 基準分數突出了廣泛的機器學習推理性能
基準分數突出了廣泛的機器學習推理性能
繼今年早些時候發布的訓練基準分數之后,MLPerf 發布了其推理基準的第一組基準分數。
與目前有 5 家公司的 63 份參賽作品的訓練輪相比,更多的公司提交了基于 MobileNet、ResNet、Yolo 等神經網絡架構的推理結果。總共有來自 14 個組織的 500 多個分數進行了驗證。這包括來自幾家初創公司的數據,而一些知名初創公司仍然明顯缺席。
在封閉的部門,其嚴格的條件可以直接比較系統,結果顯示性能差異為 5 個數量級,并且在估計的功耗方面跨越三個數量級。在開放部門中,提交可以使用一系列模型,包括低精度實現。
Nvidia 在封閉部門的所有類別中都獲得了商用設備的第一名。其他領先者包括數據中心類別的 Habana Labs、谷歌和英特爾,而 Nvidia 在邊緣類別中與英特爾和高通競爭。

英偉達用于數據中心推理的 EGX 平臺(圖片:英偉達)
Moor Insights and Strategy 分析師 Karl Freund 表示:“Nvidia 是唯一一家擁有生產芯片、軟件、可編程性和人才的公司,可以發布跨 MLPerf 范圍內的基準測試,并在幾乎所有類別中獲勝。” “GPU 的可編程性為未來的 MLPerf 版本提供了獨特的優勢……我認為這展示了 [Nvidia] 實力的廣度,以及挑戰者的利基性質。但隨著時間的推移,許多挑戰者會變得成熟,因此英偉達需要繼續在硬件和軟件方面進行創新。”
Nvidia 發布的圖表顯示了其對結果的解釋,在商用設備的封閉部門的所有四個場景中,它都位居第一。
