") 簡(jiǎn)介AI芯片功耗和應(yīng)用分析和發(fā)展
簡(jiǎn)介AI芯片功耗和應(yīng)用分析和發(fā)展

近一年各種深度學(xué)習(xí)平臺(tái)和硬件層出不窮,各種xPU的功耗和面積數(shù)據(jù)也是滿天飛,感覺有點(diǎn)亂。在這里我把我看到的一點(diǎn)情況做一些小結(jié),順便列一下可能的市場(chǎng)。在展開之前,我想強(qiáng)調(diào)的是,深度學(xué)習(xí)的應(yīng)用無數(shù),我能看到的只有能在千萬級(jí)以上的設(shè)備中部署的市場(chǎng),各個(gè)小眾市場(chǎng)并不在列。
深度學(xué)習(xí)目前最能落地的應(yīng)用有兩個(gè)方向,一個(gè)是圖像識(shí)別,一個(gè)是語(yǔ)音識(shí)別。這兩個(gè)應(yīng)用可以在如下市場(chǎng)看到:個(gè)人終端(手機(jī),平板),監(jiān)控,家庭,汽車,機(jī)器人,服務(wù)器。
先說手機(jī)和平板。這個(gè)市場(chǎng)一年的出貨量在30億顆左右(含功能機(jī)),除蘋果外總值300億刀。手機(jī)主要玩家是蘋果(3億顆以下),高通(8億顆以上),聯(lián)發(fā)科(7億顆以上),三星(一億顆以下),海思(一億顆),展訊(6億顆以上),平板總共4億顆左右。而28納米工藝,量很大的話(1億顆以上),工程費(fèi)用可以攤的很低,平均1平方毫米的成本是8美分左右,低端4G芯片(4核)的面積差不多是50平方毫米以下,成本就是4刀。中端芯片(8核)一般在100平方毫米左右,成本8刀。16納米以及往上,同樣的晶體管數(shù),單位成本會(huì)到1.5倍。
一般來說,手機(jī)的物料成本中,處理器芯片(含基帶)價(jià)格占了1/6左右。一個(gè)物料成本90刀的手機(jī),用的處理器一般在15刀以下,甚至只有10刀。這個(gè)10刀的芯片,包含了處理器,圖形處理器,基帶,圖像信號(hào)處理器,每一樣都是高科技的結(jié)晶,卻和肯德基全家桶一個(gè)價(jià),真是有點(diǎn)慘淡。然而生產(chǎn)成本只是一部分,人力也是很大的開銷。一顆智能機(jī)芯片,軟硬開發(fā),測(cè)試,生產(chǎn),就算全用的成熟IP,也不會(huì)少于300人,每人算10萬刀的開銷,量產(chǎn)周期兩年,需要6000萬刀。外加各種EDA工具,IP授權(quán)和開片費(fèi),芯片還沒影子,1億刀就下去了。
言歸正傳,手機(jī)上的應(yīng)用,最直接的就是美顏相機(jī),AR和語(yǔ)音助手。這些需求翻譯成硬件指令就是對(duì)8位整數(shù)點(diǎn)乘(INT8)和16位浮點(diǎn)運(yùn)算(FP16)的支持。具體怎么支持?曾經(jīng)看到過一張圖,我覺得較好的詮釋了這一點(diǎn):
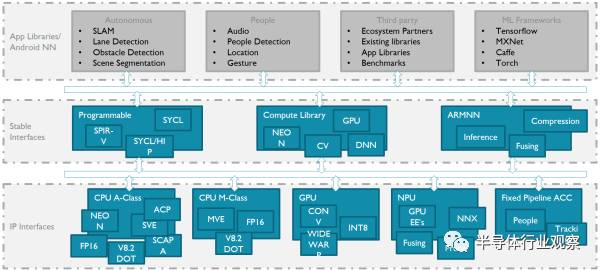
智能手機(jī)和平板上,是安卓的天下,所有獨(dú)立芯片商都必須跟著谷歌爸爸走。谷歌已經(jīng)定義了Android NN作為上層接口,可以支持它的TensorFlow以及專為移動(dòng)設(shè)備定義的TensorFlow Lite。而下層,針對(duì)各種不同場(chǎng)景,可以是CPU,GPU,DSP,也可以是硬件加速器。它們的能效比如下圖:
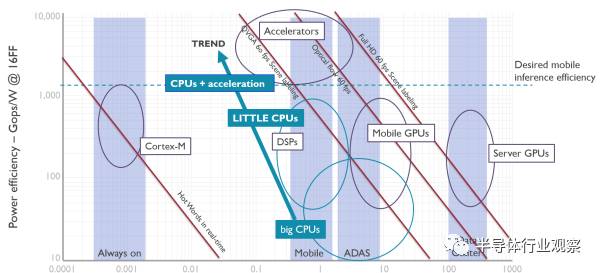
可以看到,在TSMC16納米工藝下,大核能效比是10-100Gops/W(INT8),小核可以做到100G-1Tops/W,手機(jī)GPU是300Gops/W,而要做到1Tops/W以上,必須使用加速器。這里要指出的是,小核前端設(shè)計(jì)思想與大核完全不同,在后端實(shí)現(xiàn)上也使用不同的物理單元,所以看上去和大核的頻率只差50%,但是在邏輯運(yùn)算能效比上會(huì)差4倍以上,在向量計(jì)算中差的就更多了。
手機(jī)的長(zhǎng)時(shí)間運(yùn)行場(chǎng)景下,芯片整體功耗必須小于2.5瓦,分給深度學(xué)習(xí)任務(wù)的,不會(huì)超過1.5瓦。相對(duì)應(yīng)的,如果做到1Tops/W,那這就是1.5T(INT8)的處理能力。對(duì)于照片識(shí)別而言,情況要好些,雖然對(duì)因?yàn)橥ǔ2恍枰L(zhǎng)時(shí)間連續(xù)的處理。這時(shí)候,CPU是可以爆發(fā)然后休息的。語(yǔ)音識(shí)別對(duì)性能要求比較低,100Gops可以應(yīng)付一般應(yīng)用,用小核也足夠。但有些連續(xù)的場(chǎng)景,比如AR環(huán)境識(shí)別,每秒會(huì)有30-60幀的圖像送進(jìn)來,如果不利用前后文幫助判斷,CPU是沒法處理的。此時(shí),就需要GPU或者加速器上場(chǎng)。
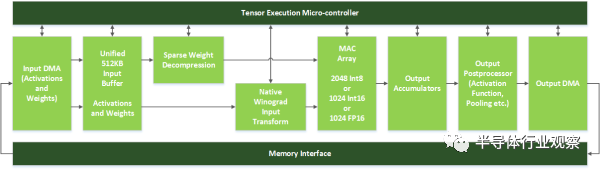
上圖是NVidia的神經(jīng)網(wǎng)絡(luò)加速器DLA,它只有Inference的功能。前面提到在手機(jī)上的應(yīng)用,也只需要Inference來做識(shí)別,訓(xùn)練可以在服務(wù)端預(yù)先處理,訓(xùn)練好的數(shù)據(jù)下載到手機(jī)就行,識(shí)別的時(shí)候無需連接到服務(wù)端。
DLA綠色的模塊形成類似于固定的流水線,上面有一個(gè)控制模塊,可以用于動(dòng)態(tài)分配計(jì)算單元,以適應(yīng)不同的網(wǎng)絡(luò)。我看到的大多數(shù)加速器其實(shí)都是和它大同小異,除了這了幾百K字節(jié)的SRAM來存放輸入和權(quán)值(一個(gè)273x128, 128x128, 128x128 ,128x6 的4層INT8網(wǎng)絡(luò),需要70KBSRAM)外,而有些加速器增加了一個(gè)SmartDMA引擎,可以通過簡(jiǎn)單計(jì)算預(yù)取所需的數(shù)據(jù)。根據(jù)我看到的一些跑分測(cè)試,這個(gè)預(yù)取模塊可以把計(jì)算單元的利用率提高到90%以上。
至于能效比,我看過的加速器,在支持INT8的算法下,可以做到1.2Tops/W (1Ghz@T16FFC),1Tops/mm^2,并且正在向1.5Tops/W靠近。也就是說,1.5W可以獲得2Tops(INT8)的理論計(jì)算能力。這個(gè)計(jì)算能力有多強(qiáng)呢?我這目前處理1080p60FPS的圖像中的60x60及以上的像素大小的人臉識(shí)別,大致需要0.5Tops的計(jì)算能力,2Tops完全可以滿足。當(dāng)然,如果要識(shí)別復(fù)雜場(chǎng)景,那肯定是計(jì)算力越高越好。
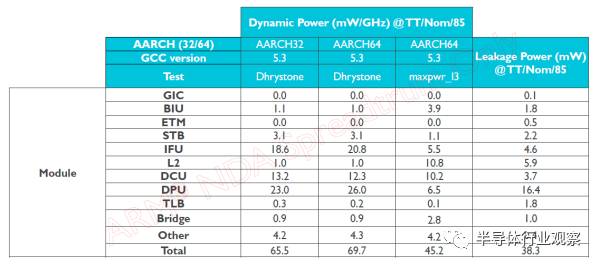
