") 針對(duì)電商場(chǎng)景調(diào)優(yōu)BERT的論文
針對(duì)電商場(chǎng)景調(diào)優(yōu)BERT的論文
最近跟幾個(gè)做電商N(yùn)LP的朋友們聊天,有不少收獲。我之前從來(lái)沒(méi)想過(guò)【搜索】在電商里的地位是如此重要,可能GMV的50%以上都是從搜索來(lái)的。巨大的經(jīng)濟(jì)價(jià)值也極大地推動(dòng)了技術(shù)的發(fā)展,他們的工作做得很細(xì)致,畢竟一個(gè)百分點(diǎn)的點(diǎn)擊率后購(gòu)買率提升也許對(duì)應(yīng)的就是幾百億的成交額。
其實(shí)之前做的汽車領(lǐng)域NLP工作跟電商有很多相似的地方,場(chǎng)景先驗(yàn)都非常重要。直接使用開(kāi)放域語(yǔ)料預(yù)訓(xùn)練的語(yǔ)言模型效果并不好。我們也嘗試過(guò)一些方法,例如用本領(lǐng)域語(yǔ)料訓(xùn)練語(yǔ)言模型,結(jié)合一些詞庫(kù)詞典等等。今天介紹最近看到的一篇針對(duì)電商場(chǎng)景調(diào)優(yōu)BERT的論文《E-BERT: Adapting BERT to E-commerce with Adaptive Hybrid Masking and Neighbor Product Reconstruction》[1],其中的一些方法應(yīng)該對(duì)細(xì)分領(lǐng)域NLP有一些啟發(fā)。
方法
論文的創(chuàng)新方法主要有兩個(gè):Adaptive Hybrid Masking(AHM,自適應(yīng)混合掩碼)和Neighbor Product Reconstruction(NPR,相似商品重構(gòu))。
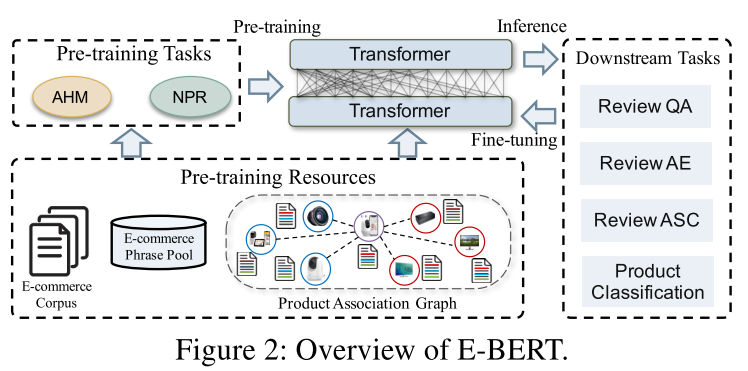
E-BERT總覽
AHM
第一個(gè)方法AHM其實(shí)是對(duì)已有掩碼方式的改進(jìn)。原始版本的BERT采用的是隨機(jī)mask,這個(gè)大家應(yīng)該都比較清楚。這種mask方式針對(duì)的是token,而眾所周知token是由單詞通過(guò)wordpiece tokenizer分割而來(lái)。所以這種方式遮蓋住的可能是單詞的一個(gè)部分,學(xué)習(xí)這種類似看三個(gè)字母猜剩下四個(gè)字母的任務(wù)不是很符合大家的直覺(jué)。隨后就誕生了更加符合人類認(rèn)知的Whole Word Masking,這個(gè)方法就是說(shuō)要遮就遮整個(gè)詞。這里用一個(gè)網(wǎng)上的例子幫大家理解
InputText:themanjumpedup,puthisbasketonphil##am##mon'shead OriginalMaskedInput:[MASK]man[MASK]up,puthis[MASK]onphil[MASK]##mon'shead WholeWordMaskedInput:theman[MASK]up,puthisbasketon[MASK][MASK][MASK]'shead
philammon是一個(gè)詞,他會(huì)被tokenizer分解成三個(gè)token,這時(shí)就體現(xiàn)了普通mask和WWM的區(qū)別。
