") 采用雙塔BERT模型對文本字符和label進行編碼
采用雙塔BERT模型對文本字符和label進行編碼
這是一篇來自于 ACL 2022 的文章,總體思想就是在 meta-learning 的基礎上,采用雙塔 BERT 模型分別來對文本字符和對應的label進行編碼,并且將二者進行 Dot Product(點乘)得到的輸出做一個分類的事情。文章總體也不復雜,涉及到的公式也很少,比較容易理解作者的思路。對于采用序列標注的方式做 NER 是個不錯的思路。

1、模型
1.1 架構
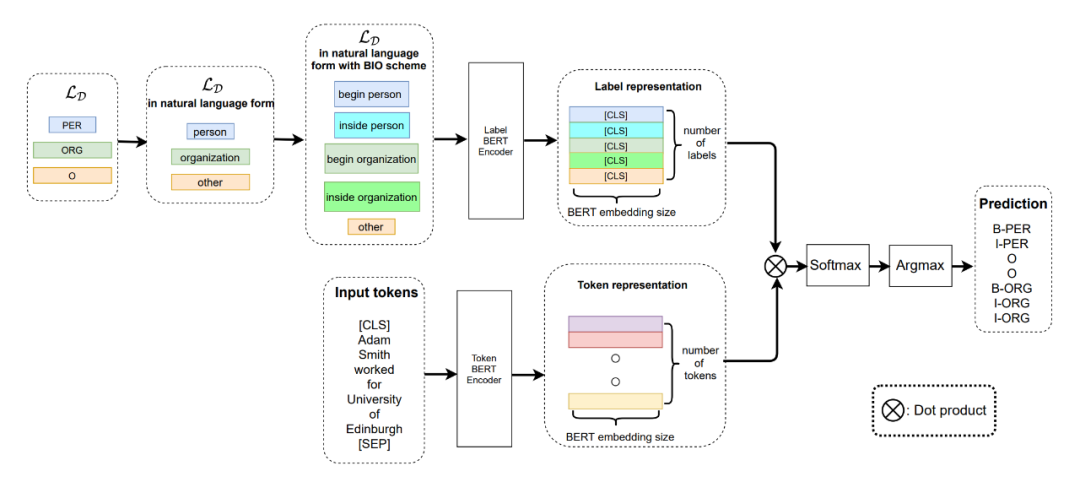
▲圖1.模型整體構架
從上圖中可以清楚的看到,作者采用了雙塔 BERT 來分別對文本的 Token 和每個 Token 對應的 label 進行編碼。這里作者采用這種方法的思路也很簡單,因為是 Few-shot 任務,沒有足夠的數(shù)據(jù)量,所以作者認為每個 Token 的 label 可以為 Token 提供額外的語義信息。 作者的 Meta-Learning 采用的是 metric-based 方法,直觀一點理解就是首先計算每個樣本 Token 的向量表征,然后與計算得到的 label 表征計算相似度,這里從圖上的 Dot Product 可以直觀的體現(xiàn)出來。然后對得到的相似度矩陣 ([batch_size,sequence_length,embed_dim]) 進行 softmax 歸一化,通過 argmax 函數(shù)取最后一維中值最大的 index,并且對應相應的標簽列表,得到當前 Token 對應的標簽。
1.2 Detail
此外,作者在對標簽進行表征時,也對每個標簽進行了相應的處理,總體分為以下三步: 1. 將詞語的簡寫標簽轉為自然語言形式,例如 PER--》person,ORG--》organization,LOC--》local 等等; 2. 將標注標簽起始、中間的標記轉為自然語言形式,例如以 BIO 形式進行標記的就可以轉為 begin、inside、other 等等,其他標注形式的類似。 3. 按前兩步的方法轉換后進行組合,例如 B-PER--》begin person,I-PER--》inside person。 由于進行的是 Few-shot NER 任務,所以作者在多個 source datasets 上面訓練模型,然后他們在多個 unseen few shot target datasets 上面驗證經(jīng)過 fine-tuning 和不經(jīng)過 fine-tuning 的模型的效果。 在進行 Token 編碼時,對應每個 通過 BERT 模型可以得到其對應的向量 ,如下所示:
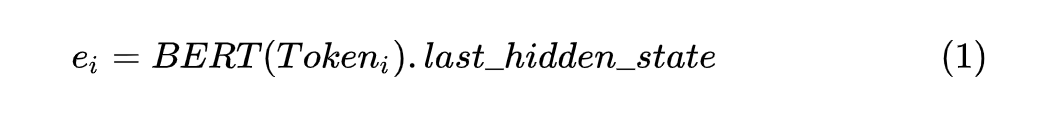
這里需要注意的是 BERT 模型的輸出取 last_hidden_state 作為對應 Token 的向量。 對標簽進行編碼時,對標簽集合中的所有標簽進行對應編碼,每個完整的 label 得到的編碼取 部分作為其編碼向量,并且將所有的 label 編碼組成一個向量集合 ,最后計算每個 與 的點積,形式如下:
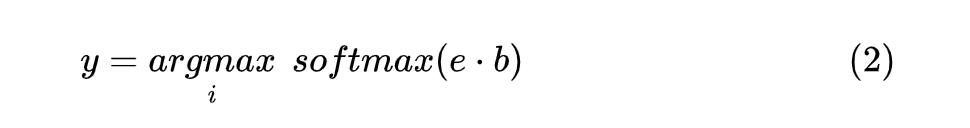
