") NLP界的“神話”并沒那么神?
NLP界的“神話”并沒那么神?
曾經(jīng)狂掃11項(xiàng)記錄的谷歌NLP模型BERT,近日遭到了網(wǎng)友的質(zhì)疑:該模型在一些基準(zhǔn)測(cè)試中的成功僅僅是因?yàn)槔昧藬?shù)據(jù)集中的虛假統(tǒng)計(jì)線索,如若不然,還沒有隨機(jī)的結(jié)果好。這項(xiàng)研究已經(jīng)在Reddit得到了廣泛的討論。
NLP神話被質(zhì)疑。
自去年谷歌發(fā)布BERT以來,這個(gè)曾狂破11項(xiàng)紀(jì)錄、全面超越人類的NLP模型就備受關(guān)注,熱度不減。
然而,近日一位Reddit網(wǎng)友卻對(duì)此拋出質(zhì)疑:BERT在一些基準(zhǔn)測(cè)試中的成功僅僅是因?yàn)槔昧藬?shù)據(jù)集中虛假的統(tǒng)計(jì)線索。若是沒有它們,可能還沒有隨機(jī)的結(jié)果好。
Reddit地址:
https://www.reddit.com/r/MachineLearning/comments/cfxpxy/berts_success_in_some_benchmarks_tests_may_be/
這項(xiàng)論文是由***成功大學(xué)的研究人員完成。

論文地址:
https://arxiv.org/pdf/1907.07355.pdf
研究人員表示:
我們驚訝地發(fā)現(xiàn)BERT在參數(shù)推理理解任務(wù)中的峰值性能達(dá)到77%,僅比平均未經(jīng)訓(xùn)練的人類基線低3個(gè)點(diǎn)。但是,我們表明這個(gè)結(jié)果完全是通過利用數(shù)據(jù)集中的虛假統(tǒng)計(jì)線索來解釋的。
我們分析了這些線索的性質(zhì),并證明了一系列模型都在利用它們。該分析報(bào)告了一個(gè)對(duì)抗性數(shù)據(jù)集的構(gòu)造,所有模型都在該數(shù)據(jù)集上實(shí)現(xiàn)隨機(jī)精度。
Reddit網(wǎng)友lysecret對(duì)此研究表示:

他認(rèn)為這是一種非常簡(jiǎn)單而有效的方法來表明這類模型是不能正確地做到“理解”的,智能利用(不好的)統(tǒng)計(jì)線索。然而,對(duì)于大多數(shù)人(除了埃隆·馬斯克)來說可能都會(huì)認(rèn)為,像BERT這類模型的就是這么做的。
BERT在論證理解方面真的學(xué)到什么了嗎?
論證挖掘是確定自然語言文本中的論證結(jié)構(gòu)的任務(wù)。例如,哪些文本段代表claim,并且包括支持或攻擊這些claim的reason。
對(duì)于機(jī)器學(xué)習(xí)者來說,這是一項(xiàng)具有挑戰(zhàn)性的任務(wù),因?yàn)榧词故侨祟愐埠茈y確定兩個(gè)文本段何時(shí)處于爭(zhēng)論關(guān)系中,正如對(duì)論證注釋的研究所證明的那樣。解決這個(gè)問題的一個(gè)方法是專注于warrant(權(quán)證)——一種允許推理的世界知識(shí)形式。
