") PB級(jí)分析型數(shù)據(jù)庫ClickHouse的應(yīng)用場(chǎng)景和特性等分享
PB級(jí)分析型數(shù)據(jù)庫ClickHouse的應(yīng)用場(chǎng)景和特性等分享
在百花齊放的交互式分析領(lǐng)域,ClickHouse 絕對(duì)是后起之秀,它雖然年輕,卻有非常大的發(fā)展空間。本文將分享 PB 級(jí)分析型數(shù)據(jù)庫 ClickHouse 的應(yīng)用場(chǎng)景、整體架構(gòu)、眾多核心特性等,幫助理解 ClickHouse 如何實(shí)現(xiàn)極致性能的存儲(chǔ)引擎,希望與大家一起交流。
一、交互式分析之 ClickHouse
1. 交互式分析簡(jiǎn)介
交互式分析,也稱 OLAP(Online Analytical Processing),它賦予用戶對(duì)海量數(shù)據(jù)進(jìn)行多維度、交互式的統(tǒng)計(jì)分析能力,以充分利用數(shù)據(jù)的價(jià)值進(jìn)行量化運(yùn)營、輔助決策等,幫助用戶提高生產(chǎn)效率。
交互式分析主要應(yīng)用于統(tǒng)計(jì)報(bào)表、即席查詢(Ad Hoc)等領(lǐng)域,前者查詢模式較固定,后者即興進(jìn)行探索分析。代表場(chǎng)景例如:移動(dòng)互聯(lián)網(wǎng)中 PV、UV、活躍度等典型實(shí)時(shí)報(bào)表;互聯(lián)網(wǎng)內(nèi)容領(lǐng)域中人群洞察、關(guān)聯(lián)分析等即席查詢。
交互式分析是數(shù)據(jù)分析的一種重要方式,與離線分析、流式分析、檢索分析一起,共同組成完整的數(shù)據(jù)分析解決方案,在互聯(lián)網(wǎng)、物聯(lián)網(wǎng)快速發(fā)展的背景下,從不同維度滿足用戶對(duì)海量數(shù)據(jù)的全方位分析需求。 相比專注于事務(wù)處理的傳統(tǒng)關(guān)系型數(shù)據(jù)庫,交互式分析解決了 PB 級(jí)數(shù)據(jù)分析帶來的性能、擴(kuò)展性問題。 相比離線分析長(zhǎng)達(dá) T + 1 的時(shí)效性、流式分析較為固定的分析模式、檢索分析受限的分析性能,交互式分析的分鐘級(jí)時(shí)效性、靈活多維度的分析能力、超高性能的掃描分析性能,可以大幅度提高數(shù)據(jù)分析的效率,拓展數(shù)據(jù)分析的應(yīng)用范圍。
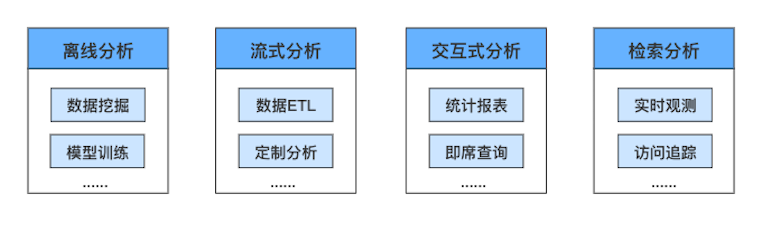
從數(shù)據(jù)訪問特性角度來看,交互式分析場(chǎng)景具有如下典型特點(diǎn):
大多數(shù)訪問是讀請(qǐng)求。
寫入通常為追加寫,較少更新、刪除操作。
讀寫不關(guān)注事務(wù)、強(qiáng)一致等特性。
查詢通常會(huì)訪問大量的行,但僅部分列是必須的。
查詢結(jié)果通常明顯小于訪問的原始數(shù)據(jù),且具有可理解的統(tǒng)計(jì)意義。
2. 百花齊放下的 ClickHouse
近十年,交互式分析領(lǐng)域經(jīng)歷了百花齊放式的發(fā)展,大量解決方案爆發(fā)式涌現(xiàn),尚未有產(chǎn)品達(dá)到類似 Oracle / MySQL 在關(guān)系型數(shù)據(jù)庫領(lǐng)域中絕對(duì)領(lǐng)先的狀態(tài)。 業(yè)界提出的開源或閉源的交互式解決方案,主要從大數(shù)據(jù)、NoSQL 兩個(gè)不同的方向進(jìn)行演進(jìn),以期望提供用戶最好的交互式分析體驗(yàn)。下圖所示是不同維度下的代表性解決方案,供大家參考了解:
