 電子發燒友App
電子發燒友App


作為技術專業人士,我們已經意識到我們的世界越來越由數據驅動。在金融市場領域尤其如此,算法交易已成為常態,利用復雜的算法以遠遠超過人類能力的速度和頻率執行交易。在這個毫秒可能意味著損益差異的世界中,算法交易通過使交易更加系統化且不受人類情感偏見的影響來提供優勢。
但是,如果我們能更進一步呢?如果我們的交易算法能夠從錯誤中吸取教訓,適應新的市場條件,并隨著時間的推移不斷提高他們的表現,那會怎樣?這就是人工智能前沿領域的強化學習發揮作用的地方。
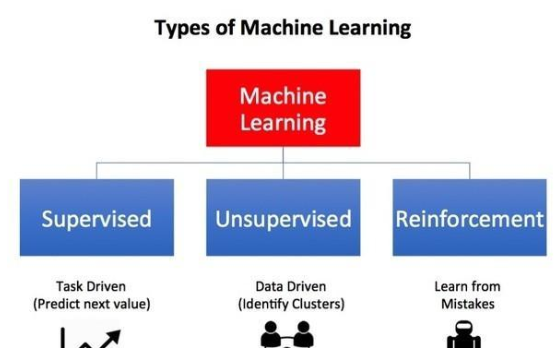
強化學習 (RL) 是機器學習的一個領域,專注于做出決策。它是關于從與環境的交互中學習以實現目標,通常被表述為一種游戲,RL 代理在其中學習采取行動以最大化其總獎勵。這項技術現在正應用于各種問題,從自動駕駛汽車到計算機網絡中的資源分配。
但強化學習的潛力在算法交易領域仍未得到開發。這是令人驚訝的,因為交易本質上是一個順序決策問題,而這正是強化學習旨在處理的問題。
在本文中,我們將深入研究強化學習如何增強算法交易,探索所涉及的挑戰,并討論人工智能和金融這個令人興奮的交叉點的未來。無論您是有興趣將您的技能應用于金融市場的數據科學家,還是對強化學習的實際應用感到好奇的技術愛好者,本文都能為您提供一些東西。
了解算法交易
算法交易,也稱為算法交易或黑盒交易,利用復雜的公式和高速的計算機編程指令,以最少的人為干預在金融市場中執行大額訂單。這種做法徹底改變了金融業,并在當今的數字時代變得越來越普遍。
算法交易的核心是使交易過程更加系統和高效。它涉及使用復雜的數學模型來快速決定何時、如何交易以及交易什么。這種高速和大批量執行交易的能力提供了顯著的優勢,包括降低手動錯誤的風險,提高訂單執行速度,以及根據歷史數據回測交易策略的能力。
此外,算法交易可以實現人類無法手動執行的復雜策略。這些策略的范圍可以從統計套利(利用價格的統計模式)到均值回歸(利用價格偏離長期平均值)。
算法交易的一個重要方面是它消除了交易過程中的情感人為影響。決策是根據預先設定的規則和模型做出的,消除了人為偏見或情緒干擾交易決策的可能性。這可以帶來更一致和可預測的交易結果。
然而,盡管算法交易功能強大,但它并非沒有挑戰。主要困難之一在于開發有效的交易算法。這些算法必須足夠強大,以應對廣泛的市場條件,并且足夠靈活以適應不斷變化的市場動態。他們還需要能夠有效地管理風險,隨著交易速度和交易量的增加,這項任務變得越來越具有挑戰性。
這就是強化學習可以發揮關鍵作用的地方。憑借其從經驗中學習并隨著時間的推移調整其策略的能力,強化學習為傳統算法交易策略面臨的挑戰提供了一個有前途的解決方案。在下一節中,我們將更深入地探討強化學習的原理以及如何將它們應用于算法交易。
強化學習的基礎知識
強化學習(RL)是人工智能的一個子領域,專注于決策過程。與其他形式的機器學習相比,強化學習模型通過與環境交互并以獎勵或懲罰的形式接收反饋來學習。
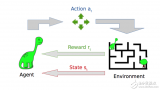
強化學習系統的基本組成部分是代理、環境、狀態、行動和獎勵。代理是決策者,環境是代理與之交互的內容,狀態是代理發現自己所處的情況,操作是代理可以做的事情,獎勵是代理在采取行動后獲得的反饋。
