") TensorFolw人工智能影像診斷平臺的工作原理
TensorFolw人工智能影像診斷平臺的工作原理
使用人工智能來輔助病理醫(yī)生對樣本進行診斷,不僅能夠大幅度提高醫(yī)師的診斷效率,而且可以減少漏診,提高診斷準確率。
數(shù)字化的病理影像能夠觀察到組織細胞形態(tài),在最高數(shù)字掃描時,文件尺寸達到GB量級,需要利用人工智能和系統(tǒng)工程學的技術(shù)去突破這些困難。
在這篇文章當中,我將會從人工智能系統(tǒng)的構(gòu)建方法角度來入手,舉例消化道病理影響輔助系統(tǒng)研發(fā)過程中的技術(shù)細節(jié)。
當然,這是相對陌生的醫(yī)療科技領(lǐng)域知識,為了讀者能更快的理解和吸收,全篇也會圍繞產(chǎn)品經(jīng)理的角度去解。
一、什么是病理?
病理就是通過分析病人的組織,細胞和體液樣本來診斷疾病。
那么,病理對于臨床醫(yī)生提供進一步治療策略的金指標。
這里有個容易混淆的是AI醫(yī)學影像,并不是所有都是從CT、X光、B超等分析得出。就拿胃癌篩查來說,它的病理影像通過掃描儀掃描組織放大形成大概1.4GB影像來進行分析判斷的。

不同病種的病理來源
病理影像都是與眾不同的,這也是技術(shù)上的挑戰(zhàn)。
那么在進行病理判斷之前,我們需要建立一套訓練模型,通過醫(yī)生標注的圖像進行增強訓練以及數(shù)據(jù)處理。
二、TENSORFOLW工作原理
我們講解TensorFolw訓練模型時,我們要了解整個的深度學習的流程。

簡易工作流程
數(shù)據(jù)源一般來自醫(yī)院的PACS、RIS系統(tǒng)等,形成數(shù)據(jù)隊列后進行數(shù)據(jù)增強圖像方向的魯棒性。
另外,我們要注意掃描儀的倍數(shù),會造成在不同樣的倍數(shù)情況下圖像的魯棒性。
然后利用TensorBoard來進行模型監(jiān)控,TensorBoard是一個可視化工具,能夠有效地展示Tensorflow在運行過程中的計算圖、各種指標隨著時間的變化趨勢以及訓練中使用到的數(shù)據(jù)信息。
再通過TensorFolw導出(病理)模型交給生產(chǎn)環(huán)境推理框架(TensorFolw Serving)進行自動處理。
那tensorfolw serving是怎么工作的呢?

Tensorserving工作流程
tensorfolw serving把病理切片分成坐標標記的小塊切分之后把節(jié)點讓一個map每個輸入分片會讓一個map任務來處理,默認情況下,以HDFS的一個塊的大小(默認為64M)為一個分片,當然我們也可以設(shè)置塊的大小。
map輸出的結(jié)果會暫且放在一個環(huán)形內(nèi)存緩沖區(qū)中(該緩沖區(qū)的大小默認為100M,由io.sort.mb屬性控制),當該緩沖區(qū)快要溢出時(默認為緩沖區(qū)大小的80%,由io.sort.spill.percent屬性控制),會在本地文件系統(tǒng)中創(chuàng)建一個溢出文件,將該緩沖區(qū)中的數(shù)據(jù)寫入這個文件。在寫入磁盤之前,線程首先根據(jù)reduce任務的數(shù)目將數(shù)據(jù)劃分為相同數(shù)目的分區(qū),也就是一個reduce任務對應一個分區(qū)的數(shù)據(jù)。
這樣做是為了避免有些reduce任務分配到大量數(shù)據(jù),而有些reduce任務卻分到很少數(shù)據(jù),甚至沒有分到數(shù)據(jù)的尷尬局面。其實分區(qū)就是對數(shù)據(jù)進行hash的過程。
然后對每個分區(qū)中的數(shù)據(jù)進行排序,如果此時設(shè)置了Combiner,將排序后的結(jié)果進行Combia操作,這樣做的目的是讓盡可能少的數(shù)據(jù)寫入到磁盤。
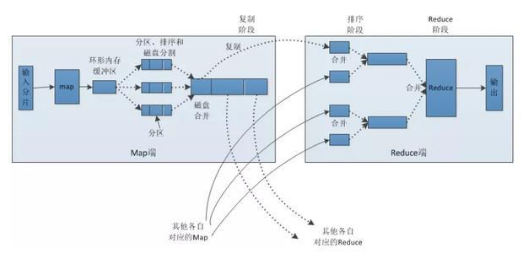
MAP與reduce機制再將分區(qū)中的數(shù)據(jù)拷貝給相對應的reduce任務。Reduce會接收到不同map任務傳來的數(shù)據(jù),并且每個map傳來的數(shù)據(jù)都是有序的。
如果reduce端接受的數(shù)據(jù)量相當小,則直接存儲在內(nèi)存中(緩沖區(qū)大小由mapred.job.shuffle.input.buffer.percent屬性控制,表示用作此用途的堆空間的百分比),如果數(shù)據(jù)量超過了該緩沖區(qū)大小的一定比例(由mapred.job.shuffle.merge.percent決定),則對數(shù)據(jù)合并后溢寫到磁盤中。
隨著溢寫文件的增多,后臺線程會將它們合并成一個更大的有序的文件,這樣做是為了給后面的合并節(jié)省時間。
其實不管在map端還是reduce端,MapReduce都是反復地執(zhí)行排序,合并操作,現(xiàn)在終于明白了有些人為什么會說:排序是hadoop的靈魂。合并的過程中會產(chǎn)生許多的中間文件(寫入磁盤了),但MapReduce會讓寫入磁盤的數(shù)據(jù)盡可能地少,并且最后一次合并的結(jié)果并沒有寫入磁盤,而是直接輸入到reduce函數(shù)。
最后返回數(shù)據(jù)到后端。
同樣的流程可以遷移學習,病理圖像有很多相似的地方,腺、息肉、囊腫等等都可以同理應用。
-
人工智能
+關(guān)注
關(guān)注
1804文章
48734瀏覽量
246651 -
醫(yī)學影像
+關(guān)注
關(guān)注
1文章
112瀏覽量
17540 -
數(shù)字化
+關(guān)注
關(guān)注
8文章
9289瀏覽量
63090
發(fā)布評論請先 登錄
開售RK3576 高性能人工智能主板
Cognizant將與NVIDIA合作部署神經(jīng)人工智能平臺,加速企業(yè)人工智能應用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論