") 將NVIDIA Riva模型部署到生產(chǎn)中
將NVIDIA Riva模型部署到生產(chǎn)中

NVIDIA Riva 是一款 AI 語音 SDK ,用于開發(fā)實(shí)時(shí)應(yīng)用程序,如轉(zhuǎn)錄、虛擬助理和聊天機(jī)器人。它包括 NGC 中經(jīng)過預(yù)訓(xùn)練的最先進(jìn)模型、用于在您的領(lǐng)域中微調(diào)模型的 TAO 工具包以及用于高性能推理的優(yōu)化技能。 Riva 使使用 NGC 中的 Riva 容器或使用 Helm chart 在 Kubernetes 上部署模型變得更簡單。 Riva 技能由 NVIDIA TensorRT 提供支持,并通過 NVIDIA Triton 提供服務(wù)推理服務(wù)器。
配置 Riva
在設(shè)置 NVIDIA Riva 之前,請確保您的系統(tǒng)上已安裝以下設(shè)備:
Python [3 。 6 。 9]
docker ce 》 19 。 03 。 5
nvidia-DOCKR2 3 。 4 。 0-1 :Installation Guide
如果您按照第 2 部分中的說明進(jìn)行操作,那么您應(yīng)該已經(jīng)安裝了所有的先決條件。
設(shè)置 Riva 的第一步是到 install the NGC Command Line Interface Tool。
圖 1 。安裝 NGC CLI
要登錄到注冊表,您必須 get access to the NGC API Key。
圖 2 。獲取 NGCAPI 密鑰
設(shè)置好工具后,您現(xiàn)在可以從 NGC 上的Riva Skills Quick Start資源下載 Riva 。要下載該軟件包,可以使用以下命令(最新版本的命令可在前面提到的 Riva 技能快速入門資源中找到):

下載的軟件包具有以下資產(chǎn),可幫助您入門:
asr _ lm _工具:這些工具可用于微調(diào)語言模型。
nb _ demo _ speech _ api 。 ipynb :Riva 的入門筆記本。
Riva _ api-1 。 6 。 0b0-py3-none-any 。 whl和NeMo 2 Riva -1 。 6 。 0b0-py3-none-any 。 whl :安裝 Riva 的滾輪文件和將 NeMo 模型轉(zhuǎn)換為 Riva 模型的工具。有關(guān)更多信息,請參閱本文后面的Inferencing with your model部分。
快速啟動(dòng)腳本( Riva .*. sh , config 。 sh ):初始化并運(yùn)行 Triton 推理服務(wù)器以提供 Riva AI 服務(wù)的腳本。有關(guān)更多信息,請參閱配置 Riva 和部署您的模型。
示例:基于 gRPC 的客戶機(jī)代碼示例。
配置 Riva 并部署您的模型
你可能想知道從哪里開始。為了簡化體驗(yàn), NVIDIA 通過提供一個(gè)配置文件,使用 Riva AI 服務(wù)調(diào)整您可能需要調(diào)整的所有內(nèi)容,從而幫助您使用 Riva 定制部署。對于本演練,您依賴于特定于任務(wù)的 Riva ASR AI 服務(wù)。
對于本演練,我們只討論一些調(diào)整。因?yàn)槟皇褂?ASR ,所以可以安全地禁用 NLP 和 TTS 。

如果您遵循第 2 部分的內(nèi)容,可以將 use _ existing _ rmirs 參數(shù)設(shè)置為 true 。我們將在后面的文章中對此進(jìn)行詳細(xì)討論。

您可以選擇從模型存儲(chǔ)庫下載的預(yù)訓(xùn)練模型,以便在不進(jìn)行自定義的情況下運(yùn)行。

如果您在閱讀本系列第 2 部分時(shí)有 Riva 模型,請首先將其構(gòu)建為稱為 Riva 模型中間表示( RMIR )格式的中間格式。您可以使用 Riva Service Maker 來完成此操作。 ServiceMaker 是一組工具,用于聚合 Riva 部署到目標(biāo)環(huán)境所需的所有工件(模型、文件、配置和用戶設(shè)置)。
使用riva-build和riva-deploy命令執(zhí)行此操作。有關(guān)更多信息,請參閱Deploying Your Custom Model into Riva。

