") 分布式系統(tǒng)中保證高可用性的常用經(jīng)驗(yàn)
分布式系統(tǒng)中保證高可用性的常用經(jīng)驗(yàn)
系統(tǒng)可用性指標(biāo)
系統(tǒng)可用性指標(biāo)簡單來講就是系統(tǒng)可用時間與總運(yùn)行時間之比
Availability=MTTF/(MTTF+MTTRMTTF)
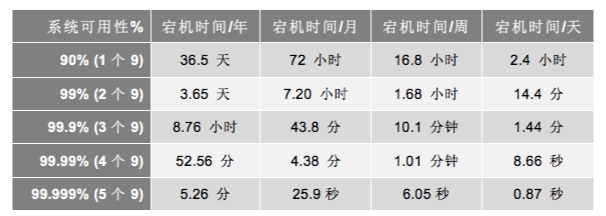
MTTF 是 Mean Time To Failure,指平均故障前的時間,即系統(tǒng)平均能夠正常運(yùn)行多長時間才發(fā)生一次故障。系統(tǒng)的可靠性越高,MTTF 越長(簡單理解MTTF 就是指系統(tǒng)正常運(yùn)行的時間)。MTTR 是 Mean Time To Recovery, 平均修復(fù)時間,即從故障出現(xiàn)到故障修復(fù)的這段時間,也就是系統(tǒng)不可用的時間,這段時間越短越好。系統(tǒng)可用性指標(biāo)可以用通過下表的999標(biāo)準(zhǔn)衡量,現(xiàn)在普遍要求至少2個9,最好4個9以上:
故障不可避免
高可用性是指系統(tǒng)提供的服務(wù)要始終可用,然而故障不可避免,特別是在分布式系統(tǒng),面對不可控的用戶流量和機(jī)房環(huán)境,系統(tǒng)故障將會顯得更加復(fù)雜和不可預(yù)測。在大規(guī)模的分布式系統(tǒng)中,各個模塊之間存在錯綜復(fù)雜的依賴,任一一個環(huán)節(jié)出現(xiàn)問題,都有可能導(dǎo)致雪崩式、多米諾骨牌式的故障,甚者可以斷言出現(xiàn)故障成了常態(tài)。
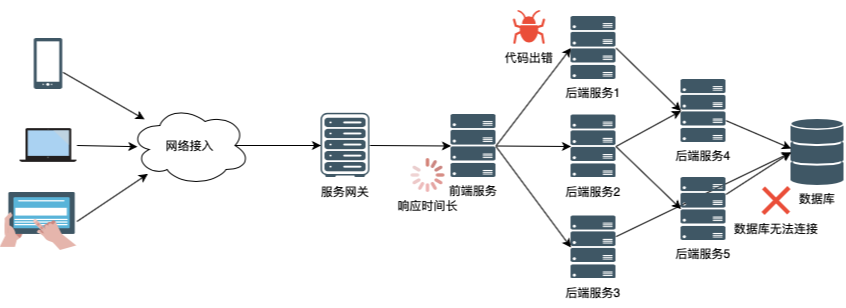
如上圖的分布式系統(tǒng)中,用戶請求系統(tǒng)中的某個服務(wù)接口,請求需要經(jīng)過長長的調(diào)用鏈才能處理返回。我們起碼要保證網(wǎng)絡(luò)連接正常,服務(wù)網(wǎng)關(guān)正常、前端服務(wù)正常、后臺服務(wù)正常、數(shù)據(jù)庫正常,請求才能被正常處理,如果調(diào)用鏈中的任一環(huán)節(jié)出現(xiàn)問題,都會直接反饋到用戶體驗(yàn)上。
系統(tǒng)出現(xiàn)故障的原因多種多樣,主要有以下這些:
網(wǎng)絡(luò)問題,網(wǎng)絡(luò)連接故障,網(wǎng)絡(luò)帶寬出現(xiàn)超時擁塞等;
性能問題,數(shù)據(jù)庫慢查詢、Java Full GC、硬盤 IO 過大、CPU 過高、內(nèi)存不足等
安全問題,被網(wǎng)絡(luò)攻擊,如 DDoS 等、異常客戶端請求,如爬蟲等。
運(yùn)維問題,需求變更頻繁不可控,架構(gòu)也在不斷地被調(diào)整,監(jiān)控問題等;
管理問題,沒有梳理出關(guān)鍵服務(wù)以及服務(wù)的依賴關(guān)系,運(yùn)行信息沒有和控制系統(tǒng)同步;
硬件問題,硬盤損壞、網(wǎng)卡出問題、交換機(jī)出問題、機(jī)房掉電、挖掘機(jī)問題(前一陣子機(jī)房電纜就經(jīng)常被挖斷)等;
面對如此多的天災(zāi)人禍,可控和不可控的故障因素,似乎系統(tǒng)的高可用性變成不可能完成的任務(wù),但是在日常開發(fā)運(yùn)維中,我們可以采用一些有效的設(shè)計、實(shí)現(xiàn)和運(yùn)維手段來提高系統(tǒng)的高可用性,盡量交付一個在任何時候都基本可用的系統(tǒng)。