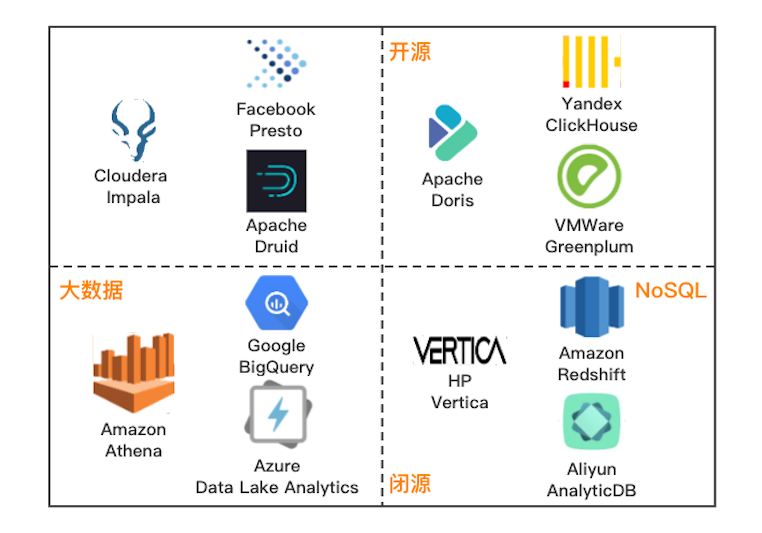
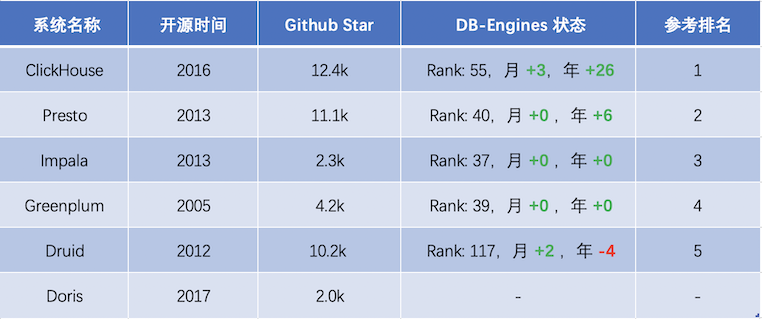
其中,ClickHouse 作為一款 PB 級(jí)的交互式分析數(shù)據(jù)庫,最初是由號(hào)稱 “ 俄羅斯 Google ” 的 Yandex 公司開發(fā),主要作為世界第二大 Web 流量分析平臺(tái) Yandex.Metrica(類 Google Analytic、友盟統(tǒng)計(jì))的核心存儲(chǔ),為 Web 站點(diǎn)、移動(dòng) App 實(shí)時(shí)在線的生成流量統(tǒng)計(jì)報(bào)表。 自 2016 年開源以來,ClickHouse 憑借其數(shù)倍于業(yè)界頂尖分析型數(shù)據(jù)庫的極致性能,成為交互式分析領(lǐng)域的后起之秀,發(fā)展速度非常快,Github 上獲得 12.4K Star,DB-Engines 排名近一年上升 26 位,并獲得思科、Splunk、騰訊、阿里等頂級(jí)企業(yè)的采用[1]。下面是 ClickHouse 及其他開源 OLAP 產(chǎn)品的發(fā)展趨勢(shì)統(tǒng)計(jì):
性能是衡量 OLAP 數(shù)據(jù)庫的關(guān)鍵指標(biāo),我們可以通過 ClickHouse 官方測(cè)試結(jié)果[2] 感受下 ClickHouse 的極致性能,其中綠色代表性能最佳,紅色代表性能較差,紅色越深代表性能越弱。 從測(cè)試結(jié)果看,ClickHouse 幾乎在所有場(chǎng)景下性能都最佳,并且從所有查詢整體看,ClickHouse 領(lǐng)先圖靈獎(jiǎng)得主 Michael Stonebraker 所創(chuàng)建的 Vertica 達(dá) 6 倍,領(lǐng)先 Greenplum 達(dá)到 18 倍。
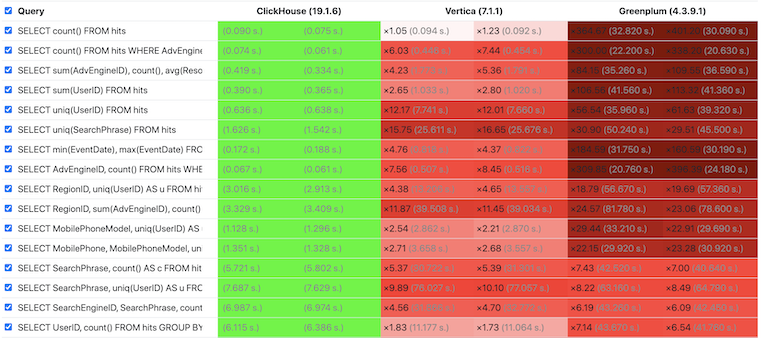
更多測(cè)試結(jié)果可參考 OLAP 系統(tǒng)第三方評(píng)測(cè)[3] ,盡管該測(cè)試使用了無索引的表引擎(或稱表類型),ClickHouse 仍然在單表模式下體現(xiàn)了強(qiáng)勁的領(lǐng)先優(yōu)勢(shì)。
二、ClickHouse 架構(gòu)
1. 集群架構(gòu)
ClickHouse 采用典型的分組式的分布式架構(gòu),具體集群架構(gòu)如下圖所示:
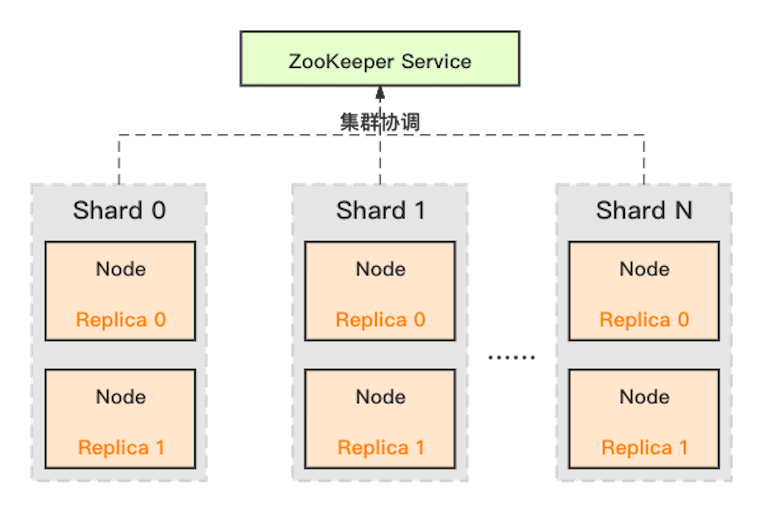
Shard :集群內(nèi)劃分為多個(gè)分片或分組(Shard 0 … Shard N),通過 Shard 的線性擴(kuò)展能力,支持海量數(shù)據(jù)的分布式存儲(chǔ)計(jì)算。
Node :每個(gè) Shard 內(nèi)包含一定數(shù)量的節(jié)點(diǎn)(Node,即進(jìn)程),同一 Shard 內(nèi)的節(jié)點(diǎn)互為副本,保障數(shù)據(jù)可靠。ClickHouse 中副本數(shù)可按需建設(shè),且邏輯上不同 Shard 內(nèi)的副本數(shù)可不同。