由于這里使用了 label 編碼表征的方式,相比于其他的 NER 方法,在模型遇到新的數(shù)據(jù)和 label 時,不需要再初始一個新的頂層分類器,以此達到 Few-shot 的目的。
1.3 Label Transfer
在文章中作者還羅列了實驗數(shù)據(jù)集的標簽轉換表,部分如下所示:
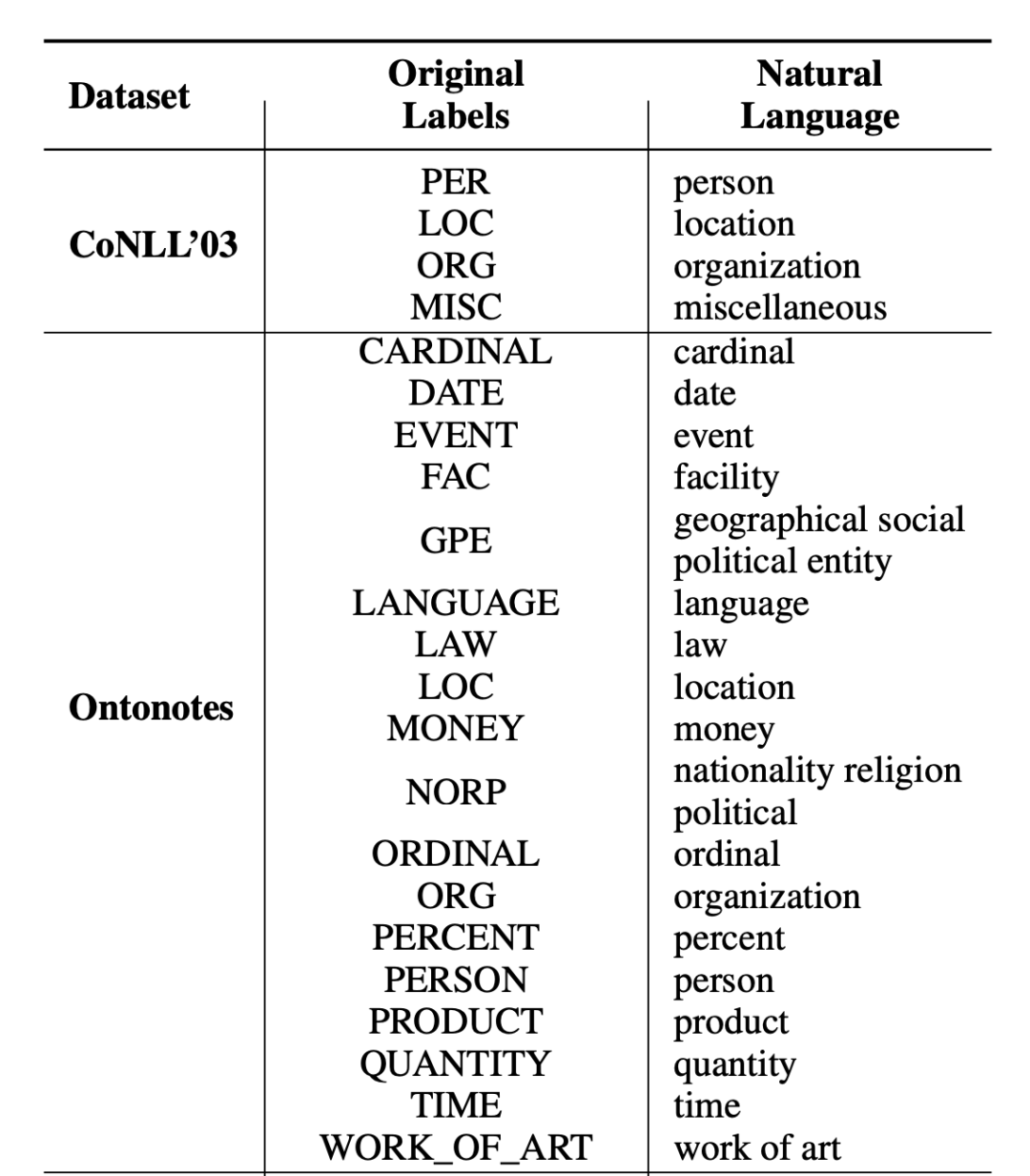
▲圖2. 實驗數(shù)據(jù)集Label Transfer
1.4 Support Set Sampling Algorithm
采樣偽代碼如下所示:

▲圖3. 采樣偽代碼
2、實驗結果
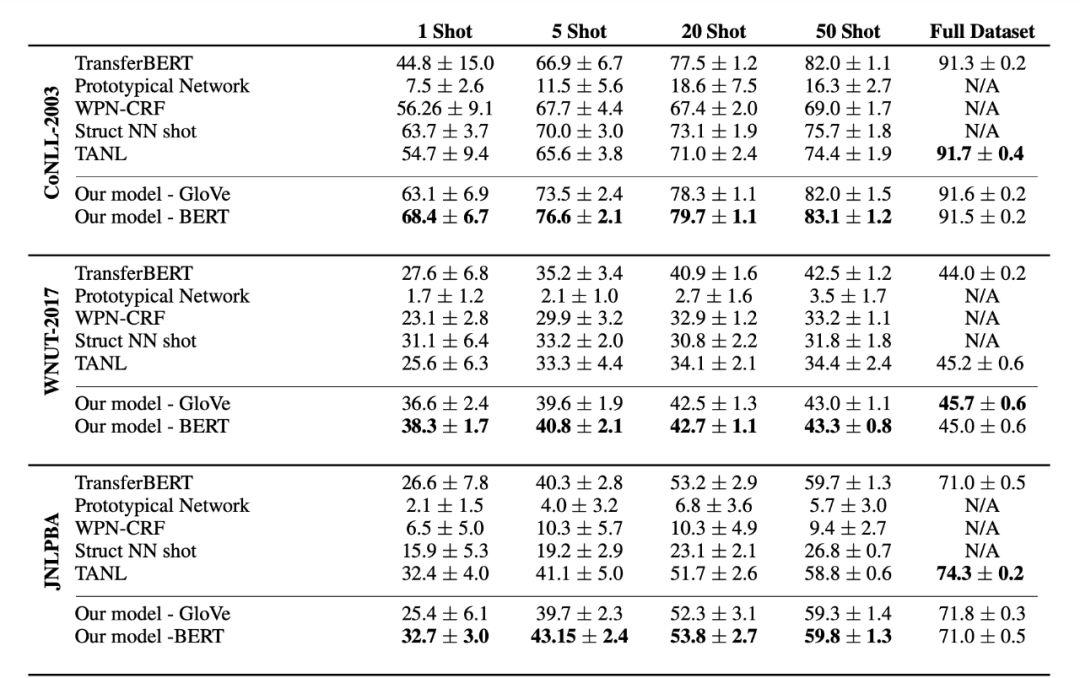
▲圖4. 部分實驗結果
從實驗結果上看,可以明顯的感受到這種方法在 Few-shot 時還是有不錯的效果的,在 1-50 shot 時模型的效果都優(yōu)于其他模型,表明了 label 語義的有效性;但在全量數(shù)據(jù)下,這種方法就打了一些折扣了,表明了數(shù)據(jù)量越大,模型對于 label 語義的依賴越小。這里筆者還有一點想法就是在全量數(shù)據(jù)下,這種方式的標簽語義引入可能會對原本的文本語義發(fā)生微小偏移,當然,這種說法在 Few-shot 下也是成立的,只不過 Few-shot 下的偏移是一個正向的偏移,能夠增強模型的泛化能力,全量數(shù)據(jù)下的偏移就有點溢出來的感覺。 雙塔 BERT 代碼實現(xiàn)(沒有采用 metric-based 方法):
#!/usr/bin/envpython #-*-coding:utf-8-*- #@Time:2022/5/2313:49 #@Author:SinGaln importtorch importtorch.nnasnn fromtransformersimportBertModel,BertPreTrainedModel classSinusoidalPositionEmbedding(nn.Module): """定義Sin-Cos位置Embedding """ def__init__( self,output_dim,merge_mode='add'): super(SinusoidalPositionEmbedding,self).__init__() self.output_dim=output_dim self.merge_mode=merge_mode defforward(self,inputs): input_shape=inputs.shape batch_size,seq_len=input_shape[0],input_shape[1] position_ids=torch.arange(seq_len,dtype=torch.float)[None] indices=torch.arange(self.output_dim//2,dtype=torch.float) indices=torch.pow(10000.0,-2*indices/self.output_dim) embeddings=torch.einsum('bn,d->bnd',position_ids,indices) embeddings=torch.stack([torch.sin(embeddings),torch.cos(embeddings)],dim=-1) embeddings=embeddings.repeat((batch_size,*([1]*len(embeddings.shape)))) embeddings=torch.reshape(embeddings,(batch_size,seq_len,self.output_dim)) ifself.merge_mode=='add': returninputs+embeddings.to(inputs.device) elifself.merge_mode=='mul': returninputs*(embeddings+1.0).to(inputs.device) elifself.merge_mode=='zero': returnembeddings.to(inputs.device) classDoubleTownNER(BertPreTrainedModel): def__init__(self,config,num_labels,position=False): super(DoubleTownNER,self).__init__(config) self.position=position self.num_labels=num_labels self.bert=BertModel(config=config) self.fc=nn.Linear(config.hidden_size,self.num_labels) ifself.position: self.sinposembed=SinusoidalPositionEmbedding(config.hidden_size,"add") defforward(self,sequence_input_ids,sequence_attention_mask,sequence_token_type_ids,label_input_ids, label_attention_mask,label_token_type_ids): #獲取文本和標簽的encode #[batch_size,sequence_length,embed_dim] sequence_outputs=self.bert(input_ids=sequence_input_ids,attention_mask=sequence_attention_mask, token_type_ids=sequence_token_type_ids).last_hidden_state #[batch_size,embed_dim] label_outputs=self.bert(input_ids=label_input_ids,attention_mask=label_attention_mask, token_type_ids=label_token_type_ids).pooler_output label_outputs=label_outputs.unsqueeze(1) #位置向量 ifself.position: sequence_outputs=self.sinposembed(sequence_outputs) #Dot交互 