") 機器學(xué)習(xí)四種常用的優(yōu)化策略解析
機器學(xué)習(xí)四種常用的優(yōu)化策略解析

從智能手機到航天器,機器學(xué)習(xí)算法無處不在。他們會告訴您明天的天氣預(yù)報,將一種語言翻譯成另一種語言,并建議您接下來想在設(shè)備上看什么電視連續(xù)劇。這些算法會根據(jù)數(shù)據(jù)自動調(diào)整(學(xué)習(xí))其內(nèi)部參數(shù)。但是,有一部分參數(shù)是無法學(xué)習(xí)的,必須由專家進行配置。這些參數(shù)通常被稱為“超參數(shù)”,隨著AI的使用增加,它們對我們的生活產(chǎn)生重大影響。
例如,決策樹模型中的樹深度和人工神經(jīng)網(wǎng)絡(luò)中的層數(shù)是典型的超參數(shù)。模型的性能在很大程度上取決于其超參數(shù)的選擇。對于中等深度的樹,決策樹可能會產(chǎn)生良好的結(jié)果,而對于非常深的樹,決策樹的性能將很差。如果我們要手動運行,最佳超參數(shù)的選擇更是藝術(shù)性。實際上,超參數(shù)值的最佳選擇取決于當前的問題。
由于算法,目標,數(shù)據(jù)類型和數(shù)據(jù)量從一個項目到另一個項目都發(fā)生了很大變化,因此沒有適合所有模型和所有問題的超參數(shù)值的最佳選擇。相反,必須在每個機器學(xué)習(xí)項目的上下文中優(yōu)化超參數(shù)。
在本文中,我們將從回顧優(yōu)化策略的功能開始,然后概述四種常用的優(yōu)化策略:
- 網(wǎng)格搜索
- 隨機搜尋
- 爬山
- 貝葉斯優(yōu)化
- 優(yōu)化策略
即使有專家深入的領(lǐng)域知識,手動優(yōu)化模型超參數(shù)的任務(wù)也可能非常耗時。另一種方法是讓專家離開,并采用自動方法。根據(jù)某種性能指標來檢測給定項目中給定模型的最佳超參數(shù)集的自動過程稱為優(yōu)化策略。
典型的優(yōu)化過程定義了可能的超參數(shù)集以及針對該特定問題要最大化或最小化的度量。因此,實際上,任何優(yōu)化過程都遵循以下經(jīng)典步驟:
1)將手頭的數(shù)據(jù)分為訓(xùn)練和測試子集
2)重復(fù)優(yōu)化循環(huán)固定次數(shù)或直到滿足條件:
a)選擇一組新的模型超參數(shù)
b)使用選定的超參數(shù)集在訓(xùn)練子集上訓(xùn)練模型
c)將模型應(yīng)用于測試子集并生成相應(yīng)的預(yù)測
d)使用針對當前問題的適當評分標準(例如準確性或平均絕對誤差)評估測試預(yù)測。存儲與選定的超參數(shù)集相對應(yīng)的度量標準值
3)比較所有度量值,然后選擇產(chǎn)生最佳度量值的超參數(shù)集
