") 機(jī)器視覺圖像處理之目標(biāo)檢測入門總結(jié)
機(jī)器視覺圖像處理之目標(biāo)檢測入門總結(jié)
本文首先介紹目標(biāo)檢測的任務(wù),然后介紹主流的目標(biāo)檢測算法或框架,重點(diǎn)為Faster R-CNN,SSD,YOLO三個(gè)檢測框架。本文內(nèi)容主要整理自網(wǎng)絡(luò)博客,用于普及性了解。
ps:由于之后可能會有一系列對象檢測的論文閱讀筆記,在論文閱讀之前,先大致了解一下目前的研究現(xiàn)狀,目標(biāo)檢測的各種主流方法的大致原理,以助于后面能更順暢看懂論文,后續(xù)再通過論文閱讀進(jìn)行細(xì)節(jié)學(xué)習(xí)。由于尚未閱讀相關(guān)論文原文,若有問題,歡迎指出!先獻(xiàn)上一個(gè)RCNN系列的圖。
Objection Detection Tasks
目前計(jì)算機(jī)視覺(CV,computer vision)與自然語言處理(Natural Language Process, NLP)及語音識別(Speech Recognition)并列為人工智能(AI,artificial intelligence)·機(jī)器學(xué)習(xí)(ML,machine learning)·深度學(xué)習(xí)(DL,deep learning)方向的三大熱點(diǎn)方向 。
而計(jì)算機(jī)視覺又有四個(gè)基本任務(wù)(關(guān)于這個(gè)任務(wù),說法不一,比如有些地方說到對象檢測detection、對象追蹤tracking、對象分割segmentation,不用拘泥),即圖像分類,對象定位及檢測,語義分割,實(shí)例分割。圖示如下:
a)圖像分類:一張圖像中是否包含某種物體
b)物體檢測識別:若細(xì)分該任務(wù)可得到兩個(gè)子任務(wù),即目標(biāo)檢測,與目標(biāo)識別,首先檢測是視覺感知得第一步,它盡可能搜索出圖像中某一塊存在目標(biāo)(形狀、位置)。而目標(biāo)識別類似于圖像分類,用于判決當(dāng)前找到得圖像塊得目標(biāo)具體是什么類別。
c)語義分割:按對象得內(nèi)容進(jìn)行圖像得分割,分割的依據(jù)是內(nèi)容,即對象類別。
d)實(shí)例分割:按對象個(gè)體進(jìn)行分割,分割的依據(jù)是單個(gè)目標(biāo)。
不管什么任務(wù),目標(biāo)檢測應(yīng)該是計(jì)算機(jī)視覺領(lǐng)域首先需要掌握的
Methods
傳統(tǒng)的計(jì)算機(jī)視覺問題的解決思路:圖像——預(yù)處理——人工特征(hand-crafted features)提取——分類。大部分研究集中在人工特征的構(gòu)造和分類算法上,涌現(xiàn)了很多杰出的工作。但存在的問題是人工設(shè)計(jì)的特征可能適用性并不強(qiáng),或者說泛化能力較弱,一類特征可能針對某類問題比較好,其他問題就效果甚微。
目前主流的深度學(xué)習(xí)解決思路:通過深度學(xué)習(xí)算法,進(jìn)行端到端的解決,即輸入圖像到輸出任務(wù)結(jié)果一步完成。但其實(shí)內(nèi)部它還是分stages的,通常是圖像——特征提取網(wǎng)絡(luò)——分類、回歸。
這里特征提取網(wǎng)絡(luò)即各種深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),針對這一算法的研究很多,比如說各層的設(shè)計(jì)細(xì)節(jié)(激活函數(shù),損失函數(shù),網(wǎng)絡(luò)結(jié)構(gòu)等)、可視化等,為了能提取更加強(qiáng)壯有效的特征,研究者考慮各種問題,如尺度不變性問題(通常用于解決小目標(biāo)的檢測,如特征金字塔網(wǎng)絡(luò),F(xiàn)eature Pyramid Network,F(xiàn)PN),整個(gè)網(wǎng)絡(luò)其實(shí)是分作兩類的,前N個(gè)層為第一部分,用于特征的提取,輸入的圖片,輸出的是特征圖,這與傳統(tǒng)的人工特征提取本質(zhì)上沒有太大區(qū)別,只是提取特征的算法變成了神經(jīng)網(wǎng)絡(luò)算法。而網(wǎng)絡(luò)的后K層是作為第二部分,完成具體的分類或者回歸任務(wù),任務(wù)的輸入是前一個(gè)部分得到的特征圖,輸出是任務(wù)的結(jié)果。所以顯然后一部分其實(shí)是可以被替代的,也確實(shí)有很多框架的第二部分采用其他機(jī)器學(xué)習(xí)的算法替代,如SVM。
所以需要對自己有個(gè)認(rèn)識!是做算法的研究(通常深度學(xué)習(xí)就是研究神經(jīng)網(wǎng)絡(luò)算法,如何讓它特征提取更強(qiáng)大、分類更準(zhǔn)確、速度更快,從網(wǎng)絡(luò)結(jié)構(gòu)、loss function、activation function等入手,需要強(qiáng)大的數(shù)學(xué)理論)?還是解決某個(gè)具體的問題(用已有的優(yōu)秀的神經(jīng)網(wǎng)絡(luò)算法,側(cè)重于研究解決問題的框架,當(dāng)然很多時(shí)候需要對已有的算法做些微調(diào))?