ZooKeeper Service :集群所有節(jié)點(diǎn)對(duì)等,節(jié)點(diǎn)間通過 ZooKeeper 服務(wù)進(jìn)行分布式協(xié)調(diào)。
2. 數(shù)據(jù)模型
ClickHouse 采用經(jīng)典的表格存儲(chǔ)模型,屬于結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)系統(tǒng)。我們分別從面向用戶的邏輯數(shù)據(jù)模型和面向底層存儲(chǔ)的物理數(shù)據(jù)模型進(jìn)行介紹。
(1)邏輯數(shù)據(jù)模型
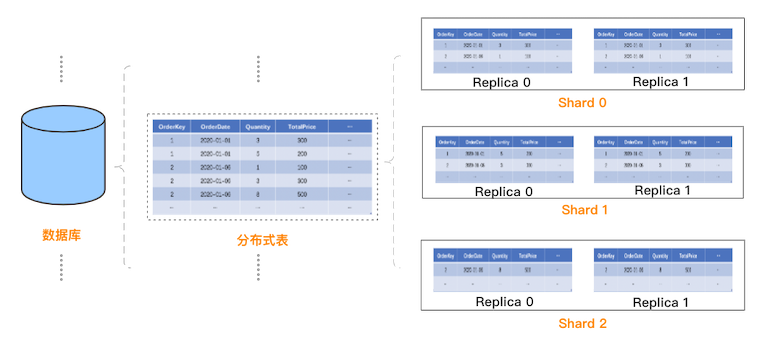
從用戶使用角度看,ClickHouse 的邏輯數(shù)據(jù)模型與關(guān)系型數(shù)據(jù)庫有一定的相似:一個(gè)集群包含多個(gè)數(shù)據(jù)庫,一個(gè)數(shù)據(jù)庫包含多張表,表用于實(shí)際存儲(chǔ)數(shù)據(jù)。 與傳統(tǒng)關(guān)系型數(shù)據(jù)庫不同的是,ClickHouse 是分布式系統(tǒng),如何創(chuàng)建分布式表呢?ClickHouse 的設(shè)計(jì)是:先在每個(gè) Shard 每個(gè)節(jié)點(diǎn)上創(chuàng)建本地表(即 Shard 的副本),本地表只在對(duì)應(yīng)節(jié)點(diǎn)內(nèi)可見;然后再創(chuàng)建分布式表,映射到前面創(chuàng)建的本地表。這樣用戶在訪問分布式表時(shí),ClickHouse 會(huì)自動(dòng)根據(jù)集群架構(gòu)信息,把請(qǐng)求轉(zhuǎn)發(fā)給對(duì)應(yīng)的本地表。創(chuàng)建分布式表的具體樣例如下:
# 首先,創(chuàng)建本地表CREATE TABLE table_local ON CLUSTER cluster_test( OrderKey UInt32, # 列定義 OrderDate Date, Quantity UInt8, TotalPrice UInt32, ……)ENGINE = MergeTree() # 表引擎PARTITION BY toYYYYMM(OrderDate) # 分區(qū)方式ORDER BY (OrderDate, OrderKey); # 排序方式SETTINGS index_granularity = 8192; # 數(shù)據(jù)塊大小 # 然后,創(chuàng)建分布式表CREATE TABLE table_distribute ON CLUSTER cluster_test AS table_localENGINE = Distributed(cluster_test, default, table_local, rand()) # 關(guān)系映射引擎 其中部分關(guān)鍵概念介紹如下,分區(qū)、數(shù)據(jù)塊、排序等概念會(huì)在物理存儲(chǔ)模型部分展開介紹:
MergeTree :ClickHouse 中使用非常多的表引擎,底層采用 LSM Tree 架構(gòu),寫入生成的小文件會(huì)持續(xù) Merge。
Distributed :ClickHouse 中的關(guān)系映射引擎,它把分布式表映射到指定集群、數(shù)據(jù)庫下對(duì)應(yīng)的本地表上。
更直觀的,ClickHouse 中的邏輯數(shù)據(jù)模型如下:
(2)物理存儲(chǔ)模型
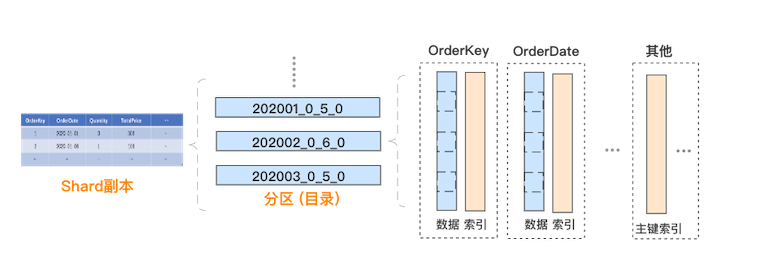