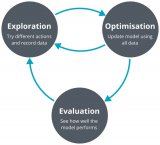
強化學習的一個關鍵概念是探索與開發的概念。智能體需要在探索環境以發現新信息和利用已有的知識以最大化回報之間取得平衡。這稱為勘探-開發權衡。
強化學習的另一個重要方面是策略的概念。策略是代理在決定來自特定狀態的操作時遵循的策略。強化學習的目標是找到最佳策略,隨著時間的推移最大化預期的累積獎勵。
強化學習已成功應用于各個領域,從游戲(如著名的AlphaGo)到機器人技術(用于教機器人新任務)。它的力量在于它能夠從反復試驗中學習并隨著時間的推移提高其性能。
在算法交易的背景下,金融市場可以被視為環境,交易算法作為代理,市場條件作為狀態,交易決策(買入、賣出、持有)作為行動,交易的盈虧作為獎勵。
將強化學習應用于算法交易意味著開發能夠根據市場反饋學習和調整其交易策略的交易算法,目的是最大化累積利潤。然而,在交易中實施強化學習有其獨特的挑戰,我們將在以下部分中探討。
算法交易和強化學習的交集
算法交易和強化學習的交集代表了金融科技領域令人興奮的前沿。其核心是創建交易算法,可以從過去的交易中學習,并隨著時間的推移迭代改進他們的交易策略。
在算法交易的典型強化學習設置中,代理(交易算法)通過基于當前市場條件(狀態)執行交易(動作)與環境(金融市場)交互。這些交易的結果,就利潤或虧損而言,作為獎勵或懲罰,指導算法調整其策略。
在這種情況下,強化學習的關鍵優勢之一是它能夠適應不斷變化的市場條件。金融市場是出了名的復雜和動態,價格受到從經濟指標到地緣政治事件等多種因素的影響。與靜態算法相比,可以實時學習和適應的交易算法具有顯著優勢。
例如,考慮突然的市場低迷。靜態交易算法可能會繼續根據其預編程策略執行交易,這可能會導致重大損失。相比之下,基于強化學習的算法可以識別市場條件的變化并相應地調整其策略,從而可能減少損失,甚至利用低迷進行有利可圖的交易。
強化學習在交易中的另一個優勢是它能夠處理高維數據并根據復雜的非線性關系做出決策。這在當今的金融市場中尤其重要,交易者可以訪問從價格歷史到社交媒體情緒的大量數據。
例如,可以訓練強化學習算法,不僅要考慮歷史價格數據,還要考慮交易量、波動性甚至新聞文章或推文等其他因素,以做出更明智的交易決策。
在算法交易中實現強化學習的挑戰和解決方案
雖然在算法交易中使用強化學習的潛在好處是顯著的,但了解與其實施相關的挑戰和復雜性也很重要。
克服維度的詛咒
維度的詛咒是指隨著數據集中特征(維度)數量的增加,計算復雜性呈指數級增長。對于交易中的強化學習模型,每個維度都可以代表一個市場因素或指標,所有這些因素的組合構成了狀態空間,可以變得巨大。
減輕維度詛咒的一種方法是通過特征選擇,這涉及識別和選擇與手頭任務最相關的特征。通過減少特征的數量,我們可以有效地縮小狀態空間,使學習問題更容易處理。
?
?
另一種方法是降維,例如主成分分析 (PCA) 或 t 分布隨機鄰域嵌入 (t-SNE)。這些技術將原始高維數據轉換為低維空間,盡可能多地保留重要信息。
?
from sklearn.decomposition import PCA
?