問題是如何從步驟2d返回到步驟2a,以進行下一次迭代。也就是說,如何選擇下一組超參數(shù),確保它實際上比上一組更好。我們希望優(yōu)化循環(huán)朝著合理的解決方案發(fā)展,即使它可能不是最佳解決方案。換句話說,我們要合理確定下一組超參數(shù)是對上一組的改進。
典型的優(yōu)化過程將機器學(xué)習(xí)模型視為黑匣子。這意味著在每個選定的超參數(shù)集的每次迭代中,我們感興趣的只是由選定指標測量的模型性能。我們不需要(想要)知道黑匣子內(nèi)部發(fā)生了什么變化。我們只需要轉(zhuǎn)到下一個迭代并迭代下一個性能評估,依此類推。
所有不同優(yōu)化策略中的關(guān)鍵因素是如何根據(jù)步驟2d中先前的度量標準輸出,在步驟2a中選擇下一組超參數(shù)值。因此,對于一個簡化的實驗,我們省略了對黑盒的訓(xùn)練和測試,我們專注于度量計算(數(shù)學(xué)函數(shù))和選擇下一組超參數(shù)的策略。此外,我們用任意數(shù)學(xué)函數(shù)替換了度量計算,并用函數(shù)參數(shù)替換了一組模型超參數(shù)。
通過這種方式,優(yōu)化循環(huán)運行得更快,并盡可能保持通用。進一步的簡化是使用僅具有一個超參數(shù)的函數(shù),以實現(xiàn)簡單的可視化。下面是我們用來演示四種優(yōu)化策略的函數(shù)。我們想強調(diào)的是,任何其他數(shù)學(xué)函數(shù)也可以起作用。
f(x)= sin(x / 2)+0.5?sin(2?x)+0.25?cos(4.5?x)
這種簡化的設(shè)置使我們可以在一個簡單的xy圖上可視化一個超參數(shù)的實驗值和相應(yīng)的函數(shù)值。在x軸上是超參數(shù)值,在y軸上是函數(shù)輸出。然后,根據(jù)描述超參數(shù)序列生成中的點位置的白紅色漸變對(x,y)點進行著色。
白點對應(yīng)于該過程中較早生成的超參數(shù)值。紅點對應(yīng)于此過程中稍后生成的超參數(shù)值。此漸變著色將在以后用于說明優(yōu)化策略之間的差異時很有用。在這種簡化的用例中,優(yōu)化過程的目標是找到一個使函數(shù)值最大化的超參數(shù)。讓我們開始回顧四種常見的優(yōu)化策略,這些策略用于為優(yōu)化循環(huán)的下一次迭代標識新的超參數(shù)值集。
這是基本的蠻力策略。如果您不知道嘗試使用哪些值,則可以全部嘗試。功能評估中使用固定步長范圍內(nèi)的所有可能值。
例如,如果范圍為[0,10],步長為0.1,那么我們將獲得超參數(shù)值的序列(0、0.1、0.2、0.3,…9.5、9.6、9.7、9.8、9.9、10) 。在網(wǎng)格搜索策略中,我們?yōu)檫@些超參數(shù)值的每一個計算函數(shù)輸出。因此,網(wǎng)格越細,我們越接近最優(yōu)值,但是所需的計算資源也就越高。
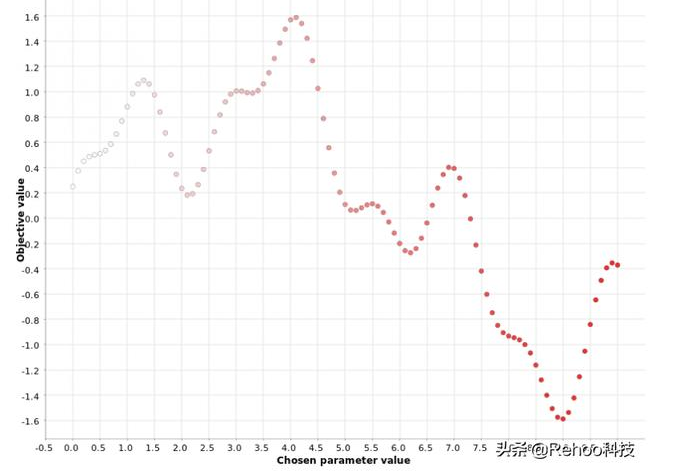
