 電子發(fā)燒友App
電子發(fā)燒友App


2016年,一場(chǎng)風(fēng)風(fēng)火火的人機(jī)大戰(zhàn),谷歌旗下DeepMind的圍棋程序AlphaGo以5局4勝的大比分贏得勝利,掀起了全世界人民,尤其是中國(guó)老百姓,對(duì)于AI前所未有的熱潮,深度學(xué)習(xí)的概念也從實(shí)驗(yàn)室、教科書(shū)首次進(jìn)入了普通大眾的視野。不少人通過(guò)互聯(lián)網(wǎng),第一次了解到AI的魅力。但是,AI的應(yīng)用遠(yuǎn)不止互聯(lián)網(wǎng)企業(yè)這么簡(jiǎn)單,它已經(jīng)滲透到安防、公安ISV、研究機(jī)構(gòu)、金融、醫(yī)療等各行各業(yè)。
縱觀整個(gè)2017年,互聯(lián)網(wǎng)圈里提到最多的一個(gè)詞一定是“人工智能”,而且這個(gè)“人工智能”已經(jīng)不僅是2016年那個(gè)很會(huì)下棋的AlphaGo,它成了無(wú)所不能的助手管家,能和你對(duì)話(智能音響),能幫公安抓人(人臉識(shí)別),也開(kāi)始搶老司機(jī)的活兒(無(wú)人駕駛)。如今的人工智能早已不再是70多年前的那個(gè)“它”了。
中國(guó)制造2025——智能制造工程
中國(guó)制造2025戰(zhàn)略中,智能制造是一個(gè)非常關(guān)鍵的奮斗目標(biāo)。到2020年,制造業(yè)重點(diǎn)領(lǐng)域智能化水平顯著提升,試點(diǎn)示范項(xiàng)目運(yùn)營(yíng)成本降低30%,產(chǎn)品生產(chǎn)周期縮短30%,不良品率降低30%。到2025年,制造業(yè)重點(diǎn)領(lǐng)域全面實(shí)現(xiàn)智能化,試點(diǎn)示范項(xiàng)目運(yùn)營(yíng)成本降低50%,產(chǎn)品生產(chǎn)周期縮短50%,不良品率降低50%。
智能制造工程推動(dòng)制造業(yè)智能轉(zhuǎn)型,推進(jìn)產(chǎn)業(yè)邁向中高端;高端裝備創(chuàng)新工程以突破一批重大裝備的產(chǎn)業(yè)化應(yīng)用為重點(diǎn),為各行業(yè)升級(jí)提供先進(jìn)的生產(chǎn)工具。重點(diǎn)聚焦“五三五十”重點(diǎn)任務(wù),即:攻克五類(lèi)關(guān)鍵技術(shù)裝備,夯實(shí)智能制造三大基礎(chǔ),培育推廣五種智能制造新模式,推進(jìn)十大重點(diǎn)領(lǐng)域智能制造成套裝備集成應(yīng)用。
那么,如何加速智能制造的發(fā)展進(jìn)度?盡快實(shí)現(xiàn)廣泛的行業(yè)領(lǐng)域應(yīng)用呢?
