 圖神經網絡也急需一個全球學者公認的統一對比基準
圖神經網絡也急需一個全球學者公認的統一對比基準

圖神經網絡(GNN)是當下風頭無兩的熱門研究話題。然而,正如計算機視覺的崛起有賴于 ImageNet 的誕生,圖神經網絡也急需一個全球學者公認的統一對比基準。
近日,Bengio 大神帶領其團隊發布了新的圖神經網絡對比基準測試框架以及附帶的 6 個標準化數據集。大家可以開始盡情刷榜了!
時至今日,圖神經網絡已經成為了分析圖數據并且進行學習的標準工具,被成功地應用到了各個領域(例如,化學、物理、社會科學、知識圖譜、推薦系統,以及神經科學)。隨著這個領域的興起,識別出在不同的網絡尺寸下都可以泛化的架構和關鍵機制就變得至關重要了,這讓我們可以處理更大、更復雜的數據集和領域。
不幸的是,在缺乏具有統一的實驗設置和大型數據集的標準化對比基準的情況下,衡量新型 GNN 的有效性以及對模型進行比較的難度越來越大。
在本文中,Bengio 團隊提出了一種可復現的 GNN 對比基準框架,而且為研究人員添加新數據集和模型帶來了便利。他們將這個對比基準框架應用于數學建模、計算機視覺、化學和組合問題等新穎的中型圖形數據集,從而在設計有效的 GNN 時創建關鍵操作。與此同時,還精確地將圖卷積,各向異性擴散,殘差連接和歸一化層作為通用構建模塊,用于開發魯棒且可擴展的 GNN。
一、引言
在許多前人的工作的努力下,近年來,圖神經網絡(GNN)已經成為了風口浪尖上的熱門研究話題,研究人員陸續開發出了一系列具有發展前景的方法。
隨著該領域的不斷發展,如何構建強大的 GNN 成為了核心問題。什么樣的架構、基本原則或機制是通用的、可泛化的,并且能擴展到大型圖數據集和大型圖之上呢?另一個重要的問題是:如何研究并量化理論發展對 GNN 的影響?
對比基準測試為解決這些基本的問題給出了一個強大的范例。這種方法已經被證明在推動科學進步、確定基本思想、解決特定領域的問題等方面對于一些科學領域大有助益。
近年來,大名鼎鼎的 2012 ImageNet 挑戰賽提供了一個很好的對比基準測試數據集,它掀起了深度學習的革命。來自世界各國的研究團隊爭相開發出用于在大規模數據集上進行圖像分類的最幽默型。
由于在 ImageNet 數據集上取得的重大進展,計算機視覺研究社區已經開辟出了一條光明的發展道路,朝著發現魯棒的網絡架構和訓練深度神經網絡的技術邁進。
然而,設計出成功的對比基準是一件極具挑戰的事情,它需要:設計合適的數據集、魯棒的編碼接口,以及為了實現公平的比較而設立的通用實驗環境,所有上述元素都需要時可復現的。
這樣的需求面臨著一些問題:
首先,如何定義合適的數據集?想要收集到具有代表性的、真實的大規模數據集可能是很困難的。而對于 GNN 來說,這卻是最重要的問題之一。大多數已發表的論文關注的都是非常小的數據集(例如,CORA 和 TU 數據集),在這種情況下,從統計及意義上說,幾乎所有的 GNN 的性能都是相同的。有些與直覺相悖的是,那些沒有考慮圖結構的對比基線模型性能與 GNN 相當,甚至還有時要優于 GNN。
這就對人們研發新的、更復雜的 GNN 架構的必要性提出了疑問,甚至對使用 GNN 的必要性也提出了疑問。例如,在 Hoang&Maehara 等人以及 Chen 等人于 2019 年發表的工作中,作者分析了 GNN 中的組件的能力,從而揭示了模型在小數據集上收到的限制。他們認為這些數據集不適合設計復雜的結構化歸納學習框架。
GNN 領域面臨的另一個主要問題是如何定義通用的實驗環境。正如 Errica 等人于 2019 年發表的論文《A fair comparison of graph neural networks for graph classifification》所述,最近基于 TU 數據集完成的論文在訓練、驗證和測試集的劃分以及評估協議方面沒有達成共識,這使得比較新思想和架構的性能變得不公平。
人們目前尚不明確如何進行良好的數據集劃分(除了隨機劃分之外),已經證明這樣會得到過于樂觀的預測結果(Lohr,2009)。此外,不同的超參數、損失函數和學習率計劃(learning rate schedules)使得評價架構的新進展變得困難。
本文主要的貢獻如下:
發布了一個公開的 GNN 對比基準框架,它是基于 PyTorch 和 DGL 庫開發的,并將其托管于 GitHub 上。
目標:超越目前流行的小型數據庫 CORA 和 TU,引入了 12,000~70,000 張具有 9~500 個節點的圖組成的中型數據集。數據集涉及數學建模(隨機分塊模型)、計算機視覺(超像素),組合優化(旅行商問題)以及化學(分子溶解度)
提出的對比基準框架確定了 GNN 的重要構建模塊。圖卷積、各向異性擴散、殘差連接,以及歸一化層等技術對于設計高效的 GNN 是最有用的。
作者目的并不是對已發布的 GNN 進行排名。對于一個特定的任務來說,找到最佳的模型的計算開銷是非常高昂的(超出了相應資源限制),它需要使用較差驗證對超參數的值進行窮舉搜索。相反,作者為所有的模型設定了一個參數變化的實驗計劃,并且分析了性能的趨勢,從而確定重要的 GNN 機制。
數值化的結果是可以完全被復現的。
二、對比基準框架
這項工作的目的之一就是給出一系列易于使用的中型數據集,在這些數據集上,過去幾年提出的各種 GNN 架構在性能方面表現出明顯且具有統計意義的差異。如表 1 所示,本文給出了 6 個數據集。對于其中的兩個計算機視覺數據集,作者將經典的 MNIST 和 CIFAR10 數據集中的每張圖片使用「super-pixel」技術轉換為圖的形式(詳見原文第 5.2 節)。接下來的任務就是對這些圖進行分類。
表1:已提出的基準數據集統計表