我粗淺的認(rèn)為前者更純理論,后者往往以工程為依托。
針對你的任務(wù),如何設(shè)計(jì)網(wǎng)絡(luò)?當(dāng)面對你的實(shí)際任務(wù)時(shí),如果你的目標(biāo)是解決該任務(wù)而不是發(fā)明新算法,那么不要試圖自己設(shè)計(jì)全新的網(wǎng)絡(luò)結(jié)構(gòu),也不要試圖從零復(fù)現(xiàn)現(xiàn)有的網(wǎng)絡(luò)結(jié)構(gòu)。找已經(jīng)公開的實(shí)現(xiàn)和預(yù)訓(xùn)練模型進(jìn)行微調(diào)。去掉最后一個(gè)全連接層和對應(yīng)softmax,加上對應(yīng)你任務(wù)的全連接層和softmax,再固定住前面的層,只訓(xùn)練你加的部分。如果你的訓(xùn)練數(shù)據(jù)比較多,那么可以多微調(diào)幾層,甚至微調(diào)所有層。
Algorithms
目標(biāo)檢測的基本思路:同時(shí)解決定位(localization) + 檢測(detection)。
多任務(wù)學(xué)習(xí),帶有兩個(gè)輸出分支。一個(gè)分支用于做圖像分類,即全連接+softmax判斷目標(biāo)類別,和單純圖像分類區(qū)別在于這里還另外需要一個(gè)“背景”類。另一個(gè)分支用于判斷目標(biāo)位置,即完成回歸任務(wù)輸出四個(gè)數(shù)字標(biāo)記包圍盒位置(例如中心點(diǎn)橫縱坐標(biāo)和包圍盒長寬),該分支輸出結(jié)果只有在分類分支判斷不為“背景”時(shí)才使用。
Region Proposal
為什么要有候選區(qū)域?既然目標(biāo)是在圖像中的某一個(gè)區(qū)域,那么最直接的方法就是滑窗法(sliding window approach),就是遍歷圖像的所有的區(qū)域,用不同大小的窗口在整個(gè)圖像上滑動,那么就會產(chǎn)生所有的矩形區(qū)域,然后再后續(xù)排查,思路簡單,但開銷巨大。
候選區(qū)域生成算法通常基于圖像的顏色、紋理、面積、位置等合并相似的像素,最終可以得到一系列的候選矩陣區(qū)域。這些算法,如selective search或EdgeBoxes,通常只需要幾秒的CPU時(shí)間,而且,一個(gè)典型的候選區(qū)域數(shù)目是2k,相比于用滑動窗把圖像所有區(qū)域都滑動一遍,基于候選區(qū)域的方法十分高效。另一方面,這些候選區(qū)域生成算法的查準(zhǔn)率(precision)一般,但查全率(recall)通常比較高,這使得我們不容易遺漏圖像中的目標(biāo)。
Selective Search
“Segmentation as selective search for object recognition”,ICCV,2011.