為什么固定流水的能效比能做的高?ASIC的能效比遠(yuǎn)高于通用處理器已經(jīng)是一個(gè)常識(shí),更具體一些,DLA不需要指令解碼,不需要指令預(yù)測(cè),不需要亂序執(zhí)行,流水線不容易因?yàn)榈却龜?shù)據(jù)而停頓。下圖是某小核各個(gè)模塊的動(dòng)態(tài)功耗分布,計(jì)算單元只占1/3,而指令和緩存訪問占了一半。
但是移動(dòng)端僅僅有神經(jīng)網(wǎng)絡(luò)加速器是遠(yuǎn)遠(yuǎn)不夠的。比如要做到下圖效果,那首先要把人體的各個(gè)細(xì)微部位精確識(shí)別,然后用各種圖像算法來打磨。而目前主流圖像算法和深度學(xué)習(xí)沒有關(guān)系,也沒看到哪個(gè)嵌入式平臺(tái)上的加速器在軟件上有很好的支持。目前圖像算法的支持平臺(tái)還主要是PC和DSP,連嵌入式GPU做的都一般。
那這個(gè)問題怎么解決?我看到兩種思路:
第一種,GPU內(nèi)置加速器。下圖是Verisilicon的Vivante改的加速器,支持固定流水的加速器和可編程模塊Vision core(類似GPU中的著色器單元),模塊數(shù)目可配,可以同時(shí)支持視覺和深度學(xué)習(xí)算法。不過在這里,傳統(tǒng)的圖形單元被砍掉了,以節(jié)省功耗和面積。只留下調(diào)度器等共用單元,來做異構(gòu)計(jì)算的調(diào)度。
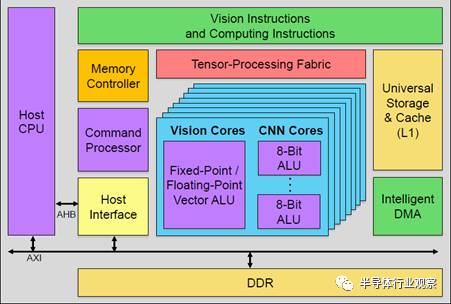
這類加速器比較適合于低端手機(jī),自帶的GPU和CPU本身并不強(qiáng),可能光支持1080p的UI就已經(jīng)耗盡GPU資源了,需要額外的硬件模塊來完成有一定性能需求的任務(wù)。
對(duì)于中高端手機(jī),GPU和CPU的資源在不打游戲的時(shí)候有冗余,那么就沒有必要去掉圖形功能,直接在GPU里面加深度學(xué)習(xí)加速器就可以,讓GPU調(diào)度器統(tǒng)一調(diào)度,進(jìn)行異構(gòu)計(jì)算。
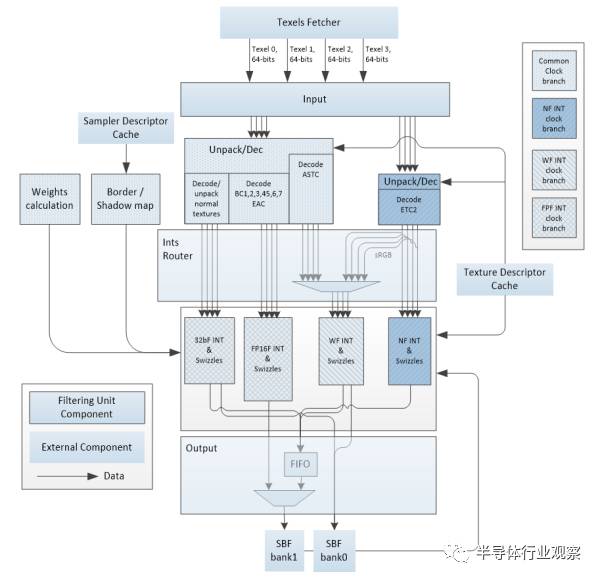
上圖是某款GPU的材質(zhì)計(jì)算單元,你有沒有發(fā)現(xiàn),其實(shí)它和神經(jīng)網(wǎng)絡(luò)加速器的流水線非常類似?都需要權(quán)值,都需要輸入,都需要FP16和整數(shù)計(jì)算,還有數(shù)據(jù)壓縮。所不同的是計(jì)算單元的密度,還有池化和激活。稍作改動(dòng),完全可以兼容,從而進(jìn)一步節(jié)省面積。
但是話說回來,據(jù)我了解,目前安卓手機(jī)上各種圖像,視頻和視覺的應(yīng)用,80%其實(shí)都是用CPU在處理。而谷歌的Android NN,默認(rèn)也是調(diào)用CPU匯編。當(dāng)然,手機(jī)芯片自帶的ISP及其后處理,由于和芯片綁的很緊,還是能把專用硬件調(diào)動(dòng)起來的。而目前的各類加速器,GPU,DSP,要想和應(yīng)用真正結(jié)合,還有挺長(zhǎng)的路要走。
終端設(shè)備上還有一個(gè)應(yīng)用,AR。據(jù)說iPhone8會(huì)實(shí)現(xiàn)這個(gè)功能,如果是的話,那么估計(jì)繼2015的VR/AR,2016的DL,2017的NB-IOT之后,2018年又要回鍋炒這個(gè)了。