接下來,我們來介紹每個(gè)分片副本內(nèi)部的物理存儲(chǔ)模型,具體如下:
數(shù)據(jù)分區(qū):每個(gè)分片副本的內(nèi)部,數(shù)據(jù)按照 PARTITION BY 列進(jìn)行分區(qū),分區(qū)以目錄的方式管理,本文樣例中表按照時(shí)間進(jìn)行分區(qū)。
列式存儲(chǔ):每個(gè)數(shù)據(jù)分區(qū)內(nèi)部,采用列式存儲(chǔ),每個(gè)列涉及兩個(gè)文件,分別是存儲(chǔ)數(shù)據(jù)的 .bin 文件和存儲(chǔ)偏移等索引信息的 .mrk2 文件。
數(shù)據(jù)排序:每個(gè)數(shù)據(jù)分區(qū)內(nèi)部,所有列的數(shù)據(jù)是按照 ORDER BY 列進(jìn)行排序的。可以理解為:對(duì)于生成這個(gè)分區(qū)的原始記錄行,先按 ORDER BY 列進(jìn)行排序,然后再按列拆分存儲(chǔ)。
數(shù)據(jù)分塊:每個(gè)列的數(shù)據(jù)文件中,實(shí)際是分塊存儲(chǔ)的,方便數(shù)據(jù)壓縮及查詢裁剪,每個(gè)塊中的記錄數(shù)不超過 index_granularity,默認(rèn) 8192。
主鍵索引:主鍵默認(rèn)與 ORDER BY 列一致,或?yàn)?ORDER BY 列的前綴。由于整個(gè)分區(qū)內(nèi)部是有序的,且切割為數(shù)據(jù)塊存儲(chǔ),ClickHouse 抽取每個(gè)數(shù)據(jù)塊第一行的主鍵,生成一份稀疏的排序索引,可在查詢時(shí)結(jié)合過濾條件快速裁剪數(shù)據(jù)塊。
三、ClickHouse核心特性
ClickHouse 為什么會(huì)有如此高的性能,獲得如此快速的發(fā)展速度?下面我們來從 ClickHouse 的核心特性角度來進(jìn)一步介紹。
1. 列存儲(chǔ)
ClickHouse 采用列存儲(chǔ),這對(duì)于分析型請(qǐng)求非常高效。一個(gè)典型且真實(shí)的情況是:如果我們需要分析的數(shù)據(jù)有 50 列,而每次分析僅讀取其中的 5 列,那么通過列存儲(chǔ),我們僅需讀取必要的列數(shù)據(jù),相比于普通行存,可減少 10 倍左右的讀取、解壓、處理等開銷,對(duì)性能會(huì)有質(zhì)的影響。
這是分析場(chǎng)景下,列存儲(chǔ)數(shù)據(jù)庫相比行存儲(chǔ)數(shù)據(jù)庫的重要優(yōu)勢(shì)。這里引用 ClickHouse 官方一個(gè)生動(dòng)形象的動(dòng)畫,方便大家理解:
行存儲(chǔ):從存儲(chǔ)系統(tǒng)讀取所有滿足條件的行數(shù)據(jù),然后在內(nèi)存中過濾出需要的字段,速度較慢:
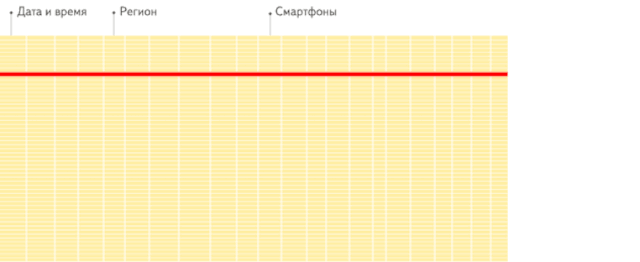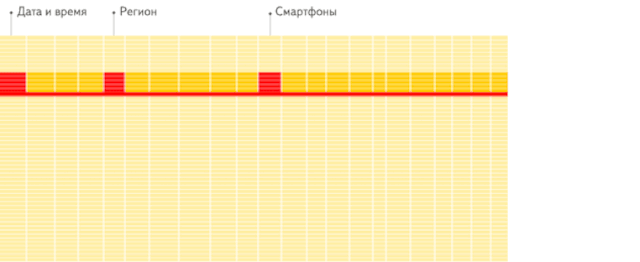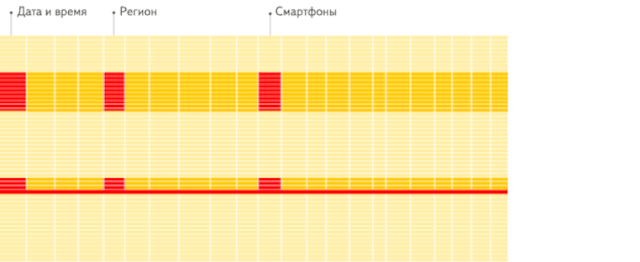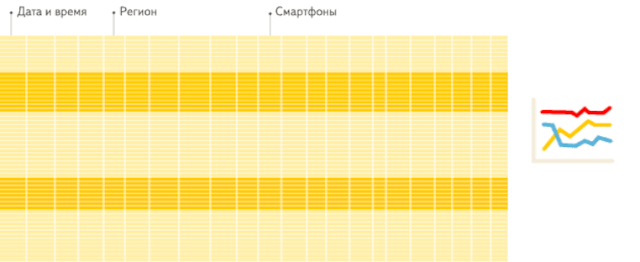
列存儲(chǔ):僅從存儲(chǔ)系統(tǒng)中讀取必要的列數(shù)據(jù),無用列不讀取,速度非常快:
2. 向量化執(zhí)行
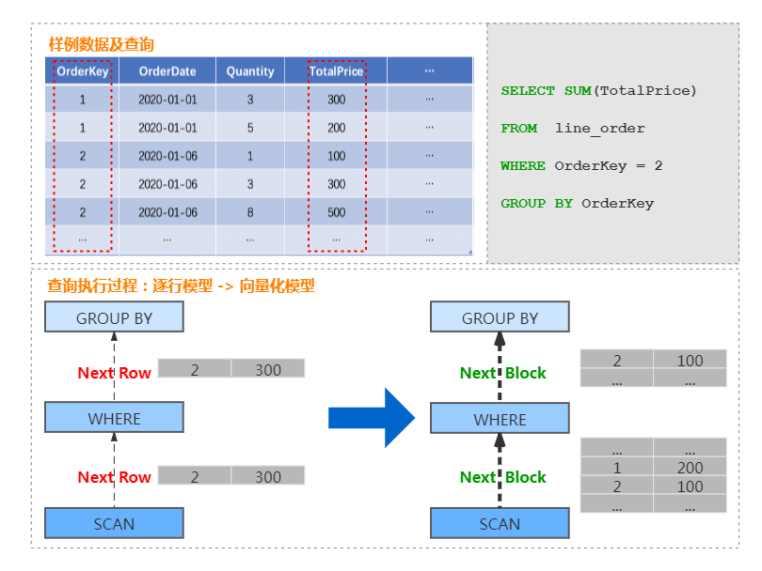
