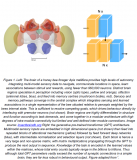
 MaX-DeepLab:雙路徑Transformer架構概覽
MaX-DeepLab:雙路徑Transformer架構概覽
全景分割是一個計算機視覺任務,會將語義分割(為每個像素分配類標簽)和實例分割(檢測和分割每個對象實例)合并。作為實際應用中的核心任務,全景分割通常使用多個代理 (Surrogate) 子任務(如使用邊界框檢測方法)粗略估計全景分割目標,來實現預測一組不相重疊的遮罩 (mask) 及其相對應的類別標簽(例如對象所屬的類別,如“汽車”、“交通指示燈”、“道路”等)。
在此代理樹中,每個子任務都會產生額外的手動設計模塊,如錨點設計規則、邊界框分配規則、非極大值抑制 (NMS)、thing-stuff(thing 類物體和 stuff 類物體)合并,等等。雖然對于單個子任務和模塊,不乏一些出色的解決方案,但當我們將這些子任務整合到一個流水線中進行全景分割時,就會產生不需要的構件,在一些比較棘手的情況下更是如此(例如,兩個具有相似邊界框的人都觸發 NMS,從而導致其中一個遮罩缺失)。
以往提出的 DETR 方法簡化邊界框檢測子任務成端到端操作來解決其中一些問題,事實證明,這種做法的計算效率更高,產生的無關構件也更少。然而,訓練過程在很大程度上仍然依賴邊界框檢測,這顯然與基于遮罩的全景分割定義不相符。另一種做法是將邊界框從管線中徹底移除,這樣做的好處是消除了整個子任務及其相關模塊和構件。例如,Axial-DeepLab預測預定義實例中心的像素偏移量時,如果圖像平面中有各種各樣的形狀,或相鄰對象的中心點較為接近,例如下面這張狗狗坐在椅子上的圖像,那它所使用的子任務則會遇到對象嚴重變形的挑戰。
當狗狗的中心和椅子的中心接近重合時,Axial-DeepLab 就會將它們合并成一個對象
在《MaX-DeepLab:利用遮罩 Transformer 實現端到端全景分割 (MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers)》(將提交給 CVPR 2021 大會)一文中,我們首次為全景分割管線提出了完全的端到端方法——將 Transformer架構擴展到此計算機視覺任務中,直接預測具有類標簽的遮罩。這種方法叫做 MaX-DeepLab,利用 Mask Xformer 對 Axial-DeepLab 進行擴展。該方法采用雙路徑架構,引入了全局內存路徑,允許與任何卷積層直接通信。MaX-DeepLab 最終在極具挑戰的COCO數據集上以及無邊界框的狀態下實現了 7.1% 的顯著全景質量 (PQ) 增益,首次消除了有邊界框方法和無邊界框方法之間的差距。在不增加測試時長的情況下,就 PQ 方面而言,MaX-DeepLab 在 COCO 測試開發集上達到了 51.3% 的水平,這已是目前的最高水準。
MaX-DeepLab 是完全端到端的:直接從圖像中預測全景分割遮罩
端到端全景分割
受 DETR 啟發,我們的模型使用經過 PQ 類目標優化的輸出遮罩和類,直接預測一組不相重疊的遮罩及其相應的語義標簽。具體來說,我們受到評估指標 PQ 的定義:識別質量(預測的類是否正確)乘以分割質量(預測的遮罩是否正確)的啟發,以一模一樣的方式在兩個具有類標簽的遮罩之間定義了一個相似度指標。直接通過一對一匹配,最大化實際遮罩和預測遮罩之間的這種相似度,直接對模型進行訓練。這種對全景分割的直接建模使端到端訓練和推理成為可能,消除了現有的有邊界框方法和無邊界框方法必須手工設計先驗的弊端。
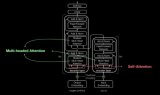
與卷積神經網絡 (CNN) 上堆疊傳統 Transformer 的方案不同,我們提出了一種結合 CNN 與 Transformer 的雙路徑框架。具體而言,我們通過一個雙路徑 Transformer 元件,使 CNN 層能夠從全局內存中讀寫數據。這里所說的這個元件采用了 CNN 路徑和內存路徑之間的所有四種注意力 (Attention) 類型,可以插入到 CNN 中的任意位置,從而允許在任何層與全局內存通信。MaX-DeepLab 還利用堆疊的沙漏式解碼器,可將多種尺度特征聚合成高分辨率輸出。然后系統會將該輸出與全局內存特征相乘,形成遮罩組預測。至于遮罩類別,則使用另一種 Transformer 進行預測。
