") 融合Image-Text和Image-Label兩種數(shù)據(jù)的多模態(tài)訓(xùn)練新方式
融合Image-Text和Image-Label兩種數(shù)據(jù)的多模態(tài)訓(xùn)練新方式
目前CV領(lǐng)域中包括兩種典型的訓(xùn)練模式,第一種是傳統(tǒng)的圖像分類訓(xùn)練,以離散的label為目標(biāo),人工標(biāo)注、收集干凈、大量的訓(xùn)練數(shù)據(jù),訓(xùn)練圖像識(shí)別模型。第二種方法是最近比較火的基于對(duì)比學(xué)習(xí)的圖文匹配訓(xùn)練方法,利用圖像和其對(duì)應(yīng)的文本描述,采用對(duì)比學(xué)習(xí)的方法訓(xùn)練模型。這兩種方法各有優(yōu)劣,前者可以達(dá)到非常高的圖像識(shí)別精度、比較強(qiáng)的遷移能力,但是依賴人工標(biāo)注數(shù)據(jù);后者可以利用海量噪聲可能較大的圖像文本對(duì)作為訓(xùn)練數(shù)據(jù),在few-shot learning、zero-shot learning上取得很好的效果,但是判別能力相比用干凈label訓(xùn)練的方法較弱。今天給大家介紹一篇CVPR 2022微軟發(fā)表的工作,融合兩種數(shù)據(jù)的一個(gè)大一統(tǒng)對(duì)比學(xué)習(xí)框架。

論文題目:Unified Contrastive Learning in Image-Text-Label Space
下載地址:https://arxiv.org/pdf/2204.03610.pdf
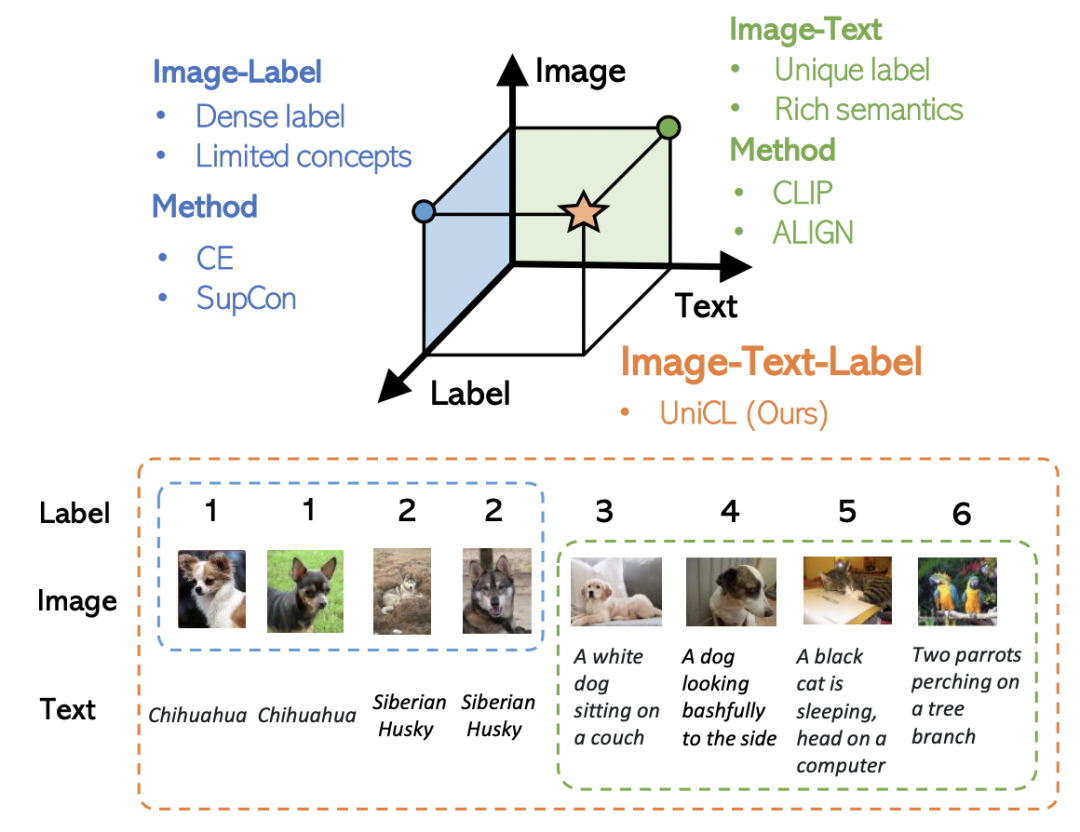
CVPR 2022微軟發(fā)表的這篇工作,希望同時(shí)利用圖像、文本、label三者的信息,構(gòu)建一個(gè)統(tǒng)一的對(duì)比學(xué)習(xí)框架,同時(shí)利用兩種訓(xùn)練模式的優(yōu)勢。下圖反映了兩種訓(xùn)練模式的差異,Image-Label以離散label為目標(biāo),將相同概念的圖像視為一組,完全忽視文本信息;而Image-Text以圖文對(duì)匹配為目標(biāo),每一對(duì)圖文可以視作一個(gè)單獨(dú)的label,文本側(cè)引入豐富的語義信息。