冗余設(shè)計
分布式系統(tǒng)中單點(diǎn)故障不可取的,而降低單點(diǎn)故障的不二法門就是冗余設(shè)計,通過多點(diǎn)部署的方式,并且最好是部署在不同的物理位置,避免單機(jī)房中多點(diǎn)同時失敗。冗余設(shè)計不僅可以提高服務(wù)的吞吐量,還可以在出現(xiàn)災(zāi)難時快速恢復(fù)。目前常見的冗余設(shè)計有主從設(shè)計和對等治理設(shè)計,主從設(shè)計又可以細(xì)分為一主多從、多主多從。
冗余設(shè)計中一個不可避免的問題是考慮分布式系統(tǒng)中數(shù)據(jù)的一致性,多個節(jié)點(diǎn)中冗余的數(shù)據(jù)追求強(qiáng)一致性還是最終一致性。即使節(jié)點(diǎn)提供無狀態(tài)服務(wù),也需要借助外部服務(wù),比如數(shù)據(jù)庫、分布式緩存等維護(hù)數(shù)據(jù)狀態(tài)。根據(jù)分布式系統(tǒng)下節(jié)點(diǎn)數(shù)據(jù)同步的基本原理CAP(Consistency (一致性)、Availablity (可用性)、Partition tolerance (分區(qū)容忍性)三個指標(biāo)不可同時滿足),數(shù)據(jù)強(qiáng)一致性的系統(tǒng)無法保證高可用性,最典型的例子就是 Zookeeper。
Zookeeper 采用主從設(shè)計,服務(wù)集群由 Leader、Follower 和 Observer 三種角色組成,它們的職責(zé)如下:
Leader: Zookeeper 集群使用 ZAB 協(xié)議通過 Leader 選舉從集群中選定一個節(jié)點(diǎn)作為 Leader。Leader 響應(yīng)客戶端的讀寫請求;
Follower:只提供數(shù)據(jù)的讀服務(wù),會將來自客戶端的寫請求轉(zhuǎn)發(fā)到 Leader 中。在 Leader 選舉的過程中參與投票,并與 Leader 維持?jǐn)?shù)據(jù)同步;
Observer:與 Folllower 的功能相同,但不參與 Leader 選舉和寫過程的“過半寫成功”策略,單純?yōu)榱颂岣呒旱淖x能力。
在 Zookeeper 集群中,由于只有 Leader 角色的節(jié)點(diǎn)具備寫數(shù)據(jù)的能力,當(dāng) Leader 節(jié)點(diǎn)宕機(jī)時,在新的 Leader 節(jié)點(diǎn)沒有被選舉出來之前,集群的寫能力都是不可用的。雖然 Zookeeper 保證了集群數(shù)據(jù)的強(qiáng)一致性,但是放棄了集群的高可用性。 對等治理設(shè)計中比較優(yōu)秀的業(yè)內(nèi)體現(xiàn)為 Netiflx 開源的 Eureka 服務(wù)注冊和發(fā)現(xiàn)組件。Eureka 集群由 Eureka Client 和 Eureka Server 兩種角色組成,其中 Eureka Client 是指服務(wù)實(shí)例使用的服務(wù)注冊和發(fā)現(xiàn)的客戶端,用于注冊和查詢服務(wù)實(shí)例信息;Eureka Server 作為服務(wù)注冊中心,存儲有各服務(wù)的實(shí)例信息列表,采用多實(shí)例的方式部署保證高可用性。 