“Selective search for object recognition.” International journal of computer vision ,2013
論文應(yīng)該是有兩部分內(nèi)容,一部分是Selective Search的方法尋找候選區(qū)域,第二部分為該區(qū)域上的特征提取及后續(xù)的分類。由于目前特征提取和分類都采用了深度學(xué)習(xí)方法,所以只是借鑒其候選區(qū)尋找算法Selective Search。
將圖像劃分成很多的小區(qū)域(regions)
如何將圖像劃分成很多的小區(qū)域? 劃分的方式應(yīng)該有很多種,比如:
1)等間距劃分grid cell,這樣劃分出來的區(qū)域每個(gè)區(qū)域的大小相同,但是每個(gè)區(qū)域里面包含的像素分布不均勻,隨機(jī)性大;同時(shí),不能滿足目標(biāo)多尺度的要求(當(dāng)然,可以用不同的尺度劃分grid cell,這稱為Exhaustive Search, 計(jì)算復(fù)雜度太大)!
2)使用邊緣保持超像素劃分;
3)使用本文提出的Selective Search(SS)的方法來找到最可能的候選區(qū)域;
其實(shí)這一步可以看做是對圖像的過分割,都是過分割,本文SS方法的過人之處在于預(yù)先劃分的區(qū)域什么大小的都有(滿足目標(biāo)多尺度的要求),而且對過分割的區(qū)域還有一個(gè)合并的過程(區(qū)域的層次聚類),最后剩下的都是那些最可能的候選區(qū)域,然后在這些已經(jīng)過濾了一遍的區(qū)域上進(jìn)行后續(xù)的識別等處理,這樣的話,將會大大減小候選區(qū)域的數(shù)目,提供了算法的速度.
下圖說明目標(biāo)的多尺度:
總體思路:假設(shè)現(xiàn)在圖像上有n個(gè)預(yù)分割的區(qū)域,表示為R={R1, R2, …, Rn}, 計(jì)算每個(gè)region與它相鄰region(注意是相鄰的區(qū)域)的相似度,這樣會得到一個(gè)n*n的相似度矩陣(同一個(gè)區(qū)域之間和一個(gè)區(qū)域與不相鄰區(qū)域之間的相似度可設(shè)為NaN),從矩陣中找出最大相似度值對應(yīng)的兩個(gè)區(qū)域,將這兩個(gè)區(qū)域合二為一,這時(shí)候圖像上還剩下n-1個(gè)區(qū)域; 重復(fù)上面的過程(只需要計(jì)算新的區(qū)域與它相鄰區(qū)域的新相似度,其他的不用重復(fù)計(jì)算),重復(fù)一次,區(qū)域的總數(shù)目就少1,知道最后所有的區(qū)域都合并稱為了同一個(gè)區(qū)域(即此過程進(jìn)行了n-1次,區(qū)域總數(shù)目最后變成了1).算法的流程圖如下圖所示:
step0:生成區(qū)域集R,具體參見論文《Efficient Graph-Based Image Segmentation》,基于圖的圖像分割,也就是說起點(diǎn)還是圖像分割
step1:計(jì)算區(qū)域集R里每個(gè)相鄰區(qū)域的相似度S={s1,s2,…}
step2:找出相似度最高的兩個(gè)區(qū)域,將其合并為新集,添加進(jìn)R
step3:從S中移除所有與step2中有關(guān)的子集
step4:計(jì)算新集與所有子集的相似度
step5:跳至step2,直至S為空
相似度計(jì)算:論文從四個(gè)方面考慮相似度度量——顏色、紋理、尺寸和空間交疊
EdgeBoxes
Edge Boxes: Locating Object Proposals from Edges ,ECCV2014
文章沒有涉及到“機(jī)器學(xué)習(xí)”,采用的是純圖像的方法。
研究方法:利用邊緣信息(Edge),確定box內(nèi)的輪廓個(gè)數(shù)和與box邊緣重疊的edge個(gè)數(shù)(知道一個(gè)box內(nèi)完全包含的輪廓個(gè)數(shù),那么目標(biāo)有很大可能性,就在這個(gè)box中),基于此對box進(jìn)行評分,進(jìn)一步根據(jù)得分的高低順序確定proposal信息(由大小,長寬比,位置構(gòu)成)。而后續(xù)工作就是在proposal內(nèi)部運(yùn)行相關(guān)檢測算法。
matlab 代碼:https://github.com/pdollar/edges
建議參考博客:《Edge Boxes: Locating Object Proposals from Edges》讀后感 :https://blog.csdn.net/wsj998689aa/article/details/39476551
R-CNN
“Rich feature hierarchies for accurate object detection and semantic segmentation.” CVPR 2014
卷積神經(jīng)網(wǎng)絡(luò)進(jìn)入目標(biāo)識別的里程碑,R-CNN,直接看圖了解其結(jié)構(gòu)!