interactive_output=sequence_outputs*label_outputs #full-connection outputs=self.fc(interactive_output) returnoutputs if__name__=="__main__": pretrain_path="../bert_model" fromtransformersimportBertConfig token_input_ids=torch.randint(1,100,(32,128)) token_attention_mask=torch.ones_like(token_input_ids) token_token_type_ids=torch.zeros_like(token_input_ids) label_input_ids=torch.randint(1,10,(1,10)) label_attention_mask=torch.ones_like(label_input_ids) label_token_type_ids=torch.zeros_like(label_input_ids) config=BertConfig.from_pretrained(pretrain_path) model=DoubleTownNER.from_pretrained(pretrain_path,config=config,num_labels=10,position=True) outs=model(sequence_input_ids=token_input_ids,sequence_attention_mask=token_attention_mask,sequence_token_type_ids=token_token_type_ids,label_input_ids=label_input_ids, label_attention_mask=label_attention_mask,label_token_type_ids=label_token_type_ids) print(outs,outs.size())
審核編輯:郭婷
-
代碼
+關注
關注
30文章
4888瀏覽量
70277 -
數(shù)據(jù)集
+關注
關注
4文章
1223瀏覽量
25284
原文標題:ACL2022 | 序列標注的小樣本NER:融合標簽語義的雙塔BERT模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
從FA模型切換到Stage模型時:module的切換說明
?VLM(視覺語言模型)?詳細解析

使用OpenVINO?訓練擴展對水平文本檢測模型進行微調(diào),收到錯誤信息是怎么回事?
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術解讀
字符串與字符數(shù)組的區(qū)別
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
Linux三劍客之Sed:文本處理神器

如何優(yōu)化自然語言處理模型的性能
如何在文本字段中使用上標、下標及變量






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論