考慮一個(gè)簡(jiǎn)單的論點(diǎn):“(1)正在下雨;因此(2)你應(yīng)該拿一把傘。” Warrant“(3)弄濕是不好的”可以許可這個(gè)推論。知道(3)有助于得出(1)和(2)之間的推論聯(lián)系。
然而,很難在任何地方找到它,因?yàn)閣arrant通常是隱含的。因此,在這種方法中,機(jī)器學(xué)習(xí)者不僅必須使用warrant進(jìn)行推理,還要發(fā)現(xiàn)它們。
論證推理理解任務(wù)(ARCT)推遲發(fā)現(xiàn)warrant的問題,并側(cè)重于推理。提供了一個(gè)包含claim C和reason R的論點(diǎn)。該任務(wù)是在分心器上選擇正確的warrant W,稱為備選warrant A。
該備選方案的書寫方式是R∧A→?C。之前例子的另一種保證可能是“(4)濕是好的”,在這種情況下我們有(1)∧(4)→“(?2)你不應(yīng)該拿傘。”數(shù)據(jù)集中的一個(gè)例子如圖1所示。

圖1:ARCT測(cè)試集中的一個(gè)數(shù)據(jù)點(diǎn)示例以及如何讀取它。從R和A到?C的推論是通過設(shè)計(jì)得出的。
ARCT SemEval共享任務(wù),驗(yàn)證了該問題的挑戰(zhàn)性。即使提供warrant,學(xué)習(xí)者仍需要依賴進(jìn)一步的世界知識(shí)。
例如,為了正確地對(duì)圖1中的數(shù)據(jù)點(diǎn)進(jìn)行分類,至少需要知道消費(fèi)者選擇和網(wǎng)絡(luò)重定向如何與壟斷概念相關(guān),并且Google是搜索引擎。除了一個(gè)參與系統(tǒng)之外,所有參與共享任務(wù)的系統(tǒng)的準(zhǔn)確度不能超過60%(二進(jìn)制分類)。
因此,令人驚訝的是,BERT以其最佳運(yùn)行(表1)實(shí)現(xiàn)了77%的測(cè)試集精度,僅比平均(未訓(xùn)練的)人類基線低3個(gè)點(diǎn)。如果沒有為這項(xiàng)任務(wù)提供所需的世界知識(shí),那么期望它表現(xiàn)如此之好似乎是不合理的。這就激發(fā)了一個(gè)問題:BERT在論證理解方面學(xué)到了什么?
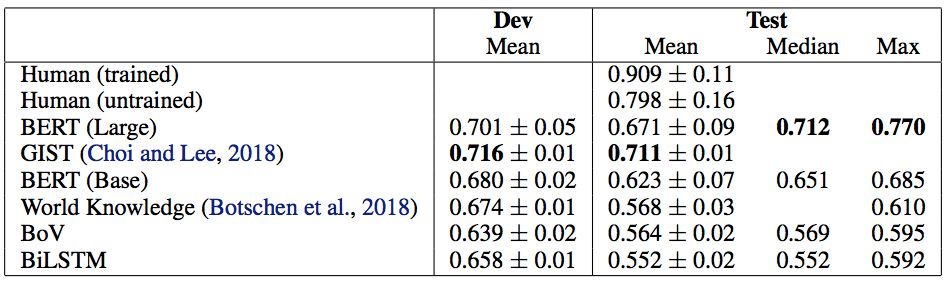
表1:基線和BERT結(jié)果。我們的結(jié)果來自20個(gè)不同的隨機(jī)種子(±給出標(biāo)準(zhǔn)偏差)。BERT Large的平均值受到5/20隨機(jī)種子的影響而不能訓(xùn)練,這是Devlin等人提出的一個(gè)問題。因此,我們認(rèn)為中位數(shù)是衡量BERT平均表現(xiàn)的更好指標(biāo)。BERT(大)的非退化運(yùn)行的平均值為0.716±0.04。
