 計算型存儲: 異構計算的下一個關鍵應用
計算型存儲: 異構計算的下一個關鍵應用
AWS re:Invent2019顯示AWS市場占用率達到45%,相比2018年營收增長29%。使用專用芯片構建用于加速特定場景的戰略更加清晰,除去Intel和AMD的X86和Nvidia GPU,還有通過其Annapurna Labs部門推出的基于Arm的Graviton的定制芯片,并承諾基于Graviton2(7納米)的新型EC2實例的性能是第一代Graviton的7倍。
早在摩爾定律失效之前,一個逐漸達成的共識就是通用處理器的算力應該專注于復雜的商業邏輯,而簡單重復的工作則由專用芯片完成更加合適。
超算和智能網卡
早在20年以前,基于異構計算的智能網卡就已經應用于超算(HPC)領域。從1993年開始 TOP500 就以每年兩次的頻率,基于 Linpack benchmark 負載模型來統計地球上運行最快的超級計算集群。
2003年,弗吉尼亞理工學院暨州立大學創建一個InfiniBand集群,在當時的TOP500排名第三;
2009年,世界500強超級算機中,152個使用InfiniBand,并提供38.7%的算力;
2020年11月,根據最新的第56版,155個使用 InfiniBand,并提供40%的算力,排名前10的超算集群有8個由 InfiniBand 構建,更是占據了前5的4席位置。
在構建高速網路時,爭論主要是把網絡功能Onload到CPU上,還是把這些功能Offload到專用硬件:
常用Onloading,TCP/IP技術在數據包從網卡到應用程序的過程中,要經過OS,數據在主存、CPU緩存和網卡緩存之間來回復制,給服務器的CPU和主存造成負擔,也加劇網絡延遲。
Offloading 基于RDMA實現遠程內存直接訪問,將數據從本地快速移動到遠程主機應用程序的用戶空間,通過Zero-copy和Kernel bypass來實現高性能的遠程直接數據存取的目標。
下圖可以直觀的看到兩者在訪問路徑的區別:
當然,Offloading 需要將RDMA協議固化于硬件上,所以依賴于網卡的算力是否可以滿足運行RDMA協議的開銷,這實際上就是專用芯片和網卡的結合。用更性感的說法是
SmartNICs are an example of DPU (Data Processing Unit) technology
AWS和Nitro
云計算催生超大規模數據中心,也同時放大通用算力的不足和異構計算的優勢。就好比研發團隊規模變大的同時必然走向專業化。AWS EC2早期由純軟(也意味著需要消耗CPU)的Xen對CPU、存儲和網絡完成虛擬化。基于這種實現方式,一個EC2實例的虛擬化管理開銷高達30%。
30%相當可觀,最重要的是并沒有為客戶提供直接價值。按照 Werner Vogels(AWS CTO )的說法
想為客戶顯著提高性能、安全性和敏捷性,我們必須將大部分管理程序功能遷移到專用硬件上。
2012年,AWS開始構建Nitro系統,也正是這,登納德縮放定律(嚴格說是預測)幾乎消失:
2013年, Nitro 應用于C3實例,其網絡進程卸載到硬件中;
2014年,推出了C4實例類型,將EBS存儲卸載到硬件中,并開始和Annapurna Labs合作;
2015年,收購 Annapurna Labs;
2017年,C5實例卸載控制平面和剩余的I/O,實現完整的Nitro系統;
此時,Nitro系統已經包含三個主要部分:Nitro卡、Nitro安全芯片和Nitro管理程序。主要卸載和加速IO,虛擬私有云(VPC)、彈性塊存儲(EBS)和實例存儲,從而讓用戶可以使用100%的通用算力。
對客戶而言,意味更好的性能和價格,下圖可以看到基于Nitro的C5和I3.metal的延時明顯降低:
計算型存儲和數據庫
從AWS的營收看,網絡、存儲、計算和軟件是收入的四駕馬車,數據庫毫無疑問是存儲領域的關鍵場景。隨著云計算帶來基礎環境的改變,也直接加速云原生技術的發展和成熟,程序員不會再寫出單體(Monolithic)應用,也再也不會在應用中只使用一種數據庫。還是借用Werner Vogels的話
A one size fits all database doesn‘t fit anyone.
從AWS提供的數據庫服務也應證了一點(國內的云計算巨頭也類似)。
不同的數據庫針對不同的場景,比如Airbnb使用 Aurora 替代 MySQL,Snapchat 使用DynamoDB 承載起最大的寫負載,麥當勞將ElastiCache應用于低延時高吞吐的工作負載,旅游網站expedia.com使用ElasticSearch實時優化產品價格。當然,對于存儲介質,更快速和更大容量的需求普遍存在。從下面數據庫的工程實踐看,壓縮是實現這一目標的共識:
DB-Engines DBMS數據壓縮特性
DBMS
是否支持數據壓縮
Oracle
MySQL
Microsoft SQL Server
PostgreSQL
MongoDB
IBM Db2
Elasticsearch
Redis
SQLite
Cassandra
壓縮率依賴于數據本身,1948年由美國數學家克勞德·香農(Claude Shannon)在經典論文《通信的數學理論》中首先提出信息熵,理想情況下,不管是什么樣內容的數據,只要具有同樣的概率分布,就會得到同樣的壓縮率。
在實現時,常常要在壓縮吞吐,解壓吞吐,和犧牲壓縮率之間做取舍,這也是產生諸多壓縮算法的原因。下圖是基于Silesia compression corpus不同壓縮算法之間的差異。
Compressor Name
Ratio
CompressionDecompress
zstd 1.4.5 -1
2.884
500MB/S
1660MB/S
zlib 1.2.11 -1
2.743
90MB/S400MB/S
brotli 1.0.7 -0
2.703
400MB/S450MB/S
zstd 1.4.5--fast=1
2.434
570MB/S2200MB/S
zstd 1.4.5--fast=3
2.312
640MB/S2300MB/S
quicklz 1.5.0 -1
2.238
560MB/S710MB/S
zstd 1.4.5 --fast=5
2.178
700MB/S2420MB/S
lzo1x 2.10 -1
2.106
690MB/S820MB/S
lz4 1.9.2
2.101
740MB/S4530MB/S
lzf 3.6 -1
2.077
410MB/S860MB/S
snappy 1.1.8
2.073
560MB/S1790MB/S
從一個常見的場景出發,應用多次寫入壓縮率各不相同的數據,邏輯寫入量為36KB,如下圖所示:
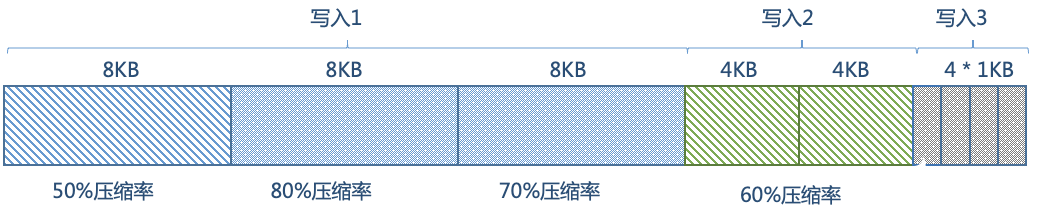
按照前面所示的壓縮率,最理想的情況是壓縮后占用15.2KB。
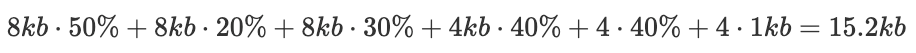
但現有的空間管理實踐會占用更多的物理空間,首先寫入時需要按照文件系統頁對齊寫入(假設4KB),占用物理空間為48KB,數據存儲分布如下圖所示:

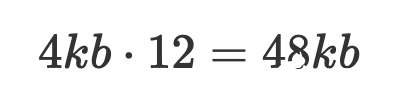
但因為壓縮后數據依然需要按照文件系統頁大小(4KB)對齊,數據存儲分布如下圖所示:
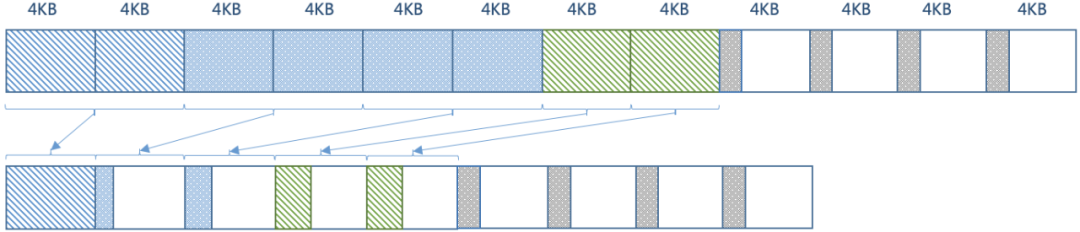
所以實際占用的物理空間是36KB離預期的壓縮率相去甚遠。
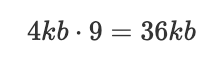
為進一步提升壓縮效率,通常會進一步壓實(compaction)空間,壓實后數據存儲分布如下:
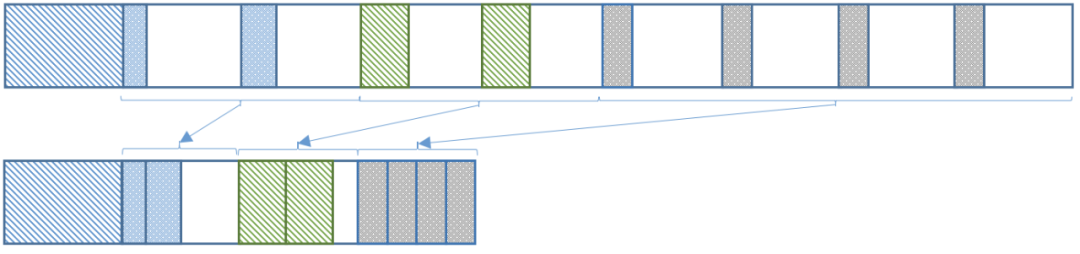
這時占用的物理空間是 16KB,才接近15.2KB。
可見在工程實踐時,要想在應用場景中獲得可觀的壓縮收益,僅關注數據結構和壓縮算法是不夠的,還要考慮壓實(Compaction)效率,如果還要兼顧算力消耗、IO延時和代碼復雜度等指標,工程難度將指數級提升。
針對這個場景,支持透明壓縮的計算型存儲 CSD2000,將壓縮解壓縮算法offload到盤內FPGA,使計算更靠近數據存儲的地方(“in-situ computing”),進一步縮短數據路徑,從而提升數據處理的效率。
對比“軟”壓縮(基于CPU)和硬壓縮(基于FPGA)兩者的收益并不復雜,下面以MySQL為例,將MySQL頁壓縮,MySQL表壓縮和CSD2000透明壓縮三者進行對比,采用TPC-C和TPC-E數據集和負載模型,以壓縮率和數據庫性能(TPS和時延)為指標衡量壓縮效率。
先看壓縮率,計算型存儲 CSD2000 提供更高的壓縮率,幾乎是MySQL自帶壓縮的2倍以上,如下所示:

再看性能,使用sysbench測試1/4/16/64/256/512并發下性能表現,可以觀察到(如下圖所示):
≥ 64并發時,CSD2000 QPS/TPS平均提高~5倍,最高提高~12倍,99%平均時延降低68%以上;
《64并發時,CSD2000 QPS/TPS普遍高于普通NVMe SSD 20%~50%,99%平均時延降低8%~45%;
說明:為了便于對比,以普通NVMe SSD指標為基線做歸一化。


Mark Callaghan (Facebook Distinguished Engineer)曾經吐槽在數據庫中實現透明頁壓縮并應用在生產環境,工程實現過于復雜,難怪Jens Axboe(Linux內核代碼主要貢獻者之一,FIO和IO_URING的作者)建議他把這些工作丟給計算型存儲公司 ScaleFlux。而從計算型存儲帶來的壓縮及性能(詳見:可計算存儲:數據壓縮和數據庫計算下推)收益來看已經超額完成任務。
計算型存儲和文件系統
壓縮同時減少數據寫入量(Nand Written)和寫放大(Write Amplification),但實際的情況會更復雜一些,大多數情況下數據庫運行在文件系統之上。
以日志型文件系統ext4為例,設計以下測試驗證日志寫入量與數據庫數據寫入量的比例及透明壓縮對于減少寫入量的收益:
選用 MySQL 和 MariaDB;
200GB數據集;
3種負載模型:Insert/Update-Index/Update-Non-Index;
兩種數據訪問方式:熱點集中(Non-uniform Key Distribution) 和全隨機(Uniform Key Distribution);
最終測試結果如下:
因為文件系統的 WAL(Write Ahead Log)機制,加上日志的稀疏結構,日志寫入量占整體寫入量20%~90%,可見文件系統日志寫入量可能大于上層應用(數據庫)的數據寫入量;
透明壓縮對于減少數據庫數據量的寫入效果明顯,對于減少日志系統寫入量的效果更加顯著,全部測試場景減少日志寫入量約4~5倍;
說明:以普通NVMe SSD指標為基線做歸一化,直方圖面積越小,數據寫入量越少。
人類的智慧注定都要在山頂相遇
亞馬遜經常談論單向(one-way)和雙向(two-way)門決策。雙向門決策容易逆轉,例如A/B test,這類決策可以快速采取行動,即使失敗,成本也不高。單向門決策大多數時候不可撤銷,必須”大膽假設,小心求證“。Nitro 顯而易見是一個單向(one-way)門決策,即便是2012年開始,AWS也花了足足7年時間才完整落地。
在異構計算領域,頭部云計算廠已經達成共識,相關產品也加速推出,包括支持計算下推的阿里云PolarDB(詳見:可計算存儲:數據壓縮和數據庫計算下推),以及 AWS re:Invent2020 再次提到的基于 AUQA(Advanced Query Accelerator) 節點加速的 Redshift。
風物長宜放眼量,人類的智慧注定都要在山頂相遇。
責任編輯:haq
-
存儲
+關注
關注
13文章
4502瀏覽量
87065 -
計算機
+關注
關注
19文章
7628瀏覽量
90172 -
AWS
+關注
關注
0文章
435瀏覽量
25087
發布評論請先 登錄
能效提升3倍!異構計算架構讓AI跑得更快更省電
RAKsmart智能算力架構:異構計算+低時延網絡驅動企業AI訓練范式升級
RK3399處理器:高性能多核異構計算平臺
異構計算的概念、核心、優勢、挑戰及考慮因素
【一文看懂】什么是異構計算?

詳解Arm計算平臺的優勢
一文詳解計算型存儲協議框架

澎峰科技高性能計算庫PerfIPP介紹
淺談國產異構雙核RISC-V+FPGA處理器AG32VF407的優勢和應用場景
打造異構計算新標桿!國數集聯發布首款CXL混合資源池參考設計

AvaotaA1全志T527開發板AMP異構計算簡介
異構計算:解鎖算力潛能的新途徑
智能時代的路,將由異構計算鋪就





 工商網監
工商網監
評論