1
兩種數(shù)據(jù)的融合
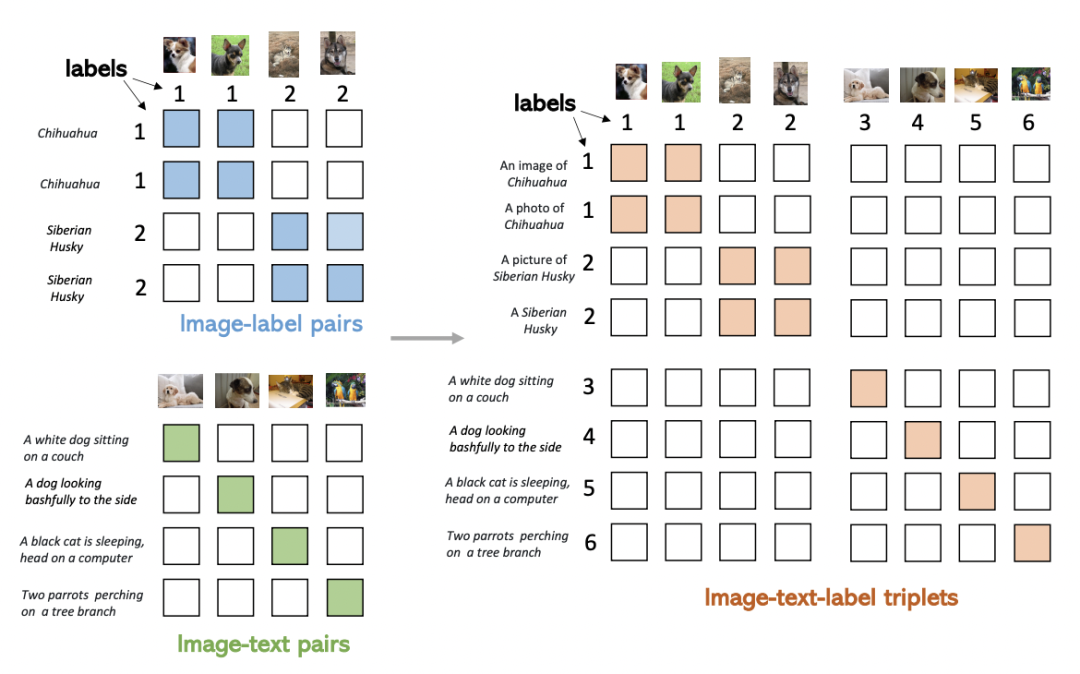
上面所說的Image-Label和Image-Text兩種數(shù)據(jù),可以表示成一個(gè)統(tǒng)一的形式:(圖像,文本,label)三元組。其中,對(duì)于Image-Lable數(shù)據(jù),文本是每個(gè)label對(duì)應(yīng)的類別名稱,label對(duì)應(yīng)的每個(gè)類別的離散標(biāo)簽;對(duì)于Image-Text數(shù)據(jù),文本是每個(gè)圖像的文本描述,label對(duì)于每對(duì)匹配的圖文對(duì)都是不同的。將兩種數(shù)據(jù)融合到一起,如下圖右側(cè)所示,可以形成一個(gè)矩陣,填充部分為正樣本,其他為負(fù)樣本。Image-Label數(shù)據(jù)中,對(duì)應(yīng)類別的圖文為正樣本;Image-Text中對(duì)角線為正樣本。
2
損失函數(shù)
在上述矩陣的基礎(chǔ)上,可以利用對(duì)比學(xué)習(xí)的思路構(gòu)建融合Image-Label和Image-Text兩種數(shù)據(jù)優(yōu)化函數(shù)。對(duì)于一個(gè)batch內(nèi)的所有樣本,分別使用圖像Encoder和文本Encoder得到圖像和文本的表示,并進(jìn)行歸一化,然后計(jì)算圖像文本之間的相似度,和CLIP類似。其中Image-to-Text損失函數(shù)可以表示為:
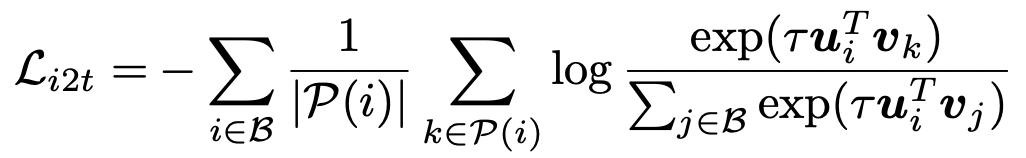
以樣本i(文本)為中心,k表示當(dāng)前batch內(nèi),和樣本i的label相同的圖像,j表示batch內(nèi)所有其他樣本。也就是說,對(duì)于每個(gè)文本,損失函數(shù)的分子是和該文本匹配的圖像,分母是batch內(nèi)所有圖像。Text-to-Image損失函數(shù)也類似。最終BiC loss是二者之和:
