") 強化學(xué)習(xí)在自動駕駛的應(yīng)用
強化學(xué)習(xí)在自動駕駛的應(yīng)用
制造真正的自動駕駛汽車(即能夠在任何要求的環(huán)境中安全駕駛)的關(guān)鍵是更加重視關(guān)于其軟件的自學(xué)能力。換句話說,自動駕駛汽車首先是人工智能問題,需要一個非常具體的機器學(xué)習(xí)開發(fā)技能。而強化學(xué)習(xí)是機器學(xué)習(xí)的一個重要分支,是多學(xué)科多領(lǐng)域交叉的一個產(chǎn)物,它的本質(zhì)是解決決策(decision making)問題,即自動進(jìn)行決策,并且可以做連續(xù)決策。今天人工智能頭條給大家介紹強化學(xué)習(xí)在自動駕駛的一個應(yīng)用案例,無需 3D 地圖也無需規(guī)則,讓汽車從零開始在二十分鐘內(nèi)學(xué)會如何自動駕駛。
▌前言
強化學(xué)習(xí)是通過對未知環(huán)境一邊探索一邊建立環(huán)境模型以及學(xué)得一個最優(yōu)策略。強化學(xué)習(xí)具有以下特征:
沒有監(jiān)督數(shù)據(jù),只有獎勵(reward)信號;
獎勵信號不一定是實時的,而很可能是延后的,有時甚至延后很多;
時間(序列)是一個重要因素;
智能體當(dāng)前的行為影響后續(xù)接收到的數(shù)據(jù)。
而有監(jiān)督學(xué)習(xí)則是事先給你了一批樣本,并告訴你哪些樣本是優(yōu)的哪些是劣的(樣本的標(biāo)記信息),通過學(xué)習(xí)這些樣本而建立起對象的模型及其策略。在強化學(xué)習(xí)中沒有人事先告訴你在什么狀態(tài)下應(yīng)該做什么,只有在摸索中反思之前的動作是否正確來學(xué)習(xí)。從這個角度看,可以認(rèn)為強化學(xué)習(xí)是有時間延遲標(biāo)記信息的有監(jiān)督學(xué)習(xí)。
其他許多機器學(xué)習(xí)算法中學(xué)習(xí)器都是學(xué)得怎樣做,而強化學(xué)習(xí)是在嘗試的過程中學(xué)習(xí)到在特定的情境下選擇哪種行動可以得到最大的回報。
簡而言之,強化學(xué)習(xí)采用的是邊獲得樣例邊學(xué)習(xí)的方式,在獲得樣例之后更新自己的模型,利用當(dāng)前的模型來指導(dǎo)下一步的行動,下一步的行動獲得獎勵之后再更新模型,不斷迭代重復(fù)直到模型收斂。
強化學(xué)習(xí)有廣泛的應(yīng)用:像直升機特技飛行、經(jīng)典游戲、投資管理、發(fā)電站控制、讓機器人模仿人類行走等等。
英國初創(chuàng)公司 wayve 日前發(fā)表的一篇文章 Learning to drive in a day,闡述了強化學(xué)習(xí)在自動駕駛汽車中的應(yīng)用。Wayve是英國兩位劍橋大學(xué)的機器學(xué)習(xí)博士創(chuàng)立的英國自動駕駛汽車公司,正在建立“端到端的機器學(xué)習(xí)算法”,它聲稱使用的方法與大部分自駕車的思維不同。具體來說,這家公司認(rèn)為制造真正的自動駕駛汽車的關(guān)鍵在于軟件的自學(xué)能力,而其他公司使用更多的傳感器并不能解決問題,它需要的是更好的協(xié)調(diào)。
自動駕駛的人工智能包含了感知、決策和控制三個方面。
感知指的是如何通過攝像頭和其他傳感器的輸入解析出周圍環(huán)境的信息,例如有哪些障礙物、障礙物的速度和距離、道路的寬度和曲率等。而感知模塊不可能做到完全可靠。Tesla 的無人駕駛事故就是在強光的環(huán)境中感知模塊失效導(dǎo)致的。強化學(xué)習(xí)可以做到,即使在某些模塊失效的情況下也能做出穩(wěn)妥的行為。強化學(xué)習(xí)可以比較容易地學(xué)習(xí)到一系列的行為。自動駕駛中需要執(zhí)行一系列正確的行為才能成功的駕駛。如果只有標(biāo)注數(shù)據(jù),學(xué)習(xí)到的模型每個時刻偏移了一點,到最后可能會偏移非常多,產(chǎn)生毀滅性的后果。強化學(xué)習(xí)能夠?qū)W會自動修正偏移。