怎么繼續(xù)改進(jìn)遮蓋方法呢,一個(gè)比較直觀的方向是繼續(xù)提高遮蓋的整體性。前面是從token走到了word,可以繼續(xù)往前走一步到phrase。這個(gè)方向其實(shí)之前有人做了,比如SpanBert[2]隨機(jī)mask一小段,ERNIE[3]mask實(shí)體等等。這篇論文做了兩個(gè)工作,一個(gè)是進(jìn)一步提升遮蓋phrase的質(zhì)量,用了一種叫AutoPhrase[4]的方法來(lái)構(gòu)建高質(zhì)量的電商短語(yǔ)集合;第二個(gè)是設(shè)計(jì)了一套自適應(yīng)機(jī)制,讓模型訓(xùn)練在詞語(yǔ)遮蓋和短語(yǔ)遮蓋間切換,兩個(gè)方面合在一起就叫做AHM。
AHM總體的流程如下圖所示。對(duì)于一句輸入,首先用兩種方式進(jìn)行mask,左邊是常規(guī)word mask,右邊是phrase mask,然后輸入到BERT,分別得到MLM的loss,Lw和Lp。然后用一個(gè)函數(shù)f,根據(jù)兩個(gè)loss計(jì)算變量,跟預(yù)設(shè)的超參數(shù)進(jìn)行比較,如果就用word masking,反之就用phrase masking。的計(jì)算其實(shí)可以有很多方法,論文也沒(méi)有在這塊做對(duì)比實(shí)驗(yàn),我也就不展開(kāi),大家有興趣可以去看原文。
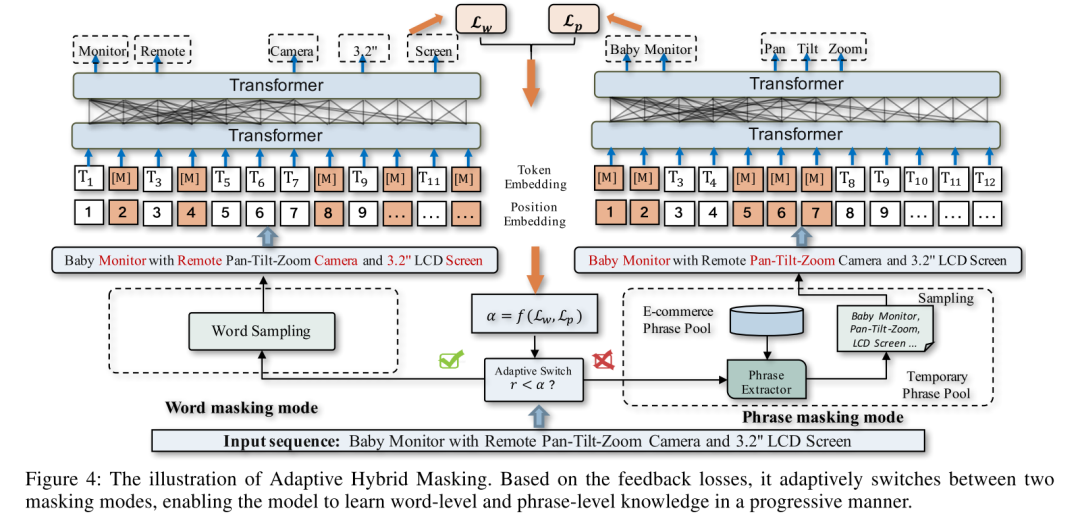
AHM總體流程
NPR
NPR是個(gè)比較有意思的部分,直觀的解釋是希望能通過(guò)一個(gè)商品重建出另一個(gè)相似商品的隱空間表示。具體的做法是把兩個(gè)商品a和b的文本內(nèi)容送進(jìn)Bert,得到各自的embedding矩陣;然后對(duì)這兩個(gè)句子做交叉注意力,得到注意力矩陣,然后用注意力矩陣加權(quán)a的embedding得到重構(gòu)后的b的embedding,反過(guò)來(lái)也從b重構(gòu)a。得到重構(gòu)后的embedding后再和原embedding計(jì)算距離作為loss,論文采用的是歐氏距離。只做相似商品重構(gòu)還不夠,論文還引入了不相似商品(隨機(jī)采樣)作為負(fù)樣本,采用triplet loss來(lái)計(jì)算最終的重構(gòu)損失。
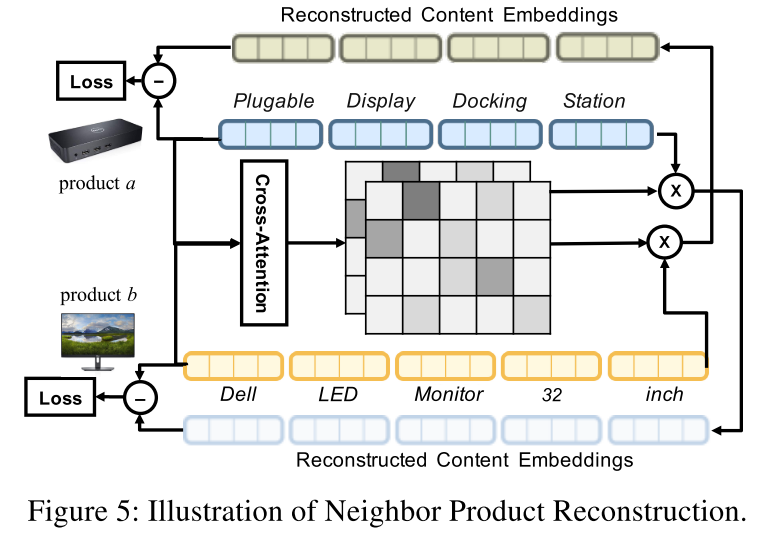
NPR示意圖
效果
論文的實(shí)驗(yàn)和結(jié)果比較部分做的比較全面。
先介紹一下對(duì)照實(shí)驗(yàn)涉及的模型。baseline是裸BERT(BERT Raw),用電商數(shù)據(jù)finetune過(guò)的Bert外加SpanBERT作為對(duì)照組,finetune有兩種方法,分別是word masking的Bert和phrase masking的Bert-NP。實(shí)驗(yàn)組是各種配置的E-Bert,包括只使用phrase masking的E-Bert-DP,使用AHM的E-Bert-AHM和AHM+NPR的E-Bert。
評(píng)估效果使用了4個(gè)電商場(chǎng)景場(chǎng)景的下游任務(wù),Review-based Question Answering(基于評(píng)論的問(wèn)答),Review Aspect Extraction(評(píng)論方面抽取?),Review Aspect Sentiment Classification(評(píng)論情感分類)和Product Classification(商品類別分類)。
不同模型在不同任務(wù)上的結(jié)果如下圖
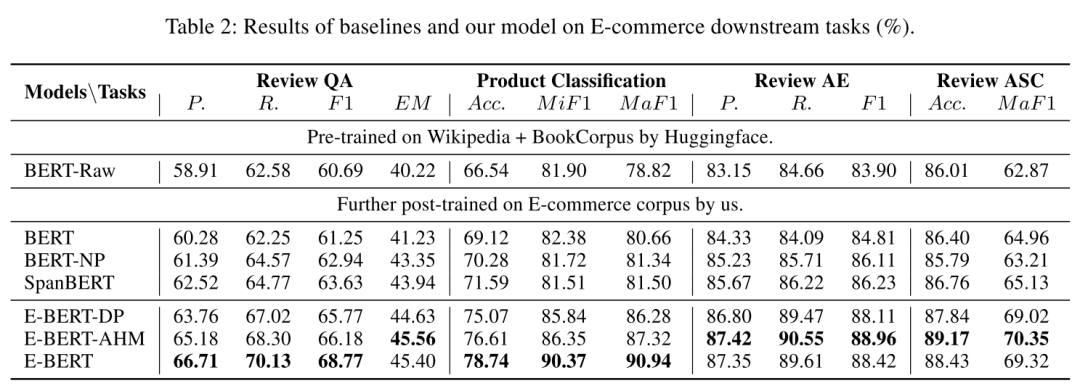
模型結(jié)果比較