這些場景代表不同的用例。離線和服務器場景用于數據中心的推理。離線場景可能代表大量圖片的離線照片標記并測量純吞吐量。服務器場景代表一個用例,其中包含來自不同用戶的多個請求,在不可預測的時間提交請求,并在固定時間測量吞吐量。邊緣場景是單流,它對單個圖像進行推理,例如在手機應用程序中,以及多流,它測量可以同時推理多少個圖像流,用于多攝像頭系統。
公司可以為選定的機器學習模型提交結果,這些模型在四種場景中的每一種中執行圖像分類、對象檢測和語言翻譯。
數據中心結果
“從數據中心的結果來看,Nvidia 在服務器和離線類別的所有五個基準測試中均名列前茅,”Nvidia 加速計算產品管理總監 Paresh Kharya 說。“在商用解決方案中,我們的 Turing GPU 的性能優于其他所有人。”
Kharya 強調了這樣一個事實,即英偉達是唯一一家在數據中心類別的所有五個基準模型中提交結果的公司,而對于服務器類別(這是更困難的情況),英偉達的性能相對于其競爭對手有所提高。
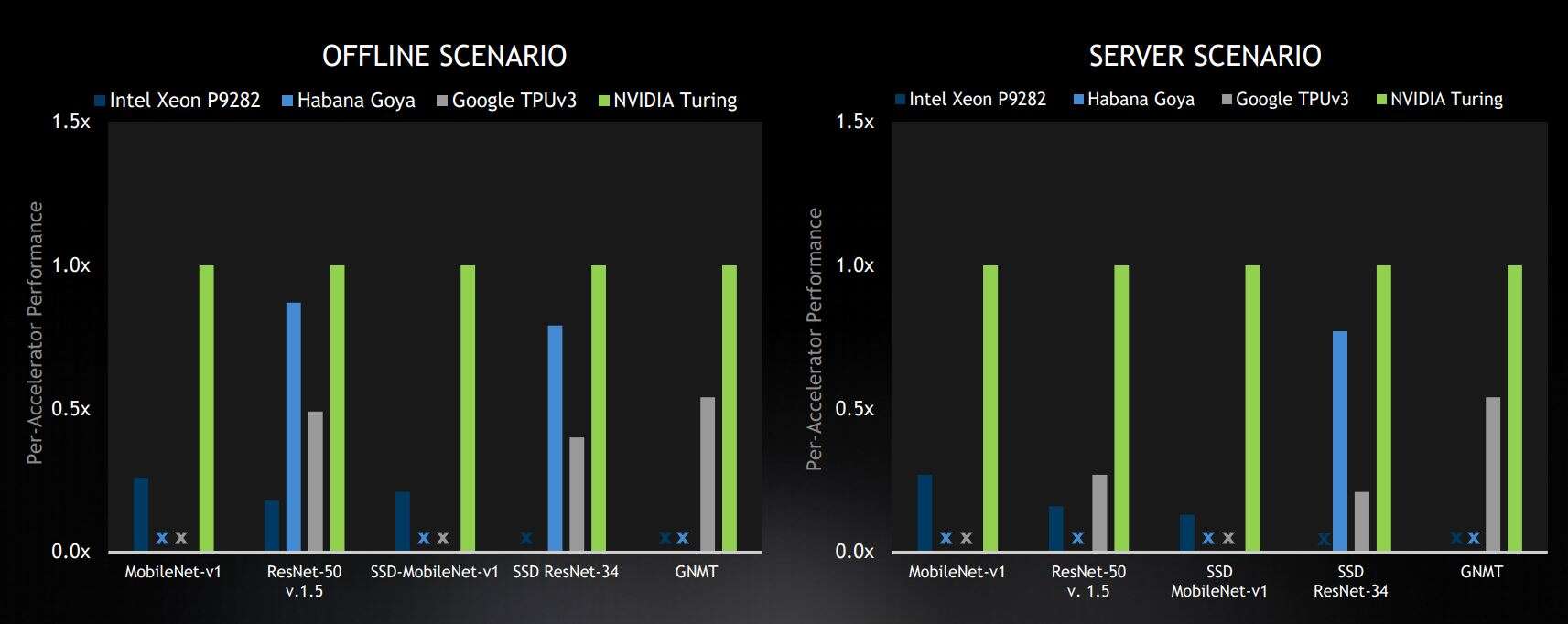
選定的數據中心基準測試結果來自封閉部門,在商用設備類別中處于領先地位。結果顯示相對于每個加速器的 Nvidia 分數。X 代表“未提交結果”(圖片:Nvidia)
英偉達在數據中心領域最接近的競爭對手是擁有Goya 推理芯片的以色列初創公司 Habana Labs 。
分析師 Karl Freund 表示:“Habana 是唯一一個全面生產高性能芯片的挑戰者,當下一個 MLPerf 套件有望包含功耗數據時,它應該會做得很好。”
Habana Labs 在接受 EETimes 采訪時指出,基準分數純粹基于性能——功耗不是衡量標準,實用性也不是(例如考慮解決方案是被動冷卻還是水冷),成本也不是。