每一個 Eureka Server 都是對等的數(shù)據(jù)節(jié)點(diǎn),Eureka Client 可以向任意的 Eureka Server 發(fā)起服務(wù)注冊請求和服務(wù)發(fā)現(xiàn)請求。Eureka Server 之間的數(shù)據(jù)通過異步 HTTP 的方式同步,由于網(wǎng)絡(luò)的不可靠性,不同 Eureka Server 中的服務(wù)實(shí)例數(shù)據(jù)不能保證在任意時間節(jié)點(diǎn)都相等,只能保證在 SLA 承諾時間內(nèi)達(dá)到數(shù)據(jù)的最終一致性。Eureka 點(diǎn)對點(diǎn)對等的設(shè)計保證了服務(wù)注冊與發(fā)現(xiàn)中心的高可用性,但是犧牲了數(shù)據(jù)的強(qiáng)一致性,降級為數(shù)據(jù)的最終一致性。
熔斷設(shè)計
在分布式系統(tǒng)中,一次完整的請求可能需要經(jīng)過多個服務(wù)模塊的通力合作,請求在多個服務(wù)中傳遞,服務(wù)對服務(wù)的調(diào)用會產(chǎn)生新的請求,這些請求共同組成了這次請求的調(diào)用鏈。當(dāng)調(diào)用鏈中的某個環(huán)節(jié),特別是下游服務(wù)不可用時,將會導(dǎo)致上游服務(wù)調(diào)用方不可用,最終將這種不可用的影響擴(kuò)大到整個系統(tǒng),導(dǎo)致整個分布式系統(tǒng)的不可用,引發(fā)服務(wù)雪崩現(xiàn)象。
為了避免這種情況,在下游服務(wù)不可用時,保護(hù)上游服務(wù)的可用性顯得極其重要。對此,我們可以參考電路系統(tǒng)的斷路器機(jī)制,在必要的時候壯士斷腕,當(dāng)下游服務(wù)因?yàn)檫^載或者故障不能用時,及時“熔斷”服務(wù)調(diào)用方和服務(wù)提供方的調(diào)用鏈,保護(hù)服務(wù)調(diào)用方資源,防止服務(wù)雪崩現(xiàn)象的出現(xiàn)。
斷路器的基本設(shè)計圖如下,由關(guān)閉、打開、半開三種狀態(tài)組成:
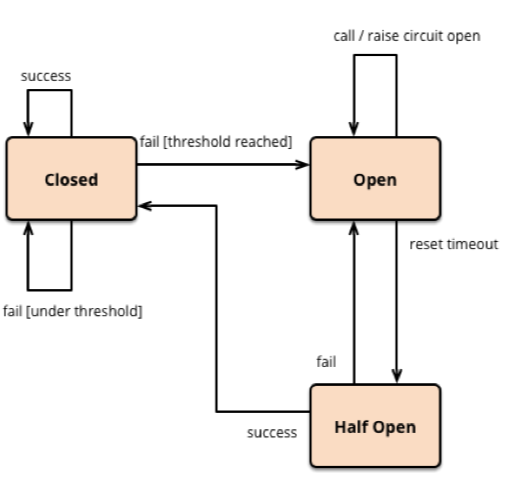
關(guān)閉(Closed)狀態(tài):
此時服務(wù)調(diào)用方可以調(diào)用服務(wù)提供方。斷路器中使用失敗計數(shù)器周期性統(tǒng)計請求失敗次數(shù)和請求總次數(shù)的比例,如果最近失敗頻率超過了周期時間內(nèi)允許失敗的閾值,則切換到打開(Open)狀態(tài)。在關(guān)閉狀態(tài)下,失敗計數(shù)器基于時間周期運(yùn)作,會在每個統(tǒng)計周期開始前自動重置,防止某次偶然錯誤導(dǎo)致斷路器進(jìn)入打開狀態(tài)。
打開(Open)狀態(tài):
在該狀態(tài)下,對應(yīng)用程序的請求會立即返回錯誤響應(yīng)或者執(zhí)行預(yù)設(shè)的失敗降級邏輯,而不調(diào)用服務(wù)提供方。斷路器進(jìn)入打開狀態(tài)后會啟動超時計時器,在計時器到達(dá)后,斷路器進(jìn)入半開狀態(tài)。
半開(Half-Open)狀態(tài):
