 電子發(fā)燒友App
電子發(fā)燒友App


特斯拉是一個(gè)典型的AI公司,過去一年訓(xùn)練了75000個(gè)神經(jīng)網(wǎng)絡(luò),意味著每8分鐘就要出一個(gè)新的模型,共有281個(gè)模型用到了特斯拉的車上。接下來(lái)我們分幾個(gè)方面來(lái)解讀特斯拉FSD的算法和模型進(jìn)展。
感知 Occupancy Network
特斯拉今年在感知方面的一個(gè)重點(diǎn)技術(shù)是Occupancy Network (占據(jù)網(wǎng)絡(luò))。研究機(jī)器人技術(shù)的同學(xué)肯定對(duì)occupancy grid不會(huì)陌生,occupancy表示空間中每個(gè)3D體素(voxel)是否被占據(jù),可以是0/1二元表示,也可以是[0, 1]之間的一個(gè)概率值。
為什么估計(jì)occupancy對(duì)自動(dòng)駕駛感知很重要呢?因?yàn)樵谛旭傊校顺R娬系K物如車輛、行人,我們可以通過3D物體檢測(cè)的方式來(lái)估計(jì)他們的位置和大小,還有更多長(zhǎng)尾的障礙物也會(huì)對(duì)行駛產(chǎn)生重要影響。例如:1.可變形的障礙物,如兩節(jié)的掛車,不適合用3D bounding box來(lái)表示;2.異形障礙物,如翻倒的車輛,3D姿態(tài)估計(jì)會(huì)失效;3.不在已知類別中的障礙物,如路上的石子、垃圾等,無(wú)法進(jìn)行分類。因此,我們希望能找到一種更好的表達(dá)來(lái)描述這些長(zhǎng)尾障礙物,完整估計(jì)3D空間中每一個(gè)位置的占據(jù)情況(occupancy),甚至是語(yǔ)義(semantics)和運(yùn)動(dòng)情況(flow)。
特斯拉用下圖的具體例子來(lái)展現(xiàn)Occupancy Network的強(qiáng)大。不同于3D的框,occupancy這種表征對(duì)物體沒有過多的幾何假設(shè),因此可以建模任意形狀的物體和任意形式的物體運(yùn)動(dòng)。圖中展示了一個(gè)兩節(jié)的公交車正在啟動(dòng)的場(chǎng)景,藍(lán)色表示運(yùn)動(dòng)的體素,紅色表示靜止的體素,Occupancy Network精確地估計(jì)出了公交車的第一節(jié)已經(jīng)開始運(yùn)動(dòng),而第二節(jié)還處于靜止?fàn)顟B(tài)。