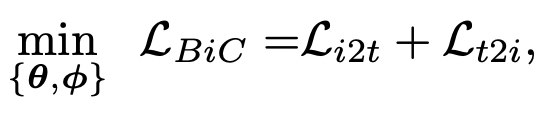
3
與其他損失函數(shù)的對(duì)比
BiC loss和交叉熵、Supervised Contrast以及CLIP三種方法的損失函數(shù)差別如下圖所示,這幾種損失函數(shù)之間存在著一定的聯(lián)系。
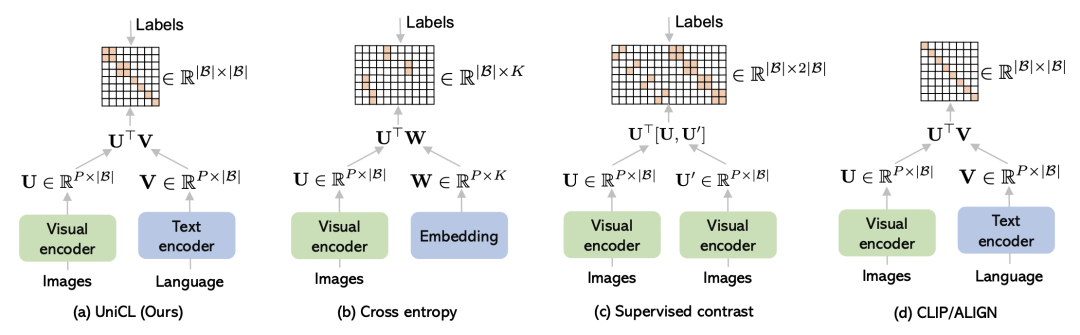
與交叉熵?fù)p失的關(guān)系:如果text encoder只是一個(gè)普通的全連接,并且batch size相比類別數(shù)量足夠大,以至于一個(gè)batch內(nèi)所有類別的樣本都出現(xiàn)過,那么BiC和交叉熵等價(jià)。因此BiC相比交叉熵更具一般性,BiC讓具有相似文本描述的圖像表示形成類簇,不具有相似文本描述的圖像被拉遠(yuǎn)。文本側(cè)也更加靈活,能夠使用任意種類的文本輸入,結(jié)合更豐富的文本Encoder聯(lián)合學(xué)習(xí)。
與SupCon的關(guān)系:SupCon是圖像對(duì)比學(xué)習(xí),訓(xùn)練數(shù)據(jù)每對(duì)pair都是圖像,共用一個(gè)Encoder;而BiC針對(duì)的是跨模態(tài)對(duì)比學(xué)習(xí),圖片和文本跨模態(tài)對(duì)齊。但是兩者的核心思路都是根據(jù)有l(wèi)abel數(shù)據(jù),將batch內(nèi)出現(xiàn)樣本更多置為正樣本。
與CLIP的關(guān)系:和CLIP的主要差別在于,利用label信息將一部分非對(duì)角線上的元素視為正樣本。如果這里不使用Image-Label數(shù)據(jù),那么就和CLIP相同。
4
實(shí)驗(yàn)效果
圖像分類效果對(duì)比:相比使用交叉熵?fù)p失和有監(jiān)督對(duì)比學(xué)習(xí),文中提出的UniCL在多個(gè)模型和數(shù)據(jù)集上取得較好的效果。尤其是在小數(shù)據(jù)集上訓(xùn)練時(shí),UniCL比交叉熵訓(xùn)練效果提升更明顯,因?yàn)橐氲膱D文匹配方式讓具有相似語義圖像聚集在一起,緩解了過擬合問題。