流程:原圖——Selective Search得到2K Proposal Regions —— Warpped image region(?) —— ConvNet —— 分類(svm) + 回歸(bounding box regression)。
這里的Warpped Image Region應(yīng)該是一種類似resize的操作,將不同大小的proposal region統(tǒng)一到相同的尺寸,用以輸入相同的ConvNet,上面的Convnet是相同的,但SVM分類器是針對每一個(gè)類別單獨(dú)訓(xùn)練好的,是不同的分類器。
R-CNN,是基于這樣一種非常簡單的想法,對于輸入圖像,通過selective search方法,先確定出例如2000個(gè)最有可能包含物體的窗口,對于這2000個(gè)窗口,我們希望它能夠?qū)Υ龣z測物體達(dá)到非常高的召回率。然后對這2000個(gè)中的每一個(gè)去用CNN進(jìn)行特征提取和分類。對這2000個(gè)區(qū)域都要去跑一次CNN,那么它的速度是非常慢的,即使每次只需要0.5秒,2000個(gè)窗口的話也是需要1000秒,為了加速2014年的時(shí)候何凱明提出了SPP-net,其做法是對整個(gè)圖跑一次CNN,而不需要每一個(gè)窗口單獨(dú)做,但是這樣有一個(gè)小困難,就是這2000個(gè)候選窗口每一個(gè)的大小都不一樣,為了解決這個(gè)問題,SPP-net設(shè)計(jì)了spatial pyramid pooling,使得不同大的小窗口具有相同維度的特征。這個(gè)方法使得檢測時(shí)不需要對每一個(gè)候選窗口去計(jì)算卷積,但是還是不夠快,檢測一張圖像還是需要幾秒的時(shí)間。
存在的不足:
1)多個(gè)候選區(qū)域?qū)?yīng)的圖像需要預(yù)先提取,占用較大的磁盤空間;
2)針對傳統(tǒng)CNN需要固定尺寸的輸入圖像,crop/warp(歸一化)產(chǎn)生物體截?cái)嗷蚶欤瑫?dǎo)致輸入CNN的信息丟失;
3)每一個(gè)ProposalRegion都需要進(jìn)入CNN網(wǎng)絡(luò)計(jì)算,上千個(gè)Region存在大量的范圍重疊,重復(fù)的特征提取帶來巨大的計(jì)算浪費(fèi)。
SPP-Net
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,ECCV 2014,Kaiming He
各個(gè)Proposal Region大小不一,全圖只卷積一次的話,就不需要經(jīng)過Wrapp,在特征圖上找這些Region的時(shí)候還是存在大小不一的問題,由于維度不同,后面的全連接層FC的輸入無法統(tǒng)一,故采用SPP,空間金字塔池化,這樣不同尺寸的Region通過不同金字塔池化層,從而得到統(tǒng)一維度的輸出,加速算法同時(shí),兼顧了尺度問題。
在R-CNN中,要求輸入固定大小的圖片,因此需要對圖片進(jìn)行crop、wrap變換,改變尺寸引起的形變影響檢測效果。此外,對每一個(gè)圖像中每一個(gè)proposal進(jìn)行一遍CNN前向特征提取,如果是2000個(gè)propsal,需要2000次前向CNN特征提取,這無疑將浪費(fèi)很多時(shí)間。
該論文對R-CNN中存在的缺點(diǎn)進(jìn)行了改進(jìn),基本思想是,輸入整張圖像,提取出整張圖像的特征圖,然后利用空間關(guān)系從整張圖像的特征圖中,在spatial pyramid pooling layer提取各個(gè)region proposal的特征。
1)取消了crop/warp圖像歸一化過程,解決圖像變形導(dǎo)致的信息丟失以及存儲問題;
2)采用空間金字塔池化(SpatialPyramid Pooling )替換了 全連接層之前的最后一個(gè)池化層(上圖top),翠平說這是一個(gè)新詞,我們先認(rèn)識一下它。
SPP主要有兩個(gè)特點(diǎn):
結(jié)合空間金字塔方法實(shí)現(xiàn)CNNs的對尺度輸入。
一般CNN后接全連接層或者分類器,他們都需要固定的輸入尺寸,因此不得不對輸入數(shù)據(jù)進(jìn)行crop或者warp,這些預(yù)處理會造成數(shù)據(jù)的丟失或幾何的失真。SPP Net的第一個(gè)貢獻(xiàn)就是將金字塔思想加入到CNN,實(shí)現(xiàn)了數(shù)據(jù)的多尺度輸入。
