 浙大團隊研發基于單目視頻的三維場景重建框架NeuralRecon
浙大團隊研發基于單目視頻的三維場景重建框架NeuralRecon
最近,iPad 和 iPhone 上的 LiDAR 有了新玩法,Apple Clips 應用程序中更新了基于三維重建的 AR 空間特效。通過 Clips 3.1 的 AR 空間功能,用戶只需用帶有 LiDAR 傳感器的 iPad Pro 或 iPhone Pro 在房間中進行掃描和重建,就能為拍攝的視頻中添加絢麗的 AR 效果。
比如跟著 AR 投射出來的燈光跳舞;
再比如用 Star Walk 2 的 AR 功能,足不出戶在房間屋頂上觀看星座。
不過要實現上述視頻中的效果,需要 iPad 和 iPhone 高端型號上配備的 LiDAR 深度傳感器,而使用浙江大學-商湯三維視覺聯合實驗室所提出的方法,希望能讓普通手機的單目攝像頭也可實現上述效果。
實驗室成員周曉巍接受了我們的采訪。他是國內計算機視覺領域青年學者、也是浙江大學計算機輔助設計與圖形學國家重點實驗室的“百人計劃” 研究員和博士生導師。幾年前,在結束美國賓夕法尼亞大學 GRASP 機器人實驗室的博士后研究后,回到母校任教。他告訴 DeepTech:“目前我們跟商湯、華為都有非常緊密的合作,通過這種產學研的結合,我們的研究成果既有對學術前沿的探索,又能根據實際需求去攻克一些技術瓶頸。與此同時,國內的 3D 視覺領域還處于新興發展階段,也需要我們回來一起把這個方向給發展壯大起來,不斷縮短與國際領先水平之間的差距。”
周曉巍所在的團隊提出了一種基于單目視頻的三維場景重建框架 NeuralRecon。在實時 (25 FPS) 的速度下,使用該方法可高質量地重建三維場景。對比結果顯示,在 ScanNet、7-Scenes 等數據集上,NeuralRecon 的速度和精度均大幅領先以往方法。該工作將發表于今年的計算機視覺頂級會議 CVPR,并錄用為口頭報告。
據其表示,NeuralRecon 提出了用神經網絡、直接回歸基于 TSDF 表示的局部三維表面,并能使用基于 GRU 的 TSDF 融合模塊,來融合歷史局部表面的特征。這樣設計的好處是,網絡不僅能直接學習到三維表面的局部光滑性先驗并借此實現準確且一致的重建,還可以減少以往方法中重復冗余的計算量,在保持質量的前提下實現實時的重建。據該團隊所知,這是首個基于深度學習方法、并能實時重建稠密且一致三維表面的系統。
問題和挑戰:基于圖像的實時場景的三維重建依然任重道遠
一直以來,稠密場景重建都是三維視覺的核心問題,在增強現實(AR)等應用中,扮演著重要角色。在 AR 應用中,要想實現真實、沉浸式的虛實融合體驗,就需要正確處理真實場景和虛擬的AR物體之間的遮擋關系,并對陰影等效果做出正確的渲染,如此才能實現合理的虛擬內容放置、以及它和與真實場景的交互。概括來說,要想實現這些效果,都得對場景進行實時且精確的三維重建。
三維重建需要依賴精確的六自由度相機位姿估計。最近幾年,視覺慣性 SLAM 逐漸成熟,且已得到大范圍的落地應用。ARKit 和 ARCore 等 AR 框架的出現,讓多數智能手機都能準確跟蹤其自身六自由度的姿態。
