊列里的消息均勻分發到N個隊列中,同時一個隊列對應一個消費者,相當于消費速度提高了N倍。
修改前:
修改后:
積壓時間太久,導致部分消息過期,怎么處理?
批量重導。在業務不繁忙的時候,比如凌晨,提前準備好程序,把丟失的那批消息查出來,重新導入到MQ中。
消息大量積壓,MQ磁盤被寫滿了,導致新消息進不來了,丟掉了大量消息,怎么處理?
這個沒辦法。誰讓【消息分發的消費者】寫的太慢了,你臨時寫程序,接入數據來消費,消費一個丟棄一個,都不要了,快速消費掉所有的消息。然后走第二個方案,到了晚上再補數據吧。
-
服務器
+關注
關注
12文章
9638瀏覽量
87138 -
交換機
+關注
關注
21文章
2708瀏覽量
101235 -
rabbitmq
+關注
關注
0文章
19瀏覽量
1118
原文標題:RabbitMQ、RocketMQ 和 Kafka 三元歸一
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
交換機接口類型,交換機各種類型接口圖片及介紹
交換機的10種故障類型
交換機的端口類型與接入的光模塊類型
核心交換機、匯聚交換機、接入交換機之間的對比分析
千兆交換機和百兆交換機應該如何選擇?






 工商網監
工商網監
評論