如下圖所示,在卷積層和全連接層之間加入了SPP layer。此時(shí)網(wǎng)絡(luò)的輸入可以是任意尺度的,在SPP layer中每一個(gè)pooling的filter會根據(jù)輸入調(diào)整大小,而SPP的輸出尺度始終是固定的。
只對原圖提取一次卷積特征
在R-CNN中,每個(gè)候選框先resize到統(tǒng)一大小,然后分別作為CNN的輸入,這樣是很低效的。所以SPP Net根據(jù)這個(gè)缺點(diǎn)做了優(yōu)化:只對原圖進(jìn)行一次卷積得到整張圖的feature map,然后找到每個(gè)候選框在feature map上的映射patch,將此patch作為每個(gè)候選框的卷積特征輸入到SPP layer和之后的層。節(jié)省了大量的計(jì)算時(shí)間,比R-CNN有一百倍左右的提速。
存在的不足:
1)和RCNN一樣,訓(xùn)練過程仍然是隔離的,提取候選框 | 計(jì)算CNN特征| SVM分類 | Bounding Box回歸獨(dú)立訓(xùn)練,大量的中間結(jié)果需要轉(zhuǎn)存,無法整體訓(xùn)練參數(shù);
2)SPP-Net在無法同時(shí)Tuning在SPP-Layer兩邊的卷積層和全連接層,很大程度上限制了深度CNN的效果;
3)在整個(gè)過程中,Proposal Region仍然很耗時(shí)。
Fast R-CNN
“Fast r-cnn.” ICCV 2015. Girshick, Ross.
R-CNN的進(jìn)階版Fast R-CNN就是在RCNN的基礎(chǔ)上采納了SPP Net方法,對RCNN作了改進(jìn),使得性能進(jìn)一步提高。
Fast R-CNN借鑒了SPP-net的做法,在全圖上進(jìn)行卷積,然后采用ROI-pooling得到定長的特征向量,例如不管窗口大小是多少,轉(zhuǎn)換成7x7這么大。Fast R-CNN還引入了一個(gè)重要的策略,在對窗口進(jìn)行分類的同時(shí),還會對物體的邊框進(jìn)行回歸,使得檢測框更加準(zhǔn)確。前面我們說候選窗口會有非常高的召回率,但是可能框的位置不是很準(zhǔn),例如一個(gè)人體框可能是缺胳膊缺腿,那么通過回歸就能夠?qū)z測框進(jìn)行校準(zhǔn),在初始的位置上求精。Fast R-CNN把分類和回歸放在一起來做,采用了多任務(wù)協(xié)同學(xué)習(xí)的方式。
ROI Pooling(region of interest pooling)
興趣區(qū)域匯合旨在由任意大小的候選區(qū)域?qū)?yīng)的局部卷積特征提取得到固定大小的特征,這是因?yàn)橄乱徊降膬煞种ЬW(wǎng)絡(luò)由于有全連接層,需要其輸入大小固定。其做法是,先將候選區(qū)域投影到卷積特征上,再把對應(yīng)的卷積特征區(qū)域空間上劃分成固定數(shù)目的網(wǎng)格(數(shù)目根據(jù)下一步網(wǎng)絡(luò)希望的輸入大小確定,例如VGGNet需要7×7的網(wǎng)格),最后在每個(gè)小的網(wǎng)格區(qū)域內(nèi)進(jìn)行最大匯合,以得到固定大小的匯合結(jié)果。和經(jīng)典最大匯合一致,每個(gè)通道的興趣區(qū)域匯合是獨(dú)立的。
Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,NIPS 2015
之前的Fast R-CNN已經(jīng)基本實(shí)現(xiàn)端到端的檢測,而主要的速度瓶頸是在Selective Search算法實(shí)現(xiàn)的Region Proposal,故到了Faster R-CNN,主要是解決Region Proposal問題,以實(shí)現(xiàn)Real-Time檢測。Faster R-CNN的主要思路是,既然檢測工作是在卷積的結(jié)果Feature Map上做的,那么候選區(qū)域的選取是否也能在Feature Map上做?于是RPN網(wǎng)絡(luò)(Region Proposal Network)應(yīng)運(yùn)而生。
候選框提取不一定要在原圖上做,特征圖上同樣可以,低分辨率特征圖意味著更少的計(jì)算量,基于這個(gè)假設(shè),MSRA的任少卿等人提出RPN(RegionProposal Network),整體架構(gòu)如下圖所示
通過添加額外的RPN分支網(wǎng)絡(luò),將候選框提取合并到深度網(wǎng)絡(luò)中,這正是Faster-RCNN里程碑式的貢獻(xiàn) !