允許應(yīng)用程序一定數(shù)量的請求去調(diào)用服務(wù)。如果這些請求對服務(wù)的調(diào)用成功,那么可以認(rèn)為之前導(dǎo)致調(diào)用失敗的錯誤已經(jīng)修正,此時斷路器切換到關(guān)閉狀態(tài),同時將失敗計數(shù)器重置。如果這一定數(shù)量的請求存在調(diào)用失敗的情況,則認(rèn)為導(dǎo)致之前調(diào)用失敗的問題仍然存在,斷路器切回到打開狀態(tài),并重置超時計時器來給系統(tǒng)一定的時間來修正錯誤。半開狀態(tài)能夠有效防止正在恢復(fù)中的服務(wù)被突然而來的大量請求再次打垮。
使用斷路器設(shè)計模式,能夠有效地保護(hù)服務(wù)調(diào)用方的穩(wěn)定性,它能夠避免服務(wù)調(diào)用者頻繁調(diào)用可能失敗的服務(wù)提供者,防止服務(wù)調(diào)用者浪費(fèi) CPU 周期、線程和 IO 資源等,提高服務(wù)整體的可用性。
小結(jié)
本文主要介紹了幾種高可用的設(shè)計,除了上面介紹的方式之外,還有限流設(shè)計和一些其他設(shè)計與方案,如降級設(shè)計、無狀態(tài)設(shè)計、冪等性設(shè)計、重試設(shè)計、接口緩存、實(shí)時監(jiān)控和度量以及常規(guī)劃化維護(hù)。
原文標(biāo)題:進(jìn)來抄作業(yè)吧!分布式系統(tǒng)中保證高可用性的常用經(jīng)驗(yàn)
文章出處:【微信公眾號:華為開發(fā)者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
分布式系統(tǒng)
+關(guān)注
關(guān)注
0文章
147瀏覽量
19521
原文標(biāo)題:進(jìn)來抄作業(yè)吧!分布式系統(tǒng)中保證高可用性的常用經(jīng)驗(yàn)
文章出處:【微信號:Huawei_Developer,微信公眾號:華為開發(fā)者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Vsan數(shù)據(jù)恢復(fù)——Vsan分布式文件系統(tǒng)上虛擬機(jī)不可用的數(shù)據(jù)恢復(fù)
分布式光伏發(fā)運(yùn)維系統(tǒng)實(shí)際應(yīng)用案例分享
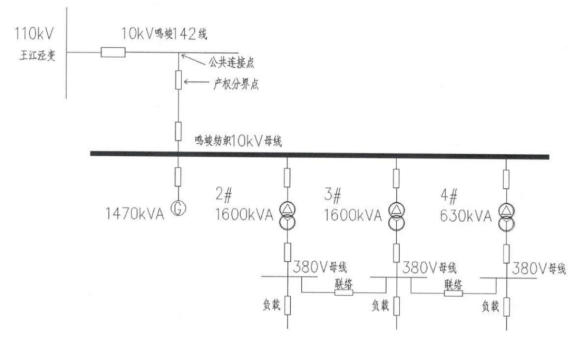
淺談分布式光伏系統(tǒng)在工業(yè)企業(yè)的設(shè)計及應(yīng)用

分布式 IO 模塊:開啟藥品罐裝產(chǎn)線高效生產(chǎn)新紀(jì)元

基于ptp的分布式系統(tǒng)設(shè)計
分布式光伏監(jiān)控系統(tǒng)在能源領(lǐng)域中的重要性
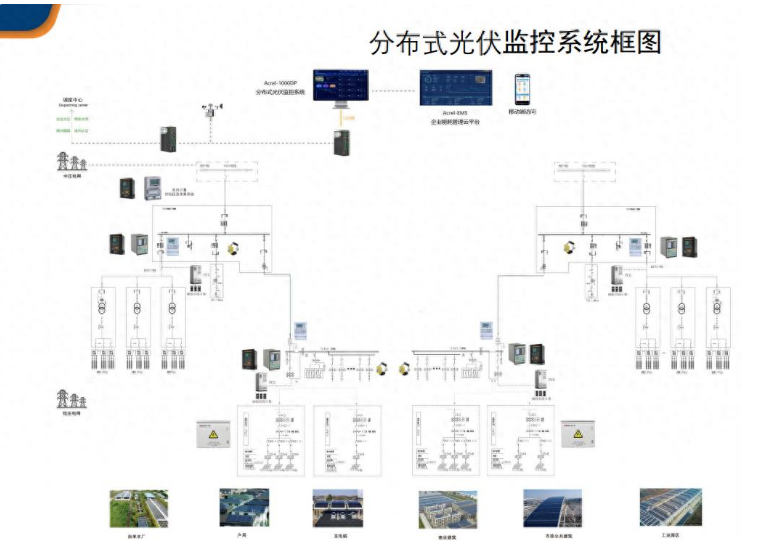
增強(qiáng)分布式光伏電站管理,遠(yuǎn)程管理 提高管理便捷性
分布式光伏發(fā)電系統(tǒng)的應(yīng)用
使用bq769x0對高可用性系統(tǒng)進(jìn)行故障監(jiān)控

一文講清什么是分布式云化數(shù)據(jù)庫!
分布式存儲費(fèi)用高嗎?大概需要多少錢
分布式云化數(shù)據(jù)庫的優(yōu)缺點(diǎn)分析
淺析分布式風(fēng)電電池儲能系統(tǒng)可用性
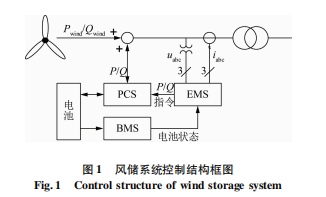
分布式SCADA系統(tǒng)的特點(diǎn)的組成
安徽京準(zhǔn) NTP授時服務(wù)器(北斗授時設(shè)備)在分布式系統(tǒng)中的重要性





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論