使用步驟0.1在[0,10]范圍內(nèi)對超參數(shù)值進行網(wǎng)格搜索。顏色梯度反映了在生成的超參數(shù)候選序列中的位置。白點
如圖所示,從小到大掃描超參數(shù)的范圍。網(wǎng)格搜索策略在單個參數(shù)的情況下可以很好地工作,但是當必須同時優(yōu)化多個參數(shù)時,它的效率將非常低下。
隨機搜尋
對于隨機搜索策略,顧名思義,超參數(shù)的值是隨機選擇的。在多個超參數(shù)的情況下,通常首選此策略,并且當某些超參數(shù)對最終指標的影響大于其他參數(shù)時,此策略特別有效。
同樣,在[0,10]范圍內(nèi)生成超參數(shù)值。然后,隨機生成固定數(shù)量的超參數(shù)。可以使用固定數(shù)量的預(yù)定義超參數(shù)進行試驗,您可以控制此優(yōu)化策略的持續(xù)時間和速度。N越大,達到最佳狀態(tài)的可能性越高,但是所需的計算資源也就越高。

在[0,10]范圍內(nèi)隨機搜索超參數(shù)值。顏色梯度反映了在生成的超參數(shù)候選序列中的位置。白點對應(yīng)于過程中較早
不出所料,來自生成序列的超參數(shù)值沒有降序或升序使用:白色和紅色點在圖中隨機混合。
爬山
在爬坡,在每次迭代的方式選擇在超參數(shù)空間選擇下一個超參數(shù)值的最佳方向。如果沒有相鄰改善最終指標,則優(yōu)化循環(huán)將停止。
請注意,此過程在一個重要方面與網(wǎng)格搜索和隨機搜索不同:選擇下一個超參數(shù)值時要考慮先前迭代的結(jié)果。
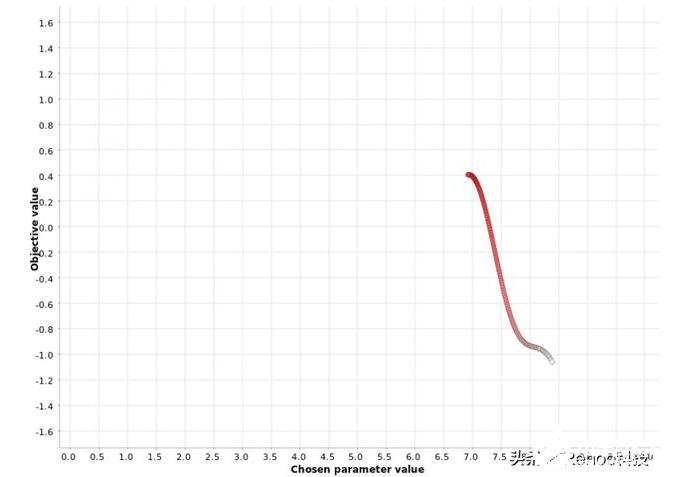
在[0,10]范圍內(nèi)對超參數(shù)值進行爬山搜索。顏色梯度反映了在生成的超參數(shù)候選序列中的位置。白點對應(yīng)于過程
上圖顯示了應(yīng)用于我們函數(shù)的爬坡策略從一個隨機的超參數(shù)值x = 8.4開始,然后在x = 6.9時朝函數(shù)最大值y = 0.4移動。一旦達到最大值,就不會在下一個鄰居中看到度量值的進一步增加,并且搜索過程將停止。
此示例說明了與此策略有關(guān)的警告:它可能陷入次要最大值。從其他圖中可以看出,全局最大值位于x = 4.0處,對應(yīng)的度量值為1.6。該策略找不到全局最大值,但陷入局部最大值。此方法的一個很好的經(jīng)驗法則是以不同的起始值多次運行它,并檢查算法是否收斂到相同的最大值。
貝葉斯優(yōu)化
該貝葉斯優(yōu)化戰(zhàn)略選擇基于以前的迭代,類似于爬山策略的功能輸出的下一個超參數(shù)值。與爬山不同,貝葉斯優(yōu)化會全局查看過去的迭代,而不僅僅是最后一次。
此過程通常分為兩個階段:
在稱為預(yù)熱的第一階段中,將隨機生成超參數(shù)值。在用戶定義的數(shù)量N個此類超參數(shù)的隨機生成之后,第二階段開始。
