") Swin Transformer在MIM中的應用
Swin Transformer在MIM中的應用

自何愷明MAE橫空出世以來,MIM(Masked Image Modeling)這一自監(jiān)督預訓練表征越來越引發(fā)關注。
但與此同時, 研究人員也不得不思考它的局限性。
MAE論文中只嘗試了使用原版ViT架構作為編碼器,而表現(xiàn)更好的分層設計結構(以Swin Transformer為代表),并不能直接用上MAE方法。
于是,一場整合的范式就此在研究團隊中上演。
代表工作之一是來自清華、微軟亞研院以及西安交大提出SimMIM,它探索了Swin Transformer在MIM中的應用。
但與MAE相比,它在可見和掩碼圖塊均有操作,且計算量過大。有研究人員發(fā)現(xiàn),即便是SimMIM的基本尺寸模型,也無法在一臺配置8個32GB GPU的機器上完成訓練。
基于這樣的背景,東京大學&商湯&悉尼大學的研究員,提供一個新思路。

不光將Swin Transformer整合到了MAE框架上,既有與SimMIM相當的任務表現(xiàn),還保證了計算效率和性能——
將分層ViT的訓練速度提高2.7倍,GPU內存使用量減少70%。
來康康這是一項什么研究?
當分層設計引入MAE
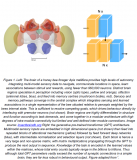
這篇論文提出了一種面向MIM的綠色分層視覺Transformer。
即允許分層ViT丟棄掩碼圖塊,只對可見圖塊進行操作。
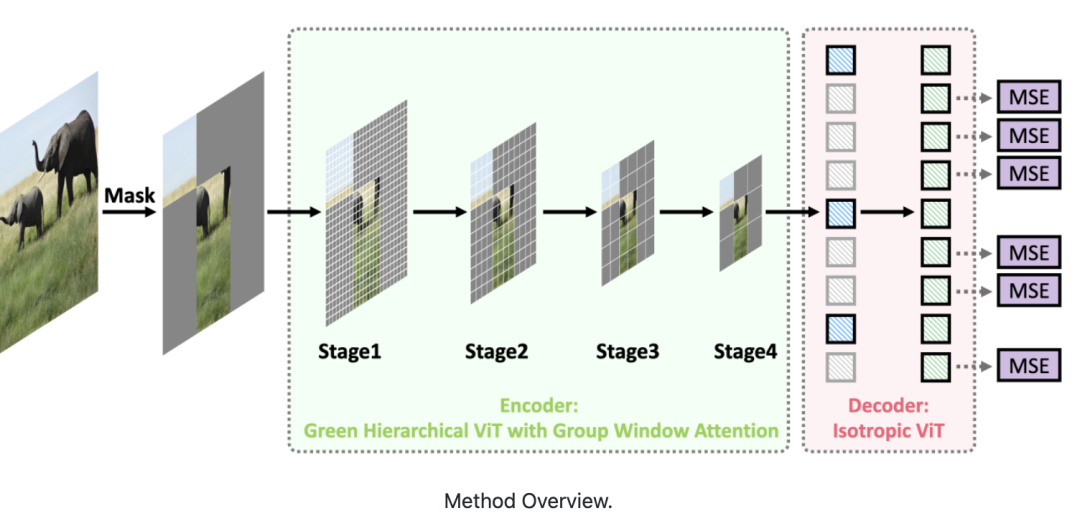
具體實現(xiàn),由兩個關鍵部分組成。
首先,設計了一種基于分治策略的群體窗口注意力方案。
將具有不同數量可見圖塊的局部窗口聚集成幾個大小相等的組,然后在每組內進行掩碼自注意力。
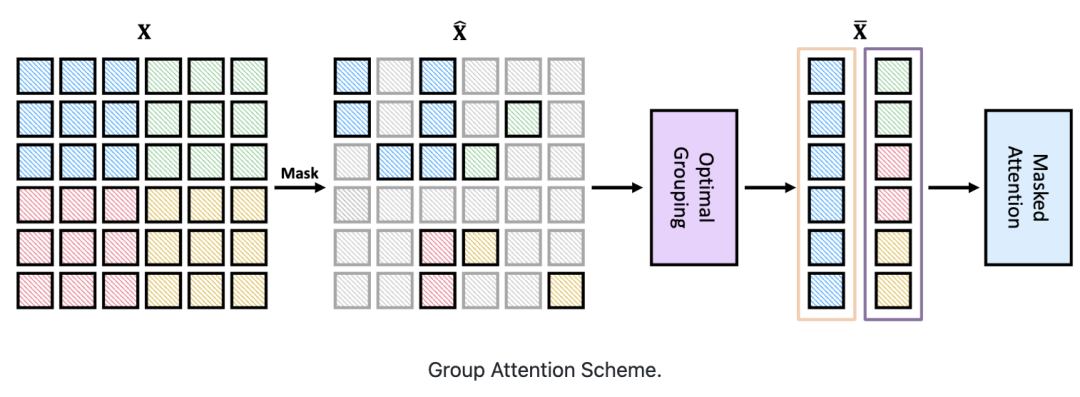
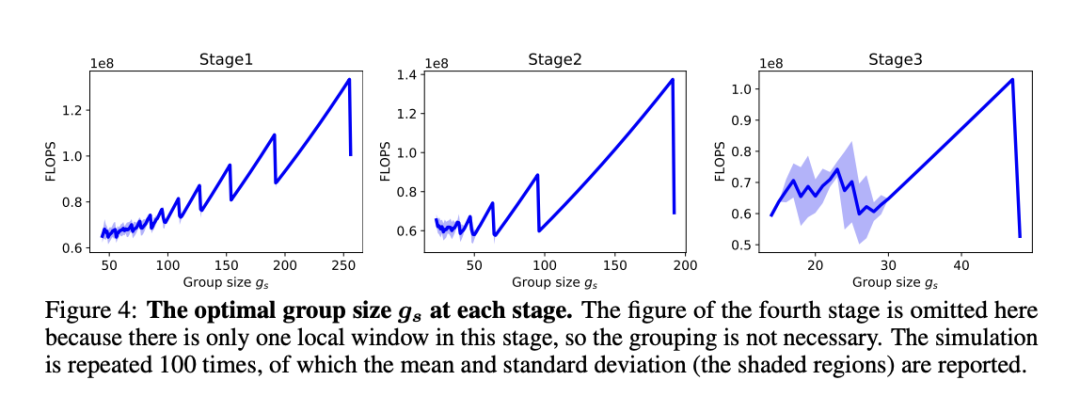
其次,把上述分組任務視為有約束動態(tài)規(guī)劃問題,受貪心算法的啟發(fā)提出了一種分組算法。