Habana Labs PCIe 卡采用 Goya 推理芯片(圖片:Habana Labs)
Habana 還使用開放分區來展示其低延遲能力,比封閉分區進一步限制延遲,并為多流場景提交結果。
邊緣計算結果
在邊緣基準測試中,Nvidia 贏得了所有四個在封閉部門提交商用解決方案的類別。高通的 Snapdragon 855 SoC 和英特爾的 Xeon CPU 在單流類別中落后于英偉達,高通和英特爾都沒有提交更困難的多流場景的結果。
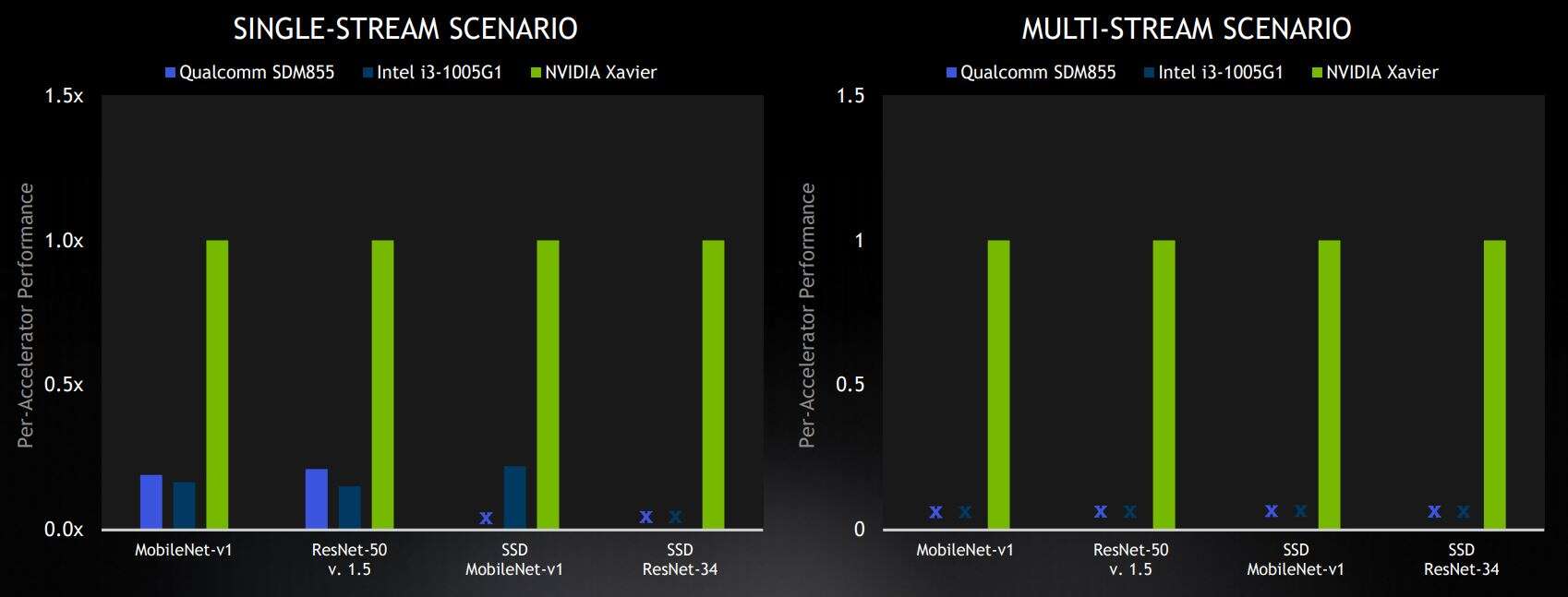
選定的邊緣基準測試結果來自封閉部門,在商用設備類別中處于領先地位。結果顯示相對于每個加速器的 Nvidia 分數。X 代表“未提交結果”(圖片:Nvidia)
“預覽”系統(尚未商業化)的結果將阿里巴巴 T-Head 的含光芯片與英特爾的 Nervana NNP-I、Hailo-8和 Centaur Technologies 的參考設計進行了對比。與此同時,研發類別的特色是一家隱秘的韓國初創公司 Furiosa AI,對此我們知之甚少。
MLPerf 網站上提供了最近的推理分數以及早期的訓練分數。
審核編輯 黃昊宇
-
基準測試
+關注
關注
0文章
21瀏覽量
7679 -
機器學習
+關注
關注
66文章
8492瀏覽量
134091
發布評論請先 登錄
英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型

探討DeepSeek-R1滿血版的推理部署與優化策略

《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
NVIDIA Jetson Orin Nano開發者套件的新功能

利用Arm Kleidi技術實現PyTorch優化

解鎖NVIDIA TensorRT-LLM的卓越性能
Arm KleidiAI助力提升PyTorch上LLM推理性能
Arm成功將Arm KleidiAI軟件庫集成到騰訊自研的Angel 機器學習框架
澎峰科技高性能大模型推理引擎PerfXLM解析

開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能






 工商網監
工商網監
評論