RPN引入了所謂anchor box的設(shè)計(jì),具體來說,RPN在最后一個(gè)卷積層輸出的特征圖上,先用3x3的卷積得到每個(gè)位置的特征向量,然后基于這個(gè)特征向量去回歸9個(gè)不同大小和長寬比的窗口,如果特征圖的大小是40x60,那么總共就會有大約2萬多個(gè)窗口,把這些窗口按照信度進(jìn)行排序,然后取前300個(gè)作為候選窗口,送去做最終的分類 。
Faster實(shí)現(xiàn)了端到端的檢測,并且?guī)缀踹_(dá)到了效果上的最優(yōu),但小物體的識別還存在問題,故SSD算法誕生;速度方向的改進(jìn)仍有余地,于是YOLO誕生了。
SSD
SSD算法是一種直接預(yù)測目標(biāo)類別和bounding box的多目標(biāo)檢測算法。與faster rcnn相比,該算法沒有生成 proposal 的過程,這就極大提高了檢測速度。針對不同大小的目標(biāo)檢測,傳統(tǒng)的做法是先將圖像轉(zhuǎn)換成不同大小(圖像金字塔),然后分別檢測,最后將結(jié)果綜合起來(NMS)。而SSD算法則利用不同卷積層的feature map進(jìn)行綜合也能達(dá)到同樣的效果。算法的主網(wǎng)絡(luò)結(jié)構(gòu)是VGG16,將最后兩個(gè)全連接層改成卷積層,并隨后增加了4個(gè)卷積層來構(gòu)造網(wǎng)絡(luò)結(jié)構(gòu)。對其中5種不同的卷積層的輸出(feature map)分別用兩個(gè)不同的3×3的卷積核進(jìn)行卷積,一個(gè)輸出分類用的confidence,每個(gè)default box生成21個(gè)類別confidence;一個(gè)輸出回歸用的localization,每個(gè)default box生成4個(gè)坐標(biāo)值(x, y, w, h)。此外,這5個(gè)feature map還經(jīng)過PriorBox層生成prior box(生成的是坐標(biāo))。上述5個(gè)feature map中每一層的default box的數(shù)量是給定的(8732個(gè))。最后將前面三個(gè)計(jì)算結(jié)果分別合并然后傳給loss層。

YOLO
2015年出現(xiàn)了一個(gè)名為YOLO的方法,其最終發(fā)表在CVPR 2016上。這是一個(gè)蠻奇怪的方法,對于給定的輸入圖像,YOLO不管三七二十一最終都劃分出7x7的網(wǎng)格,也就是得到49個(gè)窗口,然后在每個(gè)窗口中去預(yù)測兩個(gè)矩形框。這個(gè)預(yù)測是通過全連接層來完成的,YOLO會預(yù)測每個(gè)矩形框的4個(gè)參數(shù)和其包含物體的信度,以及其屬于每個(gè)物體類別的概率。YOLO的速度很快,在GPU上可以達(dá)到45fps。
YOLO的處理步驟為:把輸入圖片縮放到448×448大小;運(yùn)行卷積網(wǎng)絡(luò);對模型置信度卡閾值,得到目標(biāo)位置與類別。對VOC數(shù)據(jù)集來說,YOLO就是把圖片統(tǒng)一縮放到448×448,然后每張圖平均劃分為7×7=49個(gè)小格子,每個(gè)格子預(yù)測2個(gè)矩形框及其置信度,以及20種類別的概率。舍棄了Region proposal階段,加快了速度,但是定位精度比較低,與此同時(shí)帶來的問題是,分類的精度也比較低。在各類數(shù)據(jù)集上的平均表現(xiàn)大概為54.5%mAP。
總結(jié)一下RCNN系列算法的步驟:
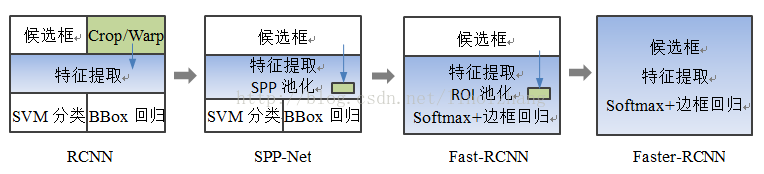
RCNN
在圖像中確定約1000-2000個(gè)候選框 (使用選擇性搜索)
每個(gè)候選框內(nèi)圖像塊縮放至相同大小,并輸入到CNN內(nèi)進(jìn)行特征提取
