") 干貨:直觀地解釋和可視化每個(gè)復(fù)雜的 DataFrame 操作
干貨:直觀地解釋和可視化每個(gè)復(fù)雜的 DataFrame 操作

大多數(shù)數(shù)據(jù)科學(xué)家可能會贊揚(yáng)Pandas進(jìn)行數(shù)據(jù)準(zhǔn)備的能力,但許多人可能無法利用所有這些能力。操作數(shù)據(jù)幀可能很快會成為一項(xiàng)復(fù)雜的任務(wù),因此在Pandas中的八種技術(shù)中均提供了說明,可視化,代碼和技巧來記住如何做。
Pandas提供了各種各樣的DataFrame操作,但是其中許多操作很復(fù)雜,而且似乎不太平易近人。本文介紹了8種基本的DataFrame操作方法,它們涵蓋了數(shù)據(jù)科學(xué)家需要知道的幾乎所有操作功能。每種方法都將包括說明,可視化,代碼以及記住它的技巧。
Pivot
透視表將創(chuàng)建一個(gè)新的“透視表”,該透視表將數(shù)據(jù)中的現(xiàn)有列投影為新表的元素,包括索引,列和值。初始DataFrame中將成為索引的列,并且這些列顯示為唯一值,而這兩列的組合將顯示為值。這意味著Pivot無法處理重復(fù)的值。
旋轉(zhuǎn)名為df的DataFrame的代碼如下:
記住:Pivot——是在數(shù)據(jù)處理領(lǐng)域之外——圍繞某種對象的轉(zhuǎn)向。在體育運(yùn)動中,人們可以繞著腳“旋轉(zhuǎn)”旋轉(zhuǎn):大熊貓的旋轉(zhuǎn)類似于。原始DataFrame的狀態(tài)圍繞DataFrame的中心元素旋轉(zhuǎn)到一個(gè)新元素。有些元素實(shí)際上是在旋轉(zhuǎn)或變換的(例如,列“bar”),因此很重要。
Melt
Melt可以被認(rèn)為是“不可透視的”,因?yàn)樗鼘⒒诰仃嚨臄?shù)據(jù)(具有二維)轉(zhuǎn)換為基于列表的數(shù)據(jù)(列表示值,行表示唯一的數(shù)據(jù)點(diǎn)),而樞軸則相反。考慮一個(gè)二維矩陣,其一維為“B”和“C”(列名),另一維為“a”,“b”和“c”(行索引)。
我們選擇一個(gè)ID,一個(gè)維度和一個(gè)包含值的列/列。包含值的列將轉(zhuǎn)換為兩列:一列用于變量(值列的名稱),另一列用于值(變量中包含的數(shù)字)。
結(jié)果是ID列的值(a,b,c)和值列(B,C)及其對應(yīng)值的每種組合,以列表格式組織。
可以像在DataFramedf上一樣執(zhí)行Mels操作:
記住:像蠟燭一樣融化(Melt)就是將凝固的復(fù)合物體變成幾個(gè)更小的單個(gè)元素(蠟滴)。融合二維DataFrame可以解壓縮其固化的結(jié)構(gòu)并將其片段記錄為列表中的各個(gè)條目。
Explode
是一種擺脫數(shù)據(jù)列表的有用方法。當(dāng)一列爆炸時(shí),其中的所有列表將作為新行列在同一索引下(為防止發(fā)生這種情況,此后只需調(diào)用.reset/_index()即可)。諸如字符串或數(shù)字之類的非列表項(xiàng)不受影響,空列表是NaN值(您可以使用.dropna()清除它們)。
在DataFramedf中Explode列“A”非常簡單:
要記住:Explode某物會釋放其所有內(nèi)部內(nèi)容-Explode列表會分隔其元素。
Stack
堆疊采用任意大小的DataFrame,并將列“堆疊”為現(xiàn)有索引的子索引。因此,所得的DataFrame僅具有一列和兩級索引。
堆疊名為df的表就像df.stack()一樣簡單。
為了訪問狗的身高值,只需兩次調(diào)用基于索引的檢索,例如df.loc ['dog']。loc ['height']。
要記住:從外觀上看,堆棧采用表的二維性并將列堆棧為多級索引。
Unstack
取消堆疊將獲取多索引DataFrame并對其進(jìn)行堆疊,將指定級別的索引轉(zhuǎn)換為具有相應(yīng)值的新DataFrame的列。在表上調(diào)用堆棧后再調(diào)用堆棧不會更改該堆棧(原因是存在“0”)。
堆疊中的參數(shù)是其級別。在列表索引中,索引為-1將返回最后一個(gè)元素。這與水平相同。級別-1表示將取消堆疊最后一個(gè)索引級別(最右邊的一個(gè))。作為另一個(gè)示例,當(dāng)級別設(shè)置為0(第一個(gè)索引級別)時(shí),其中的值將成為列,而隨后的索引級別(第二個(gè)索引級別)將成為轉(zhuǎn)換后的DataFrame的索引。
可以按照與堆疊相同的方式執(zhí)行堆疊,但是要使用level參數(shù):df.unstack(level = -1)。
Merge
合并兩個(gè)DataFrame是在共享的“鍵”之間按列(水平)組合它們。此鍵允許將表合并,即使它們的排序方式不一樣。完成的合并DataFrame默認(rèn)情況下會將后綴/_x和/_y添加到value列。
為了合并兩個(gè)DataFramedf1和df2(其中df1包含leftkey,而df2包含rightkey),請調(diào)用:
合并不是pandas的功能,而是附加到DataFrame。始終假定合并所在的DataFrame是“左表”,在函數(shù)中作為參數(shù)調(diào)用的DataFrame是“右表”,并帶有相應(yīng)的鍵。
默認(rèn)情況下,合并功能執(zhí)行內(nèi)部聯(lián)接:如果每個(gè)DataFrame的鍵名均未列在另一個(gè)鍵中,則該鍵不包含在合并的DataFrame中。另一方面,如果一個(gè)鍵在同一DataFrame中列出兩次,則在合并表中將列出同一鍵的每個(gè)值組合。例如,如果df1具有3個(gè)鍵foo值,而df2具有2個(gè)相同鍵的值,則在最終DataFrame中將有6個(gè)條目,其中l(wèi)eftkey = foo和rightkey = foo。
記住:合并數(shù)據(jù)幀就像在水平行駛時(shí)合并車道一樣。想象一下,每一列都是高速公路上的一條車道。為了合并,它們必須水平合并。
Join
通常,聯(lián)接比合并更可取,因?yàn)樗哂懈啙嵉恼Z法,并且在水平連接兩個(gè)DataFrame時(shí)具有更大的可能性。連接的語法如下:
使用聯(lián)接時(shí),公共鍵列(類似于合并中的right/_on和left/_on)必須命名為相同的名稱。how參數(shù)是一個(gè)字符串,它表示四種連接方法之一,可以合并兩個(gè)DataFrame:
'left':包括df1的所有元素,僅當(dāng)其鍵為df1的鍵時(shí)才包含df2的元素。否則,df2的合并DataFrame的丟失部分將被標(biāo)記為NaN。
'right':'left',但在另一個(gè)DataFrame上。包括df2的所有元素,僅當(dāng)其鍵是df2的鍵時(shí)才包含df1的元素。
“outer”:包括來自DataFrames所有元素,即使密鑰不存在于其他的-缺少的元素被標(biāo)記為NaN的。
“inner”:僅包含元件的鍵是存在于兩個(gè)數(shù)據(jù)幀鍵(交集)。默認(rèn)合并。
記住:如果您使用過SQL,則單詞“ join”應(yīng)立即與按列添加相聯(lián)系。如果不是,則“ join”和“ merge”在定義方面具有非常相似的含義。
Concat
合并和連接是水平工作,串聯(lián)或簡稱為concat,而DataFrame是按行(垂直)連接的。例如,考慮使用pandas.concat([df1,df2])串聯(lián)的具有相同列名的兩個(gè)DataFramedf1和df2:
盡管可以通過將axis參數(shù)設(shè)置為1來使用concat進(jìn)行列式聯(lián)接,但是使用聯(lián)接會更容易。
請注意,concat是pandas函數(shù),而不是DataFrame之一。因此,它接受要連接的DataFrame列表。
如果一個(gè)DataFrame的另一列未包含,默認(rèn)情況下將包含該列,缺失值列為NaN。為了防止這種情況,請?zhí)砑右粋€(gè)附加參數(shù)join ='inner',該參數(shù)只會串聯(lián)兩個(gè)DataFrame共有的列。
切記:在列表和字符串中,可以串聯(lián)其他項(xiàng)。串聯(lián)是將附加元素附加到現(xiàn)有主體上,而不是添加新信息(就像逐列聯(lián)接一樣)。由于每個(gè)索引/行都是一個(gè)單獨(dú)的項(xiàng)目,因此串聯(lián)將其他項(xiàng)目添加到DataFrame中,這可以看作是行的列表。
Append是組合兩個(gè)DataFrame的另一種方法,但它執(zhí)行的功能與concat相同,效率較低且用途廣泛。
-
審核編輯 黃昊宇
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7256瀏覽量
91850
發(fā)布評論請先 登錄
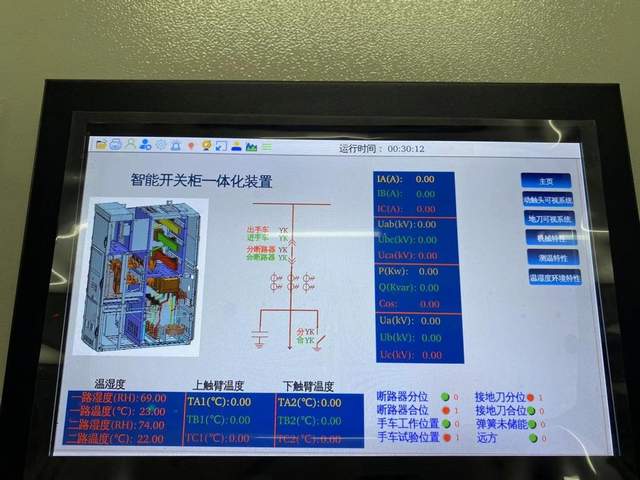
開關(guān)柜防誤可視化順控操作為什么有必要做?
工業(yè)設(shè)備可視化管理系統(tǒng)是什么

可視化組態(tài)物聯(lián)網(wǎng)平臺是什么
VirtualLab Fusion中的可視化設(shè)置
七款經(jīng)久不衰的數(shù)據(jù)可視化工具!
什么是大屏數(shù)據(jù)可視化?特點(diǎn)有哪些?
如何找到適合的大屏數(shù)據(jù)可視化系統(tǒng)
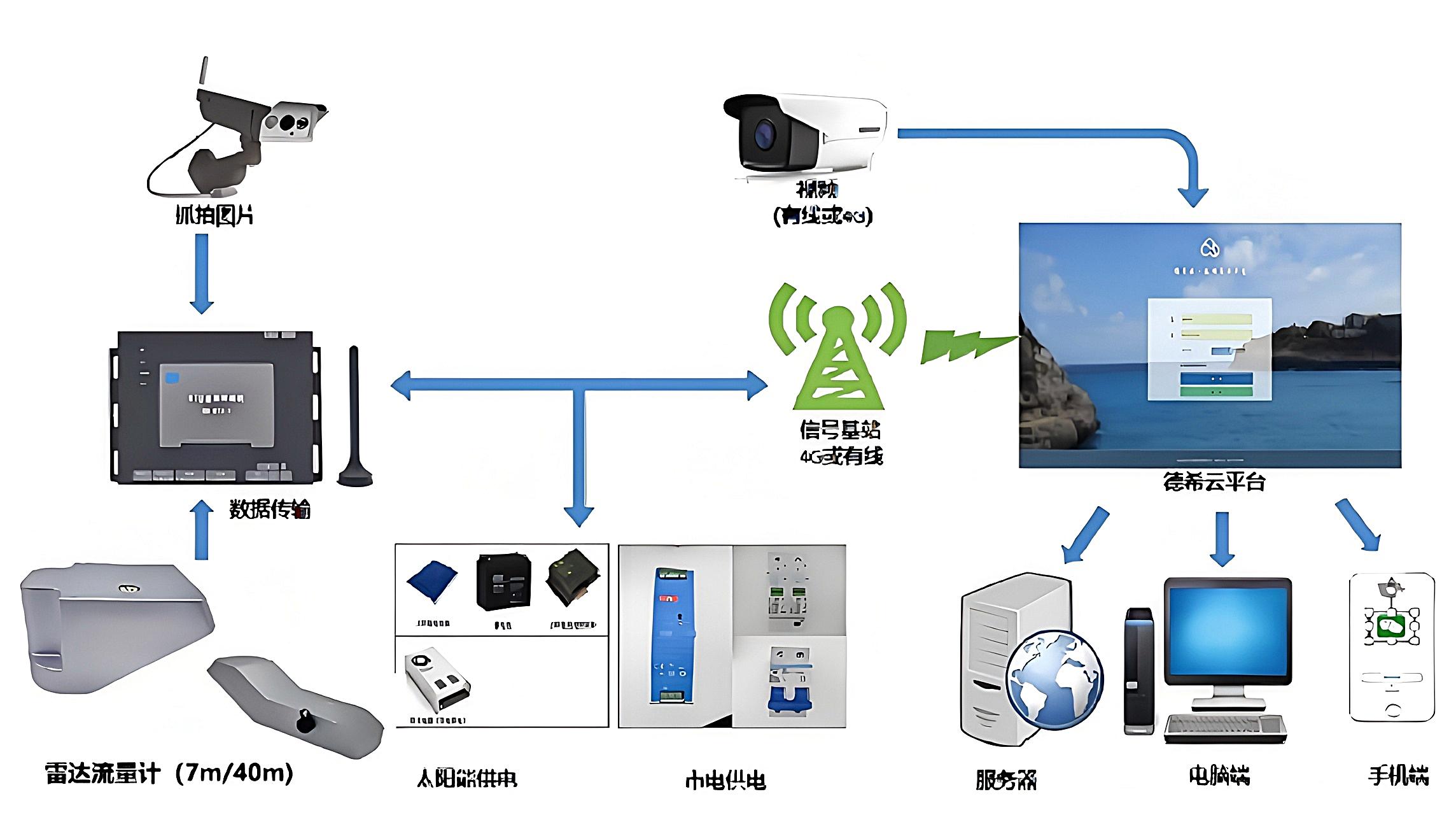
天然河道河流生態(tài)流量監(jiān)測系統(tǒng):直觀可視化界面,輕松解讀生態(tài)流量數(shù)據(jù)
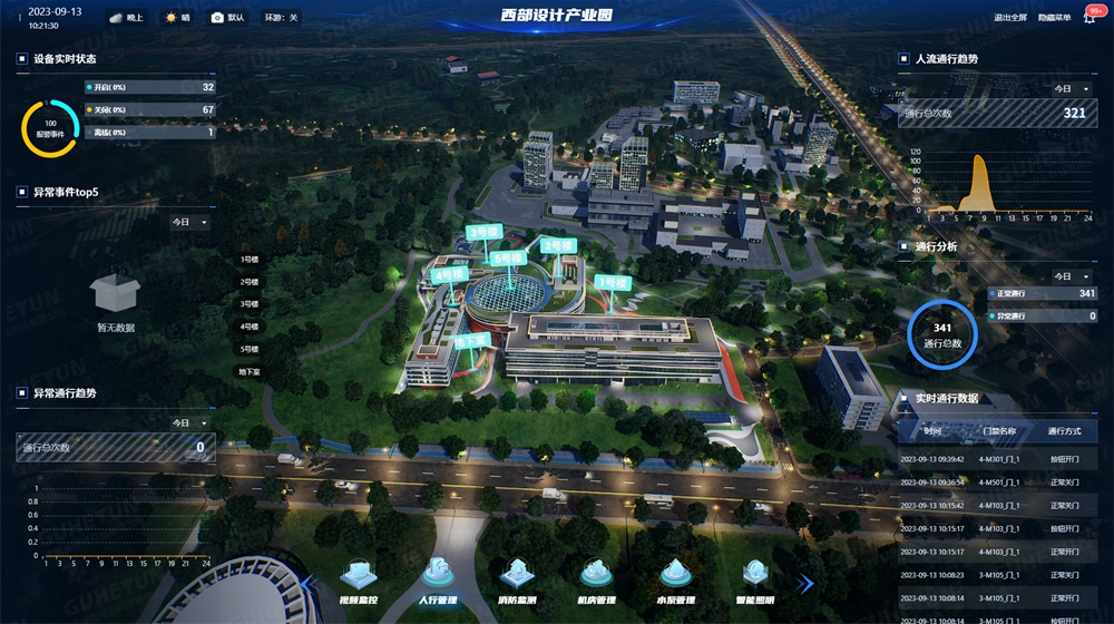
智慧能源可視化監(jiān)管平臺——助力可視化能源數(shù)據(jù)管理

智慧樓宇可視化的優(yōu)點(diǎn)
智慧園區(qū)數(shù)據(jù)可視化優(yōu)勢體現(xiàn)在哪些地方
開關(guān)柜可視化操作是什么?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論