為了研究BERT的決策,工作人員研究了數(shù)據(jù)點(diǎn),發(fā)現(xiàn)在多次運(yùn)行中很容易分類。對(duì)SemEval提交進(jìn)行了類似的分析,并且與他們的結(jié)果一致,發(fā)現(xiàn)BERT利用了warrant中提示詞的存在,特別是“not”。通過探索旨在隔離這些影響的實(shí)驗(yàn),研究人員在這項(xiàng)工作中證明了BERT在利用虛假統(tǒng)計(jì)線索方面的驚人之處。
但是,結(jié)果表明ARCT是可以消除主要問題的。由于R∧A→?C,我們可以添加每個(gè)數(shù)據(jù)點(diǎn)的副本,其中claim被否定并且標(biāo)簽被反轉(zhuǎn)。
這意味著warrant中統(tǒng)計(jì)線索的分布將反映在兩個(gè)標(biāo)簽上,從而消除了信號(hào)。在這種對(duì)抗性數(shù)據(jù)集上,所有模型都是隨機(jī)執(zhí)行的,BERT實(shí)現(xiàn)了53%的最大測(cè)試集精度。
因此,對(duì)抗性數(shù)據(jù)集提供了對(duì)參數(shù)理解的更可靠的評(píng)估,并且應(yīng)該被用作該數(shù)據(jù)集的未來工作的標(biāo)準(zhǔn)。
實(shí)驗(yàn)表明:BERT并不能做出正確“理解”,只能利用統(tǒng)計(jì)線索
如果一個(gè)模型正在利用標(biāo)簽上的分布線索,那么如果只訓(xùn)練warrant(W),它應(yīng)該表現(xiàn)得相對(duì)較好。
同樣的道理也適用于僅刪除claim、保留reason和warrant(R,W)或刪除reason(C,W)。
后一種設(shè)置允許模型額外考慮reason和claim中的線索,以及與warrant組合相關(guān)的線索。
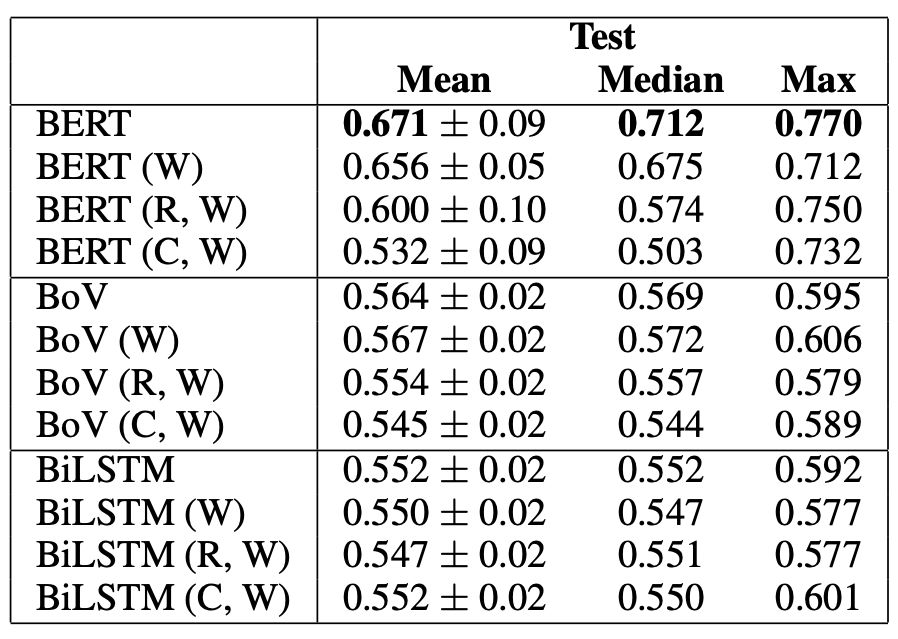
表3用BERT Large、BoV和BiLSTM作為基線探測(cè)實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)結(jié)果如表3所示。僅在warrant(W)上,BERT的準(zhǔn)確率最高可達(dá)71%。與其最高峰值的77%差了6個(gè)百分點(diǎn)。
而(R,W)比(W)增加了4個(gè)百分點(diǎn),(C,W)增加了2個(gè)百分點(diǎn),這就是剛才說到了那6個(gè)百分點(diǎn)。
基于這一證據(jù),研究人員發(fā)現(xiàn)BERT的全部表現(xiàn)可以通過利用虛假的統(tǒng)計(jì)線索來解釋。
對(duì)抗性測(cè)試集
由于數(shù)據(jù)集的原始設(shè)計(jì),消除了ARCT中標(biāo)簽統(tǒng)計(jì)線索的主要問題。
鑒于R∧A→?C,可以通過否定claim并反轉(zhuǎn)每個(gè)數(shù)據(jù)點(diǎn)的標(biāo)簽來產(chǎn)生對(duì)抗性示例(如圖4所示)。

圖4 原始和對(duì)抗數(shù)據(jù)點(diǎn)。claim被否定,warrant被交換。W和A的標(biāo)簽分配保持不變。
