 電子發(fā)燒友App
電子發(fā)燒友App


訓(xùn)練專項(xiàng)網(wǎng)絡(luò)
還記得我們?cè)陂_始時(shí)丟棄的70%的培訓(xùn)數(shù)據(jù)嗎?結(jié)果表明,如果我們想在Kaggle排行榜上獲得一個(gè)有競(jìng)爭(zhēng)力的得分,這是一個(gè)很糟糕的主意。在70%的數(shù)據(jù)和挑戰(zhàn)的測(cè)試集中,我們的模型還有相當(dāng)多特征沒有看到。
因此,改變之前只訓(xùn)練單個(gè)模型的方式,讓我們訓(xùn)練幾個(gè)專項(xiàng)網(wǎng)絡(luò),每個(gè)專項(xiàng)網(wǎng)絡(luò)預(yù)測(cè)一組不同的目標(biāo)值。我們將訓(xùn)練一個(gè)只預(yù)測(cè)left_eye_center和right_eye_center的模型,一個(gè)僅用于nose_tip等等;總的來說,我們將有六個(gè)模型。這將允許我們使用完整的訓(xùn)練數(shù)據(jù)集,并希望獲得整體更有競(jìng)爭(zhēng)力的分?jǐn)?shù)。
六個(gè)專項(xiàng)網(wǎng)絡(luò)都將使用完全相同的網(wǎng)絡(luò)架構(gòu)(一種簡(jiǎn)單的方法,不一定是最好的)。因?yàn)橛?xùn)練必須比以前花費(fèi)更長的時(shí)間,所以讓我們考慮一個(gè)策略,以便我們不必等待max_epochs完成,即使驗(yàn)證錯(cuò)誤停止提高很多。這被稱為早期停止,我們將寫另一個(gè)on_epoch_finished回調(diào)來處理。這里的實(shí)現(xiàn):
class EarlyStopping(object):
def __init__(self, patience=100):
self.patience = patience
self.best_valid = np.inf
self.best_valid_epoch = 0
self.best_weights = None
def __call__(self, nn, train_history):
current_valid = train_history[-1]['valid_loss']
current_epoch = train_history[-1]['epoch']
if current_valid < self.best_valid:
self.best_valid = current_valid
self.best_valid_epoch = current_epoch
self.best_weights = nn.get_all_params_values()
elif self.best_valid_epoch + self.patience < current_epoch:
print("Early stopping.")
print("Best valid loss was {:.6f} at epoch {}.".format(
self.best_valid, self.best_valid_epoch))
nn.load_params_from(self.best_weights)
raise StopIteration()
可以看到,在call函數(shù)里面有兩個(gè)分支:第一個(gè)是現(xiàn)在的驗(yàn)證錯(cuò)誤比我們之前看到的要好,第二個(gè)是最好的驗(yàn)證錯(cuò)誤所在的迭代次數(shù)和當(dāng)前迭代次數(shù)的距離已經(jīng)超過了我們的耐心。在第一個(gè)分支里,我們存下網(wǎng)絡(luò)的權(quán)重:
self.best_weights = nn.get_all_params_values()
第二個(gè)分支里,我們將網(wǎng)絡(luò)的權(quán)重設(shè)置成最優(yōu)的驗(yàn)證錯(cuò)誤時(shí)存下的值,然后發(fā)出一個(gè)StopIteration,告訴NeuralNet我們想要停止訓(xùn)練。
nn.load_params_from(self.best_weights)
raise StopIteration()
讓我們?cè)趎et的定義中更新on_epoch_finished處理程序的列表,并添加EarlyStopping:
net8 = NeuralNet(
# ...
on_epoch_finished=[
AdjustVariable('update_learning_rate', start=0.03, stop=0.0001),
AdjustVariable('update_momentum', start=0.9, stop=0.999),
EarlyStopping(patience=200),
],
# ...
)
到目前為止一切順利,但是如何定義這些專項(xiàng)網(wǎng)絡(luò)進(jìn)行相應(yīng)的預(yù)測(cè)呢?讓我們做一個(gè)列表:
SPECIALIST_SETTINGS = [
dict(
columns=(
'left_eye_center_x', 'left_eye_center_y',
'right_eye_center_x', 'right_eye_center_y',
),
flip_indices=((0, 2), (1, 3)),
),
dict(
columns=(
'nose_tip_x', 'nose_tip_y',
),
flip_indices=(),
),
dict(
columns=(
'mouth_left_corner_x', 'mouth_left_corner_y',
'mouth_right_corner_x', 'mouth_right_corner_y',
'mouth_center_top_lip_x', 'mouth_center_top_lip_y',
),
flip_indices=((0, 2), (1, 3)),
),
dict(
columns=(
'mouth_center_bottom_lip_x',
'mouth_center_bottom_lip_y',
),
flip_indices=(),
),
dict(
columns=(
'left_eye_inner_corner_x', 'left_eye_inner_corner_y',
'right_eye_inner_corner_x', 'right_eye_inner_corner_y',
'left_eye_outer_corner_x', 'left_eye_outer_corner_y',
'right_eye_outer_corner_x', 'right_eye_outer_corner_y',
),
flip_indices=((0, 2), (1, 3), (4, 6), (5, 7)),
),
dict(
columns=(
'left_eyebrow_inner_end_x', 'left_eyebrow_inner_end_y',
'right_eyebrow_inner_end_x', 'right_eyebrow_inner_end_y',
'left_eyebrow_outer_end_x', 'left_eyebrow_outer_end_y',
'right_eyebrow_outer_end_x', 'right_eyebrow_outer_end_y',
),
flip_indices=((0, 2), (1, 3), (4, 6), (5, 7)),
),
]
我們很早前就討論過在數(shù)據(jù)擴(kuò)充中flip_indices的重要性。在數(shù)據(jù)介紹部分,我們的load_data()函數(shù)也接受一個(gè)可選參數(shù),來抽取某些列。我們將在用專項(xiàng)網(wǎng)絡(luò)預(yù)測(cè)結(jié)果的fit_specialists()中使用這些特性:
from collections import OrderedDict
from sklearn.base import clone
def fit_specialists():
specialists = OrderedDict()
for setting in SPECIALIST_SETTINGS:
cols = setting['columns']
X, y = load2d(cols=cols)
model = clone(net)
model.output_num_units = y.shape[1]
model.batch_iterator_train.flip_indices = setting['flip_indices']
# set number of epochs relative to number of training examples:
model.max_epochs = int(1e7 / y.shape[0])