從結(jié)果可以看出E-BERT在各種任務(wù)上都大幅領(lǐng)先裸BERT,甚至也大幅領(lǐng)先基于領(lǐng)域語(yǔ)料預(yù)訓(xùn)練過(guò)的BERT。文章的方法其實(shí)可以在任何的垂直領(lǐng)域中使用,可以說(shuō)相當(dāng)?shù)膶?shí)用。
最近一個(gè)討論比較多的問(wèn)題是在BERT時(shí)代,NLP算法工程師的價(jià)值是什么?我想這個(gè)結(jié)果可以從一個(gè)側(cè)面給答案,知道如何在模型中引入行業(yè)先驗(yàn)知識(shí)是可以大大提高模型在特定場(chǎng)景的表現(xiàn)的,即使如BERT這樣自身很強(qiáng)的超級(jí)模型也不例外。
參考資料
[1]
E-BERT: Adapting BERT to E-commerce with Adaptive Hybrid Masking and Neighbor Product Reconstruction: https://arxiv.org/pdf/2009.02835
[2]
SpanBERT: Improving Pre-training by Representing and Predicting Spans: http://arxiv.org/abs/1907.10529
[3]
ERNIE: Enhanced Language Representation with Informative Entities: http://arxiv.org/abs/1905.07129
[4]
AutoPhrase: https://github.com/shangjingbo1226/AutoPhrase
責(zé)任編輯:xj
原文標(biāo)題:E-BERT: 電商領(lǐng)域語(yǔ)言模型優(yōu)化實(shí)踐
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10681 -
AHM
+關(guān)注
關(guān)注
0文章
2瀏覽量
7532 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22488
原文標(biāo)題:E-BERT: 電商領(lǐng)域語(yǔ)言模型優(yōu)化實(shí)踐
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
手把手教你如何調(diào)優(yōu)Linux網(wǎng)絡(luò)參數(shù)
xgboost超參數(shù)調(diào)優(yōu)技巧 xgboost在圖像分類中的應(yīng)用
用VESC電調(diào)代替STLink給VESC電調(diào)刷固件 可刷所有的基于VESC的電調(diào)固件
MCF8316A調(diào)優(yōu)指南

MCT8316A調(diào)優(yōu)指南
MCT8315A調(diào)優(yōu)指南
MMC DLL調(diào)優(yōu)
TDA3xx ISS調(diào)優(yōu)和調(diào)試基礎(chǔ)設(shè)施
大數(shù)據(jù)從業(yè)者必知必會(huì)的Hive SQL調(diào)優(yōu)技巧
智能調(diào)優(yōu),使步進(jìn)電機(jī)安靜而高效地運(yùn)行
MMC SW調(diào)優(yōu)算法
如何調(diào)優(yōu)DS160PR410實(shí)現(xiàn)出色的信號(hào)完整性
TAS58xx系列通用調(diào)優(yōu)指南
AM6xA ISP調(diào)優(yōu)指南
OSPI控制器PHY調(diào)優(yōu)算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論