# Assume X is the feature matrix
n_components = 5 # Number of principal components to keep
pca = PCA(n_components=n_components)
X_reduced = pca.fit_transform(X)
?
?
處理不確定性和噪聲
金融市場本質上是嘈雜和不可預測的,價格受到許多因素的影響。為了解決這個問題,我們可以將管理不確定性的技術整合到我們的強化學習模型中。例如,貝葉斯方法可用于表示和操縱模型中的不確定性。
此外,可以使用Q學習和SARSA等強化學習算法,這些算法學習動作值函數,并且已知可以處理具有高度不確定性的環境。
防止過度擬合
當模型對訓練數據過于專用并且對看不見的數據表現不佳時,就會發生過度擬合。正則化技術(如 L1 和 L2 正則化)可以通過懲罰過于復雜的模型來幫助防止過度擬合。
?
?
?
防止過度擬合的另一種方法是使用驗證集和交叉驗證。通過在訓練過程中定期評估模型在單獨的驗證集上的性能,我們可以跟蹤模型對未見過的數據的泛化程度。
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
?
# Assume X and y are the feature matrix and target variable
model = LinearRegression()
cv_scores = cross_val_score(model, X, y, cv=5) # 5-fold cross-validation
?
? ? ? ?平衡勘探和開發
在探索(嘗試新動作)和利用(堅持已知動作)之間取得適當的平衡是強化學習的一個關鍵挑戰。可以使用多種策略來管理這種權衡。
一種常見的方法是 epsilon-greedy 策略,其中代理主要采取它當前認為最好的操作(開發),但概率很小(epsilon),它采取隨機操作(探索)。
?
import numpy as np
?
def epsilon_greedy(Q, state, n_actions, epsilon):
if np.random.random() < epsilon:
return np.random.randint(n_actions) # Exploration: choose a random action
else:
return np.argmax(Q[state]) # Exploitation: choose the action with the highest Q-value
?
?
?
另一種方法是置信上限(UCB)方法,其中代理根據預期獎勵的上限選擇行動,鼓勵探索具有高潛力的行動。
?
import numpy as np
import math
?
def ucb_selection(plays, rewards, t):
n_arms = len(plays)
ucb_values = [0] * n_arms
for i in range(n_arms):
if plays[i] == 0:
ucb_values[i] = float('inf')
else:
ucb_values[i] = rewards[i] / plays[i] + math.sqrt(2 * math.log(t) / plays[i])
return np.argmax(ucb_values)
?
?
未來展望
強化學習和算法交易的交叉是一個新興領域,雖然它已經顯示出希望,但有幾個令人興奮的發展即將到來。
最突出的趨勢之一是越來越多地使用深度強化學習,它將強化學習的決策能力與深度學習的模式識別能力相結合。深度強化學習有可能處理更復雜的決策任務,使其特別適合金融市場的復雜性。
我們還可以期待在強化學習模型中看到更復雜的獎勵結構。當前的模型通常使用簡單的獎勵結構,例如交易的利潤或損失。然而,未來的模型可以包含更細微的回報,考慮到風險、流動性和交易成本等因素。這將允許制定更加平衡和可持續的貿易戰略。
另一個有趣的前景是使用強化學習進行投資組合管理。強化學習不是對單個交易做出決策,而是可以用來管理資產組合,決定將投資組合的比例分配給每種資產,以最大限度地提高回報和管理風險。
在研究方面,有很多正在進行的工作旨在克服與交易中強化學習相關的挑戰。例如,研究人員正在探索更有效地管理勘探-開發權衡的方法,以處理維度的詛咒,并防止過度擬合。
總之,雖然算法交易中的強化學習仍然是一個相對較新的領域,但它具有巨大的潛力。通過繼續探索和開發這項技術,我們可以徹底改變算法交易,使其更高效、更具適應性和盈利能力。作為技術專業人士,我們有令人興奮的機會站在這場革命的最前沿。
審核編輯:郭婷



















 工商網監
工商網監
評論