在支持列存的基礎(chǔ)上,ClickHouse 實(shí)現(xiàn)了一套面向向量化處理 的計(jì)算引擎,大量的處理操作都是向量化執(zhí)行的。 相比于傳統(tǒng)火山模型中的逐行處理模式,向量化執(zhí)行引擎采用批量處理模式,可以大幅減少函數(shù)調(diào)用開銷,降低指令、數(shù)據(jù)的 Cache Miss,提升 CPU 利用效率。并且 ClickHouse 可利用 SIMD 指令進(jìn)一步加速執(zhí)行效率。這部分是 ClickHouse 優(yōu)于大量同類 OLAP 產(chǎn)品的重要因素。 以商品訂單數(shù)據(jù)為例,查詢某個(gè)訂單總價(jià)格的處理過程,由傳統(tǒng)的按行遍歷處理的過程,轉(zhuǎn)換為按 Block 處理的過程,具體如下圖:
3. 編碼壓縮
由于 ClickHouse 采用列存儲(chǔ),相同列的數(shù)據(jù)連續(xù)存儲(chǔ),且底層數(shù)據(jù)在存儲(chǔ)時(shí)是經(jīng)過排序的,這樣數(shù)據(jù)的局部規(guī)律性非常強(qiáng),有利于獲得更高的數(shù)據(jù)壓縮比。 此外,ClickHouse 除了支持 LZ4、ZSTD 等通用壓縮算法外,還支持 Delta、DoubleDelta、Gorilla 等專用編碼算法[4],用于進(jìn)一步提高數(shù)據(jù)壓縮比。 其中 DoubleDelta、Gorilla 是 Facebook 專為時(shí)間序數(shù)據(jù)而設(shè)計(jì)的編碼算法,理論上在列存儲(chǔ)環(huán)境下,可接近專用時(shí)序存儲(chǔ)的壓縮比,詳細(xì)可參考 Gorilla 論文[5]。

在實(shí)際場(chǎng)景下,ClickHouse 通常可以達(dá)到 10 : 1 的壓縮比,大幅降低存儲(chǔ)成本。同時(shí),超高的壓縮比又可以降低存儲(chǔ)讀取開銷、提升系統(tǒng)緩存能力,從而提高查詢性能。
4. 多索引
列存用于裁剪不必要的字段讀取,而索引則用于裁剪不必要的記錄讀取。ClickHouse 支持豐富的索引,從而在查詢時(shí)盡可能的裁剪不必要的記錄讀取,提高查詢性能。 ClickHouse 中最基礎(chǔ)的索引是主鍵索引。前面我們?cè)谖锢泶鎯?chǔ)模型中介紹,ClickHouse 的底層數(shù)據(jù)按建表時(shí)指定的 ORDER BY 列進(jìn)行排序,并按 index_granularity 參數(shù)切分成數(shù)據(jù)塊,然后抽取每個(gè)數(shù)據(jù)塊的第一行形成一份稀疏的排序索引。 用戶在查詢時(shí),如果查詢條件包含主鍵列,則可以基于稀疏索引進(jìn)行快速的裁剪。這里通過下面的樣例數(shù)據(jù)及對(duì)應(yīng)的主鍵索引進(jìn)行說明:

樣例中的主鍵列為 CounterID、Date,這里按每 7 個(gè)值作為一個(gè)數(shù)據(jù)塊,抽取生成了主鍵索引 Marks 部分。當(dāng)用戶查詢 CounterID equal ‘h’ 的數(shù)據(jù)時(shí),根據(jù)索引信息,只需要讀取 Mark number 為 6 和 7 的兩個(gè)數(shù)據(jù)塊。 ClickHouse 支持更多其他的索引類型,不同索引用于不同場(chǎng)景下的查詢裁剪,具體匯總?cè)缦拢敿?xì)的介紹參考 ClickHouse 官方文檔[6]:
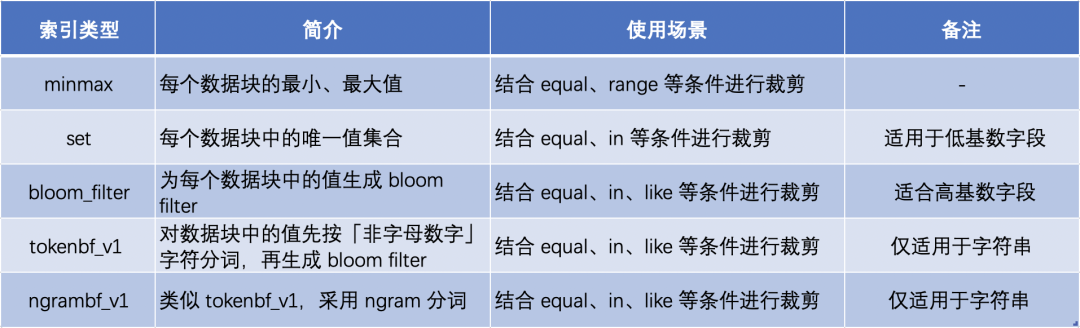