那AR到底用到哪些技術(shù)?我了解的如下,先是用深度傳感器得到場(chǎng)景深度信息,然后結(jié)合攝像頭拍到的2維場(chǎng)景,針對(duì)某些特定目標(biāo)(比如桌子,面部)構(gòu)建出一個(gè)真實(shí)世界的三維物體。這其中需要用到圖像識(shí)別來幫助判斷物體,還需要確定物體邊界。有了真實(shí)物體的三維坐標(biāo),就可以把所需要渲染的虛擬對(duì)象,貼在真實(shí)物體上。然后再把攝像頭拍到的整個(gè)場(chǎng)景作為材質(zhì),貼到背景圖層,最后把所有這些圖層輸出到GPU或者硬件合成器,合成最終輸出。這其中還需要判斷光源,把光照計(jì)算渲染到虛擬物體上。這里每一步的計(jì)算量有多大?
首先是深度信息計(jì)算。獲取深度信息目前有三個(gè)方法,雙目攝像頭,結(jié)構(gòu)光傳感器還有TOF。他們分別是根據(jù)光學(xué)圖像差異,編碼后的紅外光模板和反射模板差異,以及光脈沖飛行時(shí)間來的得到深度信息。
第一個(gè)的缺點(diǎn)是需要兩個(gè)攝像頭之間有一定距離并且對(duì)室內(nèi)光線亮度有要求,第二個(gè)需要大量計(jì)算并且室外效果不佳,第三個(gè)方案鏡頭成本較高。據(jù)說蘋果會(huì)用結(jié)構(gòu)光方案,主要場(chǎng)景是室內(nèi),避免了缺點(diǎn)。結(jié)構(gòu)光傳感器的成本在2-3刀之間,也是可以接受的。
而對(duì)于計(jì)算力的要求,最基本的是對(duì)比兩個(gè)經(jīng)過偽隨機(jī)編碼處理過的發(fā)射模板以及接受模板,計(jì)算出長(zhǎng)度差,然后用矩陣倒推平移距離,從而得到深度信息。這可以用專用模塊來處理,我看到單芯片的解決方案,720p60FPS的處理能力,需要10GFLOPS的計(jì)算量以上。換成CPU,就是4-8核。
當(dāng)然,我們完全可以先識(shí)別出目標(biāo)物體,用圖像算法計(jì)算出輪廓,還可以降低深度圖的精度(通常不需要很精確),從而大大降低計(jì)算量。而識(shí)別本身的計(jì)算量前文已經(jīng)給出,計(jì)算輪廓是經(jīng)典的圖像處理手段,針對(duì)特定區(qū)域的話計(jì)算量非常小,1-2個(gè)核就可以搞定。
接下去是根據(jù)深度圖,計(jì)算真實(shí)物體的三維坐標(biāo),并輸出給GPU。這個(gè)其實(shí)就是GPU渲染的第一階段的工作,稱作頂點(diǎn)計(jì)算。在移動(dòng)設(shè)備上,這部分通常只占GPU總計(jì)算量的10%,后面的像素計(jì)算才是大頭。產(chǎn)生虛擬物體的坐標(biāo)也在這塊,同樣也很輕松。
接下去是生成背景材質(zhì),包括產(chǎn)生minimap等。這個(gè)也很快,沒什么計(jì)算量,把攝像頭傳過來的原始圖像放到內(nèi)存,告訴GPU就行。
稍微麻煩一些的是計(jì)算虛擬物體的光照。背景貼圖的光照不需要計(jì)算,使用原圖中的就可以。而虛擬物體需要從背景貼圖抽取亮度和物體方向,還要計(jì)算光源方向。我還沒有見過好的算法,不過有個(gè)取巧,就是生成一個(gè)光源,給一定角度從上往下照,如果對(duì)AR要求不高也湊合了。
其他的渲染部分,和VR有些類似,什么ATW啊,F(xiàn)ront Buffer啊,都可以用上,但是不用也沒事,畢竟不是4K120FPS的要求。總之,AR如果做的不那么復(fù)雜,對(duì)CPU和GPU的性能要求并不高,搞個(gè)圖像識(shí)別模塊,再多1-2個(gè)核做別的足矣。