容錯(cuò)服務(wù)器專(zhuān)家的觀點(diǎn)認(rèn)為,以邊緣計(jì)算引領(lǐng)人工智能的發(fā)展,將有力的推動(dòng)制造智能化進(jìn)程,并且讓人工智能更加“聰明”。
目前,受過(guò)訓(xùn)練的人工智能系統(tǒng),在特定領(lǐng)域的表現(xiàn)已可超越人類(lèi),而相關(guān)軟件技術(shù)迅速發(fā)展的背后,邊緣計(jì)算解決方法的運(yùn)用讓人工智能變得更加強(qiáng)大。物聯(lián)網(wǎng)(IoT)將可望進(jìn)化成AIoT(AI+IoT)。 智能機(jī)器人的遍地開(kāi)花可能還只是個(gè)開(kāi)端,人工智能終端的邊緣運(yùn)算能力,其所將帶來(lái)的價(jià)值更讓人引頸期盼。
容錯(cuò)邊緣計(jì)算團(tuán)隊(duì)認(rèn)為,基于邊緣計(jì)算解決方案的人工智能終端,將在各行各業(yè)帶來(lái)變革,從而改變未來(lái)的走向。傳統(tǒng)人工智能運(yùn)算的硬件架構(gòu),主要包括中央處理器(CPU)、圖型處理器(GPU)、現(xiàn)場(chǎng)可編程數(shù)組(FPGA)等。
特定領(lǐng)域的專(zhuān)用人工智能系統(tǒng),由于應(yīng)用背景需求明確、深厚之領(lǐng)域知識(shí)、模型建立計(jì)算簡(jiǎn)單可行,在單項(xiàng)測(cè)試之智能水平,目前已可超越人類(lèi)智能,在許多領(lǐng)域取得具體成效。如今的技術(shù)挑戰(zhàn)在于,如何發(fā)展低功耗、高準(zhǔn)確率的認(rèn)知計(jì)算,包括新型運(yùn)算架構(gòu)電路設(shè)計(jì)、算法等。 未來(lái)人工智能將由特定的算法加速器,來(lái)加速包括卷積神經(jīng)網(wǎng)絡(luò)(Convolution Neutral Network)、遞歸神經(jīng)網(wǎng)絡(luò)(Recursive Neutral Network)在內(nèi)的各種神經(jīng)網(wǎng)絡(luò)算法。邊緣計(jì)算推動(dòng)人工智能實(shí)現(xiàn)變革性發(fā)展,這是實(shí)現(xiàn)智能制造必須跨過(guò)的一步。
雖然目前人工智能領(lǐng)域的主流研究是在服務(wù)器上的人工智能運(yùn)算,但有越來(lái)越多應(yīng)用產(chǎn)品須在終端上進(jìn)行實(shí)時(shí)運(yùn)算,此種技術(shù)便是邊緣運(yùn)算的運(yùn)用。這個(gè)發(fā)展趨勢(shì)將改變整體人工智能運(yùn)算系統(tǒng)架構(gòu)的設(shè)計(jì)與技術(shù)需求。
容錯(cuò)專(zhuān)家認(rèn)為,人工智能在邊緣側(cè)的不斷擴(kuò)展,是駕馭數(shù)據(jù)洪流的關(guān)鍵環(huán)節(jié)之一,也是物聯(lián)網(wǎng)未來(lái)發(fā)展的重要趨勢(shì)。隨著人工智能如火如荼的發(fā)展,海量數(shù)據(jù)需要快速有效地分析和提取洞察,這也大大加強(qiáng)了對(duì)于邊緣計(jì)算的需求。
兩個(gè)問(wèn)題值得思考,首先是邊緣側(cè)趨向負(fù)載整合。以前的數(shù)據(jù)很多都是結(jié)構(gòu)化數(shù)據(jù),可以通過(guò)Excel表格或者簡(jiǎn)單的關(guān)系型數(shù)據(jù)庫(kù)對(duì)其進(jìn)行維護(hù)和管理。但今后會(huì)有越來(lái)越多的非結(jié)構(gòu)化數(shù)據(jù)需要進(jìn)行處理并借此發(fā)現(xiàn)內(nèi)在關(guān)聯(lián),這時(shí)就需要邊緣計(jì)算和人工智能技術(shù)。