自動駕駛的決策是指給定感知模塊解析出的環(huán)境信息如何控制汽車的行為達(dá)到駕駛的目標(biāo)。例如,汽車加速、減速、左轉(zhuǎn)、右轉(zhuǎn)、換道、超車都是決策模塊的輸出。決策模塊不僅需要考慮到汽車的安全性和舒適性,保證盡快到達(dá)目標(biāo)地點,還需要在旁邊的車輛惡意的情況下保證乘客的安全。因此,決策模塊一方面需要對行車的計劃進(jìn)行長期規(guī)劃,另一方面需要對周圍車輛和行人的行為進(jìn)行預(yù)測。而且,無人駕駛中的決策模塊對安全性和可靠性有嚴(yán)格的要求。現(xiàn)有的無人駕駛的決策模塊一般是根據(jù)規(guī)則構(gòu)建的。雖然基于規(guī)則的構(gòu)建可以應(yīng)付大部分的駕駛情況,對于駕駛中可能出現(xiàn)的各種各樣的突發(fā)情況,基于規(guī)則的決策系統(tǒng)不可能枚舉到所有突發(fā)情況。我們需要一種自適應(yīng)的系統(tǒng)來應(yīng)對駕駛環(huán)境中出現(xiàn)的各種突發(fā)情況。
現(xiàn)在,讓我們來看看 Wayve 的自動駕駛汽車的解決方案有什么新穎的地方。
▌從零開始學(xué)會如何通過試錯法來學(xué)會自動駕駛
還記得小時候?qū)W騎自行車的情景嗎?又興奮,又有一點點焦慮。你可能是第一次坐在自行車上,踩著踏板,大人跟隨在你身邊,準(zhǔn)備在你失去平衡的時候扶住你。在一些搖擺不定的嘗試之后,你可能設(shè)法保持了幾米距離的平衡。幾個小時過去后,你可能在公園里的沙礫和草地上能夠飛馳了。大人只會給你一些簡短的提示。你不需要一張公園的密集 3D 地圖,也不需要在頭上裝一個高保真激光攝像頭。你也不需要遵循一長串的規(guī)則就能在自行車上保持平衡。大人只是為你提供了一個安全的環(huán)境,讓你學(xué)會如何根據(jù)你所見來決定你的行為,從而成功學(xué)會騎車。
如今,自動駕駛汽車安裝了大量的傳感器,并通過緩慢的開發(fā)周期中被告知如何通過一長串精心設(shè)計的規(guī)則來駕駛車輛。在本文中,我們將回到基礎(chǔ),讓汽車從零開始學(xué)會如何通過試錯法來學(xué)會自動駕駛,就像你學(xué)騎自行車一樣。
看看我們做了什么:只用了 15~20 分鐘,我們就能夠教會一輛汽車從零開始沿著一條車道行駛,而這只有當(dāng)安全駕駛員接手時作為訓(xùn)練反饋才使用。
譯注:試錯(trial and error)是一種用來解決問題、獲取知識的常見方法。此種方法可視為簡易解決問題的方法中的一種,與使用洞察力和理論推導(dǎo)的方法正好相反。在試錯的過程中,選擇一個可能的解法應(yīng)用在待解問題上,經(jīng)過驗證后如果失敗,選擇另一個可能的解法再接著嘗試下去。整個過程在其中一個嘗試解法產(chǎn)生出正確結(jié)果時結(jié)束。
像學(xué)騎自行車的方法只有一種:試錯。雖然簡單,但這個思想實驗突出了人類智能的一些重要方面。對于某些任務(wù),我們采用試錯法;而對于其他任務(wù)我們則使用規(guī)劃的方法。在強化學(xué)習(xí)中也出現(xiàn)了類似的現(xiàn)象。按照強化學(xué)習(xí)的說法,實證結(jié)果表明,一些任務(wù)更適合無模型(試錯)方法,而另一些則更適合基于模型的(規(guī)劃)方法。
▌無需密集 3D 地圖,無需手寫規(guī)則
這是自動駕駛汽車在網(wǎng)上學(xué)習(xí)的第一個例子,每一次嘗試都會讓它變得更好。那么,我們是怎么做到的呢?