if 'kwargs' in setting:
# an option 'kwargs' in the settings list may be used to
# set any other parameter of the net:
vars(model).update(setting['kwargs'])
print("Training model for columns {} for {} epochs".format(
cols, model.max_epochs))
model.fit(X, y)
specialists[cols] = model
with open('net-specialists.pickle', 'wb') as f:
# we persist a dictionary with all models:
pickle.dump(specialists, f, -1)
沒有什么值得大驚小怪的事情,只不過是訓(xùn)練了一系列模型,并存進(jìn)了字典。盡管有early stopping 但是在單塊GPU上訓(xùn)練仍然要花上半天時(shí)間,而且我也不建議你運(yùn)行這個(gè)。
在多塊GPU上跑當(dāng)然會(huì)快,但是還是太奢侈了。下一節(jié)介紹一種可以減少訓(xùn)練時(shí)間的方法,在這里,我們先看一下這些花費(fèi)了大量資源的模型的結(jié)果。
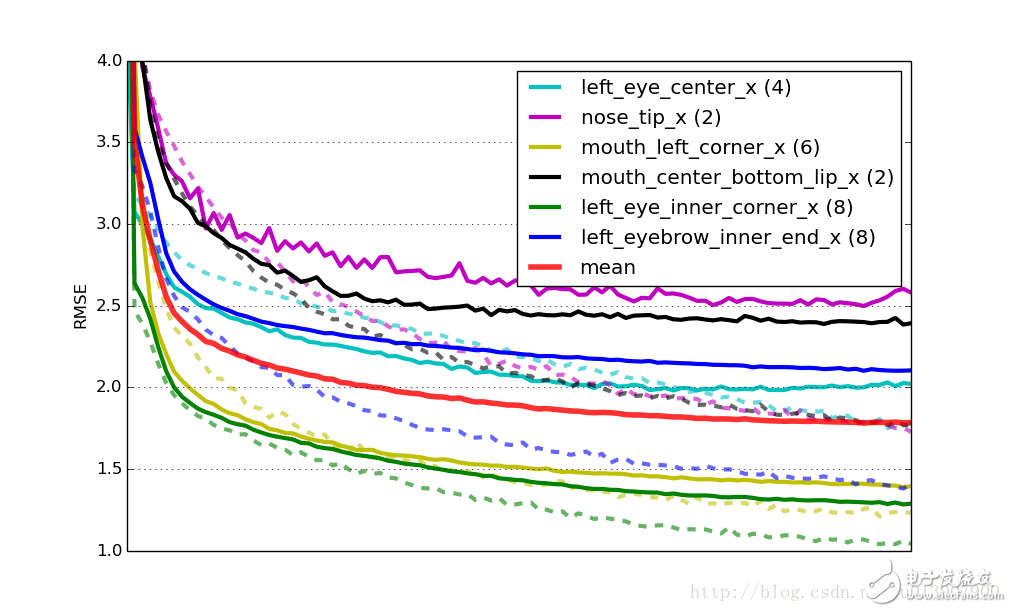
6個(gè)模型的學(xué)習(xí)率,實(shí)線代表驗(yàn)證集合上的RMSE(均方根誤差),虛線是訓(xùn)練集誤差。Mean代表 所有模型乘以權(quán)重(模型所擁有的目標(biāo)數(shù)量)的平均驗(yàn)證誤差。所有的曲線都在x軸縮放到同樣的尺度。
有監(jiān)督的前訓(xùn)練
教程的最后一部分,討論一種新的方式讓專項(xiàng)網(wǎng)絡(luò)訓(xùn)練的更快。思路是:用net6或者是net7訓(xùn)練好的權(quán)重替代隨即值來初始化網(wǎng)絡(luò)權(quán)重。如果你還記得early stopping的實(shí)現(xiàn)的話,從一個(gè)網(wǎng)絡(luò)復(fù)制權(quán)重到另一個(gè)網(wǎng)絡(luò)是非常簡(jiǎn)單的,只要使用load_params_form()方法。下面我們改變fit_specialists方法來實(shí)現(xiàn)上述功能。仍然是加了#!的行是新添加的行:
def fit_specialists(fname_pretrain=None):
if fname_pretrain: # !
with open(fname_pretrain, 'rb') as f: # !
net_pretrain = pickle.load(f) # !
else: # !
net_pretrain = None # !
specialists = OrderedDict()
for setting in SPECIALIST_SETTINGS:
cols = setting['columns']
X, y = load2d(cols=cols)
model = clone(net)
model.output_num_units = y.shape[1]
model.batch_iterator_train.flip_indices = setting['flip_indices']
model.max_epochs = int(4e6 / y.shape[0])
if 'kwargs' in setting:
# an option 'kwargs' in the settings list may be used to
# set any other parameter of the net:
vars(model).update(setting['kwargs'])
if net_pretrain is not None: # !
# if a pretrain model was given, use it to initialize the
# weights of our new specialist model:
model.load_params_from(net_pretrain) # !