對(duì)正在啟動(dòng)的兩節(jié)公交車的occupancy估計(jì),藍(lán)色表示運(yùn)動(dòng)的體素,紅色表示靜止的體素
Occupancy Network的模型結(jié)構(gòu)如下圖所示。首先模型利用RegNet和BiFPN從多相機(jī)獲取特征,這個(gè)結(jié)構(gòu)跟去年的AI day分享的網(wǎng)絡(luò)結(jié)構(gòu)一致,說(shuō)明backbone變化不大。然后模型通過帶3D空間位置的spatial query對(duì)2D圖像特征進(jìn)行基于attention的多相機(jī)融合。如何實(shí)現(xiàn)3D spatial query和2D特征圖之間的聯(lián)系呢?具體融合的方式圖中沒有細(xì)講,但有很多公開的論文可以參考。我認(rèn)為最有可能采取的是兩種方案之一,第一種叫做3D-to-2D query,即根據(jù)每個(gè)相機(jī)的內(nèi)外參將3D spatial query投影到2D特征圖上,提取對(duì)應(yīng)位置的特征。該方法在DETR3D中提出,BEVFormer和PolarFormer也采取了該思想。第二種是利用positional embedding來(lái)進(jìn)行隱式的映射,即將2D特征圖的每個(gè)位置加上合理的positional embedding,如相機(jī)內(nèi)外參、像素坐標(biāo)等,然后讓模型自己學(xué)習(xí)2D到3D特征的對(duì)應(yīng)關(guān)系。再接下來(lái)模型進(jìn)行時(shí)序融合,實(shí)現(xiàn)的方法是根據(jù)已知的自車位置和姿態(tài)變化,將3D特征空間進(jìn)行拼接。
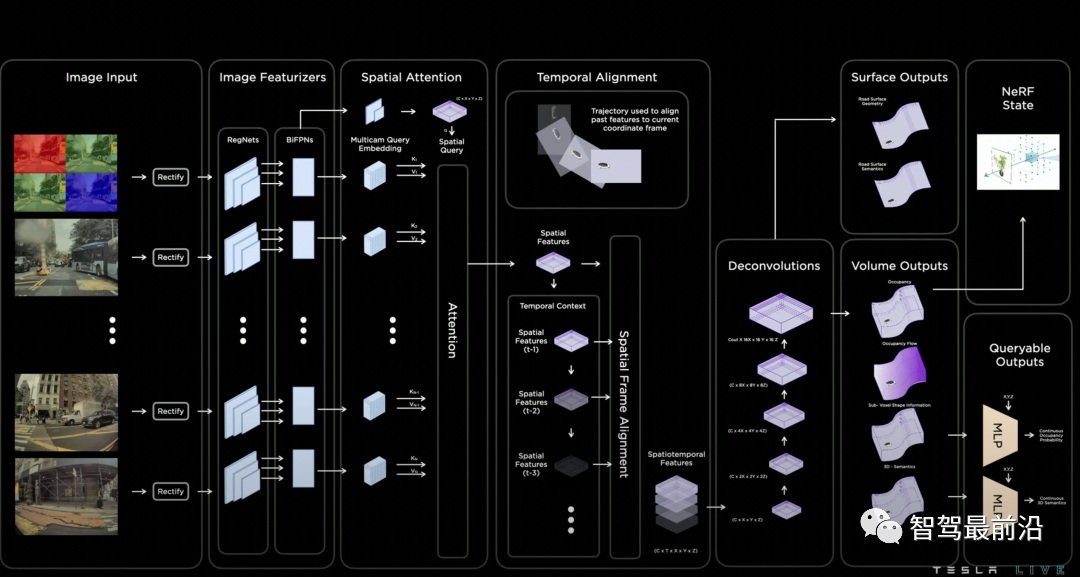
Occupancy Network結(jié)構(gòu)