有了計(jì)算量,深度學(xué)習(xí)加速器對(duì)于帶寬的需求是多少?大部分?jǐn)?shù)據(jù)都是只需要一次,1Tops的計(jì)算量需要5GB/s以下的帶寬。連接方法可以放到CPU的加速口ACP(跑在1.8GHz的ARMv8.2內(nèi)部總線可以提供9GB/s帶寬)。只用一次的數(shù)據(jù)可以設(shè)成非共享類型,需要和CPU交換或者常用的數(shù)據(jù)使用Cacheable和Shareable類型,既可以在三級(jí)緩存分配空間,還可以更高效的做監(jiān)聽操作,免掉刷緩存。
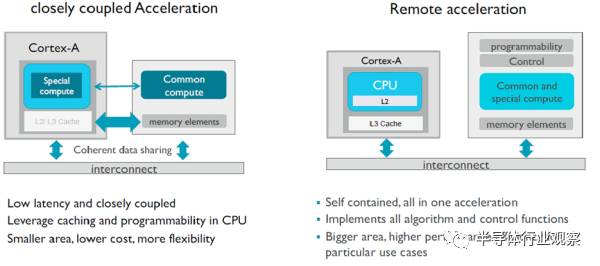
如果加速器在GPU上,那么還是得用傳統(tǒng)的ACE口,一方面提高帶寬,一方面與GPU的核交換數(shù)據(jù)在內(nèi)部進(jìn)行,當(dāng)然,與CPU的交互必然會(huì)慢一些。
在使用安卓的終端設(shè)備上,深度學(xué)習(xí)可以用CPU/DSP/GPU,也可以是加速器,但不管用哪個(gè),一定要跟緊谷歌爸爸。谷歌以后會(huì)使用Vulkan Compute來替代OpenCL,使用Vulkan 來替代OpenGL ES,做安卓GPU開發(fā)的同學(xué)可以早點(diǎn)開始熟悉了。
高通推過用手機(jī)做訓(xùn)練,然后手機(jī)間組網(wǎng),形成強(qiáng)大的計(jì)算力。從我的角度看,這個(gè)想法問題多多,先不說實(shí)際應(yīng)用,誰會(huì)沒事開放手機(jī)給別人訓(xùn)練用?耗電根本就吃不消。并且,要是我知道手機(jī)偷偷的上傳我的圖像和語(yǔ)音模板到別人那里,絕對(duì)不會(huì)買。
第二個(gè)市場(chǎng)是家庭,包括機(jī)頂盒/家庭網(wǎng)關(guān)(4億顆以下),數(shù)字電視(3億顆以下),電視盒子(1億以下)三大塊。整個(gè)市場(chǎng)出貨量在7億片,電器里面的MCU并沒有計(jì)算在內(nèi)。這個(gè)市場(chǎng)公司比較散,MStar/海思/博通/Marvell/Amlogic都在里面,小公司更是無數(shù)。如果沒有特殊要求,拿平板的芯片配個(gè)wifi就可以用。當(dāng)然,中高端的對(duì)畫質(zhì)還是有要求,MTK現(xiàn)在的利潤(rùn)從手機(jī)移到了電視芯片,屏幕顯示這塊有獨(dú)到的技術(shù)。很多機(jī)頂盒的網(wǎng)絡(luò)連接也不是以太網(wǎng),而是同軸電纜等,這種場(chǎng)合也得專門的芯片。最近,這個(gè)市場(chǎng)里又多了一個(gè)智能音箱,各大互聯(lián)網(wǎng)公司又拿出當(dāng)年追求手機(jī)入口的熱情來布局,好不熱鬧。
家庭電子設(shè)備里還有一個(gè)成員,游戲機(jī)。Xbox和PS每年出貨量均在千萬級(jí)別。VR/AR和人體識(shí)別早已經(jīng)用在其中。
對(duì)于語(yǔ)音設(shè)別,100Gops的性能需求對(duì)于無風(fēng)扇設(shè)計(jì)引入的3瓦功耗限制,CPU/DSP和加速器都可以選。不過工藝就得用28納米了或者更早的了,畢竟沒那么多量,撐不起16納米。最便宜的方案,可以使用RISC-V+DLA,沒有生態(tài)系統(tǒng)綁定的情況下最省成本。獨(dú)立的加速器本身對(duì)CPU要求并不高,不像GPU那樣需要支持OpenCL/OpenGL ES。8核G71@900Mhz差不多需要一個(gè)2GHz的A73來支持。并且由于OpenGL ES的限制,還不能使用小核來分擔(dān)任務(wù)。而100Gops的語(yǔ)音處理我估計(jì)幾百兆赫茲的處理器就可以了。