文本Encoder和損失函數(shù)對(duì)比:文中也對(duì)比了文本Encoder是否引入的效果,如果將Transformer替換成線性層,效果有所下降,表明文本Encoder的引入能夠幫助模型學(xué)習(xí)到1000多個(gè)類別之間的關(guān)系文本語義關(guān)系,有助于提升圖像分類效果。同時(shí),如果去掉i2t的loss只保留t2i的loss,會(huì)導(dǎo)致效果大幅下降。
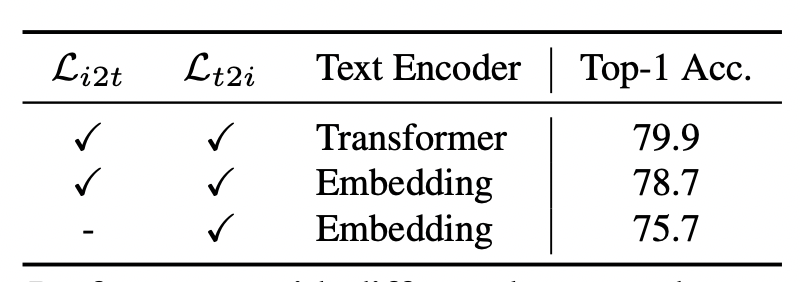
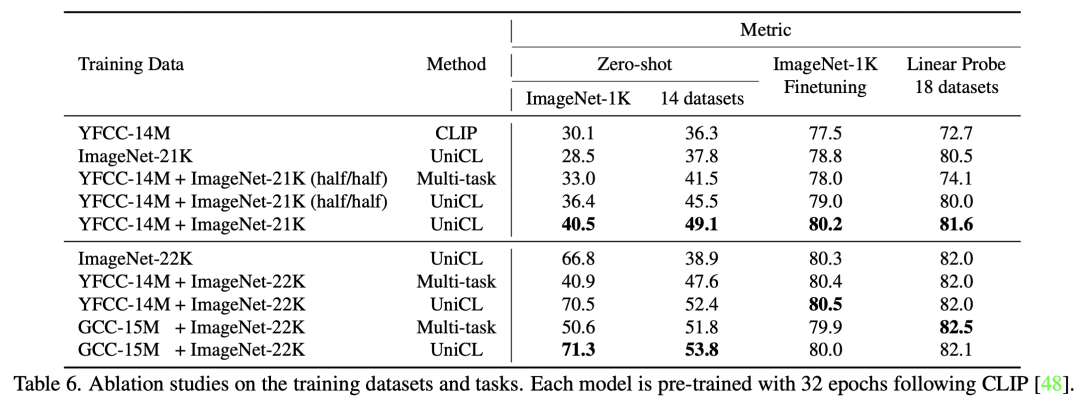
Image-Text引入對(duì)Image-Label效果提升:對(duì)于上面3行和下面3行,下面3行引入額外Image-Text數(shù)據(jù)的圖像分類效果要顯著優(yōu)于只使用圖像分類數(shù)據(jù)的效果。
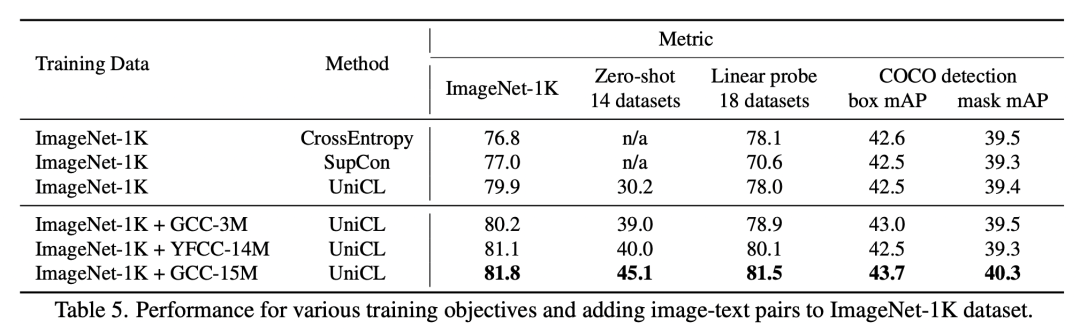
Image-Label引入對(duì)Image-Text效果提升:通過下面實(shí)驗(yàn)對(duì)比,引入Image-Label對(duì)Image-Text效果有一定提升作用。
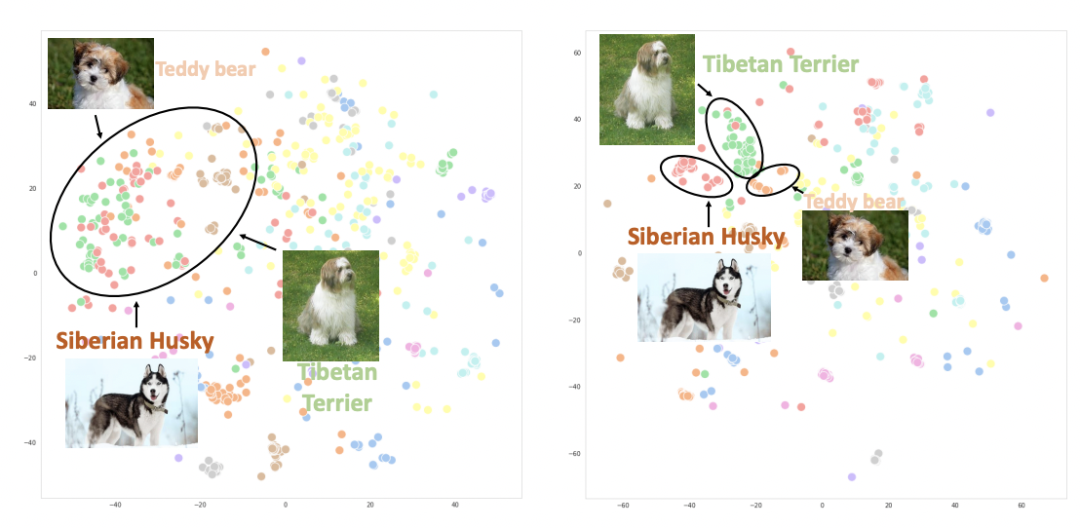
下圖繪制了使用CLIP(左)和UniCL(右)兩種方法訓(xùn)練的圖像embedding的t-sne圖。可以看到,使用CLIP訓(xùn)練的模型,不同類別的圖像表示混在一起;而使用UniCL訓(xùn)練的模型,不同類別的圖像表示能夠比較好的區(qū)分。
5
總結(jié)
本文介紹了融合Image-Text和Image-Label兩種數(shù)據(jù)的的多模態(tài)訓(xùn)練新方式,充分利用了不同的圖像-文本數(shù)據(jù),信息相互補(bǔ)充,相比單獨(dú)使用一個(gè)數(shù)據(jù)取得非常好的效果。Label的引入也讓對(duì)比學(xué)習(xí)的正負(fù)樣本構(gòu)造更加科學(xué)。