特征融合后,一個(gè)基于deconvolution的解碼器會(huì)解碼出每個(gè)3D空間位置的occupancy,semantics以及flow。發(fā)布會(huì)中強(qiáng)調(diào),由于這個(gè)網(wǎng)絡(luò)的輸出是稠密(dense)的,輸出的分辨率會(huì)受到內(nèi)存的限制。我相信這也是所有做圖像分割的同學(xué)們遇到的一大頭疼的問題,更何況這里做的是3D分割,但自動(dòng)駕駛對(duì)于分辨率度的要求卻很高(~10cm)。因此,受到神經(jīng)隱式表示(neural implicit representation)的啟發(fā),模型的最后額外設(shè)計(jì)了一個(gè)隱式queryable MLP decoder,輸入任意坐標(biāo)值(x,y,z),可解碼出該空間位置的信息,即occupancy,semantics,flow。該方法打破了模型分辨率的限制,我認(rèn)為是設(shè)計(jì)上的一個(gè)亮點(diǎn)。
規(guī)劃 Interactive Planning
規(guī)劃是自動(dòng)駕駛的另一個(gè)重要模塊,特斯拉這次主要強(qiáng)調(diào)了在復(fù)雜路口對(duì)交互(interaction)進(jìn)行建模。為什么交互建模如此重要呢?因?yàn)槠渌囕v、行人的未來(lái)行為都有一定的不確定性,一個(gè)聰明的規(guī)劃模塊要在線進(jìn)行多種自車和他車交互的預(yù)測(cè),并且對(duì)每一種交互帶來(lái)的風(fēng)險(xiǎn)進(jìn)行評(píng)估,并最終決定采取何種策略。
特斯拉把他們采用的規(guī)劃模型叫做交互搜索(Interaction Search),它主要由三個(gè)主要步驟組成:樹搜索,神經(jīng)網(wǎng)絡(luò)軌跡規(guī)劃和軌跡打分。
