 用生成模型來做圖像恢復的介紹和回顧
用生成模型來做圖像恢復的介紹和回顧
導讀
本文給出了圖像恢復的一般性框架,編解碼器 + GAN,后面的圖像復原基本都是這個框架。
本文會介紹圖像修復的目的,它的應用,等等。然后,我們將深入研究文獻中關于圖像修復的第一個生成模型(即第一個基于GAN的修復算法,上下文編碼器)。
目標
很簡單的!我們想要填補圖像中缺失的部分。
應用
移除圖像中不需要的部分(即目標移除)
修復損壞的圖像(可以擴展到修復電影)
很多其他應用!
術語
給出一個有一些缺失區域的圖像,我們定義
缺失像素/生成像素/空洞像素:待填充區域的像素。
有效像素/ground truth像素:和缺失像素含義相反。需要保留這些像素,這些像素可以幫助我們填補缺失的區域。
傳統方法
給出一個有一些缺失區域的圖像,最典型的傳統方法填充缺失區域是復制粘貼。
主要思想是從圖像本身或一個包含數百萬張圖像的大數據集中尋找最相似的圖像補丁,然后將它們粘貼到缺失的區域。
然而,搜索算法可能是耗時的,它涉及到手工設計距離的度量方法。在通用化和效率方面仍有改進的空間。
數據驅動的基于深度學習的方法
由于卷積神經網絡(Convolutional Neural Networks, CNNs)在圖像處理方面的成功,很多人開始將CNNs應用到自己的任務中。基于數據驅動的深度學習方法的強大之處在于,如果我們有足夠的訓練數據,我們就可以解決我們的問題。
如上所述,圖像修復就是將圖像中缺失的部分補上。這意味著我們想要生成一些不存在或沒有答案的東西。因此,所有基于深度學習的修復算法都使用生成對抗網絡(GANs)來產生視覺上吸引人的結果。為什么視覺上吸引人呢?由于沒有模型來回答生成的問題,人們更喜歡有良好視覺質量的結果,這是相當主觀的!
對于那些可能不知道GANs的讀者,我推薦你先去了解一下。這里以圖像修復為例,簡單地說,典型的GAN由一個生成器和一個鑒別器組成。生成器負責填補圖像中缺失的部分,鑒別器負責區分已填充圖像和真實圖像。請注意,真實的圖像是處于良好狀態的圖像(即沒有缺失的部分)。我們將隨機地將填充的圖像或真實的圖像輸入識別器來欺騙它。最終,如果鑒別器不能判斷圖像是被生成器填充的還是真實的圖像,生成器就能以良好的視覺質量填充缺失的部分!
第一個基于GAN的修復方法:上下文編碼器
在對image inpainting做了簡單的介紹之后,我希望你至少知道什么是image inpainting, GANs(一種生成模型)是inpainting領域常用的一種。現在,我們將深入研究本系列的第一篇論文。
Intention
作者想訓練一個CNN來預測圖像中缺失的像素。眾所周知,典型的CNNs(例如LeNet手寫數字識別和AlexNet圖像分類)包含許多的卷積層來提取特征,從簡單的結構特征到高級的語義特征(即早期層簡單的特征,比如邊緣,角點,到后面的層的更復雜的特征模式)。對于更復雜的功能模式,作者想利用學到的高層語義特征(也稱為隱藏特征)來幫助填充缺失的區域。
此外,為修復而學習的特征需要對圖像進行更深層次的語義理解。因此,學習到的特征對于其他任務也很有用,比如分類、檢測和語義分割。
背景
在此,我想為讀者提供一些背景信息,
Autoencoders:這是一種通常用于重建任務的CNN結構。由于其形狀,也有人稱之為沙漏結構模型。對于這個結構,輸出大小與輸入大小相同,我們實際上有兩個部分,一個是編碼器,另一個是解碼器。
編碼器部分用于特征編碼,針對輸入得到緊湊潛在的特征表示,而解碼器部分則對潛在特征表示進行解碼。我們通常把中間層稱為低維的“瓶頸”層,或者簡單地稱之為“瓶頸”,因此整個結構看起來就像一個沙漏。
讓我們想象一下,我們將一幅完好無損的圖像輸入到這個自動編碼器中。在這種情況下,我們期望輸出應該與輸入完全相同。這意味著一個完美的重建。如果可能的話,“瓶頸”是輸入的一個完美的緊湊潛在特征表示。
更具體地說,我們可以使用更少的數字來表示輸入(即更有效,它與降維技術有關)。因此,這個“瓶頸”包含了幾乎所有的輸入信息(可能包括高級語義特征),我們可以使用它來重構輸入。
上下文編碼器進行圖像生成
首先,輸入的是mask圖像(即有中心缺失的圖像)。輸入編碼器以獲得編碼后的特征。然后,本文的主要貢獻是在編碼特征和解碼特征之間放置通道全連接層,以獲得更好的語義特征(即“瓶頸”)。最后,解碼器利用“瓶頸”特征重建缺失的部分。讓我們來看看他們的網絡內部。
編碼器
編碼器使用AlexNet結構,他們用隨機初始化權值從頭開始訓練他們的網絡。
與原始的AlexNet架構和圖2所示的自動編碼器相比,主要的區別是中間的通道全連接層。如果網絡中只有卷積層,則無法利用特征圖上距離很遠的空間位置的特征。為了解決這個問題,我們可以使用全連接層,即當前層的每個神經元的值依賴于上一層的所有神經元的值。然而,全連接層會引入許多參數,8192x8192=67.1M,這甚至在GPU上也很難訓練,作者提出了通道全連接層來解決這個問題。
通道全連接層
