 用非參數方法提高強化學習的樣本效率
用非參數方法提高強化學習的樣本效率

人工智能和自主學習的最新發展表明,在棋盤游戲和電腦游戲等任務中取得了令人印象深刻的成果。然而,學習技術的適用性主要局限于模擬環境。
這種不適用于實際場景的主要原因之一是樣本效率低下,無法保證最先進的強化學習的安全運行。在強化學習理論中,你想根據一個特定的指標來改善一個代理的行為。為了改進這個度量,代理可以與環境交互,從中收集觀察結果和獎勵。可以用兩種不同的方式進行改進: 論政策 和 非保險單 。
在政策性案例中,必須通過代理人與環境的直接互動來實現改進。這種改進在數學上很簡單,但由于不允許重復使用樣本,因此阻礙了樣本效率。當代理行為得到改善時,代理必須與環境重新交互以生成新的 on 策略樣本。例如,在學習的早期階段, agentMIG 不適合與物理環境直接交互,因為它的行為是隨機的。在模擬任務中,樣本的可用性是無限的,有害行為的應用沒有危險。然而,對于實際應用,這些問題是嚴重的。
在關閉策略的情況下,可以通過與其他代理完成的環境的交互來改進代理的行為。這允許樣本重用和更安全的交互,因為與環境交互的代理可以是專家。例如,人類可以通過移動機械臂來采集樣本。
政策外改善的缺點是難以獲得可靠的估計。在目前的技術狀況下,所提出的技術要么具有高偏差,要么具有高方差。此外,有些技術對必須如何與環境進行交互有著具體而強烈的要求。
在這篇文章中,我討論了非參數非政策梯度( NOPG ),它具有更好的偏差方差權衡,并且對如何生成非政策樣本沒有什么要求。 NOPG 是由 Darmstadt 的智能自治系統實驗室開發的,已經被證明可以有效地解決一些經典的控制問題,并克服了目前最先進的非策略梯度估計中存在的一些問題。有關詳細信息,請參見 非參數的政策外政策梯度 。
強化學習與政策外梯度
強化學習是機器學習的一個子領域,其中一個代理(我在這篇文章中稱之為策略)與環境交互并觀察環境的狀態和獎勵信號。代理人的目標是使累計折扣報酬最大化,如下式所示:

代理通常由一組參數來參數化使得它能夠利用梯度優化使強化學習目標最大化。坡度關于策略參數通常是未知的,并且很難以分析形式獲得。因此,你不得不用樣本來近似它。利用非策略樣本估計梯度主要有兩種方法:半梯度法和重要性抽樣法。
半梯度
這些方法在梯度展開中減少了一個項,這導致了估計量的偏差。理論上,這個偏差項仍然足夠低,足以保證梯度收斂到正確的解。然而,當引入其他近似源(例如有限樣本或臨界近似)時,不能保證收斂到最優策略。在實踐中,經常會觀察到性能不佳。
重要性抽樣
這些方法都是基于重要性抽樣校正的。這種估計通常會受到高方差的影響,并且這種方差在強化學習環境中會被放大,因為它會隨著情節的長度而倍增。涉及重要性抽樣的技術需要已知的隨機策略和基于軌跡的數據(與環境的順序交互)。因此,在這種情況下,不允許不完整的數據或基于人的交互。
非參數非政策梯度估計
強化學習理論的一個重要組成部分是 Bellman 方程。 Bellman 方程遞歸地定義了以下值函數:

求梯度的一種方法是用非參數技術近似 Bellman 方程,并進行解析求解。具體來說,可以構造一個非參數的報酬函數和轉移函數模型。
通過增加采樣數和減少內核帶寬,您將向右收斂到無偏解。更準確地說,當方差縮小到零時,這個估計量是一致的。
非參數 Bellman 方程的求解涉及到一組線性方程組的求解,該方程組可以通過矩陣反演或共軛梯度等近似迭代方法獲得。這兩種方法都是重線性代數運算,因此適合與 GPUs 并行計算。
求解非參數 Bellman 方程后,梯度的計算變得非常簡單,可以使用自動微分工具,如 TensorFlow 或 PyTorch 來獲得。這些工具具有易于使用的 GPU 支持,與以前僅使用 CPU 的實現相比,這些工具已經被證明實現了相當大的加速。
特別是, IASL 團隊在配備了四個 NVIDIA V100 GPUs 的 NVIDIA DGX 站 上測試了 TensorFlow 和 PyTorch 兩種算法。由于 NVIDIA DGX 站提供的 20 個 NVIDIA 核有助于利用多處理技術進行多次評估,因此該機器非常適合于實證評估。有關實現代碼的更多信息,請參見 非參數政策外政策梯度 。
實證分析
為了評估 NOPG 相對于經典的非政策梯度方法的性能,例如深度確定性策略梯度,或具有重要抽樣校正的 G-POMDP ,團隊選擇了一些經典的低維控制任務:
線性二次型調節器
OpenAI 健身房秋千
手推車和電桿( Quanser 平臺)
OpenAI 健身山地車
我的團隊的分析表明,與最先進的技術相比,這種方法更具優勢。在表示為 NOPG-S 和 NOPG-D 的圖中,我們分別展示了隨機策略和確定性策略的算法:
PWIS (路徑重要性抽樣)
DPG ( deterministicpolicy gradient ),一種半梯度方法
DDPG ( deep deterministicy policy gradient ),在其經典的在線和離線模式下
該團隊使用 OpenAI 基線 對在線版本的 DDPG 進行編碼。
坡度的質量
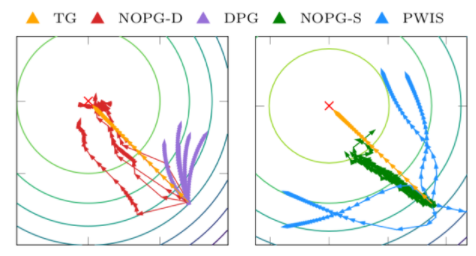
圖 1 LQR 任務中的梯度方向。與 DPG 技術相比,方差是有利的。
圖 1 描述了參數空間中的漸變方向。真梯度( TG )是理想的梯度方向。當 PWIS 的方差較大時, DPG 表現出較大的偏差,兩種方法都無法優化策略。相反,這種同時具有隨機和確定性策略的方法顯示出更好的偏差/方差權衡,并允許更好和一致的策略改進。
學習曲線
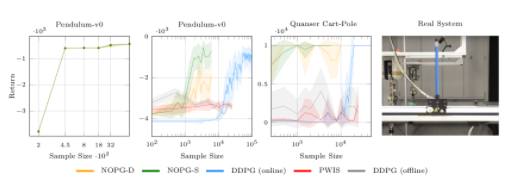
圖 2 該算法( NOPG-D , NOPG-S )比其他基線具有更好的采樣效率。在實際系統上,驗證了所學習策略對車輛穩定性的有效性。
圖 2 描述了算法關于一些經典基線的學習曲線。該算法使用較少的樣本,取得了較好的效果。 cartpole 的最終策略已經在一個真實的 cartpole 上進行了測試,如右圖所示。
從人類示范中學習
該算法可以處理基于人類的數據,而重要性抽樣技術并不直接適用。在這個實驗中,研究小組提供了次優的,人類演示的山地車任務軌跡。
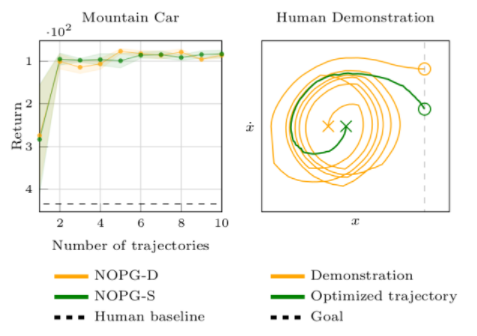
圖3 在左邊,提供了關于演示次數的算法學習曲線。該圖附有 95% 的置信區間。右邊是一個人類演示和隨后的政策在空間狀態下的表現的例子。
左邊的圖 3 顯示, NOPG 可以在只有兩個次優的演示或軌跡的情況下獲得一個有效的策略。然而,更大的數字有助于它學習稍微好一點的政策。右邊是一個人類演示的例子(橙色)和策略優化的結果(綠色)。人體在位置和速度空間的演示是次優的,因為它需要更多的步驟來達到目標位置。即使人類的演示是次優的,算法也能找到一個接近最優的策略。
今后的工作
博世人工智能中心 的一個應用是節流閥控制器。節流閥是用來調節流體或氣體流量的技術裝置。由于其復雜的動力學和物理約束,該裝置的控制具有挑戰性。
由于參數設置困難,設計最先進的控制器(如 PID 控制器)非常耗時。強化學習似乎特別適合這種應用。然而,政策外數據的可用性加上系統的低維性(系統可以用襟翼的角度和角速度來描述),使得它特別適合于 NOPG 方法。
結論
在這篇文章中,您研究了非政策梯度估計的問題。最先進的技術,如半梯度法和重要性抽樣法,往往不能提供一個可靠的估計。我討論了 NOPG ,它是在達姆施塔特的 智能自治系統( IAS ) 實驗室開發的。
在經典和低維任務(如 LQR 、擺起擺錘和 cartopole )上, NOPG 方法是樣本有效的,與基線相比安全(也就是說,它可以向人類專家學習)。雖然重要性抽樣不適用,但該方法也能從次優的人類演示數據中學習。然而,由于非參數方法不適用于高維問題,該算法僅限于低維任務。您可以研究深度學習技術的適用性,以允許降維,以及 Bellman 方程的不同近似值的使用,從而克服非參數技術的問題。
關于作者
Samuele Tosatto 是達姆施塔特理工大學的博士生。他的主要研究方向是將強化學習應用于現實世界的機器人技術。他認為,獲得更有效的學習算法對于縮短強化學習與實際機器人技術之間的差距至關重要。
審核編輯:郭婷
-
控制器
+關注
關注
114文章
17095瀏覽量
184133 -
機器人
+關注
關注
213文章
29718瀏覽量
212756 -
深度學習
+關注
關注
73文章
5561瀏覽量
122771
發布評論請先 登錄
NVIDIA Isaac Lab可用環境與強化學習腳本使用指南

18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現

嵌入式AI技術之深度學習:數據樣本預處理過程中使用合適的特征變換對深度學習的意義
詳解RAD端到端強化學習后訓練范式

高強度鋼點焊技術研究進展與應用前景

數字化轉型背景下的設備管理系統進化論

如何提高SMT生產效率
如何提高半導體設備防震基座的制造效率?







 工商網監
工商網監
評論