我們采用了一種流行的無模型深度強化學(xué)習(xí)算法(深度確定性策略梯度:deep deterministic policy gradients,DDPG)來解決車道跟蹤問題。我們的模型輸入是單目鏡攝像頭圖像。我們的系統(tǒng)迭代了三個過程:探索、優(yōu)化和評估。
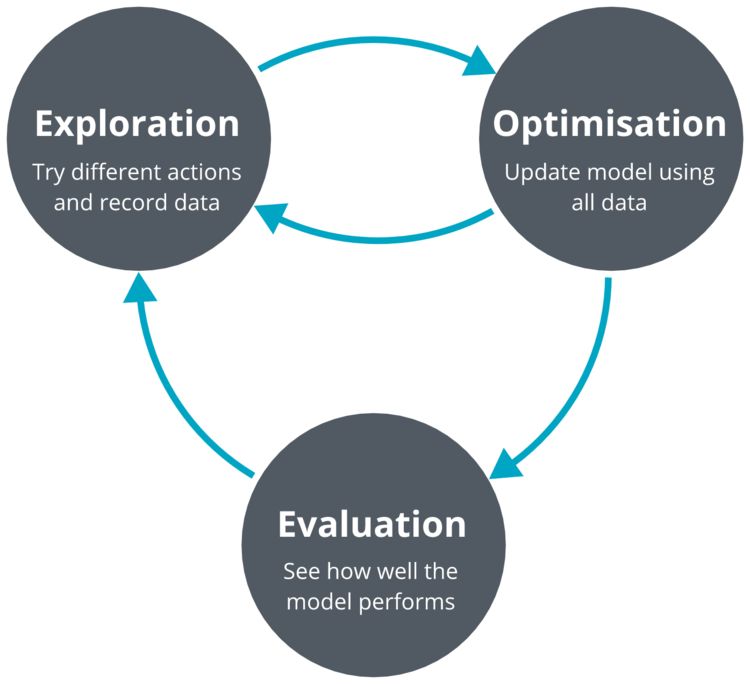
譯注:DDPG,由DeepMind的Lillicrap 等于 2016 年提出,全稱是:Deep Deterministic Policy Gradient,是將深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)融合進(jìn)DPG的策略學(xué)習(xí)方法。而 DPG 是由 DeepMind 的 D.Silver 等人在 2014 年提出的: Deterministic Policy Gradient,即確定性的行為策略。在此之前,業(yè)界普遍認(rèn)為,環(huán)境模型無關(guān)(model-free)的確定性策略是不存在的,在 2014 年的 DPG 論文中,D.Silver 等通過嚴(yán)密的數(shù)學(xué)推導(dǎo),證明了 DPG 的存在。DDPG 相對于 DPG 的核心改進(jìn)是:采用卷積神經(jīng)網(wǎng)絡(luò)作為策略函數(shù)μ 和 Q 函數(shù)的模擬,即策略網(wǎng)絡(luò)和 Q 網(wǎng)絡(luò);然后使用深度學(xué)習(xí)的方法來訓(xùn)練上述神經(jīng)網(wǎng)絡(luò)。
DDPG 算法是利用 QDN 擴展 Q 學(xué)習(xí)算法的思路對 DPG 方法進(jìn)行改造,提出的一種基于行動者-評論家(Actor-Critic,AC)框架的算法,該算法可用于解決連續(xù)動作空間上的 DRL 問題。
可參考論文《Continuous control with deep reinforcementlearning》(https://arxiv.org/abs/1509.02971)
無模型的 DDPG 方法學(xué)習(xí)更慢,但最終優(yōu)于基于模型的方法。
我們的網(wǎng)絡(luò)架構(gòu)是一個深度網(wǎng)絡(luò),有 4 個卷積層和 3 個完全連接的層,總共略低于 10k 個參數(shù)。為了比較,現(xiàn)有技術(shù)的圖像分類體系結(jié)構(gòu)有數(shù)百萬個參數(shù)。
所有的處理都是在汽車上的一個圖形處理單元(GPU)上執(zhí)行的。