5. 物化視圖(Cube/Rollup)
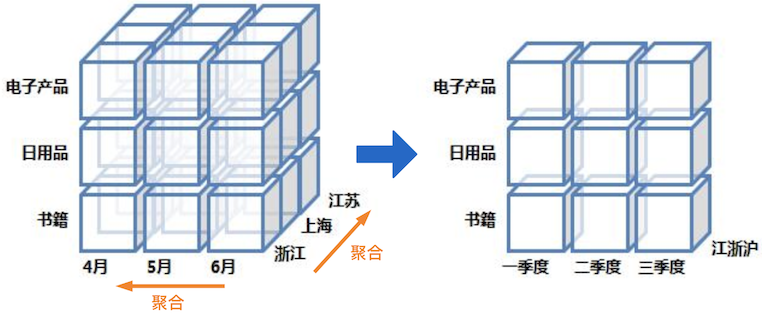
OLAP 分析領(lǐng)域有兩個(gè)典型的方向:一是 ROLAP,通過列存、索引等各類技術(shù)手段,提升查詢時(shí)性能。 另一是 MOLAP,通過預(yù)計(jì)算提前生成聚合后的結(jié)果數(shù)據(jù),降低查詢讀取的數(shù)據(jù)量,屬于計(jì)算換性能方式。 前者更為靈活,但需要的技術(shù)棧相對(duì)復(fù)雜;后者實(shí)現(xiàn)相對(duì)簡(jiǎn)單,但要達(dá)到的極致性能,需要生成所有常見查詢對(duì)應(yīng)的物化視圖,消耗大量計(jì)算、存儲(chǔ)資源。物化視圖的原理如下圖所示,可以在不同維度上對(duì)原始數(shù)據(jù)進(jìn)行預(yù)計(jì)算匯總:
ClickHouse 一定程度上做了兩者的結(jié)合,在盡可能采用 ROLAP 方式提高性能的同時(shí),支持一定的 MOLAP 能力,具體實(shí)現(xiàn)方式為 MergeTree系列表引擎[7] 和 MATERIALIZED VIEW[8]。 事實(shí)上,Yandex.Metrica 的存儲(chǔ)系統(tǒng)也經(jīng)歷過使用純粹 MOLAP 方案的發(fā)展過程,具體參考 ClickHouse的發(fā)展歷史[9]。 用戶在使用時(shí),可優(yōu)先按照 ROLAP 思路進(jìn)行調(diào)優(yōu),例如主鍵選擇、索引優(yōu)化、編碼壓縮等。當(dāng)希望性能更高時(shí),可考慮結(jié)合 MOLAP 方式,針對(duì)高頻查詢模式,建立少量的物化視圖,消耗可接受的計(jì)算、存儲(chǔ)資源,進(jìn)一步換取查詢性能。
6. 其他特性
除了前面所述,ClickHouse 還有非常多其他特性,抽取列舉如下,更多詳細(xì)內(nèi)容可參考 ClickHouse官方文檔[10]。
SQL 方言:在常用場(chǎng)景下,兼容 ANSI SQL,并支持 JDBC、ODBC 等豐富接口。
權(quán)限管控:支持 Role-Based 權(quán)限控制,與關(guān)系型數(shù)據(jù)庫使用體驗(yàn)類似。
多機(jī)多核并行計(jì)算:ClickHouse 會(huì)充分利用集群中的多節(jié)點(diǎn)、多線程進(jìn)行并行計(jì)算,提高性能。
近似查詢:支持近似查詢算法、數(shù)據(jù)抽樣等近似查詢方案,加速查詢性能。
Colocated Join:數(shù)據(jù)打散規(guī)則一致的多表進(jìn)行 Join 時(shí),支持本地化的 Colocated Join,提升查詢性能。 ……
四、ClickHouse 的不足
前面介紹了大量 ClickHouse 的核心特性,方便讀者了解 ClickHouse 高性能、快速發(fā)展的背后原因。當(dāng)然,ClickHouse 作為后起之秀,遠(yuǎn)沒有達(dá)到盡善盡美,還有不少需要待完善的方面,典型代表如下:
1. 分布式管控