「PATTERN」和「CLUSTER」數據集是根據隨機分塊模型生成的(詳見原文第 5.4 節)。對于 PATTERN 數據集,對應的任務是識別出預先定義好的子圖;對于 CLUSTER 數據集,對應的任務是識別出簇。上述兩個任務都是節點分類任務。
TSP 數據集是基于旅行商問題(給定一組城市,求訪問每個城市并回到原點的可能的最短路徑)構建的,詳見原文第 5.5 節。作者將隨機歐幾里得圖上的 TSP 作為一個邊的分類/連接預測任務來處理,其中每條邊的真實值都是由 Concorde 求解器給出的 TSP 路徑確定的。
如原文第 5.3 節所述,ZINC 是一個已經存在的真實世界中的分子數據集。每個分子可以被轉換成圖的形式:每個原子作為一個節點,每個化學鍵作為一條邊。這里對應的任務是對一種被稱為受限溶解度(Constrained Solubility)的分子特性進行回歸。
本文提出的每一個數據集都至少包含 12,000 個圖。這與 CORA 和經常使用的 TU 數據集形成了鮮明的對比,這些之前的數據集往往只包含幾百個圖。
另一方面,本文提出的數據集大多數都是人造或半人造的(除了 ZINC 之外),而 CORA 和 TU 卻并非如此。因此,可以認為這些對比基準是互為補充的。
這項工作的主要動機在于,提出足夠大的數據集,從而使觀察到的不同 GNN 架構之間的差異是具有統計意義的。
三、圖神經網絡簡介
從最簡單的形式上來說,圖神經網絡根據以下公式迭代式地從一層到另一層更新其中的節點表征:
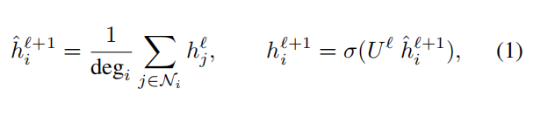
其中
是節點 i 在第 l+1 層中的 d 維嵌入表征,
是圖中與節點 i 相連的節點集合,
則是節點 i 的度,σ 是一個非線性函數,
則是一個可學習的參數。我們將這個簡單版本的圖神經網絡稱為圖卷積網絡(GCN)。
GraphSage 和 GIN(圖同構網絡)提出了這種平均機制的簡單變體。在采用平均聚合版本的 GraphSage 中,公式(1)可以被改寫為:
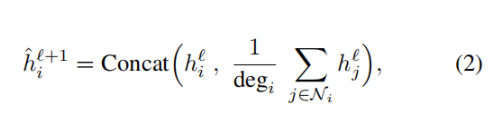
在嵌入向量被傳給下一層之前,它會被投影到單位球之上。在 GIN 架構中,公式(1)可以被改寫為:

其中
是可學習的參數,BN 是批歸一化層。值得注意的是,為了最終的預測,GIN 在所有中間層都會使用特征。在上述所有的模型中,每個鄰居對中央節點更新的貢獻是均等的。我們將這種模型稱為各向同性的,它們將所有的邊的方向等同視之。
另一方面,高斯混合模型網絡 MoNet,門控圖卷積網絡 GatedGCN,以及圖注意力網絡 GAT 提出了各向異性的更新方案:
其中,權重
和
是使用各種各樣的機制計算得到的(例如,GAT 中的注意力機制或 GatedGCN 中的門控機制)。
最后,還可以考慮一個層次化的圖神經網絡,即差分池化 DiffPool。它在層次的每一個階段以及池化的過程中都用到了 GraphSage 的公式(2)。
四、基準測試實驗
在這里,我們來展示一下這篇文章所提出的開源對比基準測試框架的實驗結果。
這篇工作中使用的大多數 GNN 網絡(包括圖卷積網絡 GCN、圖注意力網絡 GAT、GraphSage、差分池化 DiffPool、圖同構網絡 GIN、高斯混合模型網絡 MoNet),都來源于深度圖代碼庫(DGL),并且使用 PyTorch 實現。作者使用殘差鏈接、批歸一化,以及圖尺寸歸一化對所有 DGL 版的 GNN 實現進行了改進。門控圖卷積網絡 GatedGCN 是其最終考慮使用的 GNN,并用「GatedGCN-E」代表使用了邊屬性/邊特征的版本。
此外,作者還實現了一個簡單的與具體圖無關的對比基線,它以相同的方式將一個多層感知機應用于每個節點的特征向量,而與其它的節點無關。可以選擇在后面接上一個門控機制,從而得到門控的多層感知機對比基線。
這篇文章中使用了英偉達 1080Ti 的 GPU,在 TU、MNIST、CIFAR10、ZINC 以及 TSP 數據集上進行了實驗,并且使用英偉達 2080Ti 的 GPU 在 PATTERN 和 CLUSTER 數據集上進行了實驗。
1、在 TU 數據集上進行圖分類
第一個實驗是在 TU 數據集上進行圖分類。論文中選用了 3 個 TU 數據集,ENZYMES(訓練集、驗證集、測試集分別包含 480、60、60 個尺寸為 2-126 的圖),DD(訓練集、驗證集、測試集分別包含 941、118、119 個尺寸為 30-5748 的圖),以及 PROTEINS(訓練集、驗證集、測試集分別包含 889、112、112 個尺寸為 4-620 的圖)。
實驗的數值結果如表 2 所示,從統計意義上說,所有的神經網絡都具有差不多的性能,然而標準差卻非常大。
表 2:在標準 TU 測試數據集上的模型性能(數值越高越好)。給出了兩次實驗的結果,這兩次實驗所使用的超參數是相同的,但是使用的隨機種子是不同的。作者分別展示了這兩次實驗的結果,從而說明排序和可復現性的差異。性能最好的結果用加粗的紅色表示,性能第二的結果用加粗的藍色表示,性能第三的結果用加粗的黑色表示。

2、使用超像素(SuperPixel) 的圖分類
在第二個實驗中,作者用到了計算機視覺領域流行的 MNIST 和 CIFAR10 圖像分類數據集。他們使用 SuperPixel 將原始的 MNIST 和 CIFAR10 圖像轉換為圖。
在 MNIST 數據集中,訓練集、驗證集、測試集分別包含 55,000、5,000、10,000 個尺寸為 40-75 個節點(即 SuperPixel 的數量)的圖;在 CIFAR10 數據集中,訓練集、驗證集、測試集分別包含 45,000、5,000、10,000 個尺寸為 85-150 個節點的圖。
對于每一個樣本,作者構建了一個 k 最近鄰鄰接矩陣,權值
,其中 x_i,x_j 是超像素 i,j 的二維坐標,σ_x 是放縮參數(通過計算每個節點的 k 個最近鄰的平均距離 x_k 得到)。MNIST 和 CIFAR10 的超像素圖的可視化結果如圖 1 所示。