在危險的真實環(huán)境中使用真正的機器人會帶來很多新問題。為了更好地理解手頭的任務(wù),并找到合適的模型架構(gòu)和超參數(shù),我們進(jìn)行了大量的仿真測試。
上組動圖所示,是我們的車道跟隨不同角度顯示的模擬環(huán)境的示例。這個算法只能看到駕駛員的視角,也就是圖中有青色邊框的圖像。在每一次模擬中,我們都會隨機生成一條彎曲的車道,以及道路紋理和車道標(biāo)記。智能體會一直探索,直到模擬終止時它才離開。然后根據(jù)手機到的數(shù)據(jù)進(jìn)行策略優(yōu)化,我們重復(fù)這樣的步驟。
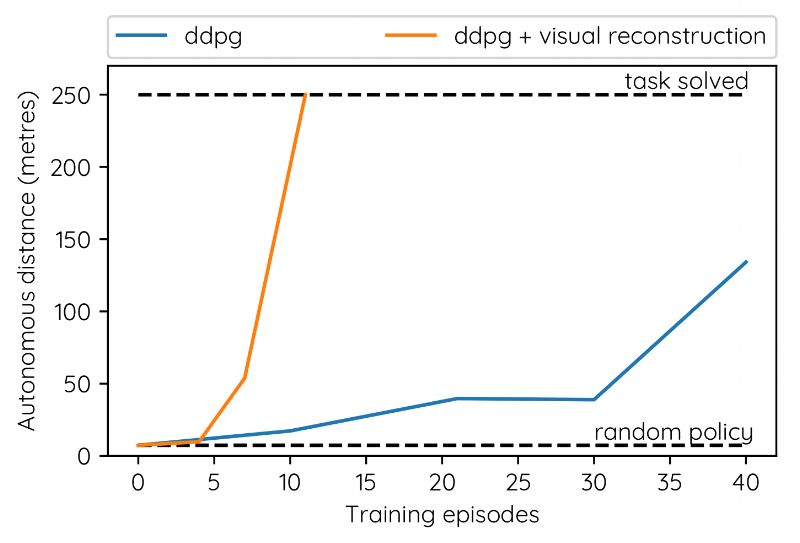
在安全駕駛員接管之前,汽車行駛的距離與模擬探索的數(shù)量有關(guān)。
我們使用模擬測試來嘗試不同的神經(jīng)網(wǎng)絡(luò)架構(gòu)和超參數(shù),直到我們找到一致的設(shè)置,這些設(shè)置在很少的訓(xùn)練集中,也就是幾乎沒有數(shù)據(jù)的情況下,始終如一地解決了車道跟隨的問題。例如,我們的發(fā)現(xiàn)之一,是使用自動編碼器重構(gòu)損失訓(xùn)練卷積層可以顯著提高訓(xùn)練的穩(wěn)定性和數(shù)據(jù)效率。
▌潛在的影響力
我們的方法的潛在影響是巨大的。想象一下,部署一支自動駕駛車隊,使用一種最初只有人類司機 95% 質(zhì)量的駕駛算法會怎么樣。這樣一個系統(tǒng)將不會像我們的演示視頻中的隨機初始化模型那樣搖搖晃晃地行駛,而是幾乎能夠處理交通信號燈、環(huán)形交叉路口、十字路口等道路情況。經(jīng)過一天的駕駛和人類安全駕駛員接管的在線改進(jìn)后,系統(tǒng)也許可以提高到 96%。一個星期以后,提高到 98%。一個月以后,提高到99%。幾個月以后,這個系統(tǒng)可能會變得超人類,因為它從許多不同的安全駕駛員的反饋中受益得以提高。
今天的自動駕駛汽車仍停留在良好的狀態(tài),但性能水平還不夠好。在本文中,我們?yōu)榈谝粋€可行的框架提供了證據(jù),以便快速改善駕駛算法,使其從不堪造就到可安全行駛。通過巧妙的試錯法快速學(xué)習(xí)解決問題的能力,使人類擁有具備進(jìn)化和生存能力的萬能機器。我們通過各種各樣的模仿來學(xué)習(xí),從騎自行車到學(xué)習(xí)烹飪,我們經(jīng)歷了很多試錯的過程。