然而,基于圖像的實時場景的三維重建依然任重道遠。目前常用的三維重建方案如 KinectFusion、BundleFusion 等,非常依賴深度傳感器提供的深度測量。但是,由于深度傳感器價格昂貴、功耗也比較高,因此其普及程度依然較低,通常只有少數高端型號的移動設備才舍得配備。因此,使用單目多視角圖像去實現實時三維重建,具有非常大的應用前景。在不增加傳感器的前提下,它可直接用在現有智能設備中。
而在基于多視角圖像的三維重建方法中,基于深度圖融合的方法非常流行。可是,這種方法存在兩個問題:
第一,其中有大量重復計算,從相鄰幀之間,可以看到相鄰區域中有大面積的重合,同一區域的深度則會被計算多次,這會帶來計算量上的冗余;第二,即便相鄰兩幀能看到的區域有較大重合,每一幀深度圖的計算卻都得重新開始,而非基于之前相鄰幀的深度預測結果。
如下圖所示,這會導致計算出來的相鄰兩幀的深度圖不一致,重建的結果也因此常會非常分散,甚至會產生分層。
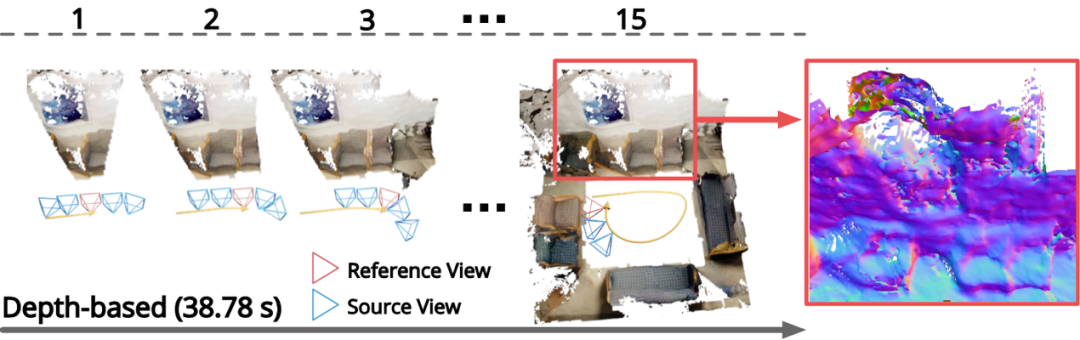
圖 | 基于深度圖融合方法的重建效果
NeuralRecon:新型三維場景重建框架
為解決上述痛點,該團隊提出這一新型三維場景重建框架 NeuralRecon,下圖展示了它的算法流程。這是一個輕量級的實時端到端系統,可直接從已知相機位姿的多視角圖像中,重建基于稀疏 TSDF 表示的三維場景幾何信息。
NeuralRecon 主要有如下兩個步驟,第一步是關鍵幀的選擇。
關鍵幀選擇的目的,是為了在提供足夠運動視差的同時,還能保持多視角的共視關系,因此所選關鍵幀之間的距離,不能太近也不能太遠。具體來說, 假如一個新傳入的幀和上一個關鍵幀的相對平移大于 t [max],并且相對旋轉角度大于 R [max],那么就可選擇該幀作為關鍵幀。而具備 N 個關鍵幀的窗口,可被定義為一個片段。
第二步是聯合片段重建和融合,其中涉及三個分步驟。
第一個分步驟是圖片特征提取和反投影,這里指的是某個視頻片段中的 N 張圖片,最初會通過一個 CNN 網絡來提取多個分辨率下的圖像深度特征。而圖片特征會反投影到三維空間中,得到三維特征體。
第二個分步驟是從粗到細的三維場景重建。采取從粗到細的方式,分階段地預測并細化場景的幾何信息。在每個階段中,稀疏三維卷積神經網絡會被用來處理三維特征體,最終通過一個多層感知機 (MLP),獲悉占有分數 (Occupancy score) 和 TSDF 值。
其中,占有分數代表著三維特征體中體素在 TSDF 截斷距離之內的概率。在每個階段的最后,占有分數小于閾值的體素,都會被定為空、并會被除掉。而在稀疏化之后,稀疏三維特征體會被上采樣。下圖是稀疏 TSDF 表示的可視化。
圖 | 稀疏 TSDF 表示示意圖
第三個分步驟是基于 GRU 的融合,這一步的目的,在于讓片段的重建之間得以保持一致,希望當前片段的重建可建立在歷史片段重建結果的基礎上。
具體來說,該方法提出了一個基于 GRU 的聯合重建與融合模塊。在每個階段,三維特征體都會首先通過一個三維稀疏卷積,并進行三維幾何特征提取。然后,三維幾何特征會被輸入進 GRU 聯合重建與融合模塊。該模塊會將三維幾何特征與在歷史片段重建中獲得的隱變量進行融合,并通過一個全局感知機回歸 TSDF 和占有分數。