雙路徑 Transformer 架構概覽
結果
我們在極具挑戰性的 COCO 全景分割數據集上,分別使用先進的無邊界框方法 (Axial-DeepLab) 和有邊界框方法 (DetectoRS) 對 MaX-DeepLab 進行了評估。在不增加測試時長的情況下,就 PQ 方面而言,MaX-DeepLab 在 COCO 測試開發集上達到了 51.3% 的水平,這已是目前的最高水準。
在無邊界框狀態下,就 PQ 方面而言,這一結果比 Axial-DeepLab 高出 7.1%,比 DetectoRS 高出 1.7%,第一次消除了有邊界框方法和無邊界框方法之間的差距。為了與 DETR 進行一致的比較,我們還評估了與 DETR 參數數量和算力均一致的輕量級 MaX-DeepLab 版本。就 PQ 方面而言,此輕量級 MaX-DeepLab 在 val 集上的表現優于 DETR 3.3%,在測試開發集上的表現優于 DETR 3.0%。此外,我們還對端到端表達式、模型伸縮、雙路徑架構和損失函數進行了廣泛的消融研究和分析。此外,MaX-DeepLab 也不像 DETR 一樣需要超長訓練計劃。
MaX-DeepLab 正確地分割了一只坐在椅子上的狗。Axial-DeepLab依賴于回歸對象中心偏移量的代理任務。它之所以失敗,是因為狗和椅子的中心太過于接近。作為代理任務,DetectoRS 會將對象的邊界框而非遮罩進行分類。由于椅子的邊界框置信度較低,所以就被濾除了。
關于 MaX-DeepLab 和先進的無邊界框及有邊界框方法的案例研究
還有一個例子可以證明 MaX-DeepLab 可以在充滿挑戰的條件下正確分割圖像。
MaX-DeepLab 正確分割了相互重疊的斑馬。此例對于其他方法也非常具有挑戰性,因為這兩只斑馬的邊界框很相似,對象的中心也很接近
結論
我們首次證明了全景分割可以進行端到端訓練。MaX-DeepLab 使用遮罩 Transformer 直接預測遮罩和類,消除了手工設計對于經驗的依賴,如對象邊界框、thing-stuff(thing 類物體和 stuff 類物體)合并等。借助 PQ 式損失函數和雙路徑 Transformer,MaX-DeepLab 在極具挑戰性的 COCO 數據集上取得了最高水準的結果,消除了有邊界框方法和無邊界框方法之間的差距。
原文標題:MaX-DeepLab:用于端到端全景分割的雙路徑 Transformer
文章出處:【微信公眾號:TensorFlow】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
計算機視覺
+關注
關注
9文章
1706瀏覽量
46536 -
tensorflow
+關注
關注
13文章
330瀏覽量
60994
原文標題:MaX-DeepLab:用于端到端全景分割的雙路徑 Transformer
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何使用MATLAB構建Transformer模型

transformer專用ASIC芯片Sohu說明

Transformer是機器人技術的基礎嗎

自動駕駛中一直說的BEV+Transformer到底是個啥?

英偉達推出歸一化Transformer,革命性提升LLM訓練速度
康謀分享 | AD/ADAS的性能概覽:在AD/ADAS的開發與驗證中“大海撈針”!

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
Transformer能代替圖神經網絡嗎
Transformer語言模型簡介與實現過程
Transformer架構在自然語言處理中的應用
使用PyTorch搭建Transformer模型
Transformer 能代替圖神經網絡嗎?






 工商網監
工商網監
評論