圖 1:示例圖及其超像素圖。通過 SLIC 得到的超像素圖(MNIST 最多有 75 個節點,CIFAR10 中最多有 150 個節點)是歐氏空間中得到的 8-最近鄰圖,圖中節點的顏色表示平均的像素強度。
在 MNIST 和 CIFAR 10 數據集上的圖分類結果如表 3 所示。
表 3:在標準的 MNIST 和 CIFAR10 測試數據集上的模型性能(數值越高越好)。實驗結果是根據四次使用不同的種子進行的實驗求平均得到的。紅色代表最優的模型,紫色代表較優模型,加粗黑色代表具有殘差連接和不具有殘差連接的模型之中的最優模型(如果二者性能相同,則都是加粗黑色字體)。

3、在分子數據集上進行圖回歸
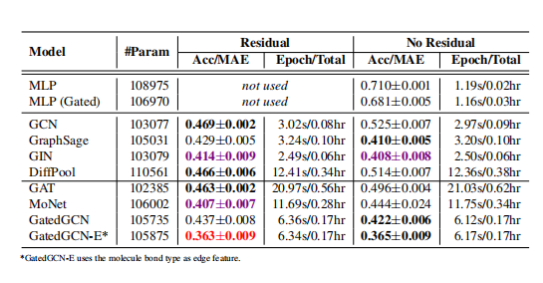
作者將 ZINC 分子圖數據集用于對被稱為「受限溶解度」(constrained solubility)的分子性質進行回歸。在 ZINC 數據集中,訓練集、驗證集、測試集分別包含 10,000、1,000、1,000 個尺寸為 9-37 個節點/原子。對于每個分子圖來說,節點特征是原子的種類,邊的特征是邊的種類。實驗結果如表 4 所示。
表 4:在標準的 ZINC 測試數據集上的模型性能(數值越低越好)。實驗結果是根據四次使用不同的種子進行的實驗求平均得到的。紅色代表最優的模型,紫色代表較優模型,加粗黑色代表具有殘差連接和不具有殘差連接的模型之中的最優模型(如果二者性能相同,則都是加粗黑色字體)。
4、在隨機分塊模型(SBM)數據集上進行節點分類
在這里,作者考慮節點級的圖模式識別任務,以及半監督圖聚類任務。圖模式識別任務旨在找出一種嵌入在各種尺寸的大型圖 G 中的固定圖模式 P。對于 GNN 來說,識別出不同的圖中的模式是最基本的任務之一。模式和嵌入后的圖是通過隨機分塊模型(SBM)生成的。SBM 是一種隨機圖,它為每個節點按照以下的規則分配所屬社區:對于任意兩個節點來說,如果它們從屬于同一個社區則它們被連接在一起的概率為 p,如果它們從屬于不同的社區則它們被連接在一起的概率為 q(q 的值作為噪聲水平)。
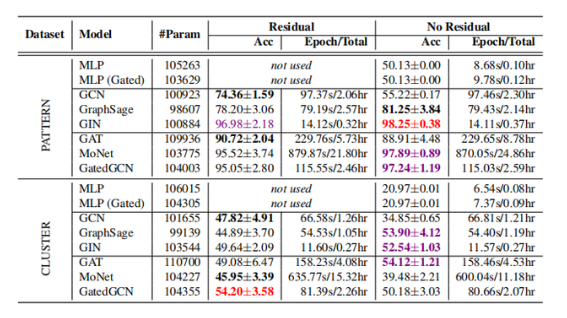
在所有的實驗中,作者生成了包含 5 個社區的圖 G,每個社區的規模在 [5, 35] 之間隨機生成。每個社區的 SBM 規則為 p = 0.5,q = 0.2,G 上的信號是通過在 3 個變量(即{0,1,2})的均勻隨機分布上采樣得到的。作者隨機生成了由 20 個節點組成的 100 個模式 P,內部概率為 p_P = 0.5,且外部概率 q_P = 0.5(即 P 中 50% 的節點與 G 中非 P 部分相連)。P 上的信號也是在{0,1,2}中生成的隨機信號。在 PATTERN 數據集中,訓練集、驗證集、測試集分別包括 10,000、2,000、2,000 個尺寸為 50-180 個節點的圖。當節點從屬于 P 時輸出信號的值為 1,節點在 G 中且不從屬于 P 時輸出信號的值為 0。
半監督聚類任務是網絡科學中的另一類基本任務。作者生成了 6 個 SBM 簇,其尺寸為 [5, 35] 之間隨機生成的值,概率 p = 0.55,q = 0.25。在 CLUSTER 數據集中,訓練集、驗證集、測試集分別包括 10,000、1,000、1,000 個尺寸為 40-190 個節點的圖。作者僅僅為每個社區給出了隨機選取的單一標簽。輸出信號被定義為聚類類別的標簽。
表 5:在標準的 PATTERN 和 CLUSTER SBM 圖測試集上的模型性能(數值越高越好)。紅色代表最優的模型,紫色代表較優模型,加粗黑色代表具有殘差連接和不具有殘差連接的模型之中的最優模型。
5、在 TSP 數據集上進行邊的分類
近年來,將機器學習用于求解 NP-hard 的組合優化問題(COP)成為了備受關注的研究熱點。最近提出的 COP 深度學習求解器將 GNN 與經典的圖搜索方法結合了起來,用于直接根據問題實例(表征為圖)預測近似解。在這里,作者考慮被廣泛研究的旅行商問題(TSP):給定一個二維的歐氏圖,我們需要找到一個最優的節點順序(路徑),遍歷所有節點一次,并且邊的權重之和(路徑長度)最小。TSP 的多尺度特性使其成為了一個極具挑戰的圖任務,它要求我們同時做到局部節點鄰居和全局圖結構的推理。
在這里的 TSP 實驗中,作者遵循了 Li 等人于 2018 年發表的論文「Combinatorial optimization
with graph convolutional networks and guided tree search」中所描述的基于學習的 COP 求解方法,其中 GNN 是為每條邊賦予屬于/部署于某個預測解集的概率的主干架構。接著,作者會通過圖搜索技術將概率轉換為離散決策。訓練集、驗證集、測試集分別包含 10,000、1,000、1,000 個 TSP 實例,其中每個實例都是一個在單位正方形
中均勻采樣得到的 n 個節點位置組成的圖(
)。作者通過為每個實例均勻地采樣得到 n 個節點(
),從而生成尺寸和復雜度不一的多個 TSP 問題。
為了將主干 GNN 架構和搜索部分的影響獨立開來,作者將 TSP 作為了一個邊的二分類任務,TSP 路徑中每條邊的真實值是由 Concorde 求解器得到的。為了拓展到大的實例上,作者使用了稀疏的 k = 25 的最近鄰圖,而并非使用完全圖。采樣得到的各種各樣尺寸的 TSP 實例請參閱圖 2。