其次,構(gòu)建邊緣協(xié)同的端到端系統(tǒng)。在一個(gè)邊緣協(xié)同的端到端系統(tǒng)中,由于不同網(wǎng)源的功耗、計(jì)算性能和所能承擔(dān)的成本各不相同,因此在選取硬件架構(gòu)時(shí)往往會(huì)有特定要求。要根據(jù)用戶需求提供不同架構(gòu)的解決方案,涵蓋至強(qiáng)處理器、至強(qiáng)融核處理器、Movidius/Nervana神經(jīng)網(wǎng)絡(luò)處理器和FPGA、網(wǎng)絡(luò)以及存儲(chǔ)技術(shù)等硬件平臺(tái),以及多種軟件工具及函數(shù)庫(kù),優(yōu)化開(kāi)源框架,來(lái)讓他們進(jìn)行自主選擇。
容錯(cuò)服務(wù)器及容錯(cuò)軟件,具有ftServer 的Lock Step和 everRun Check Point技術(shù), 在實(shí)時(shí)性,可靠性,安全私密性上有獨(dú)特的優(yōu)勢(shì),在已經(jīng)有廣泛的工業(yè)自動(dòng)化 (IA) 客戶應(yīng)用的基礎(chǔ)之上, 助力邊緣計(jì)算產(chǎn)業(yè)創(chuàng)新技術(shù)的落地。
容錯(cuò)服務(wù)器,在中國(guó)制造2025的奮斗目標(biāo)下,協(xié)助邊緣計(jì)算產(chǎn)業(yè)聯(lián)盟建立開(kāi)放與創(chuàng)新的平臺(tái)、行業(yè)踐行與示范的平臺(tái)。攜手人工智能技術(shù),加速中國(guó)制造2025實(shí)現(xiàn)進(jìn)程。
如何搭建一套高效的AI計(jì)算平臺(tái)?
早在1950年,圖靈在論文中探討了機(jī)器智能的問(wèn)題,并提出了著名的圖靈測(cè)試,1956年達(dá)特茅斯的討論會(huì)上,人工智能這一概念由此誕生。幾十年中,人工智能曾大起大落,原因?yàn)楹危?/p>
“數(shù)據(jù)”先背一個(gè)鍋,最早的人工智能也可以稱(chēng)之為專(zhuān)家系統(tǒng),也就是把專(zhuān)家們的所有理論、方法全都錄入到計(jì)算機(jī),在具體執(zhí)行任務(wù)的時(shí)候,計(jì)算機(jī)會(huì)檢索數(shù)據(jù)庫(kù)中相似的內(nèi)容,如果沒(méi)有,那么它就無(wú)能為力了。
然后是算法,類(lèi)似于數(shù)據(jù)庫(kù)檢索的算法可能只能稱(chēng)之為一個(gè)笨辦法,但20世紀(jì)90年代,神經(jīng)網(wǎng)絡(luò)的概念就成為熱點(diǎn),人工智能卻沒(méi)有取得長(zhǎng)足的進(jìn)展。這是因?yàn)槭芟抻诹硪粋€(gè)重要因素-計(jì)算。由于硬件計(jì)算平臺(tái)的限制,十余年間的進(jìn)展極其緩慢,直到以GPU為核心的協(xié)處理加速設(shè)備的應(yīng)用,人工智能應(yīng)用效率才得以大大提升。
近年來(lái),眾多企業(yè)都已經(jīng)看到了AI未來(lái)的前景,想紛紛踏入這篇沃土,孕育新的商機(jī)。想要跨進(jìn)這個(gè)新領(lǐng)域,首先要做的,是要擁有一套好的AI架構(gòu)。那么如何打造最優(yōu)的AI計(jì)算平臺(tái)?怎樣的AI計(jì)算硬件架構(gòu)更高效?AI 更注重哪些性能指標(biāo)?
要把AI練好要分三步,即“數(shù)據(jù)預(yù)處理——模型訓(xùn)練——識(shí)別推理”。三個(gè)過(guò)程分別對(duì)應(yīng)不同的計(jì)算特點(diǎn):數(shù)據(jù)預(yù)處理,對(duì)IO要求較高;模型訓(xùn)練的并行計(jì)算量很大,且通信也相對(duì)密集;推理識(shí)別則需要較高的吞吐處理能力和對(duì)單個(gè)樣本低延時(shí)的響應(yīng)。
當(dāng)我們知道了AI計(jì)算的特性之后,我們通過(guò)實(shí)測(cè)數(shù)據(jù)來(lái)看看人工智能計(jì)算對(duì)于服務(wù)器的硬件性能訴求有什么樣的特點(diǎn):
CPU和GPU誰(shuí)是AI計(jì)算的主力軍?
