 關于內存大家都知道,但什么是內存內計算
關于內存大家都知道,但什么是內存內計算

(文章來源:至頂網)
在過去的幾十年中,計算性能的提高是通過更快、更精確地處理更大數量的數據來實現的。內存和存儲空間現在是以千兆字節和兆字節來衡量的,而不是以千字節和兆字節。處理器操作64位而不是8位數據塊。然而,半導體行業創造和收集高質量數據的能力比分析數據的能力增長得更快。
隨著人工智能的不斷發展,逐漸衍生出了一個新興技術,那就是“內存內計算”。而近來,內存內計算也一度成了熱門的關鍵詞。早些時候,IBM就發布了基于相變內存(PCM)的內存內計算,在此之后基于Flash內存內計算的初創公司也獲得高額融資;而在中國,初創公司也開始在做內存內計算方面的嘗試。然而“內存內計算”倒是什么東西?這種新技術的誕生,還要從馮 · 諾依曼體系和人工智能講起。
自從計算機誕生的那天開始,馮 · 諾依曼架構的體系就占據著主導的地位。這種運行計算方式是先把數據存入主存儲器,再按照順序從主存儲器中取出指令,然后一條一條地執行。我們都知道,如果內存的通訊速度跟不上CPU的性能,就會導致計算能力受到限制,這就是內存墻了。同時在效能方面,馮 · 諾依曼體系也存在明顯的缺點,它讀寫一次內存數據的能量,要比計算一次數據的能量多消耗了足足幾百倍。
而在現在人工智能的技術中,隨著數據量越來越多,計算量越來越大,原始的馮 · 諾依曼結構正承受著越來越多的挑戰。硬件架構不能指望計算量一大,就擴展CPU。因為存儲量一變大,就馬上采用增大內存來存儲的方式是對過去架構的嚴重依賴,并且這種方式也非常不適合AI。當容量大到一定程度,只能說明某些技術需要革新。從生物角度來講,大腦存儲了大量的知識,并且能夠快速訪問并提取,而大腦的內存和計算是相容的。未來的計算機不是基于計算的memory,而是基于memory的計算。
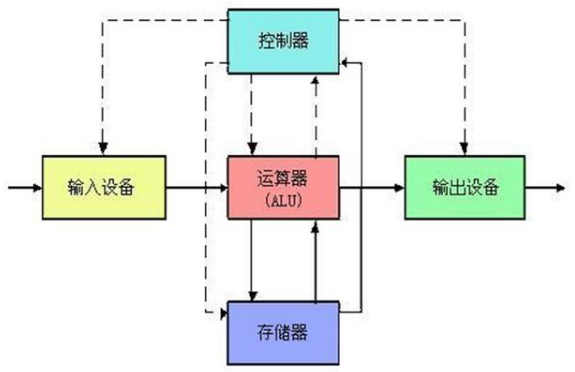
同時,目前最主流的人工智能,也是對計算能力有著極高的要求。如果想讓人工智能用在移動端和嵌入式設備中,還有能耗大,發熱降頻等問題。這樣一來,內存和效能就變成了馮 · 諾依曼計算機體系的一個瓶頸。為了解決這一系列的問題,于是就衍生出了傳說中的內存內計算。顧名思義就是把計算單元嵌入到內存里面,這樣的話內存既是一個存儲器,也是一個計算機,它并不需要從內存中讀取數據,數據是直接進出CPU的。不但不受內存的性能限制,而且還提高了效能比(能源轉換的效率之比)。
人工智能專用的NPU(嵌入式神經網絡處理器)SPR2801S就使用了內存內計算,這種技術還搭建了人工智能專用的APIM構架,它的全稱是AI Processing In Memory。采用了APIM構架的計算機不需要指令,也不需要總線和DDR(雙倍速率同步動態隨機存儲器),大數據就可以直接進出CPU,極大地提高了效能比。此外,它還把算力提高到了5.6T ops,高效能比高達9.2T ops每瓦。Firefly基于這款SPR2801S則推出了人工智能開源主板AIO-3399EC,以及NCC S1 神經網絡計算卡和USB神經網絡計算棒,還搭配了模型訓練工具PLAI。可以說,這些都加速了人工智能項目的落實。
雖然內存內計算現在還處于探索階段,但是人們在十余年之前就認識到了“內存墻”的問題,但是為什么內存內計算直到現在才被人們關注呢?小編認為主要有兩點,第一個就是基于神經網絡的AI的興起,尤其是人們都希望AI能普及到移動端和嵌入式設備中。而神經網絡的其中1個特點就是對于計算精度的誤差有著比較高的容忍度,所以內存內計算的中引入的誤差一般都可以被神經網絡所接受。內存內計算和人工智能,尤其是嵌入式人工智能,可以說是完美的結合。
第二個則是新存儲器分發展。對于內存內計算來說,存儲器的特性決定了它的效率,所以每當帶有新特性的存儲器出現時,都會帶動內存內計算的發展。此外,從存儲器推廣的角度,新存儲器的誕生也愿意搭上人工智能的風潮,這樣一來新存儲器的廠商也樂于看到有人做基于自家存儲器的內存內計算去加速人工智能,也會幫助一起推廣內存內計算。
內存內計算利用存儲器的特點,減少了人工智能在計算中的讀寫和操作,也正是因為內存內計算的精度受到了模擬計算的限制,所以它也是目前為止,最適合追求能效比以及能接受一定精確度損失的嵌入式人工智能的應用。
(責任編輯:fqj)
-
內存
+關注
關注
8文章
3123瀏覽量
75261 -
內存計算
+關注
關注
1文章
15瀏覽量
12240
發布評論請先 登錄
hyper 內存,Hyper內存:如何監控與優化hyper-v虛擬機的內存使用
虛擬內存對計算機性能的影響
虛擬內存不足如何解決 虛擬內存和物理內存的區別
虛擬內存的作用和原理 如何調整虛擬內存設置
DDR內存超頻技巧與注意事項
RAM內存頻率對性能的影響
內存模組n/a怎么解決?
邏輯內存和物理內存的區別
內存管理的硬件結構
內存時鐘是什么意思
內存與主板接觸不良,怎么解決
堆棧和內存的基本知識





 工商網監
工商網監
評論