1、樹搜索是軌跡規(guī)劃常用的算法,可以有效地發(fā)現(xiàn)各種交互情形找到最優(yōu)解,但用搜索的方法來(lái)解決軌跡規(guī)劃問題遇到的最大困難是搜索空間過大。例如,在一個(gè)復(fù)雜路口可能有20輛與自車相關(guān),可以組合成超過100種交互方式,而每種交互方式都可能有幾十種時(shí)空軌跡作為候選。因此特斯拉并沒有采用軌跡搜索的方法,而是用神經(jīng)網(wǎng)絡(luò)來(lái)給一段時(shí)間后可能到達(dá)的目標(biāo)位置(goal)進(jìn)行打分,得到少量較優(yōu)的目標(biāo)。
2、在確定目標(biāo)以后,我們需要確定一條到達(dá)目標(biāo)的軌跡。傳統(tǒng)的規(guī)劃方法往往使用優(yōu)化來(lái)解決該問題,解優(yōu)化并不難,每次優(yōu)化大約花費(fèi)1到5毫秒,但是當(dāng)前面步驟樹搜索的給出的候選目標(biāo)比較多的時(shí)候,時(shí)間成本我們也無(wú)法負(fù)擔(dān)。因此特斯拉提出使用另一個(gè)神經(jīng)網(wǎng)絡(luò)來(lái)進(jìn)行軌跡規(guī)劃,從而對(duì)多個(gè)候選目標(biāo)實(shí)現(xiàn)高度并行規(guī)劃。訓(xùn)練這個(gè)神經(jīng)網(wǎng)絡(luò)的軌跡標(biāo)簽有兩種來(lái)源:第一種是人類真實(shí)開車的軌跡,但是我們知道人開的軌跡可能只是多種較優(yōu)方案中的一種,因此第二種來(lái)源是通過離線優(yōu)化算法產(chǎn)生的其他的軌跡解。
3、在得到一系列可行軌跡后,我們要選擇一個(gè)最優(yōu)方案。這里采取的方案是對(duì)得到的軌跡進(jìn)行打分,打分的方案集合了人為制定的風(fēng)險(xiǎn)指標(biāo),舒適指標(biāo),還包括了一個(gè)神經(jīng)網(wǎng)絡(luò)的打分器。
通過以上三個(gè)步驟的解耦,特斯拉實(shí)現(xiàn)了一個(gè)高效的且考慮了交互的軌跡規(guī)劃模塊。基于神經(jīng)網(wǎng)絡(luò)的軌跡規(guī)劃可以參考的論文并不多,我有發(fā)表過一篇與該方法比較相關(guān)的論文TNT[5],同樣地將軌跡預(yù)測(cè)問題分解為以上三個(gè)步驟進(jìn)行解決:目標(biāo)打分,軌跡規(guī)劃,軌跡打分。感興趣的讀者可以前往查閱細(xì)節(jié)。此外,我們課題組也在一直探究行為交互和規(guī)劃相關(guān)的問題,也歡迎大家關(guān)注我們最新的工作InterSim[6]。