分布式系統(tǒng)通常包含 3 個(gè)重要組成部分:存儲(chǔ)引擎、計(jì)算引擎、分布式管控層。ClickHouse 有一個(gè)非常突出的高性能存儲(chǔ)引擎,但在分布式管控層顯得較為薄弱,使得運(yùn)營、使用成本偏高。主要體現(xiàn)在: (1)分布式表 ClickHouse 對(duì)分布式表的抽象并不完整,在多數(shù)分布式系統(tǒng)中,用戶僅感知集群和表,對(duì)分片和副本的管理透明,而在 ClickHouse 中,用戶需要自己去管理分片、副本,例如前面介紹的建表過程:用戶需要先創(chuàng)建本地表(分片的副本),然后再創(chuàng)建分布式表,并完成分布式表到本地表的映射。 (2)彈性伸縮 ClickHouse 集群自身雖然可以方便的水平增加節(jié)點(diǎn),但并不支持自動(dòng)的數(shù)據(jù)均衡。例如,當(dāng)包含 6 個(gè)節(jié)點(diǎn)的線上生產(chǎn)集群因存儲(chǔ) 或 計(jì)算壓力大,需要進(jìn)行擴(kuò)容時(shí),我們可以方便的擴(kuò)容到 10 個(gè)節(jié)點(diǎn),但是數(shù)據(jù)并不會(huì)自動(dòng)均衡,需要用戶給已有表增加分片 或者 重新建表,再把寫入壓力重新在整個(gè)集群內(nèi)打散,而存儲(chǔ)壓力的均衡則依賴于歷史數(shù)據(jù)過期。ClickHouse在彈性伸縮方面的不足,大幅增加了業(yè)務(wù)在進(jìn)行水平伸縮時(shí)運(yùn)營壓力。 基于 ClickHouse 的當(dāng)前架構(gòu),實(shí)現(xiàn)自動(dòng)均衡相對(duì)復(fù)雜,導(dǎo)致相關(guān)問題的根因在于 ClickHouse 分組式的分布式架構(gòu):同一分片的主從副本綁定在一組節(jié)點(diǎn)上,更直接的說,分片間數(shù)據(jù)打散是按照節(jié)點(diǎn)進(jìn)行的,自動(dòng)均衡過程不能簡(jiǎn)單的搬遷分片到新節(jié)點(diǎn),會(huì)導(dǎo)致路由信息錯(cuò)誤。而創(chuàng)建新表并在集群中進(jìn)行全量數(shù)據(jù)重新打散的方式,操作開銷過高。
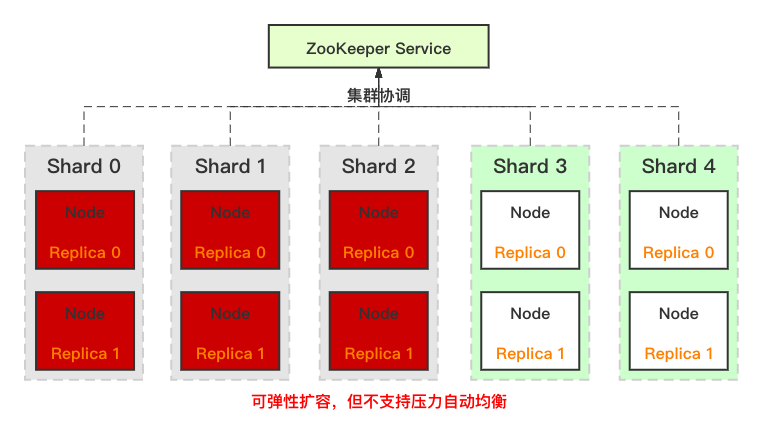
(3)故障恢復(fù) 與彈性伸縮類似,在節(jié)點(diǎn)故障的情況下,ClickHouse 并不會(huì)利用其它機(jī)器補(bǔ)齊缺失的副本數(shù)據(jù)。需要用戶先補(bǔ)齊節(jié)點(diǎn)后,然后系統(tǒng)再自動(dòng)在副本間進(jìn)行數(shù)據(jù)同步。
2. 計(jì)算引擎
雖然 ClickHouse 在單表性能方面表現(xiàn)非常出色,但是在復(fù)雜場(chǎng)景仍有不足,缺乏成熟的 MPP 計(jì)算引擎 和 執(zhí)行優(yōu)化器,例如:多表關(guān)聯(lián)查詢、復(fù)雜嵌套子查詢等場(chǎng)景下查詢性能一般,需要人工優(yōu)化;缺乏 UDF 等能力,在復(fù)雜需求下擴(kuò)展能力較弱等。這也和 OLAP 系統(tǒng)第三方評(píng)測(cè) 的結(jié)果相符。這對(duì)于性能如此出眾的存儲(chǔ)引擎來說,非常可惜。
3. 實(shí)時(shí)寫入
ClickHouse 采用類 LSM Tree 架構(gòu),并且建議用戶通過批量方式進(jìn)行寫入,每個(gè)批次不少于 1000 行 或 每秒鐘不超過一個(gè)批次,從而提高集群寫入性能,實(shí)際測(cè)試情況下,32 vCPU & 128G 內(nèi)存的情況下,單節(jié)點(diǎn)寫性能可達(dá) 50 MB/s ~ 200 MB/s,對(duì)應(yīng) 5w ~ 20w TPS。 