然后將對(duì)抗性示例與原始數(shù)據(jù)進(jìn)行組合。這通過鏡像兩個(gè)標(biāo)簽周圍的提示分布來消除該問題。
驗(yàn)證和測(cè)試集中大多數(shù)claim的否定已經(jīng)存在于數(shù)據(jù)集中的其他地方。剩下的claim被一個(gè)以英語為母語的工作人員人工進(jìn)行動(dòng)否定。
研究人員嘗試了兩種實(shí)驗(yàn)設(shè)置。
首先,在對(duì)抗集上評(píng)估在原始數(shù)據(jù)上訓(xùn)練和驗(yàn)證的模型。由于過度擬合原始訓(xùn)練集中的線索,所有結(jié)果都比隨機(jī)差。
其次,模型在對(duì)抗性訓(xùn)練和驗(yàn)證集上從頭開始訓(xùn)練,然后在對(duì)抗性測(cè)試集上進(jìn)行評(píng)估。其結(jié)果如表4所示。
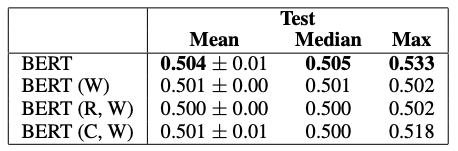
表4 BERT Large在具有對(duì)抗性訓(xùn)練和驗(yàn)證集的對(duì)抗性測(cè)試集上的結(jié)果。
BERT的峰值性能降低至53%,平均值和中值為50%。從這些結(jié)果中得出結(jié)論,對(duì)抗性數(shù)據(jù)集已成功地消除了預(yù)期的線索,從而提供了對(duì)機(jī)器參數(shù)理解的更可靠的評(píng)估。
這一結(jié)果更符合研究人員對(duì)這個(gè)任務(wù)的直覺:由于對(duì)這些論點(diǎn)背后的現(xiàn)實(shí)知之甚少或一無所知,良好的表現(xiàn)應(yīng)該是不可行的。
任務(wù)描述、基線、BERT與統(tǒng)計(jì)線索
任務(wù)描述和基線
設(shè)t i = 1, . . . ,n索引數(shù)據(jù)集D中的每個(gè)點(diǎn),其中| D | = n。在每種情況下,兩個(gè)候選warrant被隨機(jī)分配二進(jìn)制標(biāo)簽j ∈ {0, 1},使得每個(gè)具有相同的正確概率。輸入是c(i)的表示,reason r(i),保證零w0(i),并且保證一個(gè)w1(i)。標(biāo)簽y(i)是對(duì)應(yīng)于正確授權(quán)的二進(jìn)制指示符。所有模型的一般體系結(jié)構(gòu)如圖2所示。學(xué)習(xí)共享參數(shù)θ以獨(dú)立地使用參數(shù)對(duì)每個(gè)warrant進(jìn)行分類,得到 logit:
zj(i)=θ[c(i);r(i);wj(i)]