圖 2:TSP 數據集中采樣得到的圖。節點用藍色表示,TSP 路徑中的真實邊用紅色表示。
五、給我們的啟示
1、在小型數據集上,與圖無關的神經網絡(多層感知機)的性能與 GNN 相近
表 2 和表 3 說明對于小型的 TU 數據集和簡單的 MNIST 數據集來說,將 GNN 用在與圖無關的 MLP 對比基線上沒有明顯的性能提升。此外,MLP 有時比 GNN 的性能還要好(例如在 DD數據集上)。
2、在大型數據集上,GNN 可以提升與圖無關的神經網絡性能
表 4 和表 5 顯示出,在 ZINC、PATTERN 以及 CLUSTER 數據集上,所有的 GNN 都相較于兩個 MLP 對比基線模型有很大的性能提升。表 6 說明使用了殘差連接的 GNN 模型在 TSP 數據集上的性能要優于 MLP 對比基線。表 3 中的實驗結果說明,在 CIFAR10 數據集上差異較小,盡管最佳的 GNN 模型性能顯著優于 MLP 模型。
3、原始的 GCN 性能較差
GCN 是最簡單的 GNN 形式。它們對節點表征的更新依賴于一個如公式(1)所述的在鄰居節點上的各向同性平均操作。Chen 等人于 2019 年發表的論文《Are Powerful Graph Neural Nets Necessary? A Dissection on Graph Classification》中對這種各向同性的性質進行了分析,結果表明這種方法無法區分簡單的圖結構,這也解釋了 GCN 在所有的數據集上為什么性能較差。
4、在 GCN 上進行改進的新型各向同性 GNN 架構
GraphSage 通過圖卷積層的公式(2)說明了使用中心節點信息的重要性。GIN 也在公式(3)中利用了中心節點的特征,并采用了一個與所有中間層的卷積特征相連的新的分類器層。DiffPool 考慮了一種可學習的圖池化操作,其中在每一個分辨率的層級上使用了 GraphSage。這三種各向同性的 GNN 在除了 CLUSTER 的所有數據集上都極大提升了 GCN 的性能。
5、各向異性 GNN 更加精確
諸如 GAT、MoNet、GatedGCN 等各向異性模型在除了 PATTERN 之外的所有數據集上都取得了最佳的性能。同時,作者也注意到 GatedGCN 在所有的數據集上都展現出了很好的性能。
與主要依賴于對鄰居節點特征的簡單求和的各向同性 GNN 不同,各向異性 GNN 采用了復雜的機制(GAT 用到了稀疏注意力機制,GatedGCN 用到了邊的門控機制),這使得它們更難得以高效地實現。
此外,這種 GNN 還有一個優點,那就是它們可以顯式地使用邊的特征(例如,分子中兩個原子之間的化學鍵類型)如表 4 所示,對于 ZINC 分子數據集而言,GatedGCN-E 使用化學鍵的邊特征,相較于不使用化學鍵的 GatedGCN 極大地提升了 MAE 性能。
6、殘差連接可以提升性能
殘差連接在計算機視覺領域的深度學習架構中已經成為了一種通用的組成部分。使用殘差連接可以從兩方面幫助 GNN 提升性能:
一方面,它在深度網絡中限制了反向傳播過程中的梯度彌散的問題。另一方面,它使得在 GCN 和 GAT 這樣的模型中可以在卷積階段包含自節點信息,而這些模型本身并沒有顯式地使用這些信息。
表 7:對于帶有殘差連接/不帶有殘差連接的深度 GNN(最多 32 層),在 TSP 測試數據集上的模型性能(數值越高越好)。L 代表層數,加粗的黑色字體代表帶有殘差連接和不帶有殘差連接的模型中最優的一方(如果性能相同則都是加粗的黑色字體)。

