") 2D轉(zhuǎn)3D技術(shù)的便利性和方法
2D轉(zhuǎn)3D技術(shù)的便利性和方法

為什要進(jìn)行2D轉(zhuǎn)3D?
傳統(tǒng)的數(shù)字高清2D電視已經(jīng)不能滿足人們對視頻的真實(shí)感的要求,迎接3D電視的到來。
3D視頻的內(nèi)容主要來自三個(gè)個(gè)方面,其一,立體攝像機(jī)直接產(chǎn)生的視頻;其二,將原有的2D視頻信號(hào)轉(zhuǎn)換為3D視頻信號(hào);其三,計(jì)算機(jī)生成圖像(CGI);
好處:
1.目前存在大量的傳統(tǒng)2D視頻,重現(xiàn)銀幕經(jīng)典。
2.技術(shù)尚未完全成型,特別是在3D電視方面,如果研究出很好的算法,有很大的商業(yè)潛力!
3D 成像的基本原理
基本原理:人類的左眼和右眼在水平方向上有5~6.5cm的位移,因此左右眼所看見的畫面中對應(yīng)實(shí)際物體上同一點(diǎn)存在一定距離,通過這種差別判斷物體的遠(yuǎn)近和深度,即視差parallax原理。
根據(jù)“視差”原理,把同一景像用兩只眼睛視角的差距制造出兩個(gè)影像,然后讓兩只眼睛各看到對應(yīng)自己一邊的影像,就能刺激大腦產(chǎn)生3D(3Dimensions)立體效果的。
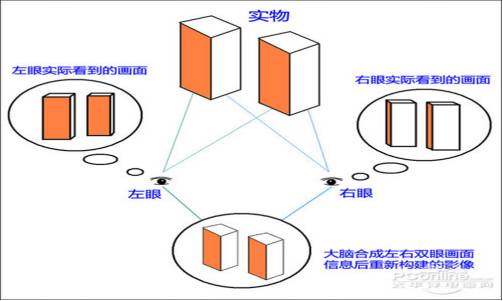
舉例:
1、大家可以輪流閉上一只眼試試--看同一個(gè)東西,側(cè)面不同
2、單眼對筆尖--比雙眼困難很多
2D轉(zhuǎn)3D技術(shù)分析
簡單的說就是從場景的一副圖像或者一系列圖像中,推導(dǎo)出該場景的精確的三維幾何描述,并定量地確定場景中物體的性質(zhì)。
主要步驟:
1.生成灰度圖
2.生成主輪廓圖,表示出圖像中重要物體的邊緣(圖像分割技術(shù))
3.生成深度圖,表示出以觀看者為中心的圖像中各物體的深度
4.3D呈現(xiàn),表示出圖像中各物體的空間幾何結(jié)構(gòu)
5.最終的3D表示所謂的3D圖像對,即略微不同的圖像,其中一個(gè)為左眼圖像,另一個(gè)為右眼圖像。
幾個(gè)關(guān)鍵詞
深度線索:用來提取三維信息的圖像特征
深度圖:通常表示為灰度圖,每一個(gè)像素點(diǎn)的值即為該點(diǎn)的深度
零視差、正視差、負(fù)視差:一個(gè)點(diǎn)落在銀幕上、一個(gè)點(diǎn)介于銀幕與觀看者之間、一個(gè)點(diǎn)看起來在銀幕平面遠(yuǎn)離觀看者。
3D圖的表示方法:一種是采用雙目視差圖方式的3D圖像對;另一種是采用2D圖加深度圖的方式
視差圖與深度圖的關(guān)系