實際上,通道全連接層非常簡單。我們只是完全獨立地連接每個通道而不是所有的通道。例如,我們有m個大小為n x n的特征映射。如果使用標準的全連接層,我們會有m2n?個參數,對于通道級的全連接層,我們只有mn?個參數。因此,我們可以在距離很遠的空間位置上捕獲特征,而不需要添加那么多額外的參數。
解碼器
對于解碼器來說,這只是編碼過程的反向。我們可以使用一系列的轉置卷積來獲得期望大小的重建圖像。
損失函數
本文使用的損失函數由兩項組成。第一項是重建損失(L2損失),它側重于像素級的重建精度(即PSNR方向的損失),但總是會導致圖像模糊。第二個是對抗損失,它通常用于GANs。它鼓勵真實圖像和填充圖像之間數據分布更接近。
對于那些對損失函數感興趣的讀者,我強烈推薦你們閱讀這篇論文中的方程。在這里,我只是口頭描述每個損失項。
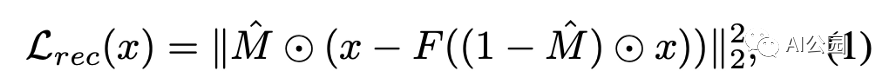
重建損失(L2損失),M表示缺失的區域(1表示缺失區域,0表示有效像素),F是生成器
L2損失:計算生成的像素與對應ground truth像素之間的L2距離(歐幾里得距離)。只考慮缺失區域。
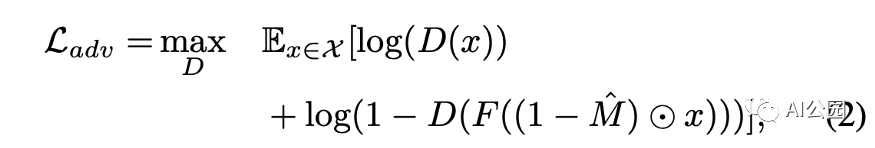
對抗損失,D是鑒別器。我們希望訓練出一種能夠區分填充圖像和真實圖像的鑒別器
對抗損失:對抗鑒別器的結構如圖4所示。鑒別器的輸出是一個二進制值0或1。如果輸入是真實圖像,則為1,如果輸入是填充圖像,則為0。
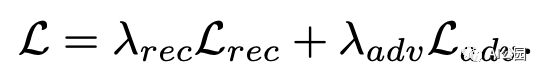
聯合損失,Lambda_rec為0.999,Lambda_adv為0.001
使用隨機梯度下降(SGD),Adam優化器交替訓練生成器和鑒別器。
實驗結果
評估使用了兩個數據集,即Paris Street View和ImageNet。
作者首先展示了修復結果,然后他們還表明,作為預訓練步驟,學習到的特征可以遷移到其他任務中。
語義修復
作者與傳統的最近鄰修復算法進行了比較。顯然,該方法優于最近鄰修復方法。
我們可以看到L2損失傾向于給出模糊的圖像(第二列)。L2 +對抗性的損失給更清晰的填充圖像。對于NN-Inpainting,他們只是復制和粘貼最相似的圖像補丁到缺失的區域。
特征學習
為了顯示他們學習到的特征的有用性,作者嘗試編碼不同的圖像patch,并根據編碼的特征得到最相似的patch。在圖7中。作者將其與傳統的HOG和典型的AlexNet進行了比較。它們實現了與AlexNet類似的表現,但AlexNet是在一百萬張標有數據集的圖像上預訓練的。
如表2所示,在ImageNet上預訓練過的模型具有最好的性能,但需要昂貴的標簽。在該方法中,上下文是用于訓練模型的監督。這就是他們所謂的通過修復圖像來學習特征。很明顯,它們學習到的特征表示與其他借助輔助監督訓練的模型相當,甚至更好。
總結
所提出的上下文編碼器訓練可以在上下文的條件下生成圖像。在語義修復方面達到了最先進的性能。
學習到的特征表示也有助于其他任務,如分類,檢測和語義分割。
要點
我想在這里強調一些要點。
對于圖像修復,我們必須使用來自有效像素的“提示”來幫助填充缺失的像素。“上下文”一詞是指對整個圖像本身的理解。
本文的主要貢獻是通道全連接層。其實,理解這一層并不難。對我來說,它是Non-Local Neural Networks或Self-Attention的早期版本/簡化版本。主要的一點是,前一層的所有特征位置對當前層的每個特征位置都有貢獻。從這個角度來看,我們對整個圖像的語義理解會更加深入。這個概念在后面的文章中被廣泛采用!
所有后來的修復論文都遵循了GAN-based結構(即編碼器-解碼器結構)。人們的目標是具有良好視覺質量的充滿圖像。
英文原文:https://medium.com/analytics-vidhya/introduction-to-generative-models-for-image-inpainting-and-review-context-encoders-13e48df30244
編輯:jq
-
解碼器
+關注
關注
9文章
1163瀏覽量
41704 -
編碼器
+關注
關注
45文章
3775瀏覽量
137161 -
GaN
+關注
關注
19文章
2177瀏覽量
76169 -
cnn
+關注
關注
3文章
354瀏覽量
22636
原文標題:用生成模型來做圖像恢復的介紹和回顧:上下文編碼器
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
利用NVIDIA 3D引導生成式AI Blueprint控制圖像生成
Gemini API集成Google圖像生成模型Imagen 3
如何使用離線工具od SPSDK生成完整圖像?
OptiSystem應用:真實圖像在光纖中傳輸后的恢復
企業AI模型托管怎么做的
AN-715::走近IBIS模型:什么是IBIS模型?它們是如何生成的?

借助谷歌Gemini和Imagen模型生成高質量圖像






 工商網監
工商網監
評論