圖 3:帶有殘差連接(實線)和不帶有殘差連接(虛線)的深度 GNN(最多 32 層)在 ZINC 和 CLUSTER 測試數據集上的模型性能。實驗結果是根據四次使用不同的種子進行的實驗求平均得到的。
7、歸一化層可以提升學習性能
大多數現實世界中的圖數據集是具有不同圖大小的不規則圖的集合。將大小不同的圖當做一批處理,可能會導致節點表征處于不同的尺度。因此,對激活值進行歸一化處理可能會有助于提升學習和泛化的性能。
在試驗中,作者使用了兩個歸一化層:批量歸一化(BN)以及圖尺寸歸一化(GN)。圖尺寸歸一化是一種簡單的操作,其產生的節點特征 h_i 是根據圖的尺寸進行歸一化之后的結果,即
,其中 V 是節點的個數。這種歸一化層被應用在卷積層之后、激活層之前。

表 8:有/沒有經過批量歸一化(BN)和圖歸一化(GN)的模型在 ZINC、CIFAR10、CLUSTER 測試數據集上的性能。
實驗結果是根據四次使用不同的種子進行的實驗求平均得到的,表示為(均值±標準差),對于 ZINC 數據集來說數值越低越好,對于 CIFAR10 和 CLUSTER 數據集來說數值越高越好。加粗的黑色字體代表使用和不使用歸一化層的模型之中最優的一方(當二者性能相同時則都為加粗黑色字體)。
六、結語
在本文中,Begio等人提出了一種促進圖神經網絡研究的對比基準測試框架,并解決了實驗中的不一致性問題。他們證明了被廣為使用的小型 TU 數據集對于檢驗該領域的創新性是不合適的,并介紹了框架內的 6 個中型數據集。
在多個針對圖的任務上進行的實驗表明:
1)當我們使用更大的數據集時,圖結構是很重要的;
2)作為最簡單的各向同性 GNN,圖卷積網絡 GCN 并不能學習到復雜的圖結構;
3)自節點信息、層次、注意力機制、邊門控以及更好的讀取函數(Readout Function)是改進 GCN 的關鍵;
4)GNN 可以使用殘差連接被擴展地更深,模型性能也可以使用歸一化層得到提升。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103599 -
GNN
+關注
關注
1文章
31瀏覽量
6561
發布評論請先 登錄
BP神經網絡與卷積神經網絡的比較
BP神經網絡的優缺點分析
什么是BP神經網絡的反向傳播算法
BP神經網絡與深度學習的關系
BP神經網絡的基本原理
深度學習入門:簡單神經網絡的構建與實現
人工神經網絡的原理和多種神經網絡架構方法

一文詳解物理信息神經網絡
經典圖神經網絡(GNNs)的基準分析研究






 工商網監
工商網監
評論