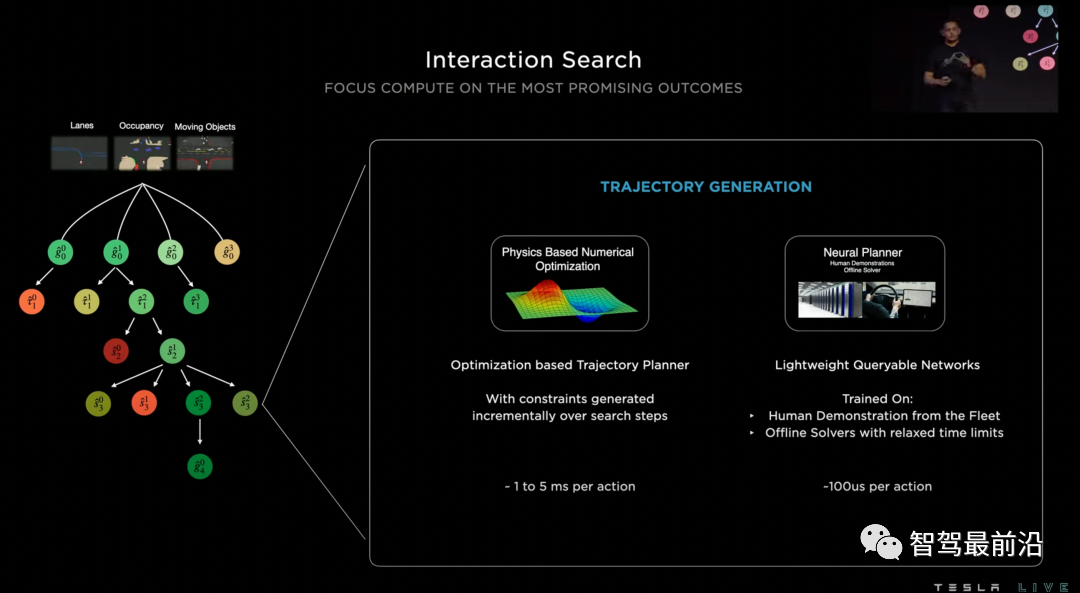
Interaction Search規(guī)劃模型結(jié)構(gòu)
矢量地圖 Lanes Network
個(gè)人覺得本次AI Day上另一大技術(shù)亮點(diǎn)是在線矢量地圖構(gòu)建模型Lanes Network。有關(guān)注去年AI Day的同學(xué)們可能記得,特斯拉在BEV空間中對(duì)地圖進(jìn)行了完整的在線分割和識(shí)別。那么為什么還要做Lanes Network呢?因?yàn)榉指畹玫降南袼丶?jí)別的車道不足夠用于軌跡規(guī)劃,我們還需要得到車道線的拓?fù)浣Y(jié)構(gòu),才能知道我們的車可以從一條車道變換到另一條車道。
我們先來(lái)看看什么是矢量地圖,如圖所示,特斯拉的矢量地圖由一系列藍(lán)色的車道中心線centerline和一些關(guān)鍵點(diǎn)(連接點(diǎn)connection,分叉點(diǎn)fork, 并道點(diǎn)merge)組成,并且通過graph的形式表現(xiàn)了他們的連接關(guān)系。
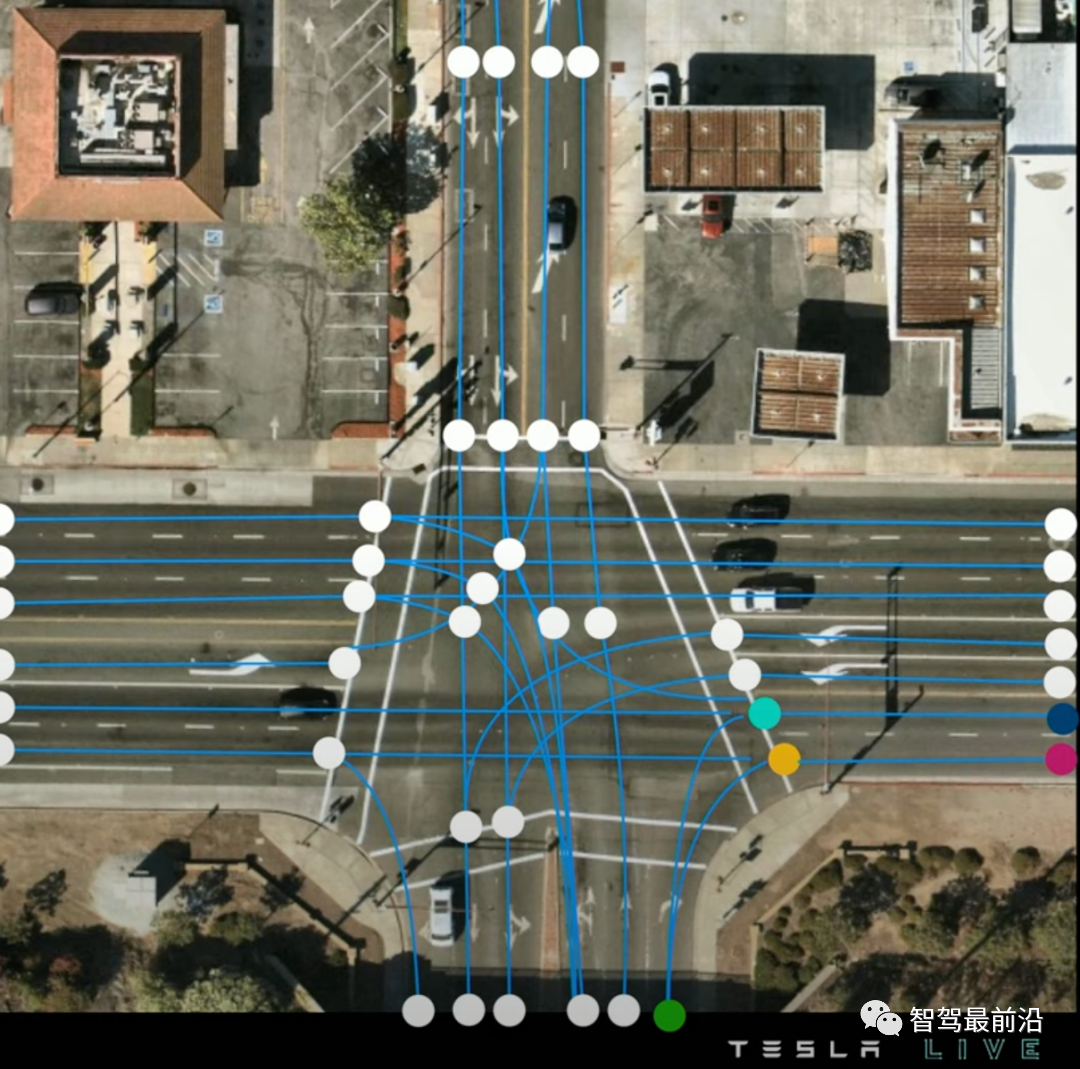
矢量地圖,圓點(diǎn)為車道線關(guān)鍵點(diǎn),藍(lán)色為車道中心線
Lanes Network在模型結(jié)構(gòu)上,是感知網(wǎng)絡(luò)backbone基礎(chǔ)上的一個(gè)decoder。相比解碼出每個(gè)體素的occupancy和語(yǔ)義,解碼出一系列稀疏的、帶連接關(guān)系的車道線更為困難,因?yàn)檩敵龅臄?shù)量不固定,此外輸出量之間還有邏輯關(guān)系。