對候選框中提取出的特征,使用分類器判別是否屬于一個(gè)特定類
對于屬于某一特征的候選框,用回歸器進(jìn)一步調(diào)整其位置
Fast RCNN
在圖像中確定約1000-2000個(gè)候選框 (使用選擇性搜索)
對整張圖片輸進(jìn)CNN,得到feature map
找到每個(gè)候選框在feature map上的映射patch,將此patch作為每個(gè)候選框的卷積特征輸入到SPP layer和之后的層
對候選框中提取出的特征,使用分類器判別是否屬于一個(gè)特定類
對于屬于某一特征的候選框,用回歸器進(jìn)一步調(diào)整其位置
Faster RCNN
對整張圖片輸進(jìn)CNN,得到feature map
卷積特征輸入到RPN,得到候選框的特征信息
對候選框中提取出的特征,使用分類器判別是否屬于一個(gè)特定類
對于屬于某一特征的候選框,用回歸器進(jìn)一步調(diào)整其位置
三者比較
| 方法 | 創(chuàng)新 | 缺點(diǎn) | 改進(jìn) |
|---|---|---|---|
| R-CNN (Region-based Convolutional Neural Networks) | 1、SS提取RP;2、CNN提取特征;3、SVM分類;4、BB盒回歸。 | 1、 訓(xùn)練步驟繁瑣(微調(diào)網(wǎng)絡(luò)+訓(xùn)練SVM+訓(xùn)練bbox);2、 訓(xùn)練、測試均速度慢 ;3、 訓(xùn)練占空間 | 1、 從DPM HSC的34.3%直接提升到了66%(mAP);2、 引入RP+CNN |
| Fast R-CNN (Fast Region-based Convolutional Neural Networks) | 1、SS提取RP;2、CNN提取特征;3、softmax分類;4、多任務(wù)損失函數(shù)邊框回歸。 | 1、 依舊用SS提取RP(耗時(shí)2-3s,特征提取耗時(shí)0.32s);2、 無法滿足實(shí)時(shí)應(yīng)用,沒有真正實(shí)現(xiàn)端到端訓(xùn)練測試;3、 利用了GPU,但是區(qū)域建議方法是在CPU上實(shí)現(xiàn)的。 | 1、 由66.9%提升到70%;2、 每張圖像耗時(shí)約為3s。 |
| Faster R-CNN (Fast Region-based Convolutional Neural Networks) | 1、RPN提取RP;2、CNN提取特征;3、softmax分類;4、多任務(wù)損失函數(shù)邊框回歸。 | 1、 還是無法達(dá)到實(shí)時(shí)檢測目標(biāo);2、 獲取region proposal,再對每個(gè)proposal分類計(jì)算量還是比較大。 | 1、 提高了檢測精度和速度;2、 真正實(shí)現(xiàn)端到端的目標(biāo)檢測框架;3、 生成建議框僅需約10ms。 |
原文標(biāo)題:圖像處理之目標(biāo)檢測入門總結(jié)
文章出處:【微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
41038 -
機(jī)器視覺
+關(guān)注
關(guān)注
163文章
4514瀏覽量
122308 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8492瀏覽量
134122
原文標(biāo)題:圖像處理之目標(biāo)檢測入門總結(jié)
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
工業(yè)相機(jī)圖像采集卡:機(jī)器視覺的核心樞紐






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論