現(xiàn)在已經(jīng)設(shè)置了模型存儲(chǔ)庫,下一步是部署模型。雖然您可以這樣做manually,但我們建議您在第一次體驗(yàn)時(shí)使用預(yù)打包的腳本。快速啟動(dòng)腳本riva_init.sh和riva_start.sh是可用于使用config.sh中的精確配置部署模型的兩個(gè)腳本。

運(yùn)行riva_init.sh時(shí):
您在config.sh中選擇的模型的 RMIR 文件從指定目錄下的 NGC 下載。
對于每個(gè) RMIR 模型文件,將生成相應(yīng)的 Triton 推理服務(wù)器模型存儲(chǔ)庫。此過程可能需要一些時(shí)間,具體取決于所選服務(wù)的數(shù)量和型號(hào)。
要使用自定義模型,請將 RMIR 文件復(fù)制到config.sh(用于$riva_model_loc)中指定的目錄。要部署模型,請運(yùn)行riva_start.sh。riva-speech容器將與從所選存儲(chǔ)庫加載到容器的模型一起旋轉(zhuǎn)。現(xiàn)在,您可以開始發(fā)送推斷請求了。
使用您的模型進(jìn)行推斷
為了充分利用 NVIDIA GPU s , Riva 利用了 NVIDIA Triton 推理服務(wù)器和 NVIDIA TensorRT 。在會(huì)話設(shè)置中,應(yīng)用程序會(huì)優(yōu)化盡可能低的延遲,但為了使用更多的計(jì)算資源,必須增加批大小,即同步處理的請求數(shù),這自然會(huì)增加延遲。 NVIDIA Triton 可用于在多個(gè) GPU 上的多個(gè)模型上運(yùn)行多個(gè)推理請求,從而緩解此問題。
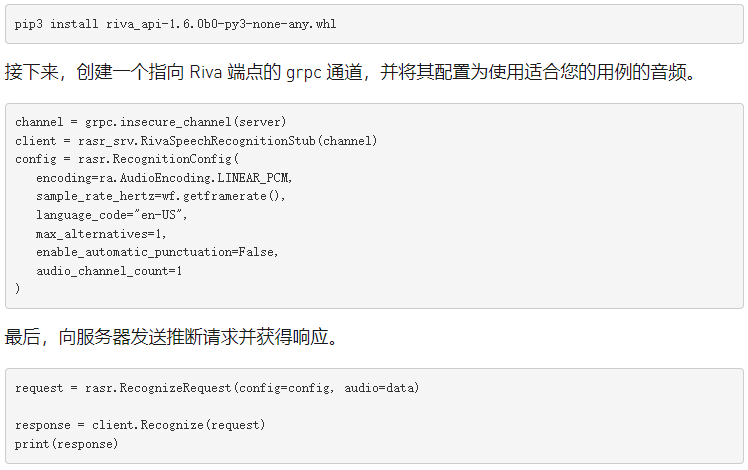
您可以使用 GRPCAPI 在三個(gè)主要步驟中查詢這些模型:導(dǎo)入 LIB 、設(shè)置 gRPC 通道和獲取響應(yīng)。
首先,導(dǎo)入所有依賴項(xiàng)并加載音頻。在這種情況下,您正在從文件中讀取音頻。我們在 examples 文件夾中還有一個(gè)流媒體示例。