它可以自適應選擇最佳分組大小,并將局部窗口分成最少的一組,從而使分組圖塊上的注意力整體計算成本最小。
表現(xiàn)相當,訓練時間大大減少
結果顯示,在ImageNet-1K和MS-COCO數據集上實驗評估表明,與基線SimMIM性能相當的同時,效率提升2倍以上。
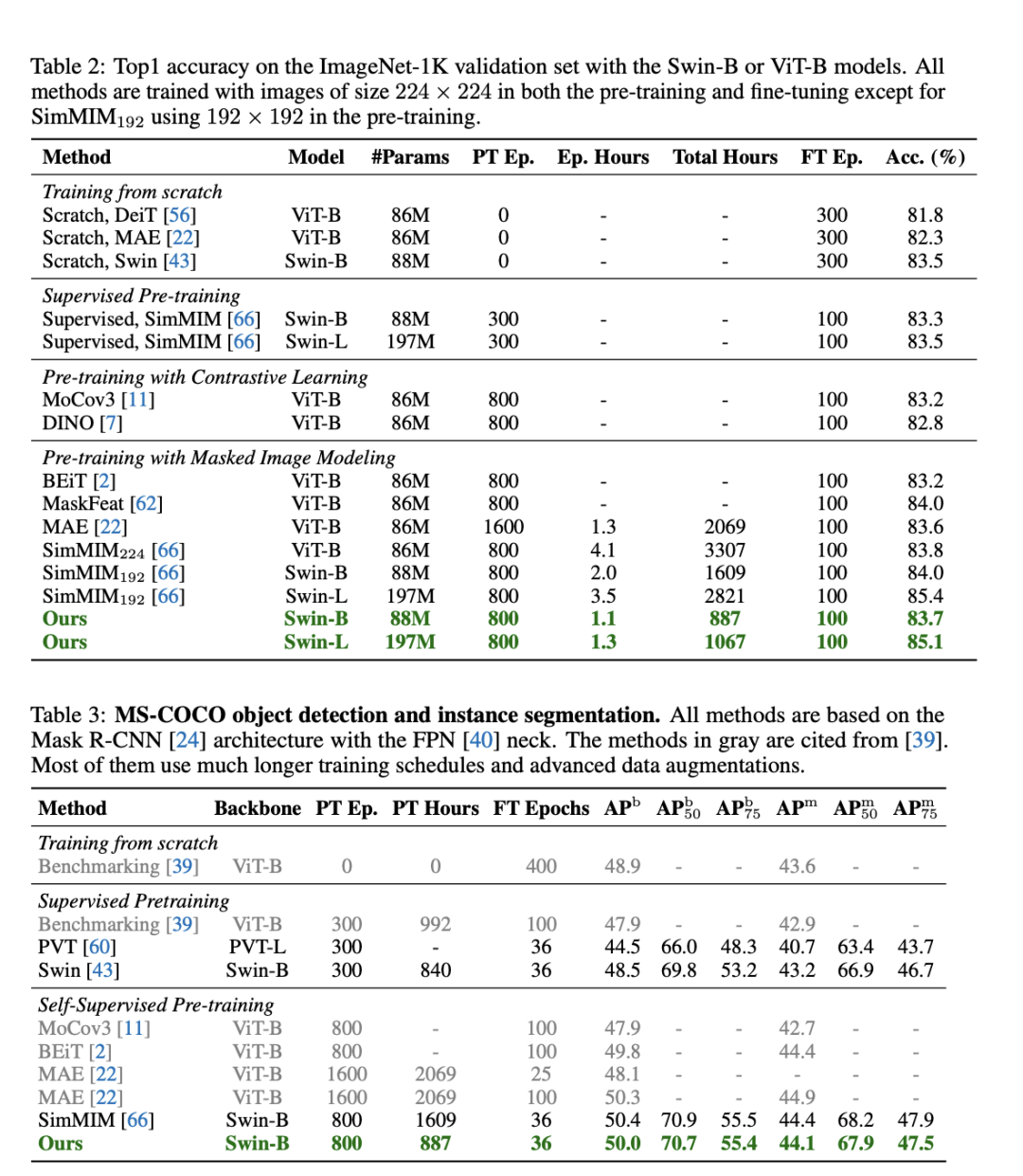
而跟SimMIM相比,這一方法在所需訓練時間大大減少,消耗GPU內存也小得多。具體而言,在相同的訓練次數下,在Swin-B上提高2倍的速度和減少60%的內存。

