 通過全棧創新推動高性能計算
通過全棧創新推動高性能計算

高性能計算(HPC)已成為科學發現的基本工具。
無論是發現新的拯救生命的藥物,對抗氣候變化,還是創建精確的世界模擬,這些解決方案都需要巨大且快速增長的處理能力。它們越來越超出傳統計算方法的范圍。
這就是為什么業界接受 NVIDIA GPU加速計算的原因。與人工智能相結合,它為科學進步帶來了性能上百萬倍的飛躍。如今,2700個應用程序可以從 NVIDIA GPU 的加速中受益,而且這個數字在不斷增長的300萬開發者社區的支持下繼續上升。
HPC 應用程序性能改進
要在整個 HPC 應用程序范圍內實現數倍的加速,需要在堆棧的各個級別進行不懈的創新。這從芯片和系統開始,一直到應用程序框架本身。
NVIDIA 平臺每年都在繼續提供顯著的性能改進,在體系結構和整個 NVIDIA 軟件堆棧方面都取得了不懈的進步。與六年前發布的 P100 相比, H100 Tensor Core GPU 預計性能將提高 26 倍,比摩爾定律快 3 倍多。
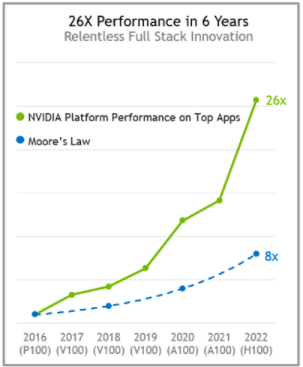
圖 1 NVIDIA HPC + AI 平臺性能從 P100 到 H100
圖 2 NVIDIA HPC SDK 為每個功能提供了開發人員資產。
NVIDIA 平臺的核心是功能豐富且高性能的軟件堆棧。為了促進 GPU 在最廣泛的 HPC 應用中的加速,該平臺包括 NVIDIA HPC SDK 。 SDK 提供了無與倫比的開發人員靈活性,支持使用標準語言、指令和 CUDA 創建和移植 GPU 加速的應用程序。
NVIDIA HPC SDK 的強大功能在于一整套高度優化的 GPU 加速數學庫 ,使您能夠充分發揮 NVIDIA GPU 的性能潛力。為了獲得最佳的多 GPU 和多節點性能, NVIDIA HPC SDK 還提供了功能強大的通信庫:
NVSHMEM 為跨越多個 GPU 內存的數據創建全局地址空間。
NVIDIA 集體通信庫( NCCL ) 優化了 GPU 之間的通信。
總之,該平臺提供了最高的性能和靈活性,以支持不斷增長的 GPU 加速 HPC 應用程序。
HPC 性能和能效
為了展示 NVIDIA 全棧創新如何轉化為 accelerated HPC 的最高性能,我們比較了 HPE 服務器與四個 NVIDIA GPU 服務器的性能,以及基于其他供應商同等數量加速器模塊的類似配置服務器的性能。
我們使用各種數據集測試了一組五個廣泛使用的 HPC 應用程序。雖然 NVIDIA 平臺可以加速 2700 個跨行業的應用程序,但我們在比較中可以使用的應用程序受到其他供應商加速器可用軟件和應用程序版本選擇的限制。
對于除分子動力學模擬軟件 NAMD 以外的所有工作負載,我們的結果是使用多個數據集的結果幾何平均值計算的,以最小化異常值的影響,并代表客戶體驗。
我們還在多 GPU 和單 GPU 場景中測試了這些應用程序。
在多 GPU 場景中,測試系統中的所有加速器都用于運行單個模擬,基于 A100 Tensor Core GPU 的服務器提供的性能比備選方案高出 2.1 倍。
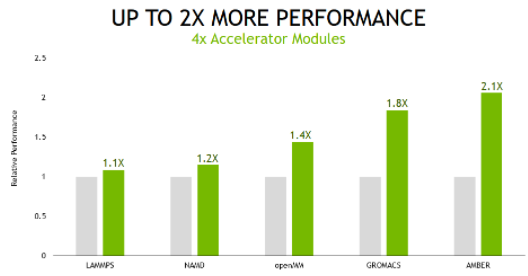
圖 3 NVIDIA A100 four- GPU 性能比較
在計算性能不斷進步的推動下,分子動力學領域正朝著在更長的模擬時間內模擬更大的原子系統的方向發展。這些進展使研究人員能夠模擬越來越多的生化機制,如光合電子傳遞和視覺信號轉導。這些和其他過程長期以來一直是科學辯論的主題,因為它們已經超出了模擬的范圍,模擬是驗證的主要工具。這是由于完成模擬所需的時間過長。
然而,我們認識到,并非所有這些應用程序的用戶在每次模擬時都使用多個 GPU 來運行它們。為了獲得最佳吞吐量,最佳執行方法通常是為每個模擬分配一個 GPU 。
當在 NVIDIA A100上的單個加速器模塊上運行這些相同的應用程序時,基于 NVIDIA A100的系統的性能提高了1.9倍。