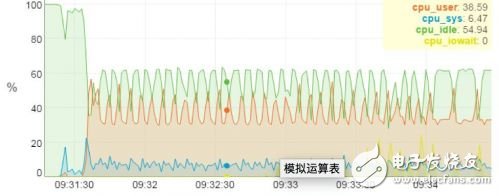

▼ CPU和GPU負(fù)載實(shí)測(cè)數(shù)據(jù)▼
上圖是一個(gè)搭載4塊GPU卡服務(wù)器上運(yùn)行Alexnet神經(jīng)網(wǎng)絡(luò)的測(cè)試分析圖,從圖上我們可以很清楚的看到計(jì)算的任務(wù)主要由GPU承擔(dān),4塊GPU卡的負(fù)載基本上都接近10%,而CPU的負(fù)載率只有不到40%。由此可見(jiàn), AI計(jì)算的計(jì)算量主要都在GPU加速卡上。
內(nèi)存和顯存,越大越好嗎?
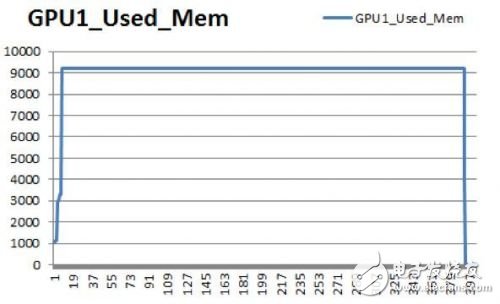

▼ 內(nèi)存和顯存負(fù)載實(shí)測(cè)數(shù)據(jù)▼
同樣的測(cè)試環(huán)境,內(nèi)存容量固定時(shí),總?cè)萘啃枨箅SBatch size擴(kuò)大而增加,Alexnet模型,Batch size為256時(shí),占用CPU內(nèi)存60GB,GPU顯存9GB。
這樣看,AI計(jì)算對(duì)于CPU內(nèi)存和GPU顯存容量的需求都很大。
磁盤(pán)IO,在模型訓(xùn)練過(guò)程中要求并不太高

▼ 磁盤(pán)IO實(shí)測(cè)數(shù)據(jù)▼
通過(guò)上圖我們可以看到,磁盤(pán)IO是一次讀,多次寫(xiě),在Alexnet模型下,磁盤(pán)讀帶寬85MB/s,寫(xiě)帶寬0.5MB/s。所以, 在模型訓(xùn)練階段,磁盤(pán)的IO并不是AI計(jì)算的瓶頸點(diǎn)。
PCIE帶寬,“路”越寬越不堵
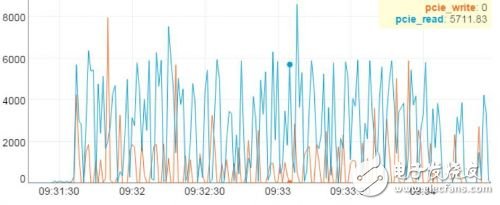
▼ PCIE帶寬負(fù)載實(shí)測(cè)數(shù)據(jù)▼
最后,我們?cè)倏纯碅I計(jì)算對(duì)于PCIE帶寬的占用情況。圖上顯示,帶寬與訓(xùn)練數(shù)據(jù)規(guī)模成正比。測(cè)試中,PCIE持續(xù)讀帶寬達(dá)到5.7GB/s,峰值帶寬超過(guò)8GB/s,因此PCIE的帶寬將是AI計(jì)算的關(guān)鍵瓶頸點(diǎn)。
于是,我們可以得出幾個(gè)結(jié)論:
1. 數(shù)據(jù)預(yù)處理階段需要提高小文件的隨機(jī)讀寫(xiě)性能
2. 模型訓(xùn)練階段需要提升并行計(jì)算能力
3. 線上推理階段需要提升批量模型推理的吞吐效率
用高計(jì)算性能的CPU服務(wù)器+高性能存儲(chǔ),解決小文件隨機(jī)讀取難題
數(shù)據(jù)預(yù)處理的主要任務(wù)是處理缺失值,光滑噪聲數(shù)據(jù),識(shí)別或刪除利群點(diǎn),解決數(shù)據(jù)的不一致性。這些任務(wù)可以利用基于CPU服務(wù)器來(lái)實(shí)現(xiàn),比如浪潮SA5212M5這種最新型2U服務(wù)器,搭載最新一代英特爾至強(qiáng)可擴(kuò)展處理器,支持Intel Skylake平臺(tái)3/4/5/6/8全系處理器,支持全新的微處理架構(gòu),AVX512指令集可提供上一代2倍的FLOPs/core,多達(dá)28個(gè)內(nèi)核及56線程,計(jì)算性能可達(dá)到上一代的1.3倍,能夠快速實(shí)現(xiàn)數(shù)據(jù)的預(yù)處理任務(wù)。
