 模型集成是一種提升模型能力的常用方法
模型集成是一種提升模型能力的常用方法
導讀
模型集成是一種提升模型能力的常用方法,但通常也會帶來推理時間的增加,在物體檢測上效果如何,可以看看。

介紹
集成機器學習模型是一種常見的提升模型能力的方式,并已在多個場景中使用,因為它們結合了多個模型的決策,以提高整體性能,但當涉及到基于DNN(深度神經網絡)的目標檢測模型時,它并不僅僅是合并結果那么簡單。
集成的需求
為了在任何模型中獲得良好的結果,都需要滿足某些標準(數據、超參數)。但在真實場景中,你可能會得到糟糕的訓練數據,或者很難找到合適的超參數。在這些情況下,綜合多個性能較差的模型可以幫助你獲得所需的結果。在某種意義上,集成學習可以被認為是一種通過執行大量額外計算來彌補學習算法不足的方法。另一方面,另一種選擇是在一個非集成系統上做更多的學習。對于計算、存儲或通信資源的相同增加,集成系統使用兩種或兩種以上的方法可能會比使用單一方法增加資源的方法更有效地提高整體精度。
看起來挺好,有沒有缺點呢?
更難調試或理解預測,因為預測框是根據多個模型繪制的。
推理時間根據模型和使用的模型數量而增加。
嘗試不同的模型以獲得合適的模型集合是一件耗時的事情。
不同的模型集成
OR方法:如果一個框是由至少一個模型生成的,就會考慮它。
AND方法:如果所有模型產生相同的框,則認為是一個框(如果IOU >0.5)。
一致性方法:如果大多數模型產生相同的框,則認為是一個框,即如果有m個模型,(m/2 +1)個模型產生相同的框,則認為這個框有效。
加權融合:這是一種替代NMS的新方法,并指出了其不足之處。

不同的集成方法
在上面的例子中,OR方法的預測得到了所有需要的對象框,但也得到了一個假陽性結果,一致性的方法漏掉了馬,AND方法同時漏掉了馬和狗。
驗證
為了計算不同的集成方法,我們將跟蹤以下參數:
True positive:預測框與gt匹配
False Positives:預測框是錯誤的
False Negatives:沒有預測,但是存在gt。
Precision:度量你的預測有多準確。也就是說,你的預測正確的百分比[TP/ (TP + FP)]
Recall:度量gt被預測的百分比[TP/ (TP + FN)]
Average Precision:precision-recall圖的曲線下面積
使用的模型
為了理解集成是如何起作用的,我們提供了用于實驗的獨立模型的結果。
1. YoloV3:

2. Faster R-CNN — ResNeXt 101 [X101-FPN]:

集成實驗
1. OR — [YoloV3, X101-FPN]

如果你仔細觀察,FPs的數量增加了,這反過來降低了精度。與此同時,TPs數量的增加反過來又增加了召回。這是使用OR方法時可以觀察到的一般趨勢。
2. AND — [YoloV3, X101-FPN]

與我們使用OR方法觀察到的情況相反,在AND方法中,我們最終獲得了較高的精度和較低的召回率,因為幾乎所有的假陽性都被刪除了,因為YoloV3和X101的大多數FPs是不同的。
檢測框加權融合
在NMS方法中,如果框的IoU大于某個閾值,則認為框屬于單個物體。因此,框的過濾過程取決于這個單一IoU閾值的選擇,這影響了模型的性能。然而,設置這個閾值很棘手:如果有多個物體并排存在,那么其中一個就會被刪除。NMS丟棄了冗余框,因此不能有效地從不同的模型中產生平均的局部預測。
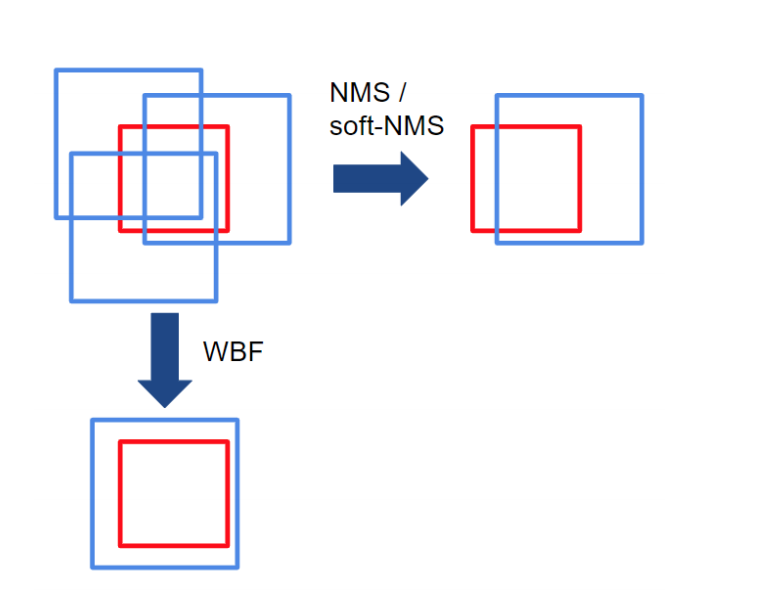
NMS和WBF之間的主要區別是,WBF利用所有的框,而不是丟棄它們。在上面的例子中,紅框是ground truth,藍框是多個模型做出的預測。請注意,NMS是如何刪除冗余框的,但WBF通過考慮所有預測框創建了一個全新的框(融合框)。
3. Weighted Boxes Fusion — [Yolov3, X101-FPN]

YoloV3和X101-FPN的權重比分別為2:1。我們也試著增加有利于X101-FPN的比重(因為它的性能更好),但在性能上沒有看到任何顯著的差異。從我們讀過的加權融合論文中,作者注意到了AP的增加,但如你所見,WBF YoloV3和X101-FPN并不比OR方法好很多。我們注意到的是,大部分的實驗涉及至少3個或更多模型。
4. Weighted Boxes Fusion — [Yolov3, X101, R101, R50]

在最后的實驗中,我們使用了YoloV3以及我們在Detectron2中訓練的3個模型[ResNeXt101-FPN, ResNet101-FPN, ResNet50-FPN]。顯然,召回率有一個跳躍(約為傳統方法的0.3),但AP的跳躍并不大。另外,需要注意的是,當你向WF方法添加更多模型時,誤報的數量會激增。
總結
當使用相互補充的模型時,集成是提高性能的一種很好的方法,但它也會以速度為代價來完成推理。根據需求,可以決定有多少個模型,采用哪種方法,等等。但從我們進行的實驗來看,性能提升的數量似乎與一起運行這些模型所需的資源和推斷時間不成比例。
責任編輯:lq
-
神經網絡
+關注
關注
42文章
4809瀏覽量
102836 -
模型
+關注
關注
1文章
3488瀏覽量
50021 -
機器學習
+關注
關注
66文章
8492瀏覽量
134125
原文標題:目標檢測多模型集成方法總結
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
FA模型訪問Stage模型DataShareExtensionAbility說明
一種基于正交與縮放變換的大模型量化方法

大模型領域常用名詞解釋(近100個)

【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
cnn常用的幾個模型有哪些
rup是一種什么模型
LLM模型和LMM模型的區別
大模型單卡的正確使用步驟
人工神經網絡模型是一種什么模型
神經網絡模型建完了怎么用
智能制造能力成熟度模型是什么?





 工商網監
工商網監
評論