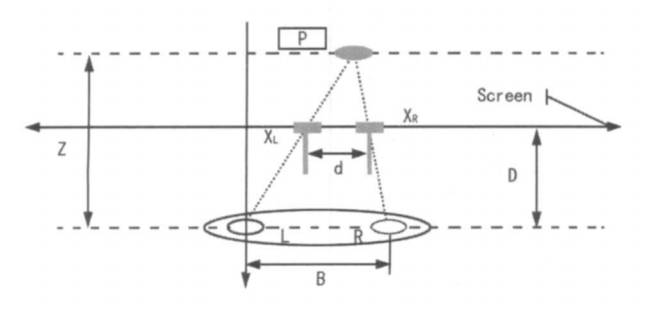
深度幾何關(guān)系
z為實(shí)物到眼睛的距離,即為深度;B為左眼與右眼的距離;XL 與XR 分別為三維世界中的點(diǎn) P 在左眼圖像中的銀幕坐標(biāo)與點(diǎn) P 在右眼圖像中的銀幕坐標(biāo)。 D 為眼睛與銀幕之間的距離。
通過控制視差d我們可以達(dá)到控制可視深度的目的,通常的做法是將作為左眼圖像,并通過增加視差來產(chǎn)生右眼圖像。
2D轉(zhuǎn)3D的基本框架
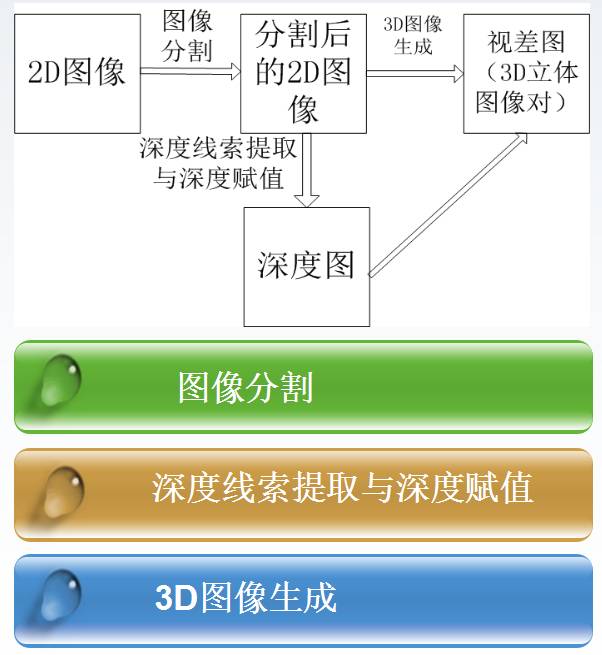
圖像分割
圖像分割的主要目標(biāo)是將圖像劃分為與其中含有的真實(shí)世界的物體或區(qū)域有強(qiáng)相關(guān)性的組成部分。
圖像分割算法一般是基于亮度值的兩個(gè)基本特征之一: 不連續(xù)性和相似性。
分割的越細(xì)致,通過后期的深度提取與深度賦值產(chǎn)生的3D世界就越有深度感。
從深度線索中提取深度
基于深度提取算法所依賴的深度線索我們可以將深度提取算法分為12類。
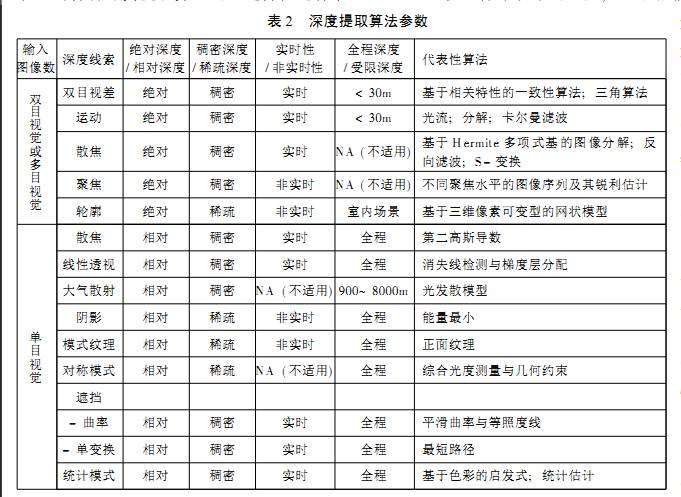
根據(jù)立體的效果,要不斷的調(diào)整獲取的深度信息,人工很浪費(fèi)時(shí)間。
雙目視差深度線索
原理:從兩個(gè)不同視點(diǎn)拍攝得到的同一個(gè)場景的兩幅圖像之間存在雙目視差。雙目視差模擬了人眼觀察實(shí)物的機(jī)制,是深度感知的重要線索,通過立體匹配的方法在兩幅圖像中尋找對應(yīng)的像素,計(jì)算雙目視差,視差越大,場景越近,視差越小,場景越遠(yuǎn);將雙目視差轉(zhuǎn)換為場景深度
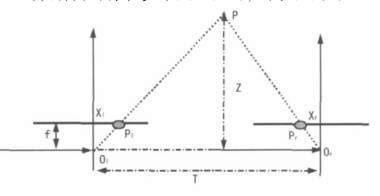
P l 與P r 是3D 世界中點(diǎn) P 在左圖像和右圖像上的投影, O l 與 Or 是左攝像機(jī)與右攝像機(jī)坐標(biāo)系統(tǒng)中的原點(diǎn)
點(diǎn)P的深度值Z可通過如下公式計(jì)算:
Z= f*T/d
其中 d= x r -x l
陰影深度線索
原理:人類的大腦能夠非常好的利用陰影及一般情況下的明暗度提供的線索。檢測到的陰影不僅明確地指示了隱藏邊緣的位置和與其鄰近的表面的可能方向, 而且一般的敏感度性質(zhì)對于導(dǎo)出深度信息有重要的價(jià)值。
一個(gè)典型的例子是人臉的照片, 從直接的2D 表示, 我們的大腦可以很好的猜出其可能的照明模型, 進(jìn)而推斷出人臉的3D 性質(zhì)。
分析