在存儲(chǔ)方面,可以采用HDFS(Hadoop分布式文件系統(tǒng))存儲(chǔ)架構(gòu)來(lái)設(shè)計(jì)。HDFS是使用Java實(shí)現(xiàn)分布式的、可橫向擴(kuò)展的文件系統(tǒng),因?yàn)樯疃葘W(xué)習(xí)天生用于處理大數(shù)據(jù)任務(wù),很多場(chǎng)景下,深度學(xué)習(xí)框架需要對(duì)接HDFS。通過(guò)浪潮SA5224M4服務(wù)器組成高效、可擴(kuò)展的存儲(chǔ)集群,在滿足AI計(jì)算分布式存儲(chǔ)應(yīng)用的基礎(chǔ)上,最大可能降低整個(gè)系統(tǒng)的TCO。
▼ 浪潮SA5224M4 4U36盤(pán)位存儲(chǔ)服務(wù)器 ▼
SA5224M4一款4U36盤(pán)位的存儲(chǔ)型服務(wù)器,在4U的空間內(nèi)支持36塊大容量硬盤(pán)。并且相比傳統(tǒng)的雙路E5存儲(chǔ)服務(wù)器,功耗降低35W以上。同時(shí),通過(guò)背板Expander芯片的帶寬加速技術(shù),顯著提升大容量SATA盤(pán)的性能表現(xiàn),更適合構(gòu)建AI所需要的HDFS存儲(chǔ)系統(tǒng)。
用GPU服務(wù)器實(shí)現(xiàn)更快速、精準(zhǔn)的AI模型訓(xùn)練
從內(nèi)部結(jié)構(gòu)上來(lái)看,CPU中70%晶體管都是用來(lái)構(gòu)建Cache(高速緩沖存儲(chǔ)器)和一部分控制單元,負(fù)責(zé)邏輯運(yùn)算的部分并不多,控制單元等模塊的存在都是為了保證指令能夠一條接一條的有序執(zhí)行,這種通用性結(jié)構(gòu)對(duì)于傳統(tǒng)的編程計(jì)算模式非常適合,但對(duì)于并不需要太多的程序指令,卻需要海量數(shù)據(jù)運(yùn)算的深度學(xué)習(xí)計(jì)算需求,這種結(jié)構(gòu)就顯得有心無(wú)力了。
與 CPU 少量的邏輯運(yùn)算單元相比,GPU設(shè)備整個(gè)就是一個(gè)龐大的計(jì)算矩陣,動(dòng)輒具有數(shù)以千計(jì)的計(jì)算核心、可實(shí)現(xiàn) 10-100 倍應(yīng)用吞吐量,而且它還支持對(duì)深度學(xué)習(xí)至關(guān)重要的并行計(jì)算能力,可以比傳統(tǒng)處理器更加快速,大大加快了訓(xùn)練過(guò)程。
根據(jù)不同規(guī)模的AI模型訓(xùn)練場(chǎng)景,可能會(huì)用到2卡、4卡、8卡甚至到64卡以上的AI計(jì)算集群。在AI計(jì)算服務(wù)器方面,浪潮也擁有業(yè)界最全的產(chǎn)品陣列。既擁有NF5280M5、AGX-2、NF6248等傳統(tǒng)的GPU/KNL服務(wù)器以及FPGA卡等,也包含了創(chuàng)新的GX4、SR-AI整機(jī)柜服務(wù)器等獨(dú)立加速計(jì)算模塊。