要安裝所有 Riva 特定依賴項(xiàng),可以使用包中提供的。 whl 文件。
關(guān)鍵信息
此 API 可用于構(gòu)建應(yīng)用程序。您可以在單個(gè)裸機(jī)系統(tǒng)上安裝 Riva ,并開始本練習(xí),或者使用 Kubernetes 和提供的Helm chart進(jìn)行大規(guī)模部署。
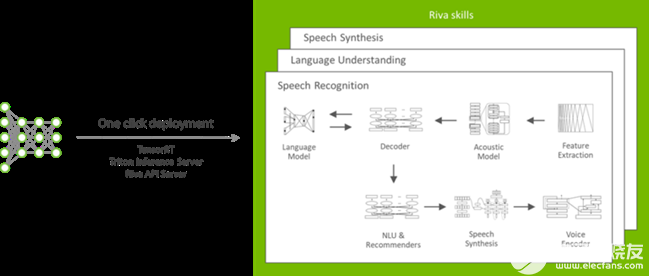
圖 3 。 NVIDIA Riva 的典型部署工作流
使用此舵圖,您可以執(zhí)行以下操作:
從 NGC 中提取 Riva 服務(wù) API 服務(wù)器、 Triton 推理服務(wù)器和其他必要的 Docker 映像。
生成 Triton 推理服務(wù)器模型庫,并啟動(dòng)英偉達(dá) Triton 服務(wù)器,并使用所選配置。
公開要用作 Kubernetes 服務(wù)的推理服務(wù)器和 Riva 服務(wù)器終結(jié)點(diǎn)。
結(jié)論
Riva 是一款用于開發(fā)語音應(yīng)用程序的端到端 GPU 加速 SDK 。在本系列文章中,我們討論了語音識(shí)別在行業(yè)中的重要性,介紹了如何在您的領(lǐng)域定制語音識(shí)別模型以提供世界級的準(zhǔn)確性,并向您展示了如何使用 Riva 部署可實(shí)時(shí)運(yùn)行的優(yōu)化服務(wù)。
關(guān)于作者
About Tanay Varshney
Tanay Varshney 是 NVIDIA 的一名深入學(xué)習(xí)的技術(shù)營銷工程師,負(fù)責(zé)廣泛的 DL 軟件產(chǎn)品。他擁有紐約大學(xué)計(jì)算機(jī)科學(xué)碩士學(xué)位,專注于計(jì)算機(jī)視覺、數(shù)據(jù)可視化和城市分析的橫斷面。
About Sirisha Rella
Sirisha Rella 是 NVIDIA 的技術(shù)產(chǎn)品營銷經(jīng)理,專注于計(jì)算機(jī)視覺、語音和基于語言的深度學(xué)習(xí)應(yīng)用。 Sirisha 獲得了密蘇里大學(xué)堪薩斯城分校的計(jì)算機(jī)科學(xué)碩士學(xué)位,是國家科學(xué)基金會(huì)大學(xué)習(xí)中心的研究生助理。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5308瀏覽量
106341 -
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7660瀏覽量
90748
發(fā)布評論請先 登錄
如何本地部署NVIDIA Cosmos Reason-1-7B模型
在env終端中勾選了tiflte support后燒錄mdk到板子上后就開始顯示連接不到,無法部署模型怎么解決?
如何使用Docker部署大模型
電機(jī)高效再制造在企業(yè)生產(chǎn)中的應(yīng)用
Cognizant將與NVIDIA合作部署神經(jīng)人工智能平臺(tái),加速企業(yè)人工智能應(yīng)用

英偉達(dá)GTC2025亮點(diǎn):NVIDIA認(rèn)證計(jì)劃擴(kuò)展至企業(yè)存儲(chǔ)領(lǐng)域,加速AI工廠部署
K230D部署模型失敗的原因?
如何部署OpenVINO?工具套件應(yīng)用程序?
NVIDIA推出面向RTX AI PC的AI基礎(chǔ)模型
NVIDIA Cosmos世界基礎(chǔ)模型平臺(tái)發(fā)布
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型
測徑儀 測測長儀是如何應(yīng)用在卷煙生產(chǎn)中的?
NVIDIA NIM助力企業(yè)高效部署生成式AI模型
借助NVIDIA NIM加速AI應(yīng)用部署
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論