DeepMind 向我們展示了深度強化學(xué)習(xí)方法可以在許多游戲中實現(xiàn)超人類的表現(xiàn),包括圍棋、象棋和電腦游戲,幾乎總是比任何基于規(guī)則的系統(tǒng)表現(xiàn)的更好。我們發(fā)現(xiàn),類似的哲學(xué)在現(xiàn)實世界中也是可能的,特別是在自動駕駛汽車中。有一點需要注意的是,DeepMind 的 Atari算法需要數(shù)百萬次試驗才能完成一個任務(wù)。值得注意的是,我們在不到 20 次試驗中,一貫都學(xué)會了沿著車道行駛。
▌結(jié)束語
20 分鐘,我們從零開始,學(xué)會了沿著車道行駛。想象一下,我們一天可以學(xué)到什么?
Wayve 的理念是構(gòu)建機器人智能,不需要大量的模型、花哨的傳感器和無盡的數(shù)據(jù)。我們需要的是一個聰明的訓(xùn)練過程,可以快速有效地學(xué)習(xí),就像我們上面的視頻一樣。人工設(shè)計的自動駕駛技術(shù)在性能上達(dá)到了令人不滿意的玻璃天花板。Wayve 正視圖通過更智能的機器學(xué)習(xí)來開發(fā)自動駕駛功能。
-
自動駕駛
+關(guān)注
關(guān)注
788文章
14179瀏覽量
169331 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11512
原文標(biāo)題:講真?一天就學(xué)會了自動駕駛——強化學(xué)習(xí)在自動駕駛的應(yīng)用
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
自動駕駛安全基石:ODD
新能源車軟件單元測試深度解析:自動駕駛系統(tǒng)視角

從《自動駕駛地圖數(shù)據(jù)規(guī)范》聊高精地圖在自動駕駛中的重要性
MEMS技術(shù)在自動駕駛汽車中的應(yīng)用
如何使用 PyTorch 進(jìn)行強化學(xué)習(xí)
自動駕駛汽車安全嗎?


自動駕駛HiL測試方案案例分析--ADS HiL測試系統(tǒng)#ADAS #自動駕駛 #VTHiL

FPGA在自動駕駛領(lǐng)域有哪些優(yōu)勢?
FPGA在自動駕駛領(lǐng)域有哪些應(yīng)用?
深度學(xué)習(xí)在自動駕駛中的關(guān)鍵技術(shù)
中級自動駕駛架構(gòu)師應(yīng)該學(xué)習(xí)哪些知識
初級自動駕駛架構(gòu)師應(yīng)該學(xué)習(xí)哪些知識
通過強化學(xué)習(xí)策略進(jìn)行特征選擇






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論