print("Training model for columns {} for {} epochs".format(
cols, model.max_epochs))
model.fit(X, y)
specialists[cols] = model
with open('net-specialists.pickle', 'wb') as f:
# this time we're persisting a dictionary with all models:
pickle.dump(specialists, f, -1)
事實(shí)證明復(fù)用訓(xùn)練好的網(wǎng)絡(luò)的權(quán)重代替隨機(jī)初始化有兩個(gè)實(shí)際上的好處:一個(gè)是訓(xùn)練收斂的更快,在這里大概有四倍快;第二個(gè)優(yōu)點(diǎn)是網(wǎng)絡(luò)的泛化能力更強(qiáng),前訓(xùn)練起到了正則化項(xiàng)的效果。還是和剛剛一樣的學(xué)習(xí)曲線圖,展示了采用了前訓(xùn)練的網(wǎng)絡(luò):
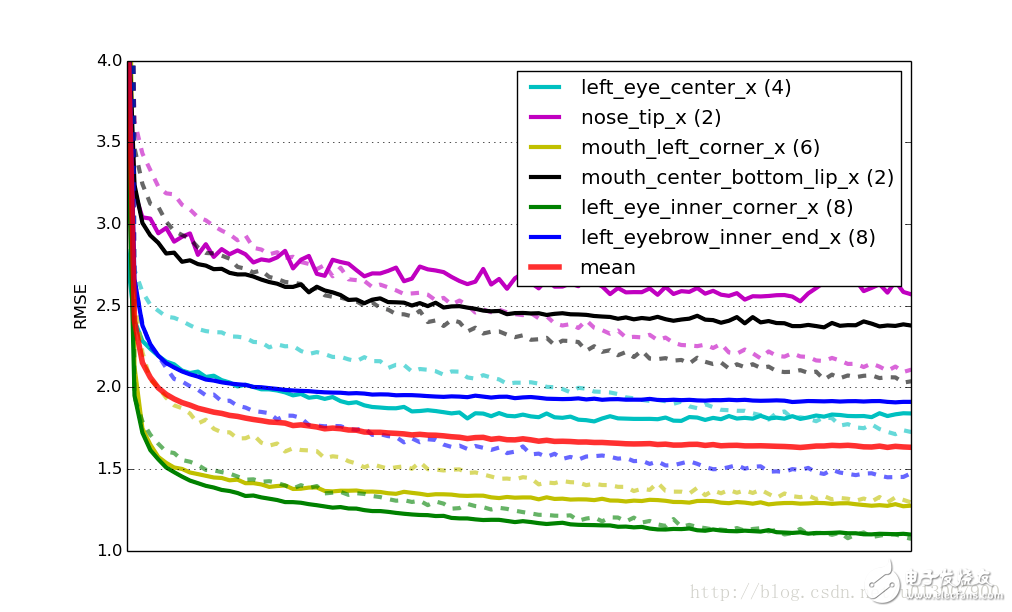
最終,這個(gè)解決方案在排行榜上的成績是2.13 RMSE。
結(jié)論
現(xiàn)在也許你已經(jīng)有了一打想法想去嘗試,你可以找到教程最終方案的源代碼,開始你的嘗試。代碼中還包括生成提交文件,運(yùn)行Python?kfkd.py找出如何在命令行使用這個(gè)腳本。
還有一大堆很明顯的你可以做的改進(jìn):嘗試將每一個(gè)專項(xiàng)網(wǎng)絡(luò)進(jìn)行優(yōu)化;觀察6個(gè)網(wǎng)絡(luò),可以發(fā)現(xiàn)素有的模型都存在不同程度的過擬合。如果模型像綠色或者黃色的曲線那樣幾乎沒有任何過擬合呢,你可以嘗試減少dropout的數(shù)量;要是過擬合的厲害,就增加dropout的數(shù)量。
在SPECIALIST_SETTINGS的定義中,我們能夠添加針對(duì)某個(gè)特定網(wǎng)絡(luò)的設(shè)置。如果說我們想要給第二個(gè)網(wǎng)絡(luò)添加更多的正則化項(xiàng),我們可以像下面這樣改變:
dict(
columns=(
'nose_tip_x', 'nose_tip_y',
),
flip_indices=(),
kwargs=dict(dropout2_p=0.3, dropout3_p=0.4), # !
),
還有各種各樣的可以嘗試改進(jìn)的地方,也許你可以再加一個(gè)卷積層或者全連接層?期待你的好消息。












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論