浪潮AI計(jì)算服務(wù)器陣列
其中,SR-AI整機(jī)柜服務(wù)器面向超大規(guī)模線下模型訓(xùn)練,能夠?qū)崿F(xiàn)單節(jié)點(diǎn)16卡、單物理集群64卡的超高密擴(kuò)展能力;GX4是能夠覆蓋全AI應(yīng)用場(chǎng)景的創(chuàng)新架構(gòu)產(chǎn)品,可以通過(guò)標(biāo)準(zhǔn)機(jī)架服務(wù)器連接協(xié)處理器計(jì)算擴(kuò)展模塊的形式完成計(jì)算性能擴(kuò)展,滿足AI云、深度學(xué)習(xí)模型訓(xùn)練和線上推理等各種AI應(yīng)用場(chǎng)景對(duì)計(jì)算架構(gòu)性能、功耗的不同需求;AGX-2是2U8 NVLinkGPU全球密度最高、性能最強(qiáng)的AI平臺(tái),面向需要更高空間密度比AI算法和應(yīng)用服務(wù)商。
根據(jù)業(yè)務(wù)應(yīng)用的需要,選擇不同規(guī)模的GPU服務(wù)器集群,從而平衡計(jì)算能力和成本,達(dá)到最優(yōu)的TCO和最佳的計(jì)算效率。
用FPGA來(lái)實(shí)現(xiàn)更低延遲、更高吞吐量的線上推理
GPU在深度學(xué)習(xí)算法模型訓(xùn)練上非常高效,但在推理時(shí)一次性只能對(duì)于一個(gè)輸入項(xiàng)進(jìn)行處理,并行計(jì)算的優(yōu)勢(shì)不能發(fā)揮出來(lái)。而FPGA正是強(qiáng)在推斷。大幅提升推斷效率的同時(shí),還要最小限度損失精確性,這正是FPGA的強(qiáng)項(xiàng)。
▼ 業(yè)界支持OpenCL的最高密度最高性能的FPGA-浪潮F10A▼
以浪潮F10A為例,這是目前業(yè)界支持OpenCL的最高密度最高性能的FPGA加速設(shè)備,單芯片峰值運(yùn)算能力達(dá)到了1.5TFlops,功耗卻只需35W,每瓦特性能到42GFlops。
測(cè)試數(shù)據(jù)顯示,在語(yǔ)音識(shí)別應(yīng)用下,浪潮F10A較CPU性能加速2.87倍,而功耗相當(dāng)于CPU的15.7%,性能功耗比提升18倍。在圖片識(shí)別分類(lèi)應(yīng)用上,相比GPU能夠提升10倍以上。
通過(guò)CPU、GPU、FPGA等不同計(jì)算設(shè)備的組合,充分發(fā)揮各自在不同方向的優(yōu)勢(shì),才能夠形成一套高效的AI計(jì)算平臺(tái)。然后選擇一個(gè)合適的框架,運(yùn)用最優(yōu)的算法,就能夠?qū)崿F(xiàn)人工智能應(yīng)用的快速落地和精準(zhǔn)服務(wù)。









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論