值得一提的是,該研究團隊在有8個32GB V100 GPU的單機上進行評估的,而SimMIM是在2或4臺機器上進行評估。
研究人員還發(fā)現(xiàn),效率的提高隨著Swin-L的增大而變大,例如,與SimMIM192相比,速度提高了2.7倍。
實驗的最后,提到了算法的局限性。其中之一就是需要分層次掩碼來達到最佳的效率,限制了更廣泛的應用。這一點就交給未來的研究。
而談到這一研究的影響性,研究人員表示,主要就是減輕了MIM的計算負擔,提高了MIM的效率和有效性。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3794瀏覽量
138006 -
數據集
+關注
關注
4文章
1224瀏覽量
25444
原文標題:何愷明MAE局限性被打破,與Swin Transformer結合,訓練速度大大提升 | 東大&商湯&悉大
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
Transformer架構中編碼器的工作流程

Transformer架構概述

快手上線鴻蒙應用高性能解決方案:數據反序列化性能提升90%
如何使用MATLAB構建Transformer模型

OptiFDTD應用:納米盤型諧振腔等離子體波導濾波器
transformer專用ASIC芯片Sohu說明

港大提出SparX:強化Vision Mamba和Transformer的稀疏跳躍連接機制

【面試題】人工智能工程師高頻面試題匯總:Transformer篇(題目+答案)
Transformer是機器人技術的基礎嗎
詳解電容的測試條件

什么是LLM?LLM在自然語言處理中的應用
自動駕駛中一直說的BEV+Transformer到底是個啥?






 工商網監(jiān)
工商網監(jiān)
評論