在第二階段中,在每次迭代中,都會估計類型為P(輸出|過去超參數(shù))的“替代”模型,以描述輸出值在過去迭代中對超參數(shù)值的條件概率。該替代模型比原始函數(shù)更容易優(yōu)化。因此,該算法優(yōu)化了替代,并建議將替代模型的最大值處的超參數(shù)值也作為原始函數(shù)的最佳值。第二階段的一小部分迭代還用于探測最佳區(qū)域之外的區(qū)域。這是為了避免局部最大值的問題。
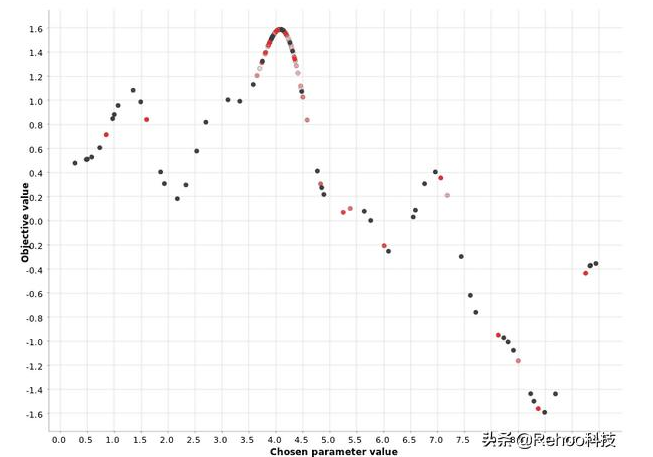
[0,10]范圍內(nèi)超參數(shù)值的貝葉斯優(yōu)化。顏色梯度反映了在生成的超參數(shù)候選序列中的位置。白點對應(yīng)于過程中較
上圖圖證明了貝葉斯優(yōu)化策略使用預(yù)熱階段來定義最有希望的區(qū)域,然后為該區(qū)域中的超參數(shù)選擇下一個值。您還可以看到,密集的紅色點聚集在更接近最大值的位置,而淡紅色和白色的點則分散了。這表明,第二階段的每次迭代都會改善最佳區(qū)域的定義。
總結(jié)
我們都知道訓(xùn)練機器學(xué)習(xí)模型時超參數(shù)優(yōu)化的重要性。由于手動優(yōu)化非常耗時并且需要特定的專家知識,因此我們探索了四種常見的超參數(shù)優(yōu)化自動過程。
通常,自動優(yōu)化過程遵循迭代過程,在該過程中,每次迭代時,都會在一組新的超參數(shù)上訓(xùn)練模型,并在測試集上進行評估。最后,將與最佳度量得分相對應(yīng)的超參數(shù)集選擇為最佳集。問題是如何選擇下一組超參數(shù),以確保它實際上比上一組更好。
我們概述了四種常用的優(yōu)化策略:網(wǎng)格搜索,隨機搜索,爬山和貝葉斯優(yōu)化。它們都各有利弊,我們通過說明它們在簡單用例中的工作方式來簡要解釋了它們之間的差異。現(xiàn)在,您都可以嘗試在現(xiàn)實中的機器學(xué)習(xí)問題中進行嘗試。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103552 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8501瀏覽量
134576 -
決策樹
+關(guān)注
關(guān)注
3文章
96瀏覽量
13828
發(fā)布評論請先 登錄
RDMA簡介3之四種子協(xié)議對比
RakSmart服務(wù)器成本優(yōu)化策略
解析DeepSeek MoE并行計算優(yōu)化策略
四種常用的最大功率點跟蹤MPPT技術(shù)介紹

MSP430F4250的四種模式分別是在什么情況下使用呢?
私藏技術(shù)大公開!四種常見供電方案
被問爆的四種供電方式,來啦~





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論