特斯拉參考了自然語(yǔ)言模型中的Transformer decoder,以序列的方式自回歸地輸出結(jié)果。具體實(shí)現(xiàn)上來(lái)說(shuō),我們首先要選取一個(gè)生成順序(如從左到右,從上到下),對(duì)空間進(jìn)行離散化(tokenization)。然后我們就可以用Lanes Network進(jìn)行一系列離散token的預(yù)測(cè)。如圖所示,網(wǎng)絡(luò)會(huì)先預(yù)測(cè)一個(gè)節(jié)點(diǎn)的粗略位置的(index:18),精確位置(index:31),然后預(yù)測(cè)該節(jié)點(diǎn)的語(yǔ)義("Start",即車道線的起點(diǎn)),最后預(yù)測(cè)連接特性,如分叉/并道/曲率參數(shù)等。網(wǎng)絡(luò)會(huì)以這樣自回歸的方式將所有的車道線節(jié)點(diǎn)進(jìn)行生成。
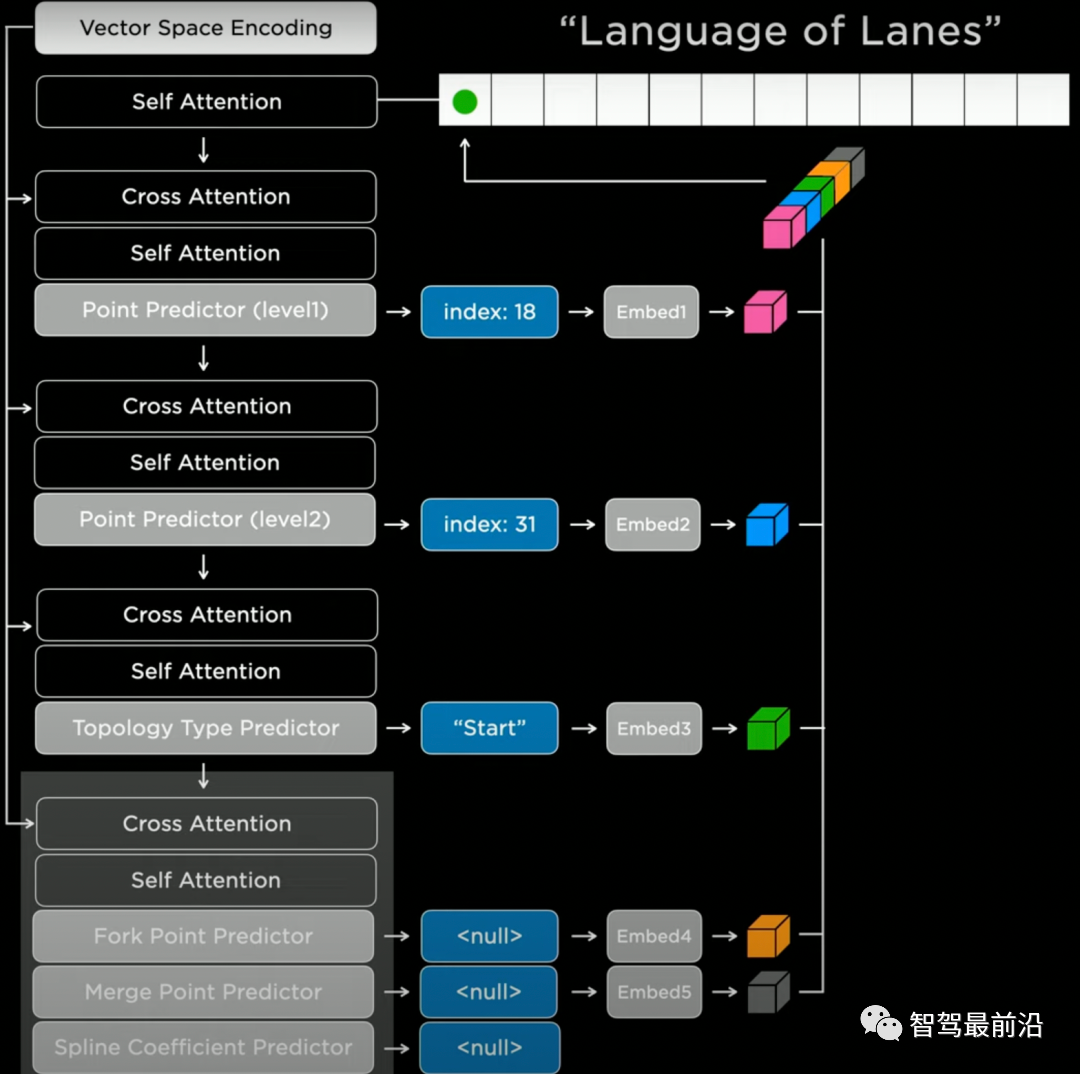
Lanes Network網(wǎng)絡(luò)結(jié)構(gòu)
我們要注意到,自回歸的序列生成并不是語(yǔ)言Transformer模型的專利。我們課題組在過去幾年中也有兩篇生成矢量地圖的相關(guān)論文,HDMapGen[7]和VectorMapNet[8]。HDMapGen采用帶注意力的圖神經(jīng)網(wǎng)絡(luò)(GAT)自回歸地生成矢量地圖的關(guān)鍵點(diǎn),和特斯拉的方案有異曲同工之妙。而VectorMapNet采用了Detection Transformer(DETR)來(lái)解決該問題,即用集合預(yù)測(cè)(set prediction)的方案來(lái)更快速地生成矢量地圖。
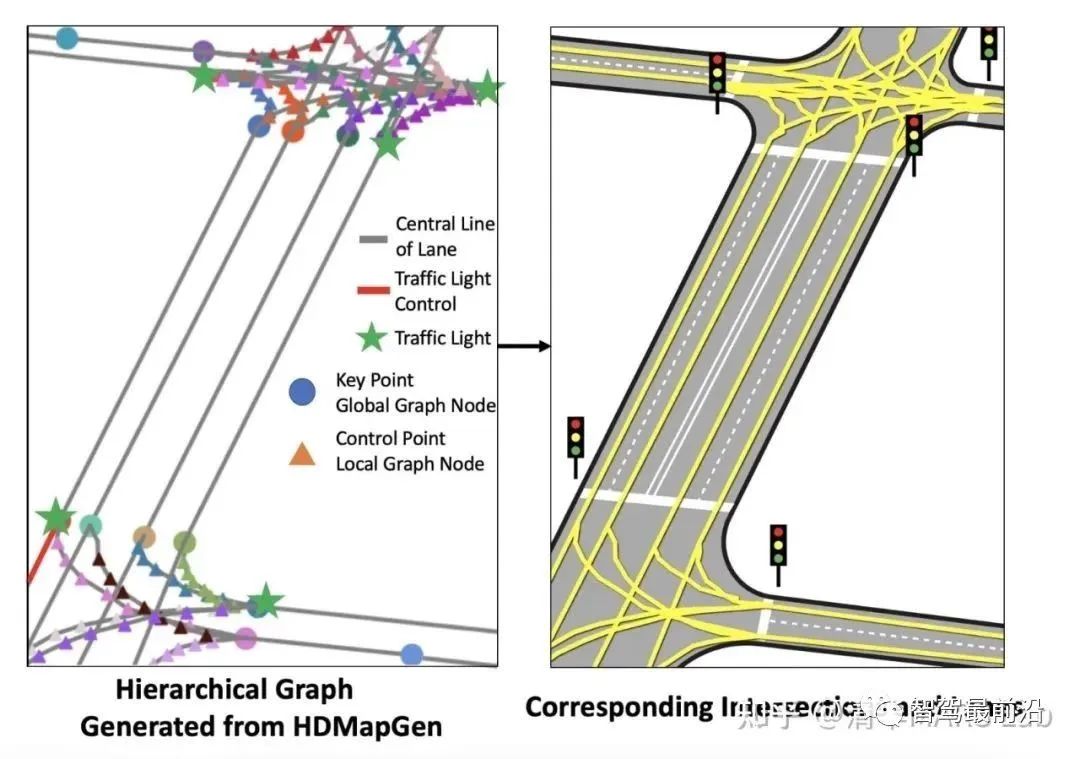
HDMapGen矢量地圖生成結(jié)果
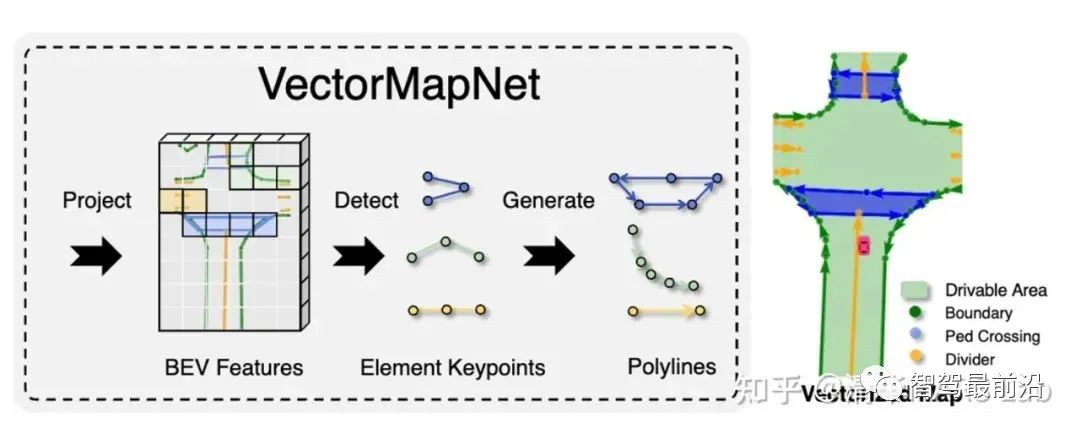
VectorMapNet矢量地圖生成結(jié)果
自動(dòng)標(biāo)注 Autolabeling
自動(dòng)標(biāo)注也是特斯拉在去年AI Day就講解過的一種技術(shù),今年的自動(dòng)標(biāo)注著重講解了Lanes Network的自動(dòng)標(biāo)注。特斯拉的車每天就能產(chǎn)生500000條駕駛旅程(trip),利用好這些駕駛數(shù)據(jù)能夠更好地幫助進(jìn)行車道線的預(yù)測(cè)。