直觀地說,這里的 GRU 作為一種基于學習的選擇性注意機制,可取代傳統 TSDF 融合中的線性操作。在后續的步驟中,因為GRU 進行了聯合重建與融合的操作,所以會直接將回歸的 TSDF 替換對應區域的全局 TSDF,最終的重建結果可以從更新后的全局 TSDF 中通過 Marching Cubes 算法獲得。
兩大優勢:重建結果具有一致性、重建過程用時更短
根據實驗結果,作者們做出了可視效果的對比圖。
對比可知,相比較傳統的基于深度圖的方法,NeuralRecon 主要有兩方面優勢:
其一,重建結果具有一致性;其二,重建過程用時更短。
作者們在 ScanNet 數據集上,將本次方法和當前最好的方法做定量對比。對比發現,本次方法在 F-score 上和速度上,都能超過此前方法,并能做到實時且精確的估計。
與此前最快的方法 MVDepthNet 比較,本次方法不僅速度略有領先,F-score 也從 0.329 提到了 0.562。相比此前精度最高的方法 COLMAP,本次方法在精度稍勝一籌的情況下,處理每個關鍵幀所需時間也從 2076ms 降至 30ms。
結語:NeuralRecon 為基于深度學習的三維感知系統打開新的可能性
概括來說,NeuralRecon 的核心思想,在于對每個視頻片段的可視區域進行增量式的聯合重建和聯合融合。這個設計讓 NeuralRecon 能實時輸出精確、且具有一致性的三維表面。
展望未來,使用 NeuralRecon 重建的稀疏 TSDF 表示能直接用于三維語義分割、三維目標檢測和可微渲染等下游任務。借助與下游任務的端到端聯合訓練,NeuralRecon 可為基于深度學習的三維感知系統提供出新的可能性。
原文標題:浙大團隊研發新型三維重建框架NeuralRecon,是首個基于深度學習的實時單目三維場景重建系統 | 專訪
文章出處:【微信公眾號:DeepTech深科技】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
Ar
+關注
關注
25文章
5147瀏覽量
172185 -
深度學習
+關注
關注
73文章
5557瀏覽量
122569
原文標題:浙大團隊研發新型三維重建框架NeuralRecon,是首個基于深度學習的實時單目三維場景重建系統 | 專訪
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用DLP LightCrafter4500投影結構光進行三維重建遇到的疑問求解
三維測量在醫療領域的應用
三維測量技術在工業中的應用
三維掃描與建模的區別 三維掃描在工業中的應用
CASAIM與東北大學達成合作,三維掃描技術助力異形建材模型重建及尺寸精準分析

CASAIM與邁普醫學達成合作,三維掃描技術助力醫療輔具實現高精度三維建模和偏差比對
建筑物邊緣感知和邊緣融合的多視圖立體三維重建方法

數字孿生三維可視化場景如何搭建?
中國研發出新型三維電壓成像新技術

留形科技借助NVIDIA平臺提供高效精確的三維重建解決方案
泰來三維|三維掃描技術在虛擬博物館建設中的應用
基于大模型的仿真系統研究一——三維重建大模型
泰來三維 三維掃描在文物保護中的應用場景






 工商網監
工商網監
評論