圖像方面的應(yīng)用,主要還是人臉識(shí)別和播放內(nèi)容識(shí)別,不過這還沒有成為一個(gè)硬需求。之前提過,0.5Tops足以搞定簡(jiǎn)單場(chǎng)景,4K分辨率的話,性能需求是1080p的四倍。
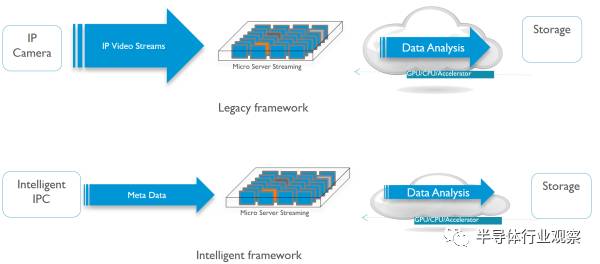
接下去是監(jiān)控市場(chǎng)。監(jiān)控市場(chǎng)上的圖像識(shí)別是迄今為止深度學(xué)習(xí)最硬的需求。監(jiān)控芯片市場(chǎng)本身并不大,有1億顆以上的量,銷售額20億刀左右。主流公司有安霸,德州儀器和海思,外加幾個(gè)小公司,OEM自己做芯片的也有。
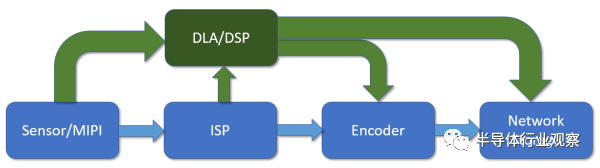
傳統(tǒng)的監(jiān)控芯片數(shù)據(jù)流如上圖藍(lán)色部分,從傳感器進(jìn)來,經(jīng)過圖像信號(hào)處理單元,然后送給視頻編碼器編碼,最后從網(wǎng)絡(luò)輸出。如果要對(duì)圖像內(nèi)容進(jìn)行識(shí)別,那可以從傳感器直接拿原始數(shù)據(jù),或者從ISP拿處理過的圖像,然后進(jìn)行識(shí)別。
中高端的監(jiān)控芯片中還會(huì)有個(gè)DSP,做一些后處理和識(shí)別的工作。現(xiàn)在深度學(xué)習(xí)加速器進(jìn)來,其實(shí)和DSP是有些沖突的。以前的一些經(jīng)典應(yīng)用,比如車牌識(shí)別等,DSP其實(shí)就已經(jīng)做得很好了。如果要做識(shí)別以外的一些圖像算法,這顆DSP還是得在通路上,并不能被替代。并且,DSP對(duì)傳統(tǒng)算法的軟件庫(kù)支持要好得多。這樣,DSP替換不掉,額外增加處理單元在成本上就是一個(gè)問題。
對(duì)于某些低功耗的場(chǎng)景,我看到有人在走另外一條路。那就是完全扔掉DSP,放棄存儲(chǔ)和傳輸視頻及圖像,加入加速器,只把特征信息和數(shù)據(jù)通過NB-IOT上傳。這樣整個(gè)芯片功耗可以控制在500毫瓦之下。整個(gè)系統(tǒng)結(jié)合傳感器,只在探測(cè)到有物體經(jīng)過的時(shí)候打開,平時(shí)都處于幾毫瓦的待機(jī)狀態(tài)。在供電上,采用太陽(yáng)能電池,10mmx20mm的面板,輸出功率可以有幾瓦。不過這個(gè)產(chǎn)品目前應(yīng)用領(lǐng)域還很小眾。
做識(shí)別的另一個(gè)途徑是在局端。如果用顯卡做,GFX1080的FP32 GLOPS是9T,180瓦,1.7Ghz,16納米,320mm。而一個(gè)Mali G72MP32提供1T FP32的GFLOPS,16納米,850Mhz,8瓦,9T的話就是72瓦,666mm。當(dāng)然,如果G72設(shè)計(jì)成跑在1.7Ghz,我相信不會(huì)比180瓦低。此外桌面GPU由于是Immediate rendering的,帶寬大,但對(duì)緩存沒有很大需求,所以移動(dòng)端的GPU面積反而大很多,但相對(duì)的,它對(duì)于帶寬需求小很多,相應(yīng)的功耗少很多