特斯拉的自動(dòng)車道線標(biāo)注有三個(gè)步驟:
1、通過視覺慣性里程計(jì)(visual inertial odometry)技術(shù),對(duì)所有的旅程進(jìn)行高精度軌跡估計(jì)。
2、多車多旅程的地圖重建,是該方案中的最關(guān)鍵步驟。該步驟的基本動(dòng)機(jī)是,不同的車輛對(duì)同一個(gè)地點(diǎn)可能有不同空間角度和時(shí)間的觀測(cè),因此將這些信息進(jìn)行聚合能更好地進(jìn)行地圖重建。該步驟的技術(shù)點(diǎn)包括地圖間的幾何匹配和結(jié)果聯(lián)合優(yōu)化。
3、對(duì)新旅程進(jìn)行車道自動(dòng)標(biāo)注。當(dāng)我們有了高精度的離線地圖重建結(jié)果后,當(dāng)有新的旅程發(fā)生時(shí),我們就可以進(jìn)行一個(gè)簡(jiǎn)單的幾何匹配,得到新旅程車道線的偽真值(pseudolabel)。這種獲取偽真值的方式有時(shí)候(在夜晚、雨霧天中)甚至?xí)?yōu)于人工標(biāo)注。
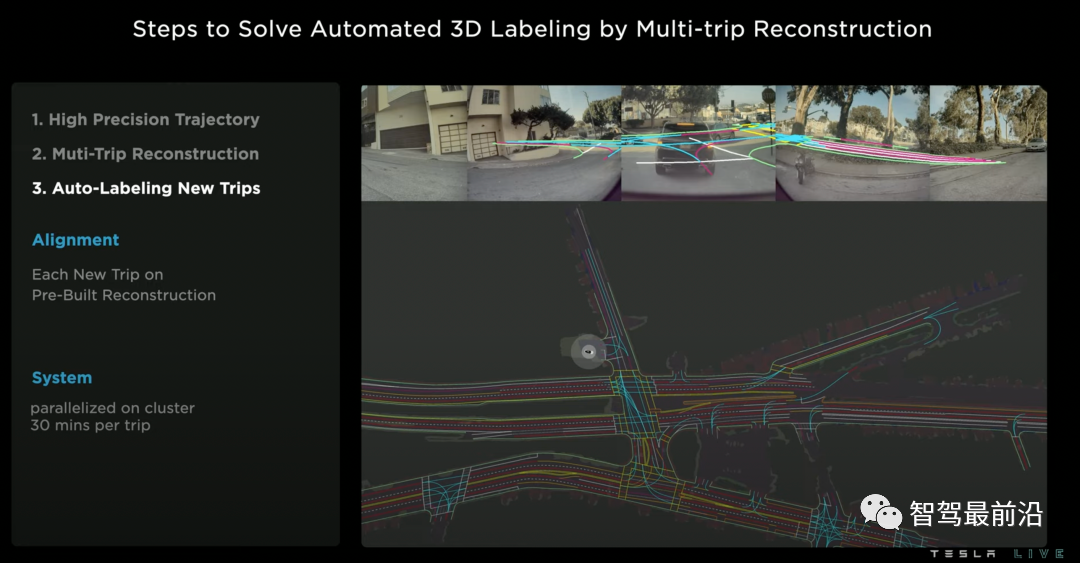
Lanes Network自動(dòng)標(biāo)注
視覺圖像的仿真是近年來(lái)計(jì)算機(jī)視覺方面的熱門方向。在自動(dòng)駕駛中,視覺仿真的主要目的,是有針對(duì)性地生成一些少見場(chǎng)景,從而免掉到真實(shí)路測(cè)中去碰運(yùn)氣的必要。例如,特斯拉常年頭疼的路中央橫著大卡車的場(chǎng)景。但是視覺仿真并不是一個(gè)簡(jiǎn)單的問題,對(duì)于一個(gè)復(fù)雜的路口(舊金山的Market Street),利用傳統(tǒng)建模渲染的方案需要設(shè)計(jì)師2周的時(shí)間。而特斯拉通過AI化的方案,現(xiàn)在只需要5分鐘。
具體來(lái)說(shuō),視覺仿真的先決條件是要準(zhǔn)備自動(dòng)標(biāo)注的真實(shí)世界道路信息 ,和豐富的圖形素材庫(kù)。然后依次進(jìn)行以下步驟:
1、路面生成:根據(jù)路沿進(jìn)行路面的填充,包括路面坡度、材料等細(xì)節(jié)信息。
2、車道線生成:將車道線信息在路面上進(jìn)行繪制。
3、植物和樓房生成:在路間和路旁隨機(jī)生成和渲染植物和房屋。生成植物和樓房的目的不僅僅是為了視覺的美觀,它也同時(shí)仿真了真實(shí)世界中這些物體引起的遮擋效應(yīng)。
4、其他道路元素生成:如信號(hào)燈,路牌,并且導(dǎo)入車道和連接關(guān)系。
5、加入車輛和行人等動(dòng)態(tài)元素。
基礎(chǔ)設(shè)施 Infrastructure
最后,我們簡(jiǎn)單說(shuō)說(shuō)特斯拉這一系列軟件技術(shù)的基礎(chǔ),就是強(qiáng)大的基礎(chǔ)設(shè)施。特斯拉的超算中心擁有14000個(gè)GPU,共30PB的數(shù)據(jù)緩存,每天都有500000個(gè)新的視頻流入這些超級(jí)計(jì)算機(jī)。為了更高效地處理這些數(shù)據(jù)額,特斯拉專門開發(fā)了加速的視頻解碼庫(kù),以及加速讀寫中間特征的文件格式.smol file format。此外,特斯拉還自研了超算中心的芯片Dojo,我們?cè)谶@里不做講解。

視頻模型訓(xùn)練的超算中心
總結(jié)
隨著近兩年特斯拉AI Day的內(nèi)容發(fā)布,我們慢慢看清了特斯拉在自動(dòng)(輔助)駕駛方向上的技術(shù)版圖,同時(shí)我們也看到特斯拉自己也在不停地自我迭代,例如從2D感知,BEV感知,到Occupancy Network。自動(dòng)駕駛是一個(gè)萬(wàn)里長(zhǎng)征,是什么在支撐特斯拉技術(shù)的演進(jìn)呢?我想是三點(diǎn):視覺算法帶來(lái)的全場(chǎng)景理解能力,強(qiáng)大算力支持的模型迭代速度,海量數(shù)據(jù)帶來(lái)的泛化性。這不就是深度學(xué)習(xí)時(shí)代的三大支柱嗎?
編輯:黃飛
?
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論