然后將它們連接起來并通過softmax以確定兩個(gè)warrant上的概率分布p(i)= softmax([z0(i),z1(i)])。那么預(yù)測(cè)是y(i)= arg maxjp(i)。基線是一包載體(BoV),雙向LSTM(BiLSTM),SemEval獲勝者GIST,Botschen等人的最佳模型,人類表現(xiàn)(表1)。對(duì)于我們的所有實(shí)驗(yàn),我們使用網(wǎng)格搜索來選擇超參數(shù),退出正則化和Adam進(jìn)行優(yōu)化。當(dāng)驗(yàn)證準(zhǔn)確度下降時(shí),我們將學(xué)習(xí)率anneal1/10。最終參數(shù)來自具有最大驗(yàn)證精度的epoch。BoV和BiLSTM輸入是在640B上訓(xùn)練的300維GloVe嵌入。GitHub上提供了重現(xiàn)所有實(shí)驗(yàn)和詳細(xì)說明所有超參數(shù)的代碼。(https://github.com/IKMLab/arct2)
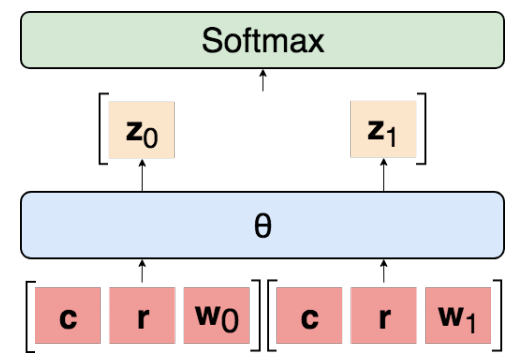
圖2:我們實(shí)驗(yàn)中模型的一般架構(gòu)。為每對(duì)argument-warrant獨(dú)立計(jì)算 logit,然后連接并通過softmax傳遞。
BERT
我們的BERT分類器如圖3所示。claim和reason連接在一起形成第一個(gè)文本段,與每個(gè)warrant配對(duì)并獨(dú)立處理。將最終層CLS向量傳遞到線性層以獲得對(duì)數(shù)zj(i)。整個(gè)架構(gòu)都經(jīng)過精心調(diào)整。學(xué)習(xí)率為2e-5,我們?cè)试S最多20個(gè)訓(xùn)練期,從最佳驗(yàn)證集準(zhǔn)確度的時(shí)期獲取參數(shù)。我們使用Hugging Face PyTorch實(shí)現(xiàn)。
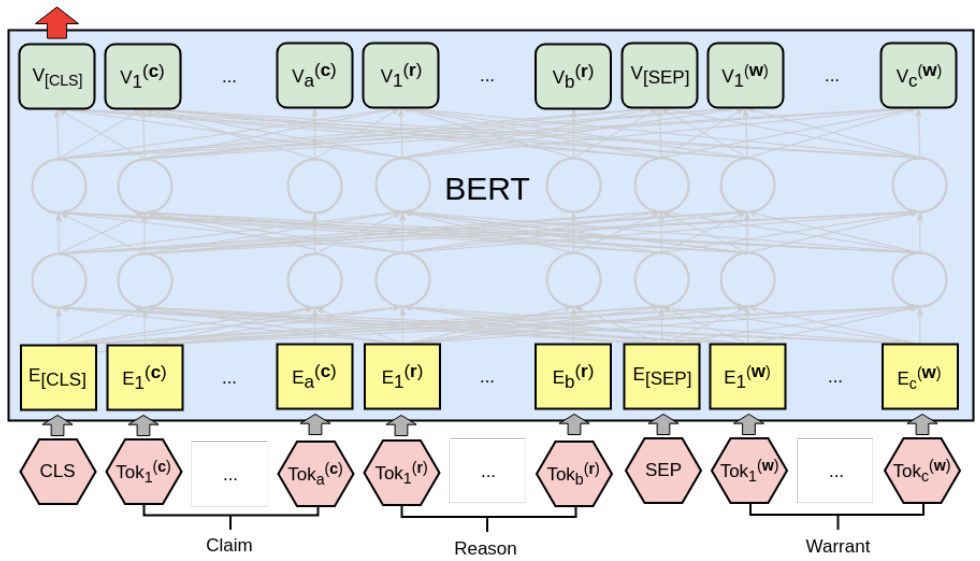
圖3:使用BERT處理參數(shù)一對(duì)argument-warrant。reason(長(zhǎng)度為a的單詞)和claim(長(zhǎng)度b)一起形構(gòu)成第一句話,而warrant(長(zhǎng)度c)是第二句。然后將最終的CLS矢量傳遞到線性層以計(jì)算 logit zj(i)。
Devlin et al.報(bào)告說,在小型數(shù)據(jù)集上,BERT有時(shí)無法訓(xùn)練,產(chǎn)生退化的結(jié)果。ARCT非常小,有1210次訓(xùn)練觀察。在5/20運(yùn)行中,我們遇到了這種現(xiàn)象,在驗(yàn)證和測(cè)試集上看到接近隨機(jī)精度。這些情況發(fā)生在訓(xùn)練準(zhǔn)確性也不明顯高于隨機(jī)(<80%)的情況下。除去退化曲線,BERT的平均值為71.6±0.04。這將超過先前的技術(shù)水平 - 中位數(shù)為71.2%,這是一個(gè)比整體平均值更好的平均值,因?yàn)樗皇芡嘶闆r的影響。但是,我們的主要發(fā)現(xiàn)是這些結(jié)果沒有意義,應(yīng)該被丟棄。在接下來的部分中,我們將重點(diǎn)放在BERT的77%峰值性能上。
統(tǒng)計(jì)線索
ARCT中虛假統(tǒng)計(jì)線索的主要來源是標(biāo)簽的不均勻分布。接下來便將展示這些線索的存在和性質(zhì)。