原文標(biāo)題:圖文匹配 + 圖像分類 = 統(tǒng)一多模態(tài)對(duì)比學(xué)習(xí)框架
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7242瀏覽量
91036 -
圖像識(shí)別
+關(guān)注
關(guān)注
9文章
526瀏覽量
38909 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4371瀏覽量
64223
原文標(biāo)題:圖文匹配 + 圖像分類 = 統(tǒng)一多模態(tài)對(duì)比學(xué)習(xí)框架
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
image.Image為什么無法創(chuàng)建圖像?
RGB888格式的image怎么保存jpg格式?
海康威視發(fā)布多模態(tài)大模型AI融合巡檢超腦
?多模態(tài)交互技術(shù)解析
DLP4500 sdk中pattern類和Image類如何使用?
解決HarmonyOS應(yīng)用中Image組件白塊問題的有效方案

2025年Next Token Prediction范式會(huì)統(tǒng)一多模態(tài)嗎

基于Label CIFAR10 image on FRDM-MCXN947例程實(shí)現(xiàn)鞋和帽子的識(shí)別

一文理解多模態(tài)大語言模型——下

超聲界“內(nèi)卷終結(jié)者”!ZRT智銳通提供全新引擎打造多模態(tài)影像融合系統(tǒng)

利用OpenVINO部署Qwen2多模態(tài)模型
圖片動(dòng)畫控件和Video image控件的使用方法
Labview與Halcon圖片Image互相轉(zhuǎn)換
鴻蒙ArkTS聲明式組件:Image






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論