 CNN根本無需理解圖像全局結構,一樣也能SOTA?
CNN根本無需理解圖像全局結構,一樣也能SOTA?

不給全圖,只投喂CNN一些看上去毫無信息量的圖像碎片,就能讓模型學會圖像分類。
更重要的是,性能完全不差,甚至還能反超用完整圖像訓練的模型。

這么一項來自加州大學圣塔芭芭拉分校的新研究,這兩天引發不少討論。
咋地,這就是說,CNN根本無需理解圖像全局結構,一樣也能SOTA?
具體是怎么一回事,咱們還是直接上論文。
實驗證據
研究人員設計了這樣一個實驗:
他們在CIFAR-10、CIFAR-100、STL-10、Tiny-ImageNet-200以及Imagenet-1K等數據集上訓練ResNet。
特別的是,用于訓練的圖像是通過隨機裁剪得到的。
這個“隨機裁剪”,可不是往常我們會在數據增強方法中見到的那一種,而是完全不做任何填充。
舉個例子,就是對圖片做PyTorch的RandomCrop變換時,padding的參數填0。
得到的訓練圖像就是下面這個樣式的。即使你是閱圖無數的老司機,恐怕也分辨不出到底是個啥玩意兒。

訓練圖像如此碎片化,模型的識圖能力又能達到幾成?
來看實驗結果:
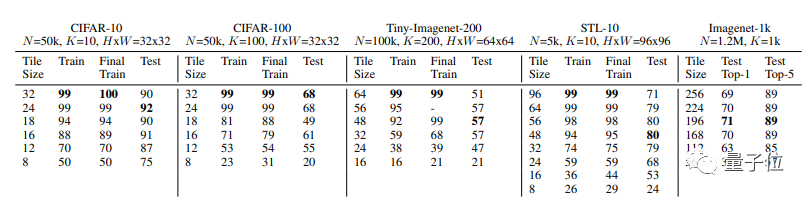
好家伙,在CIFAR-10上,用16×16的圖像碎片訓練出來的模型,測試準確率能達到91%,而用完整的32×32尺寸圖像訓練出來的模型,測試準確率也不過90%。
這一波,“殘缺版”CNN竟然完全不落下風,甚至還反超了“完整版”CNN。
要知道,被喂了碎片的CNN模型,看到的圖像甚至可能跟標簽顯示的物體毫無關系,只是原圖中背景的部分……
在STL-10、Tiny-Imagenet-200等數據集上,研究人員也得到了類似的結果。
不過,在CIFAR-100上,還是完整圖像訓練出來的模型略勝一籌。16×16圖像碎片訓練出的模型測試準確率為61%,而32×32完整圖像訓練出的模型準確率為68%。
所以,CNN為何會有如此表現?莫非它本來就是個“近視眼”?
研究人員推測,CNN能有如此優秀的泛化表現,是因為在這個實驗中,維度詛咒的影響被削弱了。
所謂維度詛咒(curse of dimensionality),是指當維數提高時,空間體積提高太快,導致可用數據變得稀疏。
而在這項研究中,由于CNN學習到的不是整個圖像的標簽,而是圖像碎片的標簽,這就在兩個方面降低了維度詛咒的影響:
圖像碎片的像素比完整圖像小得多,這減少了輸入維度
訓練期間可用的樣本數量增加了
生成熱圖
基于以上實驗觀察結果,研究人員還提出以熱圖的形式,來理解CNN的預測行為,由此進一步對模型的錯誤做出“診斷”。
就像這樣:

這些圖像來自于STL-10數據集。熱圖顯示,對于CNN而言,飛機圖像中最能“刺激”到模型的,不是飛機本身,而是天空。
同樣,在汽車圖像中,車輪才是CNN用來識別圖像的主要屬性。
論文地址: https://arxiv.org/abs/2205.10760
審核編輯 :李倩
-
圖像分類
+關注
關注
0文章
96瀏覽量
12166 -
數據集
+關注
關注
4文章
1224瀏覽量
25446 -
cnn
+關注
關注
3文章
354瀏覽量
22741
原文標題:不看全圖看局部,CNN性能竟然更強了
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
圖像采集卡和顯卡是一樣的嗎?從核心差異、工作原理與應用全解析

貼片電容和瓷片電容一樣嗎?

Stm32CubeIDE能像Keil一樣指定不同文件下的代碼編譯到不同的FLASH地址嗎?
為什么要費這么大勁讓機器人像人一樣,而不是更實用的形態?
Mamba入局圖像復原,達成新SOTA
SN65DPHY440SS 4組數據輸入輸出的內部結構是否一樣?
直線電機的精度能達到多少?和重復定位精度一樣嗎
每次Vivado編譯的結果都一樣嗎






 工商網監
工商網監
評論