這些方法都是在實(shí)際操作時(shí)科研人員發(fā)現(xiàn)的單目深度技術(shù)比較困難,有時(shí)僅僅有一幅圖像得到的僅僅是深度關(guān)系,而不是實(shí)際的深度。
目前的主流算法是利用雙目深度線索,結(jié)合多幅圖像在空間維度與時(shí)間維度上相關(guān)性來獲取場景的深度信息,特定環(huán)境下采用單目技術(shù)。
沒有一個(gè)系統(tǒng)的普遍的算法,這也是2D轉(zhuǎn)3D技術(shù)研究中的難題。
由深度圖進(jìn)行3D圖合成!
從深度圖進(jìn)行3D圖合成
過程:從深度圖到立體圖像對生成, 實(shí)際上是從原始圖像結(jié)合深度圖生成左眼圖像與 右眼圖像。而左右眼圖像是通過對分割后物體的平移操作獲得的。
最初的是將原始的2D圖像作為一個(gè)眼的圖像,平移得到另一個(gè)眼的圖像。
現(xiàn)在
原始的2D素材被當(dāng)作介于左右畫面的中間畫面,左右眼的圖像都是經(jīng)過的平移得到的。
減小了因?yàn)橛?jì)算造成的畫面變形。
后期制作
得到3D圖像對之后,根據(jù)3D效果要對前面的步驟不斷的微調(diào),已達(dá)到最好的3D效果。
-
3D
+關(guān)注
關(guān)注
9文章
2959瀏覽量
110726 -
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18339 -
深度
+關(guān)注
關(guān)注
0文章
12瀏覽量
8933
發(fā)布評論請先 登錄
針對顯示屏的2D/3D觸摸與手勢開發(fā)工具包DV102014
為什么3D與2D模型不能相互轉(zhuǎn)換?
2D到3D視頻自動(dòng)轉(zhuǎn)換系統(tǒng)
適用于顯示屏的2D多點(diǎn)觸摸與3D手勢模塊
如何把OpenGL中3D坐標(biāo)轉(zhuǎn)換成2D坐標(biāo)
3D 機(jī)器視覺為什么將逐步取代 2D 識(shí)別技術(shù)?
阿里研發(fā)全新3D AI算法,2D圖片搜出3D模型
谷歌發(fā)明的由2D圖像生成3D圖像技術(shù)解析

3d人臉識(shí)別和2d人臉識(shí)別的區(qū)別
基于神經(jīng)網(wǎng)絡(luò)的2D到3D的機(jī)器學(xué)習(xí)
探討一下2D和3D拓?fù)浣^緣體
2D與3D視覺技術(shù)的比較
一文了解3D視覺和2D視覺的區(qū)別
介紹一種使用2D材料進(jìn)行3D集成的新方法
有了2D NAND,為什么要升級到3D呢?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論