但 ClickHouse 并不適合實(shí)時(shí)寫入,原因在于 ClickHouse 并非典型的 LSM Tree 架構(gòu),它沒有實(shí)現(xiàn) Memory Table 結(jié)構(gòu),每批次寫入直接落盤作為一棵 Tree(如果單批次過大,會(huì)拆分為多棵 Tree),每條記錄實(shí)時(shí)寫入會(huì)導(dǎo)致底層大量的小文件,影響查詢性能。 這使得 ClickHouse 不適合有實(shí)時(shí)寫入需求的業(yè)務(wù),通常需要在業(yè)務(wù)和 ClickHouse 之間引入一層數(shù)據(jù)緩存層,實(shí)現(xiàn)批量寫入。
五、結(jié)語
本文重點(diǎn)分享了 ClickHouse 的整體架構(gòu)及眾多核心特性,分析了 ClickHouse 如何實(shí)現(xiàn)極致性能的存儲(chǔ)引擎,從而成為 OLAP 領(lǐng)域的后起之秀。 ClickHouse 仍然年輕,雖然在某些方面存在不足,但極致性能的存儲(chǔ)引擎,使得 ClickHouse 成為一個(gè)非常優(yōu)秀的存儲(chǔ)底座。 后續(xù)我們會(huì)在不斷拓展業(yè)務(wù)的同時(shí),優(yōu)先從分布式管控層和計(jì)算引擎層著手,持續(xù)優(yōu)化 ClickHouse 的易用性、性能,打造業(yè)界領(lǐng)先的 OLAP 分析數(shù)據(jù)庫。同時(shí),我們會(huì)持續(xù)輸出內(nèi)核優(yōu)化、最佳實(shí)踐等經(jīng)驗(yàn),歡迎更多技術(shù)愛好者們一起探索、交流。
原文標(biāo)題:交互式分析領(lǐng)域,為何 ClickHouse 能夠殺出重圍?
文章出處:【微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7242瀏覽量
91039 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3901瀏覽量
65787
原文標(biāo)題:交互式分析領(lǐng)域,為何 ClickHouse 能夠殺出重圍?
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
SQLSERVER數(shù)據(jù)庫是什么
MySQL數(shù)據(jù)庫是什么
混合信號(hào)分析儀的原理和應(yīng)用場(chǎng)景
函數(shù)信號(hào)分析儀的原理和應(yīng)用場(chǎng)景
數(shù)據(jù)網(wǎng)絡(luò)分析儀的原理和應(yīng)用場(chǎng)景
分布式云化數(shù)據(jù)庫有哪些類型
MySQL數(shù)據(jù)庫的安裝
關(guān)系型數(shù)據(jù)庫和非關(guān)系型區(qū)別
云數(shù)據(jù)庫是哪種數(shù)據(jù)庫類型?
ClickHouse:強(qiáng)大的數(shù)據(jù)分析引擎

多維表格數(shù)據(jù)庫Teable的適用場(chǎng)景?
數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—通過拼接數(shù)據(jù)庫碎片恢復(fù)SQLserver數(shù)據(jù)庫

恒訊科技分析:云數(shù)據(jù)庫rds和redis區(qū)別是什么如何選擇?
供應(yīng)鏈場(chǎng)景使用ClickHouse最佳實(shí)踐





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論