GPU是拿來做訓(xùn)練的,而視頻識(shí)別只需要做Inference,如果用固定流水的加速器,按照之前給的數(shù)據(jù),9T FP32 GLOPS換算成36Tops的INT8,只需要36mm。9Tops對(duì)應(yīng)的識(shí)別能力是20路1080p60fps,20路1080p60fps視頻解碼器對(duì)應(yīng)的面積差不多是 10mm,加上SRAM啥的,估計(jì)100mm以下。如果有一千萬的量,那芯片成本可以做到20美金以下,而一塊GFX1080板子的售價(jià)是1000美金(包括DDR顆粒),暴利。國(guó)內(nèi)現(xiàn)在不少小公司拿到了投資在做這塊的芯片。
第四個(gè)市場(chǎng)是機(jī)器人/無人機(jī)。機(jī)器人本身有多少量我沒有數(shù)據(jù),手機(jī)和平板的芯片也能用在這個(gè)領(lǐng)域。無人機(jī)的話全球一年在200萬左右,做視覺處理的芯片也應(yīng)該是這個(gè)量級(jí)。。用到的識(shí)別模塊目前看還是DSP和CPU為主,因?yàn)镈SP還可以做很多圖像算法,和監(jiān)控類似。這個(gè)市場(chǎng)對(duì)于ISP和深度信息的需求較高,雙攝和結(jié)構(gòu)光都可以用來算深度計(jì)算,上文提過就不再展開。
在無人機(jī)上做ISP和視覺處理,除了要更高的清晰度和實(shí)時(shí)性外,還比消費(fèi)電子多了一個(gè)要求,容錯(cuò)。無人機(jī)的定位都靠視覺,如果給出的數(shù)據(jù)錯(cuò)誤或者模塊無反應(yīng)都不符合預(yù)期。解決這個(gè)問題很簡(jiǎn)單,一是增加各種片內(nèi)存儲(chǔ)的ECC和內(nèi)建自檢,二是設(shè)兩個(gè)同樣功能的模塊,錯(cuò)開時(shí)鐘輸入以避免時(shí)鐘信號(hào)引起的問題,然后輸出再等相同周期,同步到一個(gè)時(shí)鐘。如果兩個(gè)結(jié)果不一致,那就做特殊處理,避免擴(kuò)散數(shù)據(jù)錯(cuò)誤。
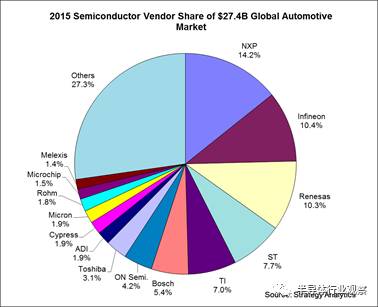
第五個(gè)市場(chǎng)是汽車,整個(gè)汽車芯片市場(chǎng)近300億刀,玩家眾多:
在汽車電子上,深度學(xué)習(xí)的應(yīng)用就是ADAS了。在ADAS里面,語(yǔ)音和視覺從技術(shù)角度和前幾個(gè)市場(chǎng)差別不大,只是容錯(cuò)這個(gè)需求進(jìn)一步系統(tǒng)化,形成Function Safety,整個(gè)軟硬件系統(tǒng)都需要過認(rèn)證,才容易賣到前裝市場(chǎng)。Function Safety比之前的ECC/BIST/Lock Step更進(jìn)一步,需要對(duì)整個(gè)芯片和系統(tǒng)軟件提供詳細(xì)的測(cè)試代碼和文檔,分析在各類場(chǎng)景下的錯(cuò)誤處理機(jī)制,連編譯器都需要過認(rèn)證。認(rèn)證本身分為ASIL到A-ASIL-D四個(gè)等級(jí),最高等級(jí)要求系統(tǒng)錯(cuò)誤率小于1%。我對(duì)于這個(gè)認(rèn)證并不清楚,不過國(guó)內(nèi)很多手機(jī)和平板芯片用于后裝市場(chǎng)的ADAS,提供語(yǔ)音報(bào)警,出貨量也是過百萬的。
最后放一張ARM的ADAS參考設(shè)計(jì)框圖。
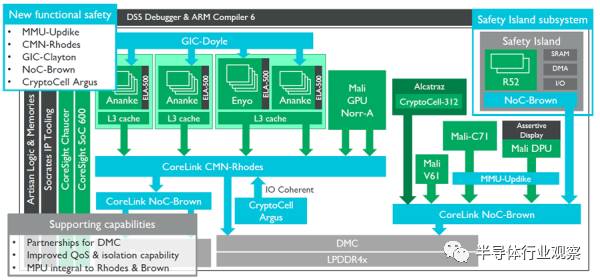
可能不會(huì)有人照著這個(gè)去設(shè)計(jì)ADAS芯片,不過有幾處可以借鑒:
右方是安全島,內(nèi)涵Lock Step的雙Cortex-R52,這是為了能夠保證在左邊所有模塊失效的情況下復(fù)位整個(gè)系統(tǒng)或者進(jìn)行異常中斷處理的。中部藍(lán)色和綠色的CryptoCell模塊是對(duì)整個(gè)系統(tǒng)運(yùn)行的數(shù)據(jù)進(jìn)行保護(hù),防止惡意竊取的。關(guān)于Trustzone設(shè)計(jì)我以前的文章有完整介紹這里就不展開了。
以上幾個(gè)市場(chǎng)基本都是Inference的需求,其中大部分是對(duì)原有產(chǎn)品的升級(jí),只有ADAS,智能音箱和服務(wù)器端的視頻識(shí)別檢測(cè)是新的市場(chǎng)。其中智能音箱達(dá)到了千萬級(jí)別,其它的兩個(gè)還都在擴(kuò)張。
接下去的服務(wù)端的訓(xùn)練硬件,可以用于訓(xùn)練的移動(dòng)端GPU每個(gè)計(jì)算核心面積是1.5mm(TSMC16nm),跑在1Ghz的時(shí)候能效比是300Gops/W。其他系統(tǒng)級(jí)的性能數(shù)據(jù)我就沒有了。雖然這個(gè)市場(chǎng)很熱,NVidia的股票也因此很貴,但是我了解到全球用于深度學(xué)習(xí)訓(xùn)練的GPU銷售額,一年只有1億刀不到。想要分一杯羹,可能前景并沒有想象的那么好。
最近970發(fā)布,果然上了寒武紀(jì)。不過2T ops FP16的性能倒是讓我吃了一驚,我倒推了下這在16nm上可能是10mm的面積,A73MP4+A53MP4+3MB二級(jí)緩存也就是這點(diǎn)大小。麒麟芯片其實(shí)非常強(qiáng)調(diào)面積成本,而在高端特性上這么舍得花面積,可見海思要在高端機(jī)上走出自己的特色之路的決心,值得稱道。不過寒武紀(jì)既然是個(gè)跑指令的通用處理器,那除了深度學(xué)習(xí)的計(jì)算,很多其他場(chǎng)合也能用上,比如ISP后處理,計(jì)算結(jié)構(gòu)光深度信息等等,能效可能比DSP還高些。
-
處理器
+關(guān)注
關(guān)注
68文章
19863瀏覽量
234402 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103284 -
AI芯片
+關(guān)注
關(guān)注
17文章
1979瀏覽量
35809
發(fā)布評(píng)論請(qǐng)先 登錄
成都匯陽(yáng)投資關(guān)于芯片+AI 眼鏡核心公司
Nordic收購(gòu) Neuton.AI 關(guān)于產(chǎn)品技術(shù)的分析
能效比達(dá)2TOPS/W!解密邊緣AI芯片低功耗設(shè)計(jì)之法
Nordic nRF54 系列芯片:開啟 AI 與物聯(lián)網(wǎng)新時(shí)代?
**【技術(shù)干貨】Nordic nRF54系列芯片:傳感器數(shù)據(jù)采集與AI機(jī)器學(xué)習(xí)的完美結(jié)合**
AI眼鏡產(chǎn)業(yè)初興,這顆芯片150uA低功耗、省電90%能否引爆賽道
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測(cè)......
AI賦能邊緣網(wǎng)關(guān):開啟智能時(shí)代的新藍(lán)海
AI模型市場(chǎng)分析
UWB模塊的功耗分析
Orin芯片功耗分析
RISC-V在AI領(lǐng)域的發(fā)展前景怎么樣?
AM62A Edge AI零售掃描儀演示:SoC選型和功耗分析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論