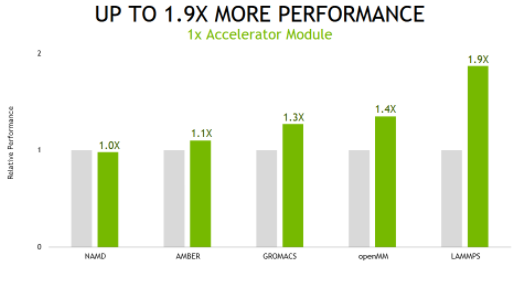
圖 4 NVIDIA A100 單 – GPU 性能比較
能源成本占數據中心和超級計算中心總體擁有成本( TCO )的很大一部分,這突出了節能計算平臺的重要性。我們的測試表明, NVIDIA 平臺提供的每瓦吞吐量比其他產品高出 2.8 倍。
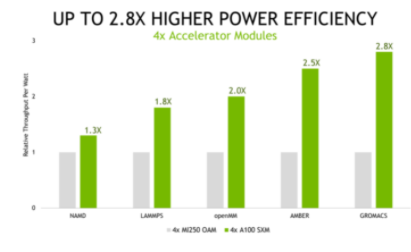
圖 5 NVIDIA A100 能效比較
顯示 A100 與 MI250 的效率比– NVIDIA 的效率越高越好。對每個應用程序的多個數據集(不同)進行 Geomean 。效率是指 GPU 使用 NVIDIA SMI 和 ROCm 中的等效功能測量的性能/功耗(瓦特)|
AMD MI250 在千兆字節 M262-HD5-00 上測量,具有( 2 )個 AMD EPYC 7763 和 4 個 AMD Instinct ? MI250 OAM ( 128 GB HBM2e ) 500W GPU 帶 AMD Infinity 結構? 技術 NVIDIA 在 ProLiant XL645d Gen10 Plus 上運行,使用雙 EPYC 7713 CPU 和 4x A100 ( 80 GB ) SXM4
LAMMPS develop \ u db00b49 ( AMD ) develop \ u 2a35ec2 ( NVIDIA )數據集 ReaxFF / c 、 Tersoff 、 Leonard Jones 、 SNAP | NAMD 3.0alpha9 數據集 STMV \ u NVE | OpenMM 7.7.0 數據集的集成運行: amber20 STMV 、 amber20 Cellular 、 apoa1pme 、 pme |
GROMACS 2021.1 ( AMD ) 2022 ( NVIDIA )數據集 ADH-Dodec (氫鍵), STMV (氫鍵)|琥珀色 20 。 xx \ U rocm \ U mr \ U 202108 ( AMD )和 20.12-AT \ U 21.12 ( NVIDIA )數據集 Cellular \ u NVE 、 STMV \ u NVE | 1x MI250 有 2x GCD
NVIDIA A100 GPU 卓越的性能和電源效率是多年不懈的軟硬件協同優化的結果,以最大限度地提高應用程序性能和效率。
A100 還以單處理器的形式出現在操作系統中,只需要啟動一個 MPI 列即可充分利用其性能。而且,由于節點中所有 GPU 之間的 600 GB / s NVLink 連接 , A100 在規模上提供了優異的性能。
AI 和 HPC 融合
正如加速計算為建模和仿真應用帶來了數倍的加速一樣, AI 和 HPC 的結合將帶來性能的下一步功能提升,開啟下一波科學發現。
關于作者
Ashraf Eassa 是NVIDIA 加速計算集團內部的高級產品營銷經理。
Chris 是 NVIDIA HPC 和 AI 的高級技術營銷經理。此前,他在 IBM 擔任聚合 HPC 和 AI 的產品經理,將 HPC 、 AI 和優化產品推向市場,專注于電子設計、航空航天和汽車行業。 Chris 擁有航空工程碩士學位,專注于設計優化。
審核編輯:郭婷
-
電源
+關注
關注
185文章
18377瀏覽量
256468 -
處理器
+關注
關注
68文章
19906瀏覽量
235525 -
NVIDIA
+關注
關注
14文章
5315瀏覽量
106504
發布評論請先 登錄
AI應用創新與全棧技術融合分論壇即將召開
知合計算:RISC-V架構創新,阿基米德系列劍指高性能計算

高性能計算集群在AI領域的應用前景

使用樹莓派構建 Slurm 高性能計算集群:分步指南!

佑駕創新獲長安汽車量產定點 為其提供高性能輔助駕駛域控制器產品
高性能計算面臨的芯片挑戰
Synaptics發布高性能AI MCU,推動邊緣計算新突破






 工商網監
工商網監
評論