雖然可能存在更為復(fù)雜的線索,但是研究人員只考慮了一元圖和二元圖的情況。
研究人員的目標(biāo)是計(jì)算模型利用線索k的有益程度,以及它在數(shù)據(jù)集中的普遍程度(表示信號(hào)的強(qiáng)度)。
首先,定義幾個(gè)概念:
線索的適應(yīng)性(applicability):αk,定義為在一個(gè)標(biāo)簽上出現(xiàn)的數(shù)據(jù)點(diǎn)數(shù);
線索的生產(chǎn)率(productivity):πk,定義為預(yù)測(cè)正確答案的適用數(shù)據(jù)點(diǎn)的比例;
線索的覆蓋率(coverage):ξk,定義為適用情況占數(shù)據(jù)點(diǎn)總數(shù)的比例。
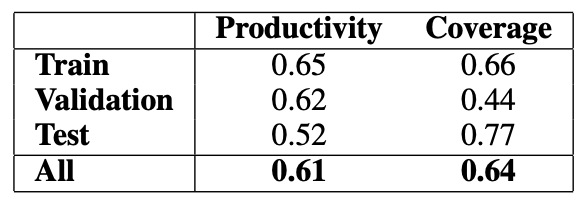
表2 適用“not”在warrant中的存在來預(yù)測(cè)ARCT中標(biāo)簽的生產(chǎn)率和覆蓋率。
表2給出了研究人員發(fā)現(xiàn)的最強(qiáng)的unigram線索(“not”)的生產(chǎn)率和覆蓋率。它提供了一個(gè)特別強(qiáng)的訓(xùn)練信號(hào)。雖然它在測(cè)試集中的效率較低,但它只是許多這樣的線索之一。
研究人員還發(fā)現(xiàn)了許多其他的unigram,盡管總體生產(chǎn)率較低,但大多數(shù)是高頻詞,如“is”、“do”和“are”。與“not”連用的bigram,如“will not”和“can”,也被發(fā)現(xiàn)是高效的。
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25283 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13608 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22492
原文標(biāo)題:臺(tái)灣小哥一篇論文把BERT拉下神壇!NLP神話缺了數(shù)據(jù)集還不如隨機(jī)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
揭秘:是什么造就了蘋果神話?
全面擁抱Transformer:NLP三大特征抽取器(CNNRNNTF)比較
NLP的介紹和如何利用機(jī)器學(xué)習(xí)進(jìn)行NLP以及三種NLP技術(shù)的詳細(xì)介紹

NLP-Progress庫NLP的最新數(shù)據(jù)集、論文和代碼
一位NLP算法工程師對(duì)NLP的看法
NLP 2019 Highlights 給NLP從業(yè)者的一個(gè)參考
NLP技術(shù)對(duì)BI而言有那么重要嗎?
知識(shí)圖譜是NLP的未來嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論